GPipe
Huang, Yanping, et al. “Gpipe: Efficient training of giant neural networks using pipeline parallelism.” Advances in neural information processing systems 32 (2019). citations:1695
开源项目:https://github.com/kakaobrain/torchgpipe
github:https://github.com/tensorflow/lingvo/blob/master/lingvo/core/gpipe.py
用了什么方法
- 提出流水线并行方法,在对数据切分(和数据并行的思路一样)能提升并行度;模型并行,可用在任意串联、堆叠起来的网络结构中;
- 通过re-materialization方法,支持训练更大的模型,但是需要额外付出20%的开销;
re-materialization:训练时把一些中间结果丢掉,下次用到时重新计算,可以减少内存的占有率。
micro-batches
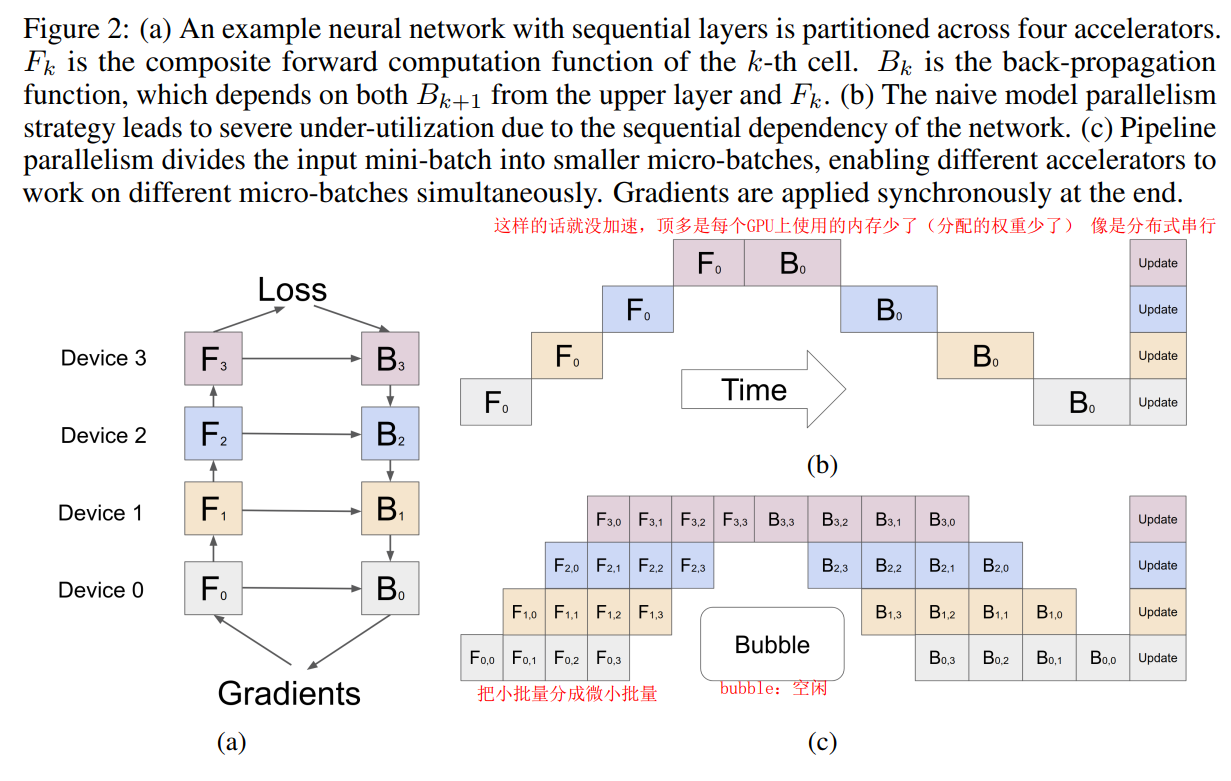
model parallelism:多层模型拆成多个层放到不同gpu上,每个gpu只执行一部分计算,就把计算结果传输给下一个gpu再计算;
data parallelism:模型复制放在每个gpu上,batch样本分成子batch分到不同gpu上做前向和保存梯度值。因为每个GPU上复制一份,保存整个模型开销大;
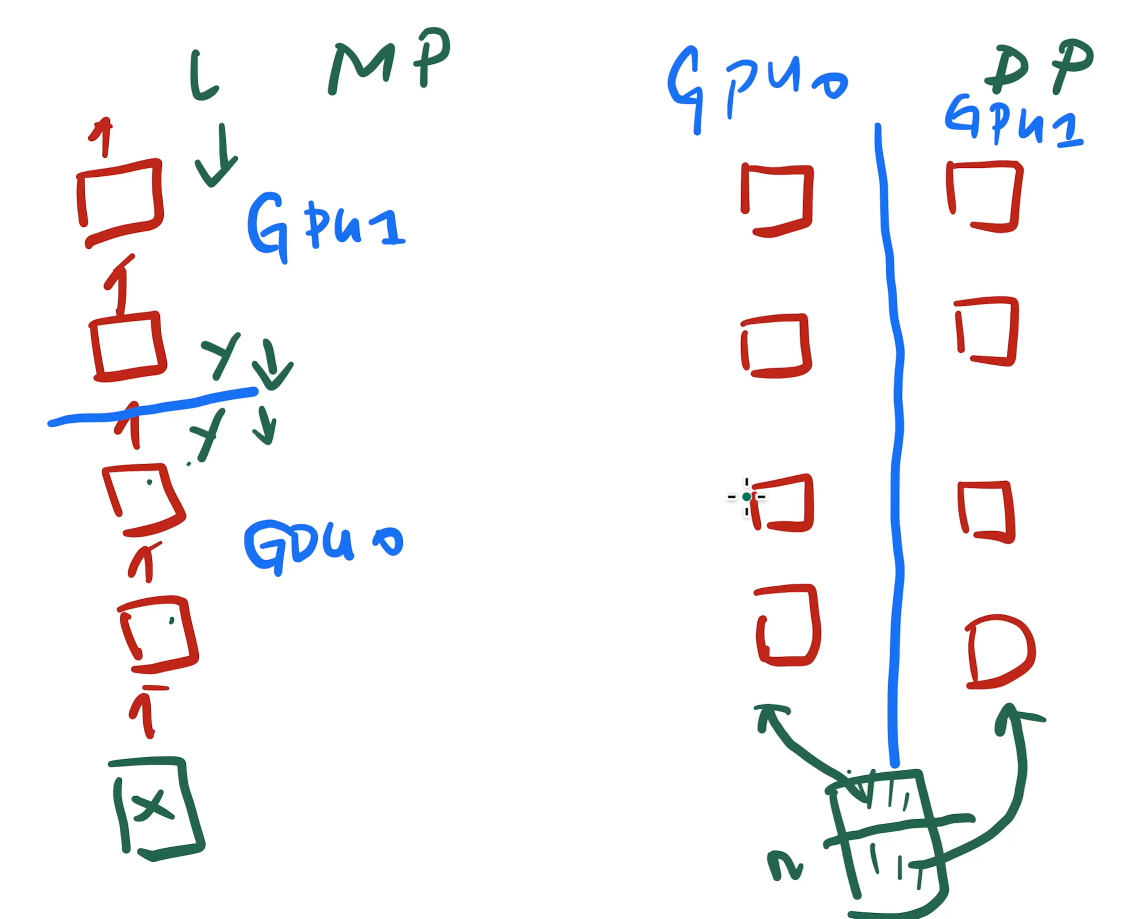
activation :指的不是激活函数,而是中间变量,前向每层的输出值,由于反向传播是链式,所以需要存储这些中间值。因此这些activation占用的内存为 $O(ldn)$ ,l是层数,n是batch大小,d是网络宽度;
用re-materialization,因此这里 $l$ 为$\frac{l}{k}$ , k是gpu数;用微批量,因此这里 $n$ 为 $\frac{n}{m}$ ,m是切的小批量数(微批量),流水线指令的长度;
存储这些activation 内存占用会增加,可以用时间换空间的方法,也就是前向计算后,就把这些中间变量删掉 释放内存,由于是用的微批量的方法,等到微批量样本累积到一个批的loss值,需要反向传播时,再进行一次前向计算得到activation;(所以要计算两次forward(可能会带来30%额外开销))
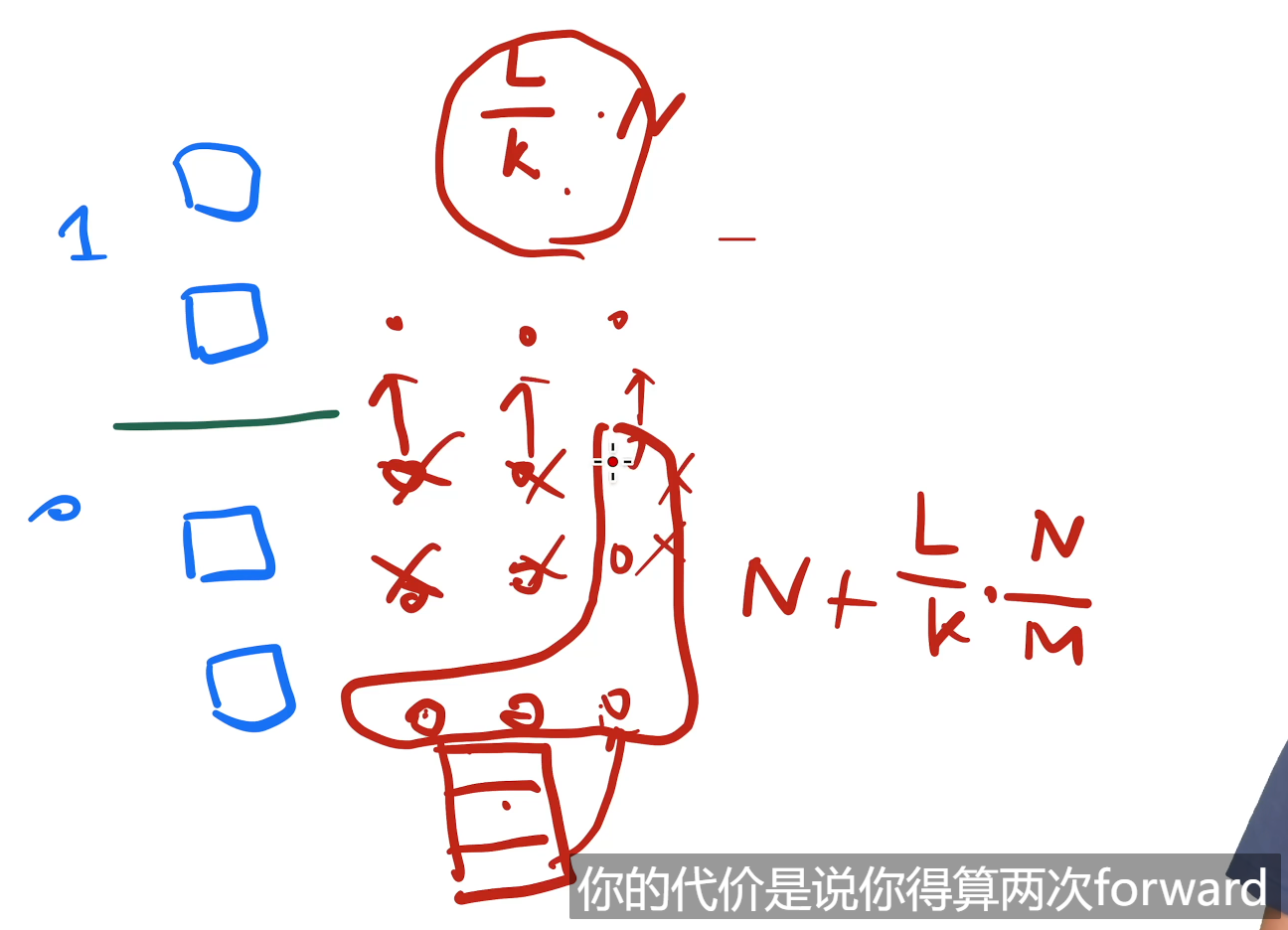
$O(\frac{K-1}{M+K-1})$ , 当 $M\ge4K$ 开销忽略不计