End-to-end object detection with transformers
Carion, Nicolas, et al. “End-to-end object detection with transformers.” European conference on computer vision. Cham: Springer International Publishing, 2020. citations:15472
目标检测背景
通常的目标检测是从一张图片中先生成很多个预测框,然后再对每个框进行物体类别分类。(可能在一个物体上不同坐标都有框,冗余),这个后处理步骤叫 nms(non-maximum suppersion非极大值抑制),用来去掉冗余的框。通常目标检测方法分为:proposal based和anchor based和non anchor based方法。
因为有nms后处理过程,非端到端,训练目标不等于最终目标,因此调参较为复杂。另外nms操作算子比较复杂,一些硬件可能不支持。
提出什么方法
在目标检测任务中提出一种端到端的方法DETR,把目标检测问题看成一个集合预测的问题,通过使用transformer进行全局建模,实现了集合预测,提出新的loss function叫set-based loss,通过二分图匹配 bi-partite matching,强制模型输出一组独一无二的预测(没有冗余框)
,一个物体只有一个框。
DETR的训练过程包括四步:特征提取、全局特征学习、预测框生成、匹配Ground Truth并计算目标检测loss,推理过程与训练相似,但不需要匹配loss,只保留置信度高的预测框(卡阈值)。
DETR模型通过卷积网络提取特征,加入位置编码后进入Transformer,经过6个Encoder和6个Decoder后,使用检测头进行物体类别和框的预测,最后通过辅助loss来稳定训练。
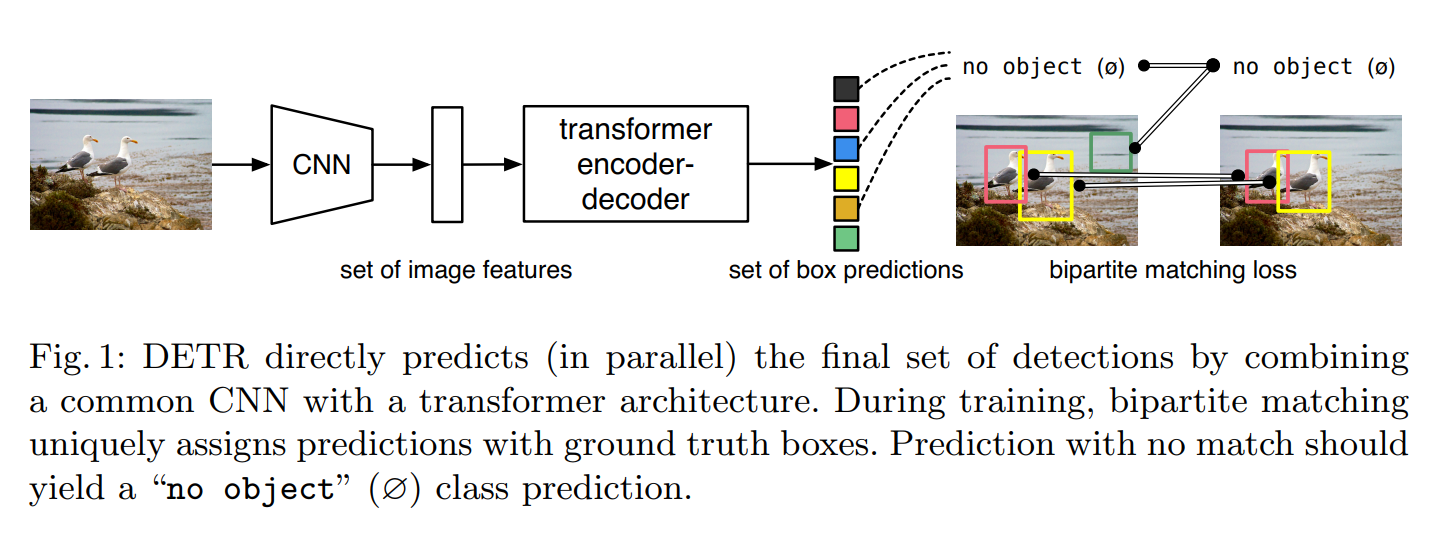
set-based loss:
二分图匹配 bipartite matching 问题是DETR模型关键解决方案之一,通过匈牙利算法实现最优匹配,解决预测框和真实框之间的对应关系,进而计算损失。
假定每张图片都有固定N个框,因此要预测N个结果,N比图片中的物体objects数量多。$\varnothing$表示没object,
$$
\hat{\sigma}=\underset{\sigma \in \mathfrak{S}N}{\arg \min } \sum_i^N \mathcal{L}{\text {match }}\left(y_i, \hat{y}_{\sigma(i)}\right)
$$
给abc分配不同的xyz,不同排列组合对应不同的总cost,任务是使得cost最小;(scipy :linear_sum_assignment() )
把abc看成预测框,xyz看成groundtruth;里面的cost是预测框的分类准确度+出框的准确度
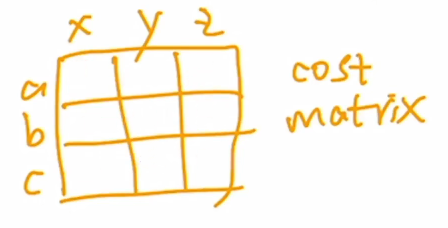
$$
\mathcal{L}{\text {match }}(y, \hat{y}{\sigma(i)})=-\mathbb{1}{\left{c_i \neq \varnothing\right}} \hat{p}{\sigma(i)}\left(c_i\right)+\mathbb{1}{\left{c_i \neq \varnothing\right}} \mathcal{L}{\text {box }}\left(b_i, \hat{b}_{\sigma(i)}\right)
$$
$$
\mathcal{L}{\text {Hungarian }}(y, \hat{y})=\sum{i=1}^N\left[-\log \hat{p}{\hat{\sigma}(i)}\left(c_i\right)+\mathbb{1}{\left{c_i \neq \varnothing\right}} \mathcal{L}{\text {box }}\left(b_i, \hat{b}{\hat{\sigma}}(i)\right)\right],
$$
这篇文章给出强假设:只有一个框和ground truth相匹配(其他目标检测一般可以多个框和ground truth匹配,也因此还需要nms后处理)。
用transformer学习到全局特征,对大物体很有效(作者认为这归因于使用全局建模和不采用Anchor机制),经常预测大框,loss就很大,不利于优化,因此使用了generalize IOU loss和L1 loss的组合,使得匹配更精确,优化效果更好。
DETR模型训练的细节,包括在Decoder后加入辅助loss来稳定训练、Object Query的自注意力操作(学习全局关系来避免冗余框)
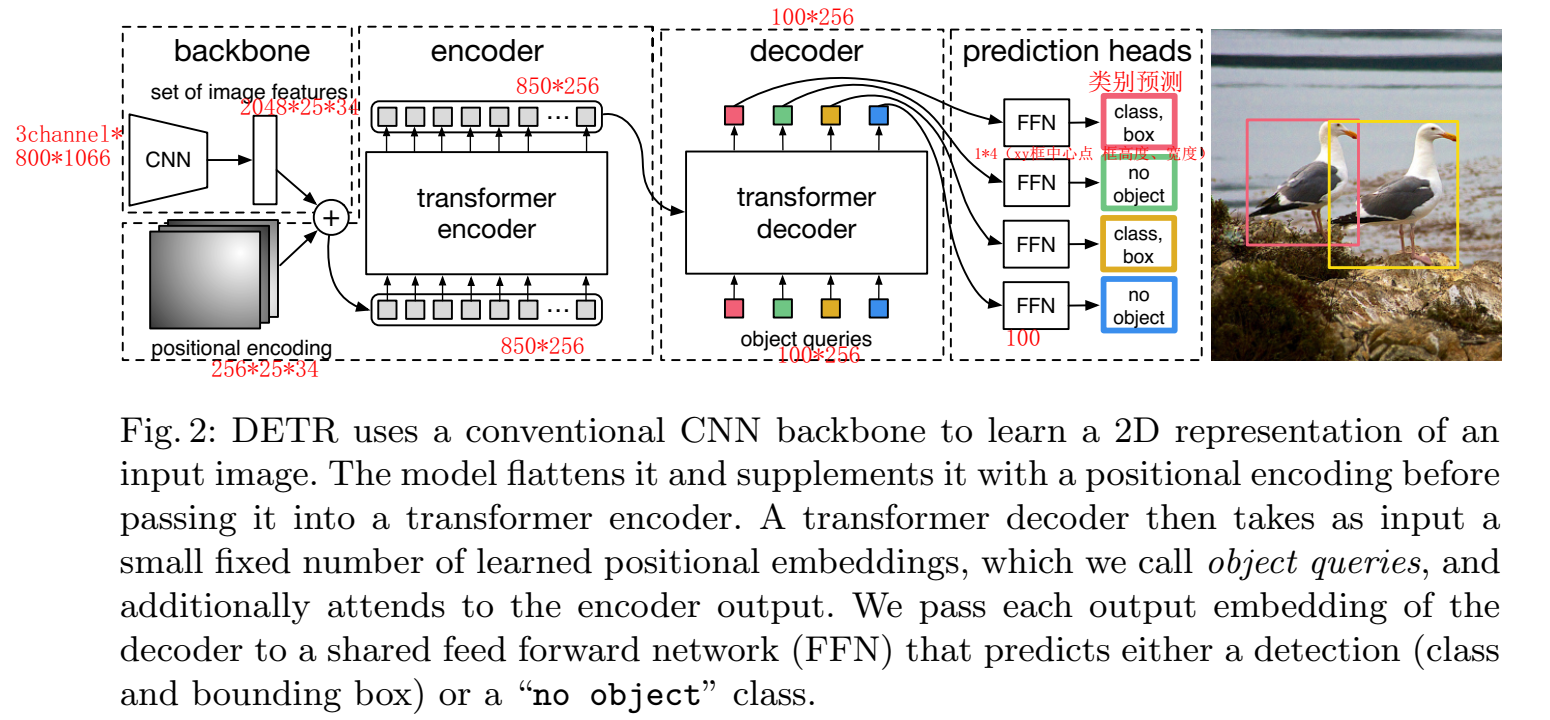
object queries : learnable 的 positional embedding

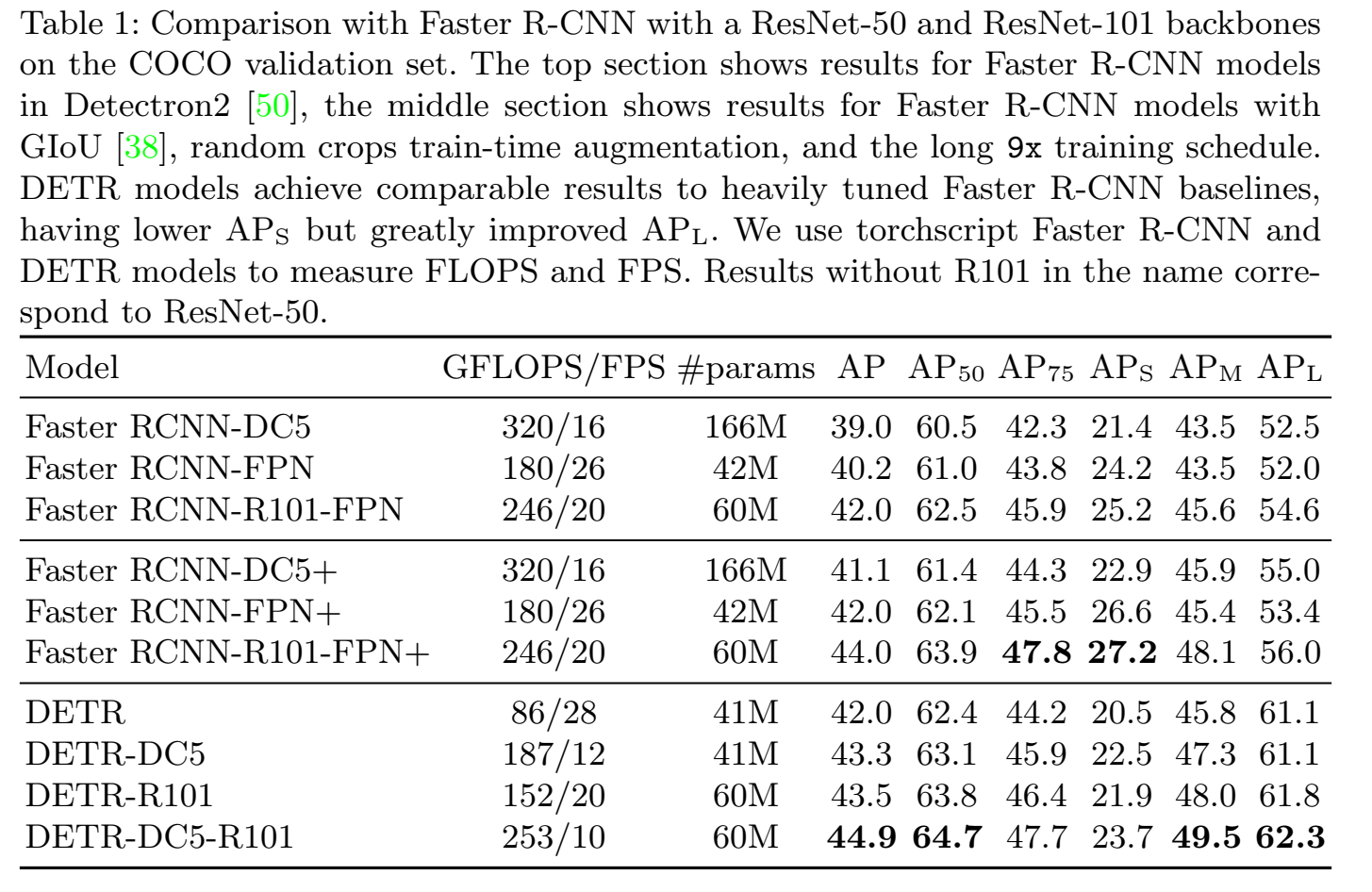
GFLOPS(每秒浮点运算数)越小,模型浮点运算量少 一般来说前向运算时间会越短,但是这个并不完全相关,还是得看FPS(单位时间能处理的帧数),FPS越大模型前向速度越快,处理图片的速度越快。
Object query的可视化展示了学习到的bounding box,object query是一个[100, 256]的张量,每个是256向量,取100中的20个向量可视化如下图,每个小图代表一个object query:
绿色点代表小bounding box,红色点代表横向bounding box 蓝色点代表竖向bounding box,这就很像anchor,只不过anchor是先验定义好的bounding box(预测与bounding box做对比),而object query是可学习的,最终起到的效果和anchor很类似,以第一个小图为例,它关注左下角的小bounding box,因此对于input图片,经过该object query时,就等同于该object query问这张图片的左下角有没有看到一些小物体,或者说有没有看到中间有大的横向物体;100个object query等同于100个问问题的人,每个人都有问问题的方式,关注的侧重点都不同,会问图片不同的问题,如果找到了合适的答案,就会输出bounding box;
