参数服务器
Li, Mu, et al. “Scaling distributed machine learning with the parameter server.” 11th USENIX Symposium on operating systems design and implementation (OSDI 14). 2014. citations:2259
李沐 参数服务器(Parameter Server)逐段精读【论文精读】
https://www.usenix.org/conference/osdi14/technical-sessions/presentation/li_mu
osdi 系统会议
解决什么问题
在大规模分布式环境中有效地进行机器学习任务,通过参数服务器框架来扩展分布式机器学习。
该问题的研究难点包括:数据通信量大、计算负载高、算法的顺序性导致的性能瓶颈。网络带宽的利用;对于大规模数据量、大模型参数量的模型训练时,所有计算节点都要频繁的访问模型参数,有大量的网络通讯耗时;
机器学习算法要不断的做全局通讯;bacth逐iter计算,导致大量的全局的同步会影响性能。
容灾 fault tolerance,挂掉的那台机器能1s恢复,在大规模环境下的容错性和可扩展性。
用了什么方法
- 提出参数服务器,提供有一个机制,有效的汇聚和同步计算节点和节点之间的统计信息;
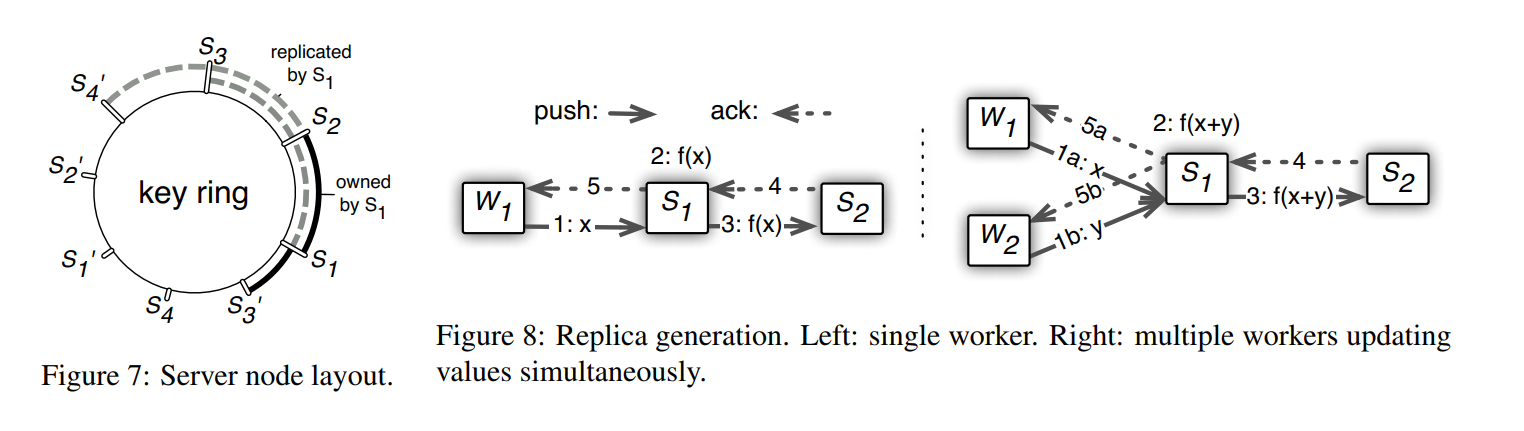
- 容灾用的vector clocks 向量钟,方法是做实时的复制,使得一台节点挂了,数据在另一地方还有;热备份机制,确保在节点故障时系统的连续性和一致性。
- 易用性: 全局共享参数以稀疏向量和矩阵的形式表示,便于线性代数操作。
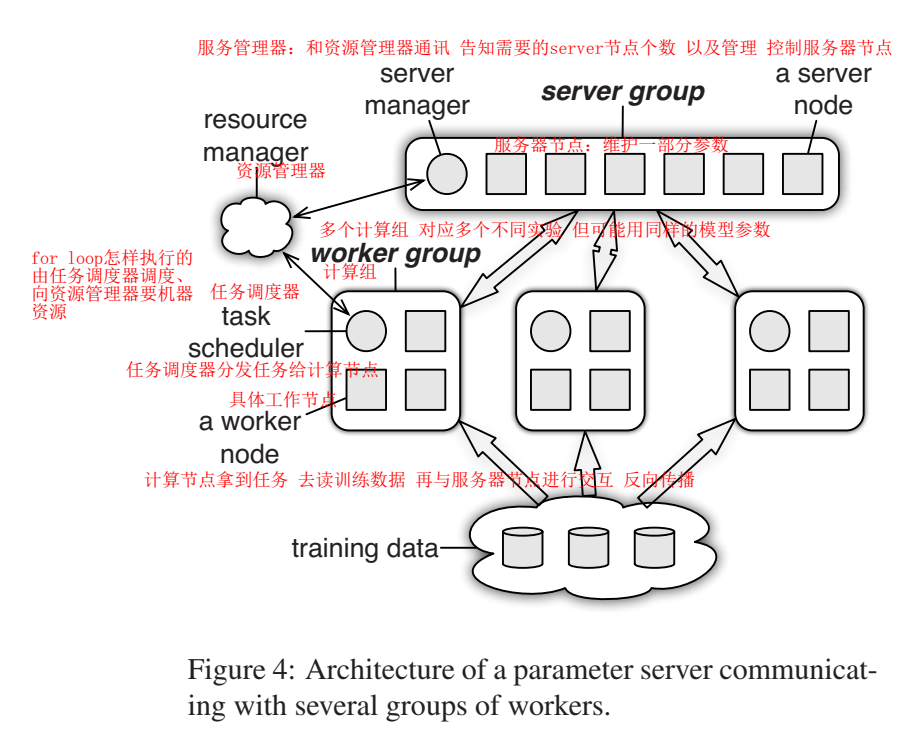
服务节点 server node :维护全局共享参数的一部分。参数量大时,由多台机器维护;
计算节点 worker node :拿参数的一块或全部,再读入一些数据进行计算;
其中的挑战:计算节点不断向服务节点要数据,有传输开销;在分布式系统中可以解决这个问题,叫做分布式的key value,但是这里的key一般是指向某一个神经元参数,这样参数量上来后,开销太大了,要开辟太多的key;本文用的segment,发送一个层的参数
节点就是进程
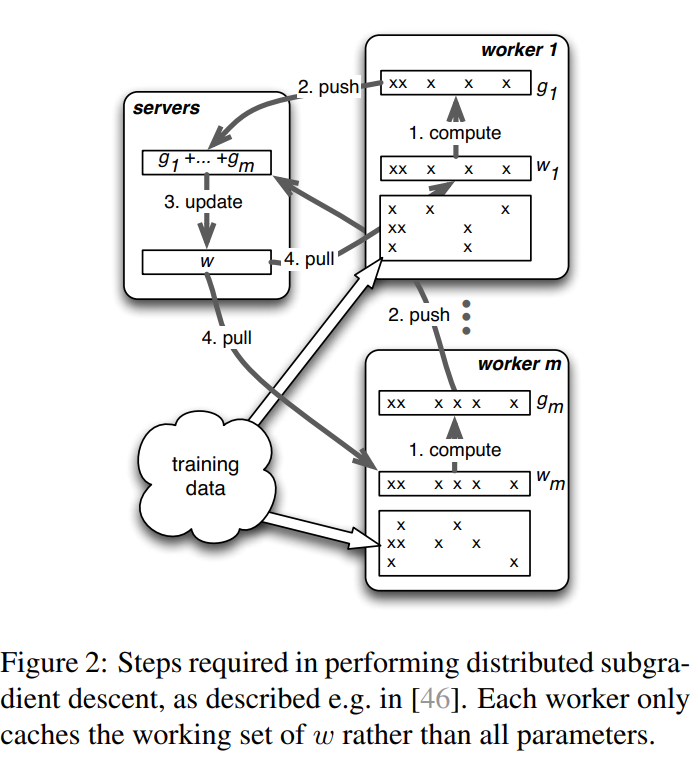
这个伪代码意思是 有m个计算节点,每个节点分配了一部分的计算权重,然后计算每个节点的梯度;然后服务节点在不同时刻汇总梯度 进行梯度更新;这里写的很简单;

计算流程: 一个框是一个节点(进程)
异步通信模型:参数服务器框架采用异步通信模型,允许计算不阻塞(除非请求)。这种模型优化了机器学习任务的通信,减少了网络流量和开销。
(key, value) vector:key是w的下标 不连续 稀疏的 哈希出来的值,int整型;value:浮点数/向量(一串浮点数)/一层的w;
带区间的 range push and pull:push是把梯度push回server节点;pull是把weight pull回来;只把部分的(key, value)发出去;这样可以节省带宽,不用把所有的weight都传输;
server端,user-defined functions
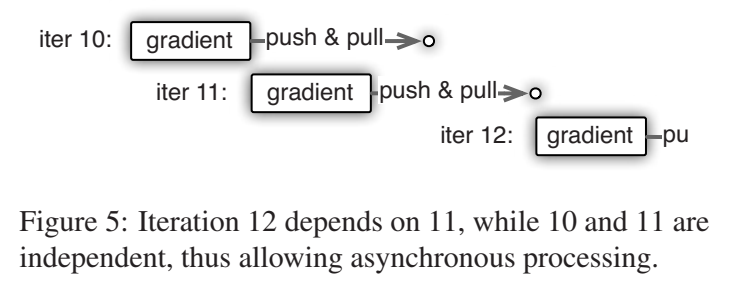
asynchronous tasks and dependency 就是网络前向如果计算也是直接串行的,那其实没怎么节省时间,所以任务要异步,计算节点计算完了就去计算其他的,没有一个等待的过程;。。。
但是任务之间有依赖怎么办,这里用了execute-after-finish 完成后才执行
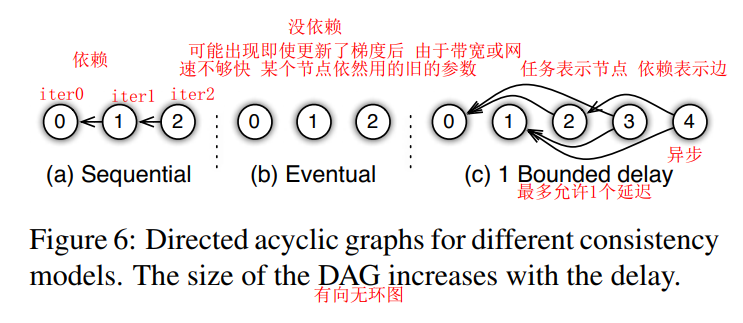
灵活的一致性模型:框架支持灵活的一致性模型,允许算法设计师在算法收敛速度和系统效率之间进行权衡。一致性模型包括顺序一致性、最终一致性和有界延迟一致性。

vector clock:需要记录不同计算节点上维护的是哪些权重,记录下是哪个时间算好的值;
减少网络通讯时延:对服务器节点和计算节点做压缩,压缩后再通讯,再解压缩。
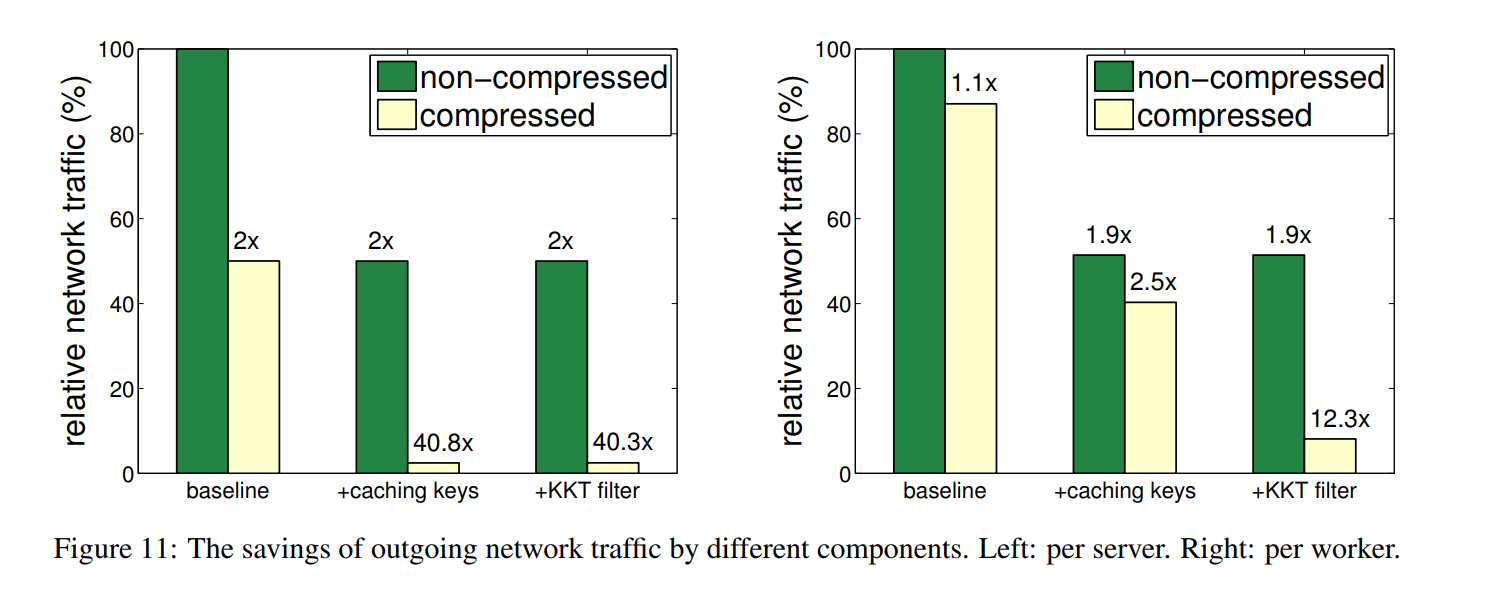
这里KKT filter:算权重的KKT。(KKT:凸函数中离最优解的距离),如果weight与kkt值接近,认为优化得很好,则不太更新了,梯度=0,好压缩。
实验中有可能哪些是瓶颈:1.网络通讯带宽;2.cpu核数;3.内存带宽,内存访问速度,server端读写的速度慢;
参数服务器(Parameter Server)是一种分布式机器学习系统中常见的架构组件,主要用于存储和更新模型参数。在训练大型机器学习模型时,尤其是深度学习模型,由于数据量和模型复杂度的增加,单机训练往往无法满足需求。因此,研究者们提出了分布式训练的方法来加速模型训练过程。
参数服务器架构一般包含两个主要部分:
- Worker节点:负责计算梯度。每个Worker节点会接收到一部分数据集,并根据当前的模型参数进行前向传播计算损失函数,然后通过反向传播计算出参数的梯度。
- Server节点(参数服务器):负责存储模型参数,并收集来自各个Worker节点的梯度更新。它会根据这些梯度信息来更新模型参数,并将最新的参数广播给所有Worker节点。
参数服务器的工作流程大致如下:
- 初始化阶段,参数服务器初始化模型参数。
- 训练过程中,各Worker节点从参数服务器获取最新的模型参数,使用本地的数据子集计算梯度,并将梯度发送回参数服务器。
- 参数服务器接收到梯度后,执行参数更新操作(如应用随机梯度下降算法),并将更新后的参数同步给所有Worker节点。
- 这个过程不断重复,直到模型收敛或达到预定的迭代次数。
参数服务器架构能够有效地支持大规模分布式机器学习任务,但它也存在一些挑战,比如网络延迟、通信成本、容错性等问题。随着技术的发展,出现了许多改进版本,如异步更新机制、稀疏梯度传输等,以提高系统的效率和性能。