CLIP
https://arxiv.org/abs/2103.00020
Radford, Alec, et al. “Learning transferable visual models from natural language supervision.” International conference on machine learning. PMLR, 2021. citations:23716
解决什么问题
学一个泛化性很好(不局限于要做的固定类别数的分类任务)的特征;
用了什么方法
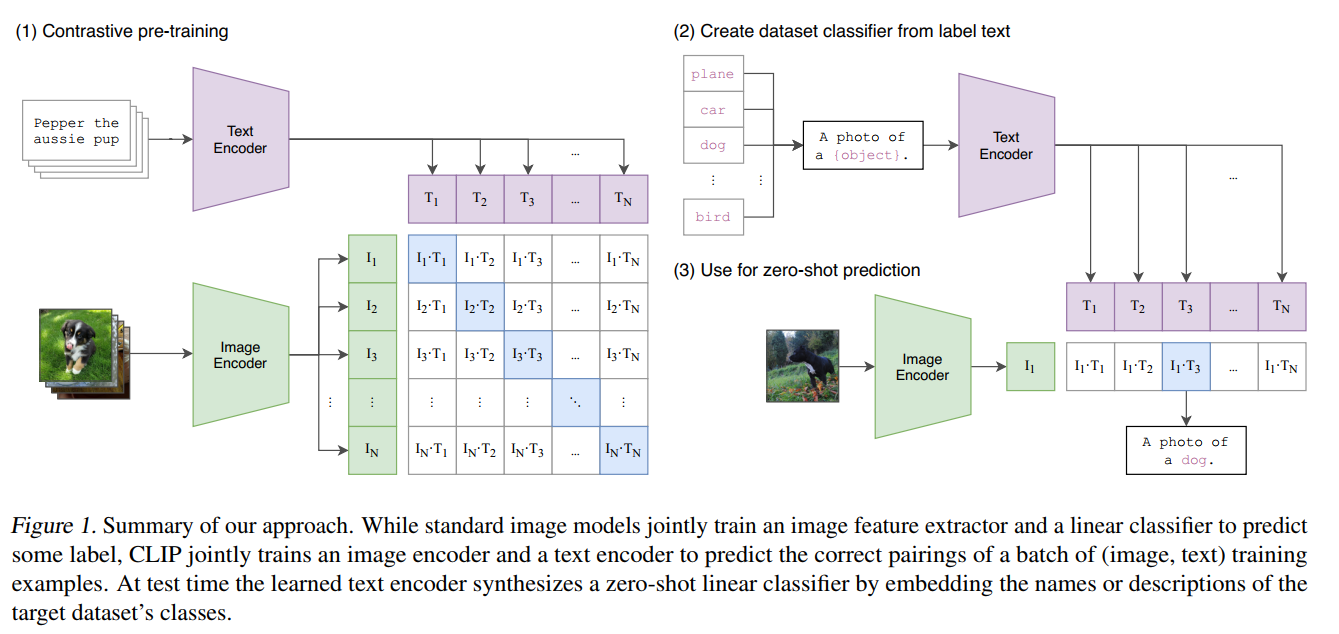
图片的embedding和文本的embedding做对齐,在空间中配对的embedding很接近,不配对的embedding不接近,这样后续即使对于没见过的类别样本zero-shot,也可以通过去查看embedding相似度,找到相似度最大的一个类作为分类结果;
用了4亿张图片(image, text) pair做自监督训练(没有特别指定要做什么任务,固定类别数的任务);多模态的对比学习;完成训练后,自然语言作为prompt引导模型做视觉分类;
效果如何
开启了cv新范式,之后很多cv论文都是基于CLIP的思路,结合自然语言处理,也就是文本内容去做的。
在30个cv任务上做zero shot看迁移效果,大部分任务效果都很好,能和有监督训练效果相当;
还有什么不足
对于完全没见过的领域数据,泛化性依然不好;在接收one-shot、few-shot样本下,效果没有zero-shot效果好,和人类的学习训练方法还是有区别。
推理过程:图片经过训练好的图片编码器得到图片特征;有一些感兴趣的标签经过prompt engineering会变成一个句子(“a photo of plane/car/dog… ”)比如4个句子,然后经过text encoder得到4个文本特征,然后与图片特征计算cos similarity;后接softmax得到argmax的文本,大概率也就是描述这个图片的文本了。
nlp之前不是很好学,直到deep contextual representation learning兴起,也就是具有上下文语义环境的的学习方式,比如bert的完形填空,自监督的学习范式兴起,nlp终于可以用大量的文本监督信号了。
图片和文字绑定到一起,因此学到的特征是多模态的特征,很容易做zero-shot的迁移学习。(而如果只做单模态的自监督学习,单模态对比学习,比如MOCO,或单模态掩码学习,MAE,只能学到视觉特征。)
作者做了一个数据集,4亿个样本,图片文本对 叫WIT (WebImageText)
多模态预训练 训练起来非常耗时,因此要做很多提高训练效率的工作。
一开始的方法:图像用cnn结构,文本用transformer结构,jointly trained联合训练,目标是预测图片的caption,也就是图片的文本。用的方法不是gpt那样的预测任务(预测下一个单词),而是用对比学习的方法。只要文本和图片配对就行。把预测型的目标函数换成对比型的目标函数,训练效率一下子提高4倍。之所以用对比学习,就是因为能提高训练效率。


最后用的线性仿射层,但是其他纯训单模态的都是用非线性仿射层。作者说线性和非线性在多模态预训练里不会有太大区别。
对比学习里temperature是个非常重要的参数。作者不想手调,把temperature作为可学习参数放到训练里。
zero-shot transfer
之前的预训练模型的目的是学习泛化性好的特征,然后用到下游任务上,还需要下游数据finetune。如何能够训练一个模型,下游任务能够不用再训练和微调了呢?:
用文本作为引导(prompt),做zero-shot 迁移学习
使用prompt的优势:
- 假如只用一个单词、不用prompt的话,会引入多义性,歧义的问题,同一个单词有不同的意思,没有语境无法判断出是哪一个意思。
- 训练预训练模型使用的是句子,推理如果只有单词,会存在distribution gap的问题
可以用prompt template提示模板 “A photo of a {label}” 比如下游任务是1000个类的imagenet,这里label就填入这1000个类。
ensemble:多用一些提示模板,做多次推理,综合结果,一般能取得更好的结果。
图片中有可以描述出来的物体,对应文本中应该也有这个物体的描述,匹配得就好;反之图片中没有可以描述出来的物体的话,CLIP表现就不好;
baseline用的是在imagenet训练好的resnet50,用 linear probe 在下游任务上(冻住参数,用作特征抽取器,额外加一个linear,只finetune这个linear层)(few shot)
之所以不用finetune,因为finetune可调的参数太多了,即使一个一般的预训练模型,可能最后也会有不错的效果;
clip在zero-shot、few shot、全量数据集效果都很好。