端到端合成论文——声学模型——VITS
==Kim, Jaehyeon, Jungil Kong, and Juhee Son. “Conditional variational autoencoder with adversarial learning for end-to-end text-to-speech.” International Conference on Machine Learning. PMLR, 2021.== citations: 118 Kakao (和hifi-gan一样的作者)
- 解决什么问题
- one-stage TTS model合成音质没有two-stage model好的问题。
- 用了什么方法
- 提出VITS(Variational Inference with adversarial learning for end-to-end Text-to-Speech) ,是一个结合了变分推断、标准化flow、对抗网络的TTS model;
- 提出了一种从输入文本合成不同韵律语音的随机时长预测器,实现one-to-many。
- 不同于two-stage tts用mel谱作为中间产物进行声学模型和声码器的串联,vits用的vae的隐变量作为中间物。
- 效果如何
- 比two-stage TTS model音质好,更自然;
- 多种生成方法结合,改善了生成模型的建模能力;
- 在LJ Speech数据集达到SOTA,媲美真实声音。
- 存在什么问题
- VITS输入依然需要文本预处理,研究语言表征的自监督学习可能是消除文本预处理的一个可能的方向。
相关工作
为什么likelihood-based的方法对于序列问题会更好:因为不用去学习text和spectrograms之间的alignment关系,直接通过最大化目标mel谱的似然。(之间用attention-map来得到text和mel的对齐关系,attention-map越好,tts模型性能更好)
two-stage系统有天然的问题,在于:
- 训练vocoder的输入用的是声学模型生成(输出)的样本,声学模型训得很好或不太好,对于后面的vocoder,以及整体的语音合成来说,不确定哪种结合方案是最好的。就是两个模型之间有gap。
- 依赖于预定义的中间特征,比如mel谱,因此无法应用习得的隐藏表示来获得进一步的性能改进。
思路
提出一个端到端TTS方法,叫VITS,用了CVAE来连接两个模块(vocoder和声学模型),CVAE的隐变量就是两个模块之间的code,中间变量;用了标准化flow来建模条件先验分布;用了对抗学习来训练生成waveform的vocoder模块。CVAE的隐变量能起到一定的one-to-many效果,为了进一步one-to-many的效果,提出stochastic duration predictor 随机时长预测器,合成不同rhythm的语音。
方法
Variational Inference
OVERVIEW
CVAE的目标是最大化变分下界variational lower bound ,也叫做 $\log p_\theta(x \mid c) $ 的 evidence lower bound (ELBO)
$$
\log p_\theta(x \mid c) \geq \mathbb{E}{q_\phi(z \mid x)}\left[\log p_\theta(x \mid z)-\log \frac{q_\phi(z \mid x)}{p_\theta(z \mid c)}\right]
=-K L\left(q_\phi(\mathbf{z} \mid \mathbf{x}) | p_\theta(\mathbf{z} \mid \mathbf{c})\right)+\mathbb{E}{q_\phi(\mathbf{z} \mid \mathbf{x})}\left[\log p_\theta(\mathbf{x} \mid \mathbf{z})\right]
$$
其中, $p_\theta(z \mid c)$ 是给定条件 $c$ 下隐变量 $z$ 的先验分布; $ p_\theta(x \mid z)$ 是数据点 $x$ 的似然函数; $q_\phi(z \mid x)$ 是后验概率分布的近似。
把ELBO取负,则第一项是 $\log q_\phi(z \mid x)$ 和 $\log p_\theta(z \mid c)$ 之间的KL散度,其中 $z \sim q_\phi(z \mid x)$ ;第二项是重构误差 reconstruction loss $-\log p_\theta(x \mid z)$ 。
$x$ 表示mel谱;$c$ 表示文本信息和对齐信息;$z$ 表示隐含变量,其中,对齐信息是一个==硬对齐矩阵,形状为[|text|,|z|]==。
文中提到,发现在 $P(z|c)$ 表示成简单的高斯分布之后再加一个flow变换,音质会更好。(这也就解释了为什么要加flow不可,其实不加也可以的)
RECONSTRUCTION LOSS
==decoder== 。重构误差里的真实数据点x用的是mel谱(不是waveform),用 $x_{mel}$ 表示。采样出来的 $z$ 通过decoder进行上采样,得到 $\hat{y}$ ,将 $\hat{y}$ 转换到mel谱域,得到 $\hat{x}{m e l}$ ,把预测和真实mel谱之间的 $L_1$ loss 作为reconstruction:(这里不是直接最大似然)
$$
L{\text {recon }}=\left|x_{m e l}-\hat{x}_{\text {mel }}\right|_1
$$
这个步骤只在训练阶段进行,而在推理阶段,不是把整个向量 $z$ 都上采样,而是只把一部分送入decoder,这叫做 windowed generator training 。
这个deocoder也就是基于gan的声码器的生成器。
KL-DIVERGENCE
我们的目标是为==后验编码器 posterior encoder==提供更多高分辨率的信息。因此,我们使用目标语音的线性尺度谱 linear-scale spectrogram $x_{lin}$ 作为输入,而不是mel谱。
因此 KL散度公式为:
$$
\begin{gathered}
L_{k l}=\log q_\phi\left(z \mid x_{l i n}\right)-\log p_\theta\left(z \mid c_{\text {text }}, A\right), \
z \sim q_\phi\left(z \mid x_{l i n}\right)=N\left(z ; \mu_\phi\left(x_{l i n}\right), \sigma_\phi\left(x_{l i n}\right)\right)
\end{gathered}
$$
这里 $x_{lin}$ 作为输入到高斯分布中,输出 $z$ ;
所以说训练时,z来自于x,是后验分布得到的z(推理时就不是通过后验分布得到z,因为推理时没有x)
然后,作者发现增加==先验分布== $p(z|c)$ 的表达性对于生成样本像不像真实语音来说很重要,因此提出在encoder的先验分布和后验上做factorized normal distribution用标准化flow $f_\theta$ ,可以根据变量变化规则,将简单分布可逆转换为更复杂的分布。(通过简单的jacobian行列式计算就可以映射过去)
这里其实是额外做了一步,没有flow这一步,先验分布也可以表示的,就是特地做的一步,因为实验发现先验分布表达好了,对结果音质会很友好。
先验分布 ==先验编码器 prior encoder== $ p_\theta(z \mid c)$ 的 factorized normal distribution的表达式为:
$$
\begin{aligned}
p_\theta(z \mid c)&=N\left(f_\theta(z) ; \mu_\theta(c), \sigma_\theta(c)\right)\left|\operatorname{det} \frac{\partial f_\theta(z)}{\partial z}\right| \
& c=\left[c_{\text {text }}, A\right]
\end{aligned}
$$
其中,先验encoder $c$ 的输入条件是文本中提取的音素 $c_{text}$ 和音素、隐变量和音素之间的对齐矩阵 $A$ 组成。
这里c为输入的高斯分布,高斯分布的输出是 $f_\theta(z)$ !注意这里输出比较特别是 $f_\theta(z)$ 服从高斯分布,然后再映射到另一个分布(z的分布)(这里如果对应到flow,z的分布就是复杂分布,而f(z)是简单分布)。
Alignment Estimation
MONOTONIC ALIGNMENT SEARCH
为了估计输入文本和目标语音之间的对齐关系 $A$,作者采用了单调对齐搜索 Monotonic Alignment Search (MAS),这是一种搜索对齐的方法,该方法使标准化flow $f$ 最大化数据的似然值(找在某参数下的A,能够让似然值(这里就不是先验分布了,而是在条件下生成样本)最大,找到对应的参数A):
这里对齐关系是语音x和c的关系。
$$
\begin{aligned}
A&=\underset{\hat{A}}{\arg \max } \log p_\theta\left(x \mid c_{\text {text }}, \hat{A}\right) \
&=\underset{\hat{A}}{\arg \max } \log N\left(f(x) ; \mu\left(c_{\text {text }}, \hat{A}\right), \sigma\left(c_{\text {text }}, \hat{A}\right)\right) \quad
\end{aligned}
$$
这里对齐矩阵A的限制条件为文本和语音都是单调对齐的,并且是non-skipping的。这种求代价最小路径的问题,很容易想出用动态规划求解,但是这里的“代价”,也就是似然值不好求,因为CVAE的目标函数也没直接求似然,而是用的求ELBO代替的。所以作者这里就没有直接用似然值作为动态规划里的“代价”,而是就用的ELBO当作是似然值了。因此MAS公式就变成了,去找ELBO最大时对应的参数A:
$$
\begin{aligned}
A&= \underset{\hat{A}}{\arg \max } \log p_\theta\left(x_{\text {mel }} \mid z\right)-\log \frac{q_\phi\left(z \mid x_{\text {lin }}\right)}{p_\theta\left(z \mid c_{\text {text }}, \hat{A}\right)} \
& =\underset{\hat{A}}{\arg \max } \log p_\theta\left(z \mid c_{\text {text }}, \hat{A}\right) \
& =\log N\left(f_\theta(z) ; \mu_\theta\left(c_{\text {text }}, \hat{A}\right), \sigma_\theta\left(c_{\text {text }}, \hat{A}\right)\right)
\end{aligned}
$$
第二行公式是因为矩阵A和 $p(x|z)$ 、 $q(z|x)$ 都无关,因此忽略这两项,只保留有关的 $p(z|c,A)$ 先验分布, 然后要最大化它。
再根据前面的先验分布的flow模块,由于 $\frac{\partial f_\theta(z)}{\partial z}$ 和A无关,行列式为1,log后为0,写成第三行。
DURATION PREDICTION FROM TEXT
时长预测模型的必要性是因为,推理阶段,先验分布 $p(z|c,A)$ 需要A,如果不知道A就无法得知先验分布,A和音素持续时长有关,因此需要知道音素时长。也就是说这个==时长预测模型,是为了推理阶段服务,才提出的==。
每个人说不同句子都可能会有不同语速,如果是确定的时长预测器(每个phone固定的预测时长),可能合成出来的不够像真实的人类的韵律。作者提出了一种随机时长预测器,每次从音素时长分布中采样,也就是说,每个音素都有一个时长分布,每次通过采样,得到这次这个音素的时长。结构是一个flow-based的生成模型,生成的东西是“音素时长“,训练目标是最大似然估计,直接用会有点问题,因为时长是离散的整数,而flow对象是连续变量,并且时长是一个标量,一个数值,因为flow的可逆性,输入输出维度相同,都是个标量,就不好做高维变换了。
为了解决用flow做时长预测器会遇到的问题,作者用了variational dequantization 和 variational data augmentation 。
具体做法为:引入两个随机变量 $u$ 和 $v$ (和时长序列 $d$ 的time resolution相同(长度相同)、维度相同),$u$ 限制在 [0,1) 里,因此 $d-u$ 就是一个连续变量 (该方法叫variational dequantization);$d$ 和 $v$ 做channel-wise拼接,得到更高维的隐变量表示(该方法叫 variational data augmentation)。 $u$ 、 $v$ 是从近似分布(不是真实分布)后验分布 $q_\phi(u, ν|d, c_{text})$ 中采样来的。
因此,音素时长预测器的目标本来是最大似然估计,这里也用VAE的变分下界代替了,目标表达式为:
$$
\log p_\theta\left(d \mid c_{\text {text }}\right) \geq \mathbb{E}{q_\phi\left(u, \nu \mid d, c{\text {text }}\right)}\left[\log \frac{p_\theta\left(d-u, \nu \mid c_{\text {text }}\right)}{q_\phi\left(u, \nu \mid d, c_{\text {text }}\right)}\right]
$$
训练的时候要让时长预测器的梯度不能回传到input,就传到中间层A、$c_{test}$ 就行(通过A矩阵知道每个音素对应多长的语音)。
实际上训练(目标)的是时长预测器的逆,训练的时候,从真实数据中采样的x作为输入,简单的分布采样z作为输出,训练x到z的映射,然后实际用时,时长预测器取逆,输入简单分布z(随机噪声),抽样,输出时长预测结果x,然后转成整数,作为时长;
Adversarial Training
和gan的vocoder一样了,就是额外添加一个判别器模型,对抗网络目标用最小均方loss和特征匹配loss。
$$
\begin{aligned}
L_{a d v}(D) & =\mathbb{E}{(y, z)}\left[(D(y)-1)^2+(D(G(z)))^2\right] \
L{a d v}(G) & =\mathbb{E}z\left[(D(G(z))-1)^2\right] \
L{f m}(G) & =\mathbb{E}{(y, z)}\left[\sum{l=1}^T \frac{1}{N_l}\left|D^l(y)-D^l(G(z))\right|_1\right]
\end{aligned}
$$
特征匹配loss可以视为VAE里的重构误差 reconstruction loss ?
Final Loss
$$
L_{vae}=L_{recon}+L_{kl}+L_{dur}+L_{adv}(G)+L_{fm}(G)
$$
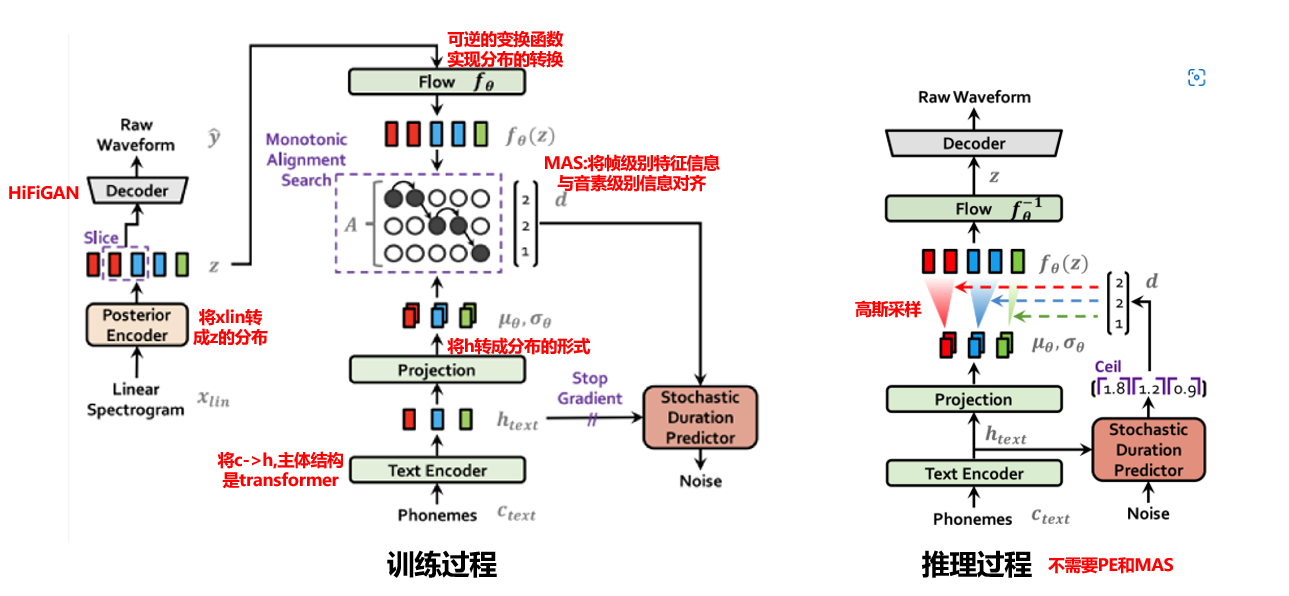
Model Architecture
下面介绍VITS中所使用的模块的结构。
POSTERIOR ENCODER
只用于训练阶段,推理不用。结构是non-causal WaveNet residual blocks 。
也就是拟合 $q_\phi(z \mid x)$ 后验概率。
输入 $x_{lin}$ ,输出均值方差,后验概率,再采样出z。
应用于多人模型时,将说话人嵌入向量添加进残差模块。
隐变量z可以理解为声学模型的输出。
PRIOR ENCODER
先验分布 $ p_\theta(z \mid c)$ ,$c=\left[c_{\text {text }}, A\right] $ 。
结构是transformer encoder + flow结构。transformer encoder目的是将文本变成提高维特征为 $c_{text}$ , flow目的是进一步变成复杂分布,提高分布的复杂度。
输入是文本,输出是先验分布。
先验编码器作用类似于声学模型,只不过 VITS 是将音素映射为中间表示 z 而不是频谱 。
应用于多人模型时,向标准化流的残差模块中添加说话人嵌入向量。
DECODER
$p_\theta(x \mid z)$。从隐变量z中生成波形。
应用于多人模型时,在说话人嵌入向量之后添加一个线性层,拼接到 $f_\theta$ 的输出隐变量 $z$ 。
DISCRIMINATOR
gan中使用,只用于训练阶段,推理不用。
STOCHASTIC DURATION PREDICTOR
基于flow。从条件输入 $h_{text}$ 估算音素时长的分布。
应用于多人模型时,在说话人嵌入向量之后添加一个线性层,并将其拼接到文本编码器的输出 $h_{text}$ 。
架构图:
VITS公式推导
出发点是 $P(z|x)$ 和 $Q(z|x)$ 的关系,注意这里是 $P(z|x)$ ,虽然 $P(x)$ 积分项里是和 $P(x|z)$ 有关。(数据x给定下的叫后验,求数据x的叫似然)。

发现这里的推导都是从kl散度出发,vae基础上加上条件变量c。
