seed-tts论文
Anastassiou, Philip, et al. “Seed-TTS: A Family of High-Quality Versatile Speech Generation Models.” arXiv preprint arXiv:2406.02430 (2024). citations:47
demo展示:https://bytedancespeech.github.io/seedtts_tech_report/
基于自回归的架构
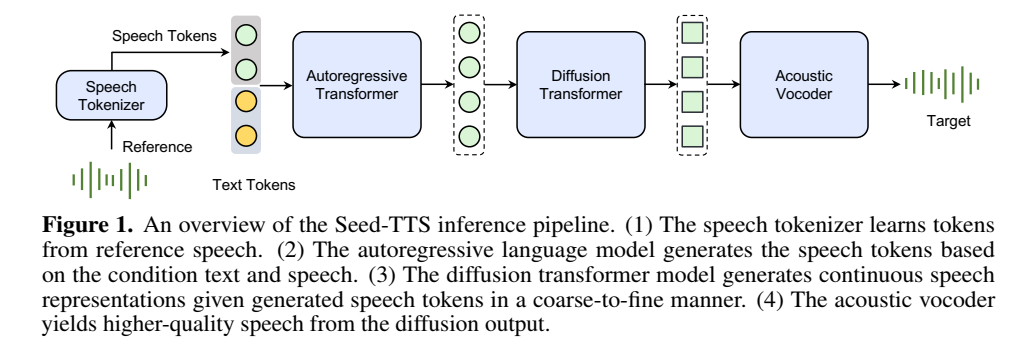
系统由四个主要构建模块组成:tokenizer语音分词器、自回归token语言模型、token扩散模型和声学声码器。
speech tokenizer:语音分词器将语音信号转换为语音token序列,设计tokenizer是最重要的;分为continuous and discrete speech tokenizers ;
autoregressive transformer:自回归transformer语言模型基于文本token和prompt语音token生成语音token,
diffusion transformer:扩散模型从粗到细生成连续的语音表示,增强声学细节,diffusion模型输入是语言模型output(speech tokens)
acoustic vocoder:声码器从扩散输出中预测最终的波形。
训练细节
- pre-training的数据量:比其他tts系统都大量的数据;
- 模块:vocoder分开训练
- 模型大小:比其他tts系统都大的模型;
- loss:侧重语音生成任务,没使用text序列loss
- 训练步骤:
- pre-training:覆盖尽可能多的场景和说话人;
- fine-tuning:分为speaker fine-tuning(enhancing performance for a selected group of speakers) 和 instruction fine-tuning(improve controllability and interactivity)
- post-training:基于RL;
适用任务
ICL(zero-shot speech in-context learning), controllable TTS, cross-lingual TTS, voice conversion, timbre generation, speaking style transfer
ICL:
ICL is defined as generating a novel spoken utterance with the same timbre and prosody as a short reference speech clip [Wang et al., 2018, 2023b, Zalán et al., 2022].ICL输入是音频片段prompt和text;
实现普通话和英语tts;
测量指标:1. 客观指标:wer、speaker similarity(SIM);2.主观指标:CMOS;结果中发现一致性导致与语音提示有更好的相似性,但导致长形式语音生成的韵律变化略少;
speaker fine-tuned实验,评估了zero-shot和5h说话人数据finetune结果;
用来生成asr数据用于asr任务;
Speaker fine-tuning (SFT) ,评估了zero-shot和10h说话人数据finetune
instruction fine-tuning :emotion controllability;
Low-latency inference and streaming processing :
减少延迟和首包延迟的方法:
- 使用因果diffusion架构;
- 使用一致性蒸馏方法,并修改了flow matching算法来减少diffusion模型的计算损失;
- 语言模型用的grouped-query attention、paged attention、flash attention、模型量化来减少模型内存和计算量;
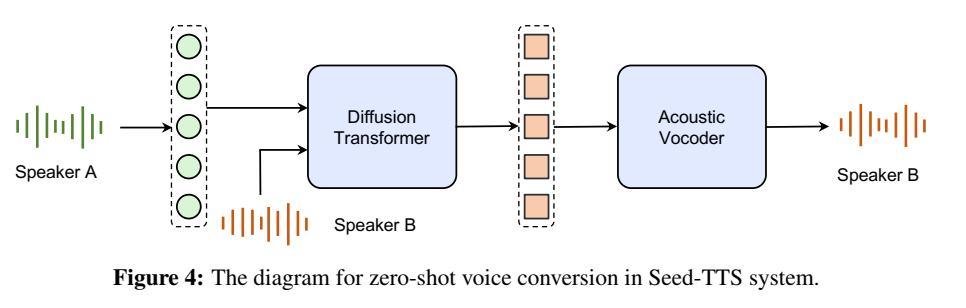
基于 self-distillation
self-distillation method designed to increase the controllability of timbre.
大多数先前的方法都是通过特征工程来实现属性分离的,提出一种基于自蒸馏的方法实现属性 disentanglement;
基于自蒸馏方法:训练集是构建了controlled speech pairs that share most information yet differ in one or a few specific target attributes. 小规模更新前文的基于自回归的模型;
训练细节:用seed-tts构造除了timber有小区别之外,其他(文本内容、韵律)都一样的音频pair;token网络的输入是生成的音频,送入diffusion模型的是token输出以及原始参考音频的timber reference,学习目标是原始参考音频,这样就强迫网络忽略token网络输出的音色信息;只记住参考音频的音色信息;
基于 reinforcement learning
Preference biasing through reinforcement learning
Direct Preference Optimization (DPO) can be extended to music and speech generation
基于外部的奖励的RL方法:比如近端策略优化proximal policy optimization、reinforce:允许对特定的语音属性进行明确控制
和不基于外部奖励的方法:比如直接偏好优化direct preference optimization(DPO):实现简单
基于 diffusion架构
研究发现额外的持续时间预测模型,会降低合成语音的自然性,因此这里的训练方法是模型会先估计出整条音频的时间;
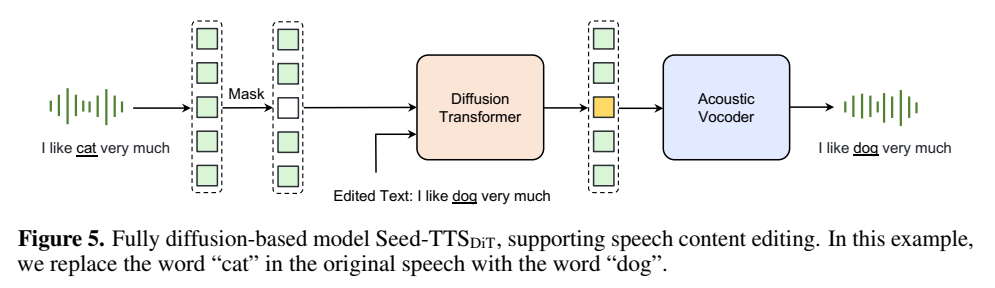
适用任务
- Content editing
- speaking rate editing
基于自回归生成方法优势:语音自然;劣势:不鲁棒;
基于diffusion生成方法优势:更细致建模,鲁棒;劣势:推理耗时,难以流式推理;