Multi-Task Learning Using Uncertainty to Weigh Losses for Scene Geometry and Semantics
Kendall, Alex, Yarin Gal, and Roberto Cipolla. “Multi-task learning using uncertainty to weigh losses for scene geometry and semantics.” Proceedings of the IEEE conference on computer vision and pattern recognition. 2018. citations 2258
网友复现 github:https://github.com/ranandalon/mtl
解决什么问题
多任务学习loss如何平衡的问题。
提出什么方法
- 每个任务的同方差不确定性 homoscedastic uncertainty。将同方差不确定性解释为任务相关的加权。文章中展示了如何推导出一个的多任务损失函数,该函数可以学习平衡各种回归和分类损失。
- 使用 shared representation(共享encoder输出特征)可以在各种指标(度量)上都能改善性能。
- 就用一个模型,进行多任务,可以让模型在不同的独立的任务输出之间保持一致,同时减少计算量。
本文贡献
- 利用同方差任务不确定性,同时学习不同数量和单位的各种分类和回归损失的多任务损失。
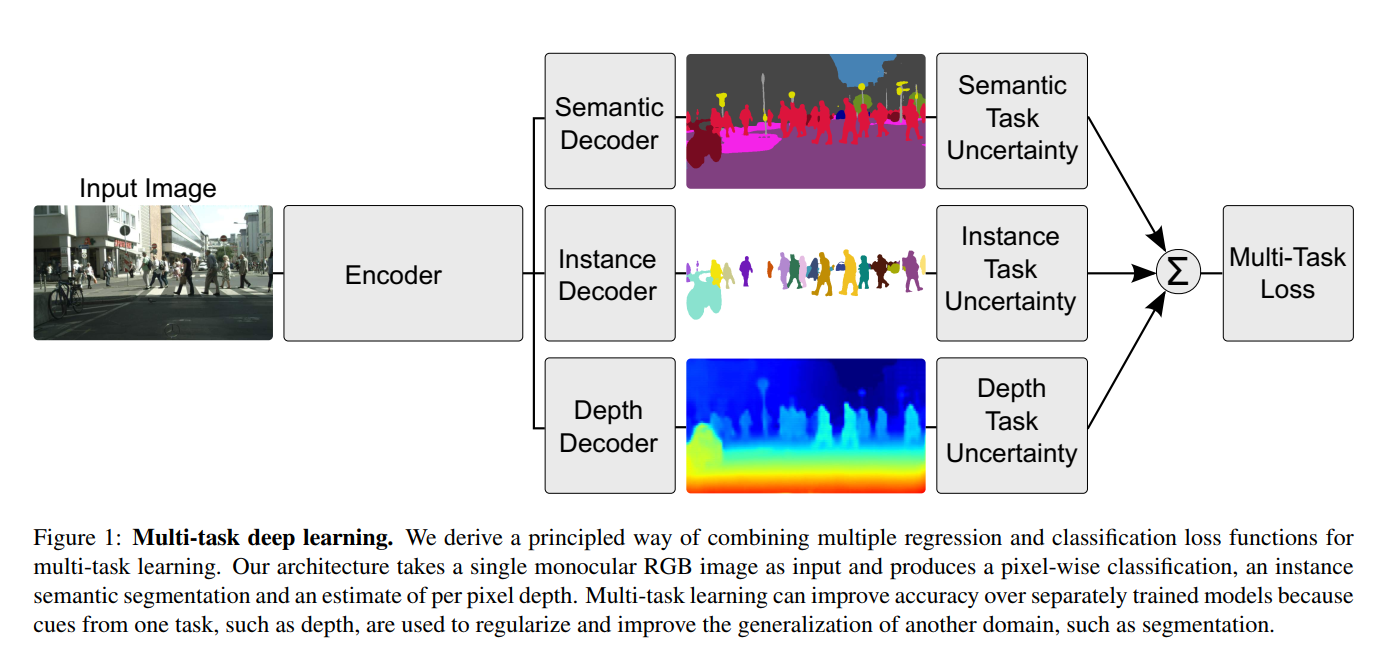
- 语义分割、实例分割和深度回归的统一架构。
- 证明了损失加权在多任务深度学习中的重要性,以及与等效的单独训练模型相比如何获得更好的性能。
效果如何
与单独学习每个任务相比,本文方法可以学习优化这些权重,从而获得更好的性能。
应用场景的例子是用的 语义分割 semantic segmentation (classify objects at a pixel level )、实例分割instance segmentation(回归任务) 、pixel-wise metric depth(depth regression,是一个回归任务 ),同时训练这三个任务。
还存在什么问题
。。。
思路
多任务,这里应用场景的例子是用的 语义分割 semantic segmentation (classify objects at a pixel level )、实例分割instance segmentation 、pixel-wise metric depth ,同时训练这三个任务。
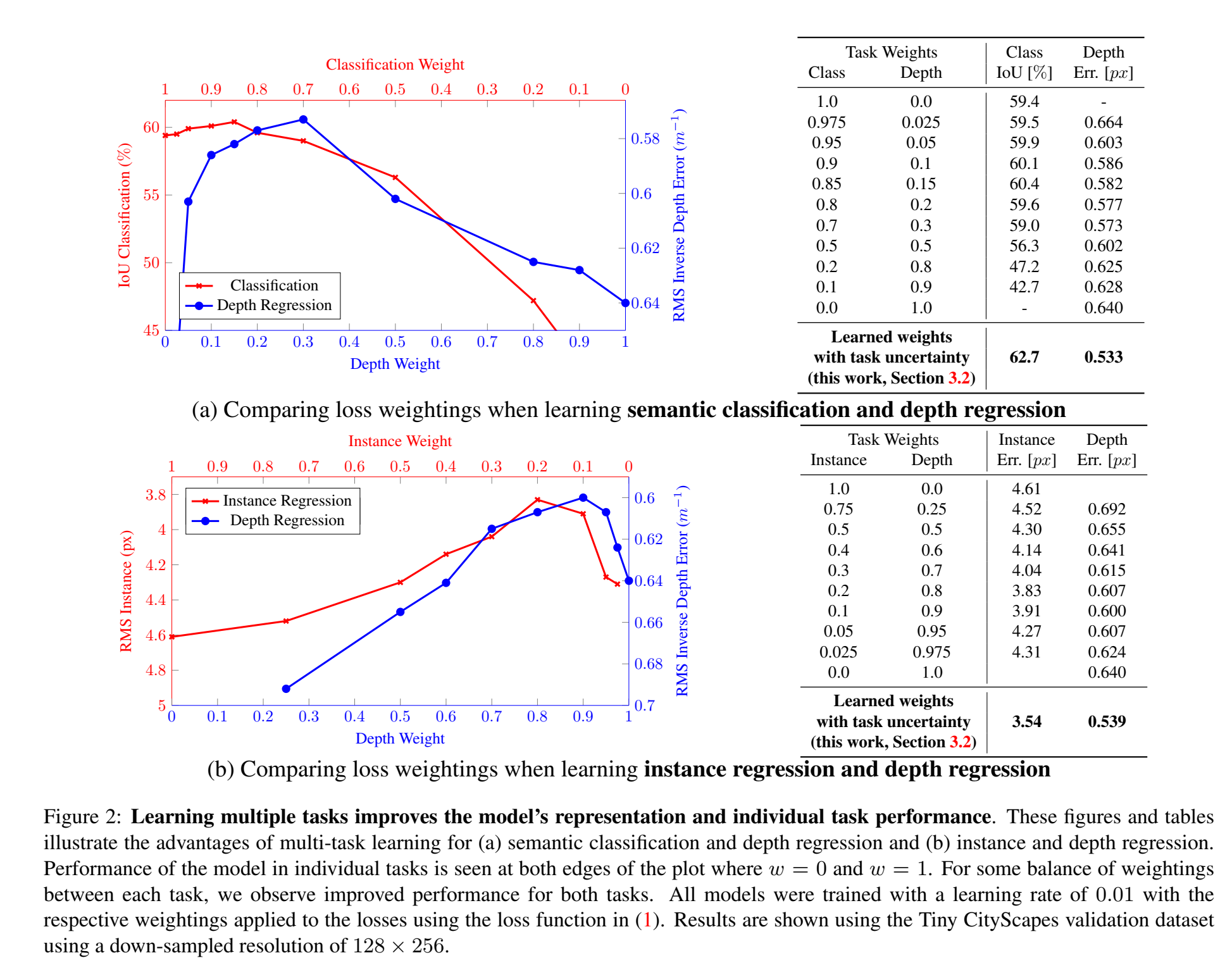
w=0和w=1是单独训练模型的情况,w在0-1中间值是联合训练:
Homoscedastic uncertainty as task-dependent uncertainty
在贝叶斯建模中,有两种主要的不确定性可以建模:
- Epistemic uncertainty 认知不确定性。是模型中的不确定性,它捕获了我们的模型由于缺乏训练数据而不知道的东西。这可以用增加的训练数据来解释。
- Aleatoric uncertainty 偶然不确定性。捕捉我们对于数据无法解释的信息的不确定性,可以解释为能够越来越精确地观察所有解释变量。分为两个子类:
- Data-dependent 或 Heteroscedastic uncertainty 是一种依赖于输入数据并被预测为模型输出的 Aleatoric uncertainty。
- Task-dependent 或 Homoscedastic uncertainty 不依赖输入数据的 Aleatoric uncertainty,相反,它是一个对所有输入数据保持不变的量,在不同的任务之间变化。因此,它可以被描述为任务相关的不确定性。
任务不确定性捕获任务之间的相对置信度,反映回归或分类任务固有的不确定性。它还取决于任务的表示或度量单位。这里用的是 Homoscedastic uncertainty。
同方差 指的是假定数据输入一定的情况下,真实的分布与任务的输出之间有一个恒定的方差。
Multi-task likelihoods
推导了一个基于最大化具有同方差不确定性的高斯似然的多任务损失函数。神经网络输入 $\mathbf x$,经过权重 $\mathbf W$,得到输出 $\mathbf f^\mathbf W(\mathbf x)$。
对于回归任务,定义输出的似然值服从一个均值是模型输出的高斯分布,即:
$$
p\left(\mathbf{y} \mid \mathbf{f}^{\mathbf{W}}(\mathbf{x})\right)=\mathcal{N}\left(\mathbf{f}^{\mathbf{W}}(\mathbf{x}), \sigma^2\right)
$$
其中,$\sigma$ 是观测噪声,是一个标量。
对于分类任务,通常通过一个softmax函数压缩模型输出,并从产生的概率向量中取样:
$$
p\left(\mathbf{y} \mid \mathbf{f}^{\mathbf{W}}(\mathbf{x})\right)=\operatorname{Softmax}\left(\mathbf{f}^{\mathbf{W}}(\mathbf{x})\right) .
$$
定义 $\mathrm{f}^{\mathrm{W}}(\mathrm{x})$ 作为充分统计量 sufficient statistics,则多任务似然概率可以分解为:
$$
p\left(\mathbf{y}_1, \ldots, \mathbf{y}_K \mid \mathbf{f}^{\mathbf{W}}(\mathbf{x})\right)=p\left(\mathbf{y}_1 \mid \mathbf{f}^{\mathbf{W}}(\mathbf{x})\right) \ldots p\left(\mathbf{y}_K \mid \mathbf{f}^{\mathbf{W}}(\mathbf{x})\right)
$$
输出 $\mathbf{y}_1, \ldots, \mathbf{y}_K$ 是不同任务的输出。
最大似然推断,用最大化 $\log$ 似然值。
对于回归任务,$\log$ 似然值:
$$
\log p\left(\mathbf{y} \mid \mathbf{f}^{\mathbf{W}}(\mathbf{x})\right) \propto-\frac{1}{2 \sigma^2}\left|\mathbf{y}-\mathbf{f}^{\mathbf{W}}(\mathbf{x})\right|^2-\log \sigma
$$
$\sigma$ 是模型的观测噪声参数,捕捉在输出中有多少噪声(通过方差来看出输出的变化程度?)。最大log似然估计,参数是 $\mathbf{W}$ 和 $\sigma$。
现在假设模型输出由两个向量 $\mathbf{y}_1$ 和 $\mathbf{y}_2$ 组成,每个向量都服从高斯分布:
$$
\begin{aligned}
p\left(\mathbf{y}_1, \mathbf{y}_2 \mid \mathbf{f}^{\mathbf{W}}(\mathbf{x})\right) & =p\left(\mathbf{y}_1 \mid \mathbf{f}^{\mathbf{W}}(\mathbf{x})\right) \cdot p\left(\mathbf{y}_2 \mid \mathbf{f}^{\mathbf{W}}(\mathbf{x})\right) \
& =\mathcal{N}\left(\mathbf{y}_1 ; \mathbf{f}^{\mathbf{W}}(\mathbf{x}), \sigma_1^2\right) \cdot \mathcal{N}\left(\mathbf{y}_2 ; \mathbf{f}^{\mathbf{W}}(\mathbf{x}), \sigma_2^2\right)
\end{aligned}
$$
最小化多任务loss, $\mathcal{L}\left(\mathbf{W}, \sigma_1, \sigma_2\right)$:
$$
\begin{aligned}
\mathcal{L}\left(\mathbf{W}, \sigma_1, \sigma_2\right) &=-\log p\left(\mathbf{y}_1, \mathbf{y}_2 \mid \mathbf{f}^{\mathbf{W}}(\mathbf{x})\right) \
& \propto \frac{1}{2 \sigma_1^2}\left|\mathbf{y}_1-\mathbf{f}^{\mathbf{W}}(\mathbf{x})\right|^2+\frac{1}{2 \sigma_2^2}\left|\mathbf{y}_2-\mathbf{f}^{\mathbf{W}}(\mathbf{x})\right|^2+\log \sigma_1 \sigma_2 \
& =\frac{1}{2 \sigma_1^2} \mathcal{L}_1(\mathbf{W})+\frac{1}{2 \sigma_2^2} \mathcal{L}_2(\mathbf{W})+\log \sigma_1 \sigma_2
\end{aligned}
$$
其中,第一个任务输出变量的loss为 $\mathcal{L}_1(\mathbf{W})=\left|\mathbf{y}_1-\mathbf{f}^{\mathbf{W}}(\mathbf{x})\right|^2$ , $\mathcal{L}_2(\mathbf{W})$ 也是类似的。
==将最后一个关于$\sigma_1$ 和 $\sigma_2$的最小化目标解释为基于数据自适应地学习损失 $\mathcal{L}_1(\mathbf{W})$ 和 $\mathcal{L}_2(\mathbf{W})$ 的相对权重。==
当输出 $y_1$ 的噪声参数 $\sigma_1$ 增大,则 $\mathcal{L}_1(\mathbf{W})$ 的权重要减小。目标中的最后一项阻止噪声增加太多(有效地忽略数据),它充当噪声项的正则器。
我的理解是:loss function里的方差项大时,也就是输出似然值变化大,我们希望输出似然值变化不要那么大,要朝着变化小的方向更新,于是这个任务的权重调小一点。
对于分类任务,通过一个softmax函数调整分类似然来压缩模型输出的缩放scaled版本
$$
p\left(\mathbf{y} \mid \mathbf{f}^{\mathbf{W}}(\mathbf{x}), \sigma\right)=\operatorname{Softmax}\left(\frac{1}{\sigma^2} \mathbf{f}^{\mathbf{W}}(\mathbf{x})\right)
$$
$\sigma$是一个正数的标量。解释为 Boltzmann distribution (也成为 Gibbs distribution) ,输入缩放到 $\sigma^2$ (通常也叫做 temperature)。这个标量要么是固定的,要么是可以学习的,其中参数的大小决定了离散分布的“均匀”(平坦)程度。这与它的不确定性有关,以熵来衡量。该输出的对数似然可以写成
$$
\begin{aligned}
\log p\left(\mathbf{y}=c \mid \mathbf{f}^{\mathbf{W}}(\mathbf{x}), \sigma\right) & =\frac{1}{\sigma^2} f_c^{\mathbf{W}}(\mathbf{x}) \
& -\log \sum_{c^{\prime}} \exp \left(\frac{1}{\sigma^2} f_{c^{\prime}}^{\mathbf{W}}(\mathbf{x})\right)
\end{aligned}
$$
其中, $f_{c^{\prime}}^{\mathbf{W}}(\mathbf{x})$ 是向量 $\mathbf{f}^{\mathbf{W}}(\mathbf{x})$ 的第 $c^{\prime}$ 个元素。
假设模型的多个输出由连续输出 $y_1$ 和离散输出 $y_2$ 组成,分别用高斯似然和软最大似然建模。就像之前的联合损失一样,$\mathcal{L}\left(\mathbf{W}, \sigma_1, \sigma_2\right)$:
$$
\begin{aligned}
\mathcal{L}\left(\mathbf{W}, \sigma_1, \sigma_2\right)& =-\log p\left(\mathbf{y}_1, \mathbf{y}_2=c \mid \mathbf{f}^{\mathbf{W}}(\mathbf{x})\right) \
& =-\log \mathcal{N}\left(\mathbf{y}_1 ; \mathbf{f}^{\mathbf{W}}(\mathbf{x}), \sigma_1^2\right) \cdot \operatorname{Softmax}\left(\mathbf{y}_2=c ; \mathbf{f}^{\mathbf{W}}(\mathbf{x}), \sigma_2\right) \
& =\frac{1}{2 \sigma_1^2}\left|\mathbf{y}1-\mathbf{f}^{\mathbf{W}}(\mathbf{x})\right|^2+\log \sigma_1-\log p\left(\mathbf{y}2=c \mid \mathbf{f}^{\mathbf{W}}(\mathbf{x}), \sigma_2\right) \
& =\frac{1}{2 \sigma_1^2} \mathcal{L}1(\mathbf{W})+\frac{1}{\sigma_2^2} \mathcal{L}2(\mathbf{W})+\log \sigma_1 \
& \qquad \quad+\log \frac{\sum{c^{\prime}} \exp \left(\frac{1}{\sigma_2^2} f{c^{\prime}}^{\mathbf{W}}(\mathbf{x})\right)}{\left(\sum{c^{\prime}} \exp \left(f{c^{\prime}}^{\mathbf{W}}(\mathbf{x})\right)\right)^{\frac{1}{\sigma_2^2}}} \
& \approx \frac{1}{2 \sigma_1^2} \mathcal{L}_1(\mathbf{W})+\frac{1}{\sigma_2^2} \mathcal{L}_2(\mathbf{W})+\log \sigma_1+\log \sigma_2,
\end{aligned}
$$
其中, $\mathcal{L}_1(\mathbf{W})=\left|\mathbf{y}_1-\mathbf{f}^{\mathbf{W}}(\mathbf{x})\right|^2$ 是 $\mathbf{y}_1$ loss的欧氏距离, $\mathcal{L}_2(\mathbf{W})=-\log \operatorname{Softmax}\left(\mathbf{y}_2, \mathbf{f}^{\mathbf{W}}(\mathbf{x})\right)$ 是 $\mathbf{y}_2$ 的交叉熵( $\mathbf{f}^{\mathrm{W}}(\mathrm{x})$ 没缩放)
(验算了一下是对的)
最优化参数 $\mathbf{W}$ 、 $\sigma_1$ 、$\sigma_2$ 。上式的最后一行是做了简化:假设 $\frac{1}{\sigma_2} \sum_{c^{\prime}} \exp \left(\frac{1}{\sigma_2^2} f_{c^{\prime}}^{\mathbf{W}}(\mathbf{x})\right) \approx$ $\left(\sum_{c^{\prime}} \exp \left(f_{c^{\prime}}^{\mathbf{W}}(\mathbf{x})\right)\right)^{\frac{1}{\sigma_2^2}}$ ,当 $\sigma_2 \rightarrow 1$ 时等号成立。
感觉这一步简化是比较难想到的。。。
最后一个目标可以看作是学习每个输出的损失的相对权重。由 $\frac{1}{2 \sigma_1^2} \mathcal{L}_1(\mathbf{W})$ 可知, 大缩放数值值$\sigma_2$ 会降低 $\mathcal{L}_2(\mathbf{W})$的贡献,反之亦然。缩放值由方程的最后一项决定。当将$\sigma_2$设置太大时,目标将被惩罚。
pytorch版代码实现
pytorch实现一:
阿里云社区 【多任务学习】Multi-Task Learning Using Uncertainty to Weigh Losses for Scene Geometry and Semantics
1 | import math |
pytorch实现二:
csdn:【论文阅读】Multi-Task Learning Using Uncertainty to Weigh Losses for Scene Geometry and Semantics
1 | class DynamicWeightedLoss(nn.Module): |
评价
多任务loss间权重如何设置呢,手调太费时,能不能通过loss值的变化大小来反馈给权重呢,要怎么衡量loss值变化呢,衡量变化,也就是衡量不确定性,很容易想到熵是衡量不确定性的。(然后我现在暂时还不知道,为什么是这样)就是对于分类任务,softmax输出乘以一个方差倒数(这个在蒸馏里是temperature),认为是“软最大似然”,这个物理意义为方差的参数$\sigma$ ,用来衡量不确定性,如果某一个任务loss变化大,则方差(不同任务的相对权重)设置为小一点;对于回归任务,认为模型似然服从高斯分布,高斯分布的均值是模型输出(因为没有softmax,所以模型输出不是后验概率),方差是 $\sigma$,然后和分类任务差不多,如果某一个任务loss变化大,则方差(不同任务的相对权重)设置为小一点。