finetune网上博客
1. 招式1:使用Pretrain模型做约束
在Finetune阶段,如果我们可用于Finetune的目标任务数据量较少时,很有可能出现过拟合现象,严重影响模型效果;或者在Finetune过程中出现知识遗忘问题(catastrophic memory),把Pretrain阶段学到的有用知识遗忘,丢了西瓜捡了芝麻。为了解决这种问题,学术界提出利用Pretrain模型作为约束,指导Finetune的过程,让Finetune得到的模型更加鲁棒。具体包括:==直接使用Pretrain模型的参数作为约束、使用Pretrain模型的中间层表示作为约束、使用Pretrain模型对不同特征注意力强度作为约束==。
为了防止模型在Finetune阶段过拟合目标任务数据,或忘记了Pretrain阶段学到的有意义知识,Explicit inductive bias for transfer learning with convolutional networks(ICML 2018)*这篇文章介绍了一种使用Pretrain模型参数约束Finetune过程的方法:通过添加Pretrain模型参数和Finetune模型参数之间的某种正则化损失,让Finetune后的模型参数和最开始的Pretrain模型参数更加相似。文章中尝试了多种正则化方法,通过最终的实验发现,一个简单的L2正则效果最好,即对于Pretrain模型和Finetune模型的对应层的参数计算L2距离,作为Finetune过程中损失函数的一部分**,公式如下(w为Finetune参数,w0位Pretrain参数):
$$
\Omega(\boldsymbol{w})=\frac{\alpha}{2}\left|\boldsymbol{w}-\boldsymbol{w}^0\right|_2^2
$$
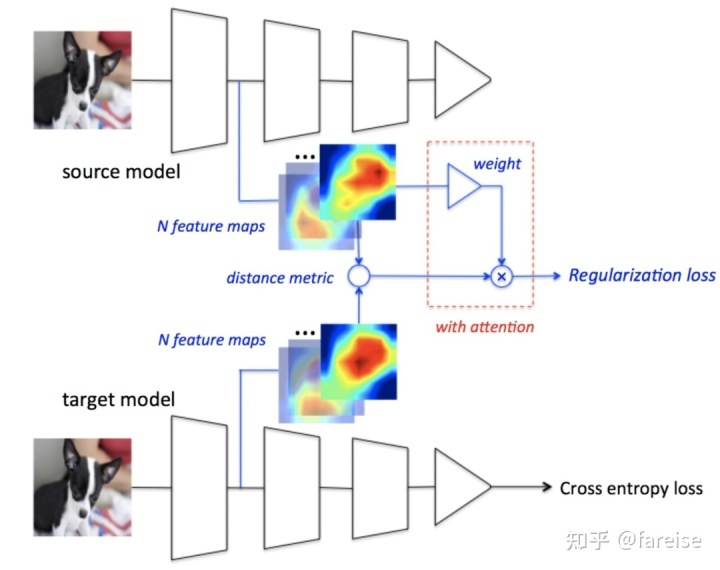
通过L2正则化的方法拉近Pretrain模型和Target模型参数也存在一定问题,如何设定正则化的强度直接决定了迁移效果,正则化太弱仍然会导致过拟合和信息遗忘,迁移强度太强会导致Finetune的模型在Target任务上不是最优解。百度的文章 DELTA: DEEP LEARNING TRANSFER USING FEATURE MAP WITH ATTENTION FOR CONVOLUTIONAL NET- WORKS(ICLR 2019) 提出,通过约束网络的behavior,即feature map,而非模型参数,来实现约束目标。具体的,约束项可以表示为如下形式:
$$
\Omega^{\prime}\left(\omega, \omega^, \mathbf{x}i, y_i, z\right)=\sum{j=1}^N\left(\mathrm{~W}_j\left(z, \omega^*, \mathbf{x}_i, y_i\right) \cdot | \mathrm{FM}_j\left(z, \omega, \mathbf{x}_i\right)-\mathrm{FM}_j\left(z, \omega^*, \mathbf{x}_i\right)\right) |_2^2
$$
其中,Wj表示第j个卷积层的约束强度,FM表示第i个样本经过参数w提取的feaure map。Wj的计算方法为,使用Pretrain的模型Freeze住底层Feature Extractor参数,Finetune后面Discriminator参数,通过衡量去掉每个channel后效果的损失,得到这个channel的迁移强度。如果去掉Pretrain模型某个channel后效果下降特别明显,说明Pretrain得到的这个channel的信息对Target任务是很有效的,这个时候要增大这种channel参数的迁移强度。
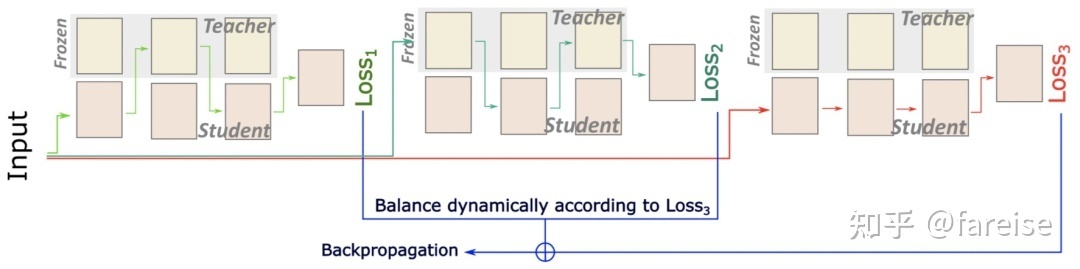
采用Pretrain模型对Finetune模型进行约束需要引入额外的正则化Loss,可以被称为Transfer Loss。由于Transfer Loss和Target Task Loss的优化目标不同,如何平衡两个Loss的关系决定了迁移效果。为了统一这两种Loss,Robust Knowledge Transfer via Hybrid Forward on the Teacher-Student Model(AAAI 2021) 提出了一种混合前向网络。当一个样本输入时,会通过三种不同的路径得到三种Loss,Loss1和Loss2通过交替进入Student网络(Target Task模型)某层和Teachder网络(Pretrain模型)某层,最终再通过Target Task Head得到;Loss3只进入Student网络通过Target Task Head得到。Loss1和Loss2代表了Student网络和Teachder网络Transfer Loss,Loss3代表了Target Task的优化Loss。与之前方法相比,该方法的三个Loss都是以优化Target Task为目标的,因此可以通过直接对比来判断目前的Transfer强度是否太强。文中设计了一种简单的平衡Transfer Loss和Target Loss的方法,让两个任务的Loss同等重要,随着训练过程动态计算Loss1和Loss2的权重。
TODO…
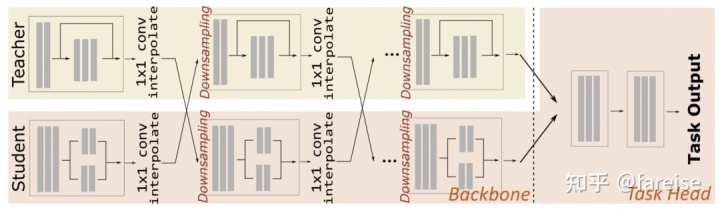
2. 招式2:选择性地对Pretrain模型迁移
Pretrain模型中的参数不一定都是对下游任务有帮助的,因此一些研究提出,对Pretrain的模型进行有选择性的迁移,重点迁移那些对下游任务帮助大的信息。Learning What and Where to Transfer(ICML 2019) 中提出一种基于meta-learning的迁移学习方法。这篇文章的核心思路建立在FITNETS: HINTS FOR THIN DEEP NETS(ICLR 2015) 一文提出的迁移方法之上,让Target模型通过一个回归任务拟合Pretrain模型中间层的表示,该优化目标可以表示为:
$$
\mathcal{L}{H T}\left(\mathbf{W}{\text {Guided }}, \mathbf{W}{\mathbf{r}}\right)=\frac{1}{2}\left|u_h\left(\mathbf{x} ; \mathbf{W}{\text {Hint }}\right)-r\left(v_g\left(\mathbf{x} ; \mathbf{W}{\text {Guided }}\right) ; \mathbf{W}{\mathbf{r}}\right)\right|^2
$$
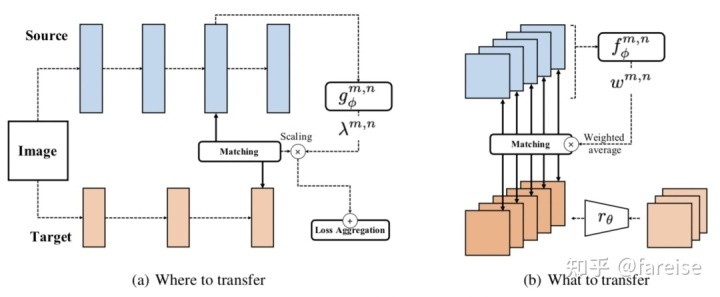
在FitNet中WGuided和WHint分别表示Target模型的Pretrain模型某一对应层的参数。Learning What and Where to Transfer(ICML 2019) 对该方法进行了扩展。在What to transfer阶段,对每一个channel的迁移做一个权重学习,每个channel的权重是通过一个单独的网络输入图片在Source模型的输出计算得到的(T代表Target模型,S代表Source模型,与FitNet中的Guided和Hint相对应):
$$
\begin{aligned}
& \mathcal{L}{\text {wfm }}^{m, n}\left(\theta \mid x, w^{m, n}\right) \
& =\frac{1}{H W} \sum_c w_c^{m, n} \sum{i, j}\left(r_\theta\left(T_\theta^n(x)\right){c, i, j}-S^m(x){c, i, j}\right)^2 \
&
\end{aligned}
$$
在Where to transfer阶段,主要决定Source模型到Target模型的迁移层pair,即Source模型的第i层参数要迁移到Target模型的哪一层。类似What to transfer,通过一个单独的网络学习(i,j)这组Source模型到Target模型pair对的迁移强度:
$$
\mathcal{L}{\mathrm{wfm}}(\theta \mid x, \phi)=\sum{(m, n) \in \mathcal{C}} \lambda^{m, n} \mathcal{L}_{\mathrm{wfm}}^{m, n}\left(\theta \mid x, w^{m, n}\right)
$$
最终的Loss由上面两个阶段的Loss,以及任务本身的Loss共同组成。在训练阶段,文章采用了Meta-learning的方法,内循环阶段更新总体Loss,外循环阶段更新三个Loss的总和。Meta-learning原理可以参考历史文章Meta-learning核心思想及近年顶会3个优化方向。
3. 招式3:在Finetune阶段调整网络结构
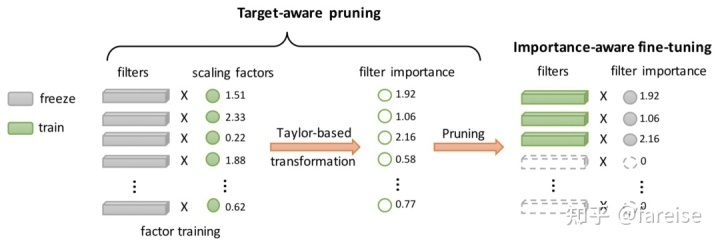
之前介绍的迁移学习方法,大多数都是通过Finetune对Pretrain模型的参数进行调整。然而,下游的Target任务可能需要和Source任务采用不同的模型结构来更好的进行学习。因此,TransTailor: Pruning the Pre-trained Model for Improved Transfer Learning(AAAI 2021) 提出了一种在Finetune阶段动态剪枝的方法,实现Finetune阶段不仅能够调整模型参数,还能调整模型网络结构。该方法分为Target-aware Pruning和Importance-aware Finetuning两个阶段。在Target-aware Pruning阶段,对于网络中每一层的每一个filter,都对应一个可学习的权重,把Pretrain模型的参数Freeze住,使用Target任务的数据和优化目标进行训练,得到每组参数最终对应的权重,训练过程可以表示为:
$$
\alpha^*=\arg \min _\alpha \mathcal{L}\left(D_t ; W_f^s \odot \alpha\right)
$$
这个重要性权重会使用泰勒变换,融合全局各层的打分结果得到全局的打分,最后将打分较低的网络参数剪枝掉。在Importance-aware Finetuning,会结合第一阶段得到的参数打分进行Finetune,具体的,通过将每组参数的打分结果乘到参数上,的到参数的转换结果进行前向传播。最终两个过程交替进行,直到得到最终模型。
4. 招式4:学习每组参数Transfer的方式
在利用Pretrain模型进行迁移学习时,我们往往需要决定哪些网络的参数要Freeze,哪些网络参数跟随Target任务Finetune。例如,在CV领域,一些研究表明底层网络能够提取出更一般的图像规律,而接近分类层的参数对于不同Task差异很大,因此为了不将Pretrain阶段学到的知识破坏,将底层参数Freeze,只Finetune上层参数,会最大限度保留Pretrain阶段在大量数据学到的知识,提升迁移学习效果。然而,不同任务需要Freeze的参数存在差异,人工调试不同的Transfer方式(哪些层Freeze、哪些层Finetune)效率很低。同时,一般的Finetune假设每个Target样本都应该使用相同的Finetune方式,这也是不合理的。例如,和source domain更相似的样本,从source domain迁移更多知识更有帮助。因此,学术界出现一些相关工作,自动化学习每层以及每个样本的迁移策略。
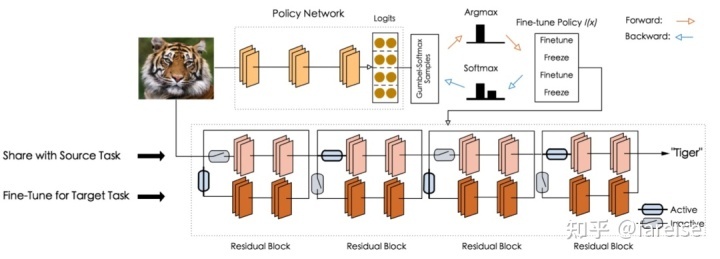
在SpotTune: Transfer Learning through Adaptive Fine-tuning(CVPR 2019) 这篇文章中,提出了对于每个样本学习一个个性化的迁移方式。对于每个样本,经过网络的每层可以选择是使用Pretrain模型的原始参数,还是使用Pretrain模型初始化后Finetune的参数。模型通过一个Policy Network,输入每个样本的特征(一般使用Pretrain模型对样本的表征向量),输出模型每组参数的迁移方式(使用Pretrain模型原始参数,或使用Pretrain模型初始化后Finetune的参数)。这个过程中需要对两种迁移方式进行采样,而采样运算不可导。为了让该运算可导,本文使用了Gumbel-Max Trick生成采样结果。SpotTune的模型结构如下图所示:
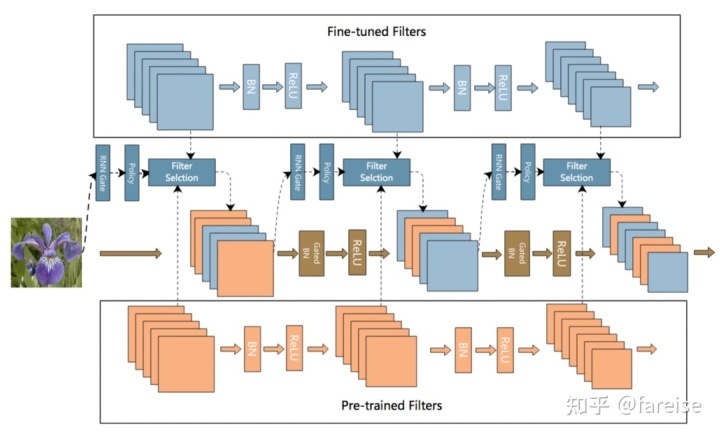
SpotTune实现了每个样本个性化的Finetune策略学习,但是只能做到layer维度。AdaFilter: Adaptive Filter Fine-tuning for Deep Transfer Learning(AAAI 2020) 提出了能够在filter维度实现每个样本的Finetune策略学习。与SpotTune类似,Finetune策略仍然为使用Pretrain模型的原始参数,或使用Pretrain模型初始化后Finetune的参数两种。与SpotTune不同的是,AdaFilter使用RNN学习每层各个channel的Finetune策略,每层的Finetune策略选择依赖于上一层输出的表示(SpotTune则是根据样本同时产出所有层的Finetune策略)。
TODO…
5. 总结
本文介绍了7篇顶会论文中对Finetune阶段进行的改进,包括Finetune过程使用Pretrain模型做约束、选择性地对Pretrain模型进行迁移、在Finetune阶段调整网络结构以及学习每组参数Transfer的方式4种类型。Pretrain-Finetune的核心问题在于,如何考虑到Target Task的样本特性,将Pretrain的知识合理迁移到Target Task的模型上。其中每个样本个性化地进行Finetune策略学习,可能是后续可以继续深入研究的方向。