Megatron
Shoeybi, Mohammad, et al. “Megatron-lm: Training multi-billion parameter language models using model parallelism.” arXiv preprint arXiv:1909.08053 (2019). citations:1837
解决什么问题
提出什么方法
提出一个方法,将transformer层从中间剖开,使得多GPU计算时每一个GPU计算重建的一块。好处是剖起来容易(按head的个数/中间隐藏层大小剖开(在层里面切开))ps. gpipe是在层之间切;
存在问题:1. 通讯量很大,并且不能和计算做异步,因此要求GPU之间连接要很好(Nvlink);
- 不能扩展到多机(多机要数据并行)
- GPU变多,冗余变多,因为输入输出都要在GPU上存放一遍;
张量并行
mlp结构模型并行(放在多个GPU上运行不同参数)的切法:
- 第一种:对于权重张量A来说,A维度是 $kk’$,假如有2个GPU,沿着行切,每个个GPU放$\frac{k}{2}k’$ 的参数,则输入X(维度$blk$)也要切分,沿着列切,每个GPU的计算量是$bl\frac{k}{2}*\frac{k}{2}*k’$,然后再求和(all reduce),求和操作需要GPU之间进行通讯。
GPU之间需要通讯(比如做求和)才能获取完整的输出结果的操作叫all reduce
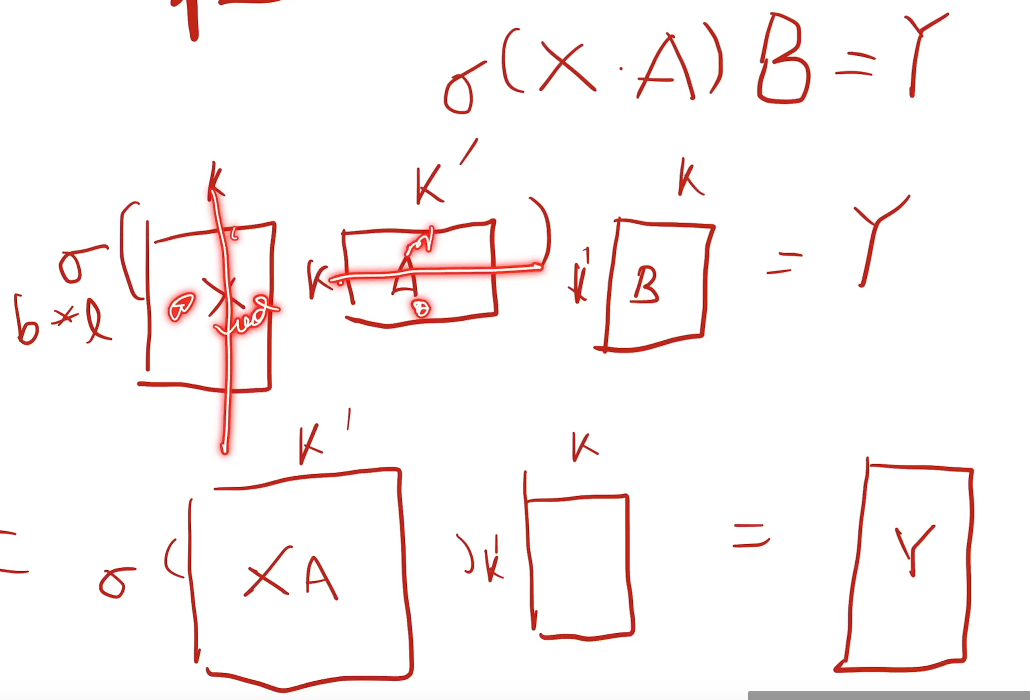
- 第二种:A沿着列切,参数分给不同GPU,则输入X在各个GPU都要复制一份,然后得到输出Y,不需要GPU之间进行通讯,各自保留了一块的结果,就直接输出X*A了。
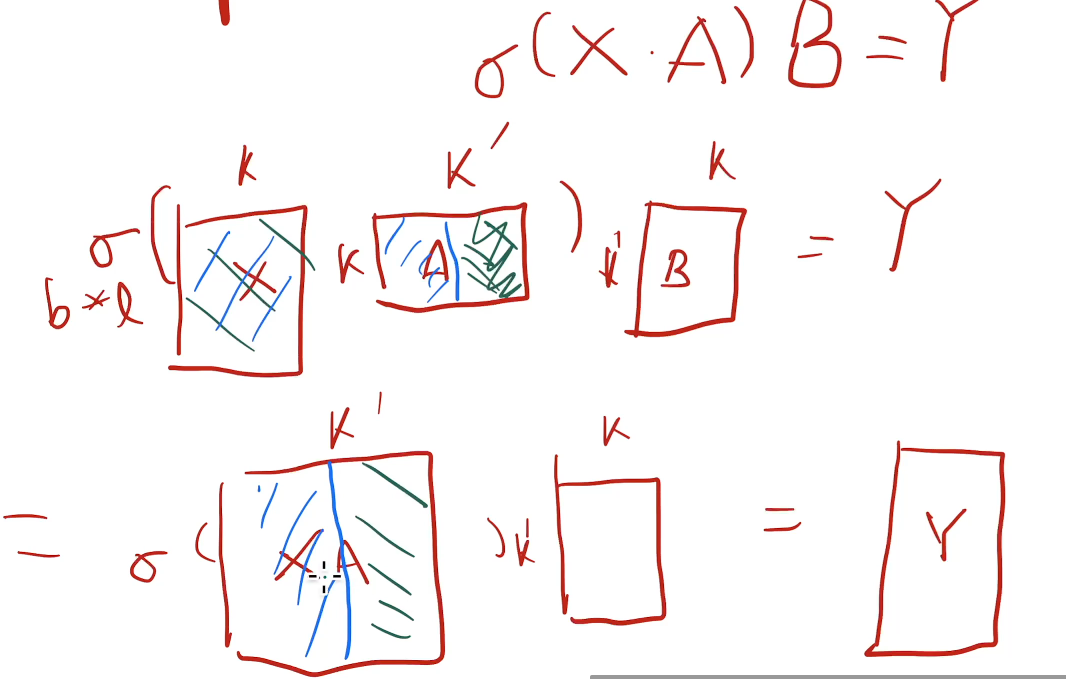
mutli-head attention结构的模型并行:
不同head放不同gpu;如果head很多则一组head放一个GPU。
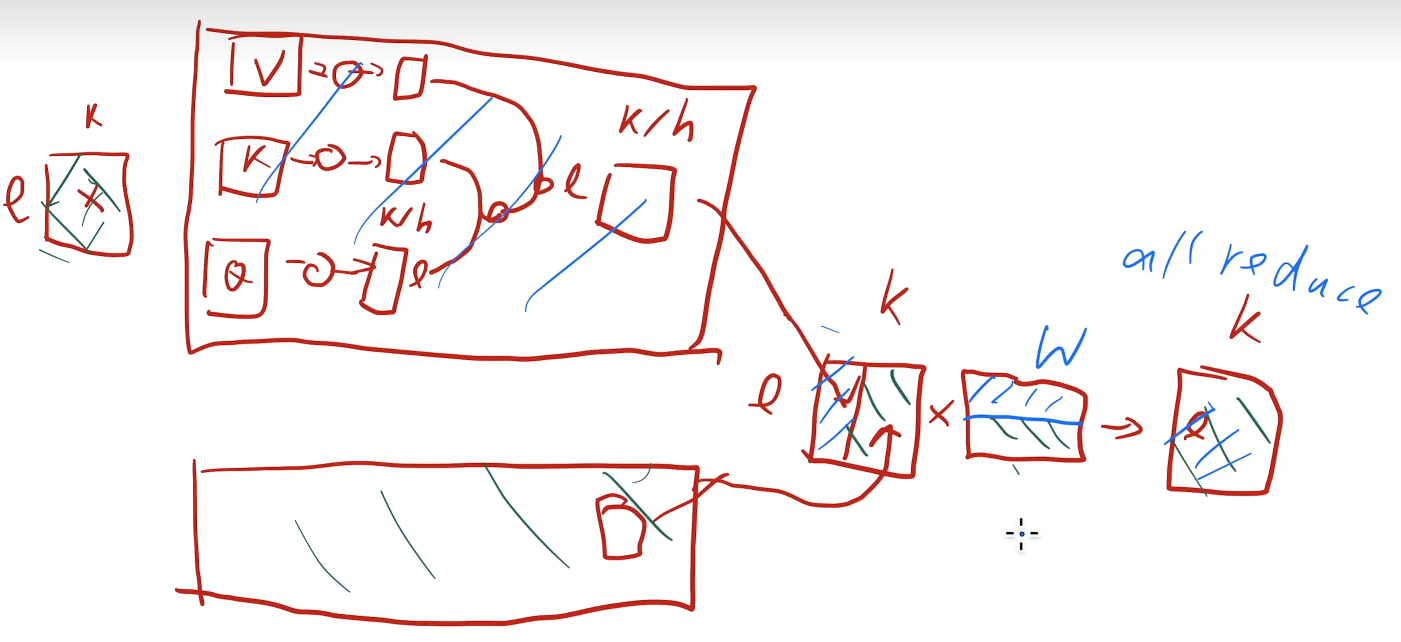
to be continue