Predicting Multi-Codebook Vector Quantization Indexes for Knowledge Distillation. 多码本向量量化索引的知识蒸馏
Guo, Liyong, et al. “Predicting Multi-Codebook Vector Quantization Indexes for Knowledge Distillation.” arXiv preprint arXiv:2211.00508 (2022). 郭理勇
微信公众号 新一代Kaldi: 新一代 Kaldi 中基于量化的蒸馏实验
相关代码:https://github.com/k2-fsa/multi_quantization.git
相关代码:https://github.com/k2-fsa/icefall/tree/master/egs/librispeech/ASR/pruned_transducer_stateless6
b站视频:姚增伟 【语音之家】AI产业沙龙—如何应用k2开发语音识别系统 或 https://xjw.h5.xeknow.com/sl/2yOtKa 22分钟起
D:\typora\typora笔记\语音\k2\视频 基于多码本向量量化的蒸馏方案.md
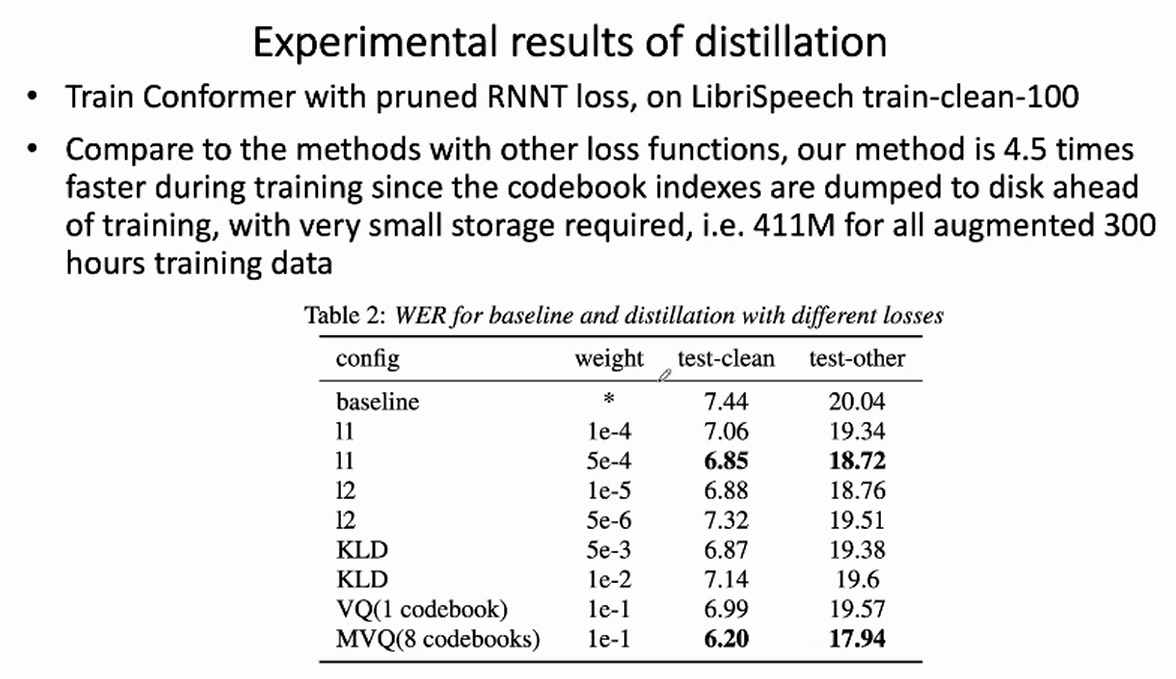
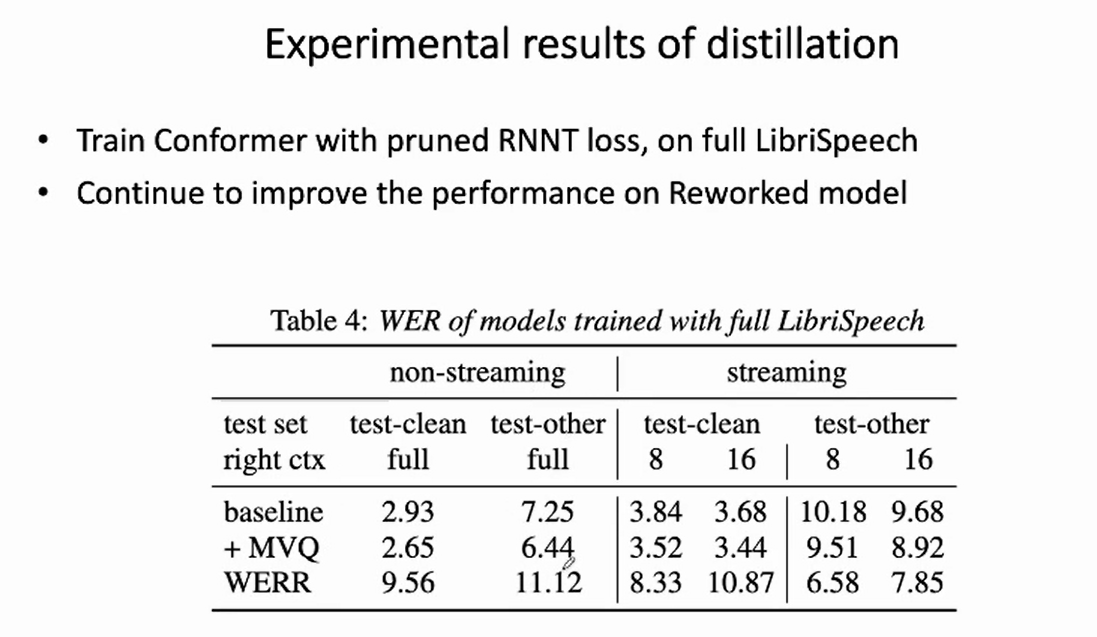
Traning overhead 几乎可以忽略不计的新型蒸馏框架
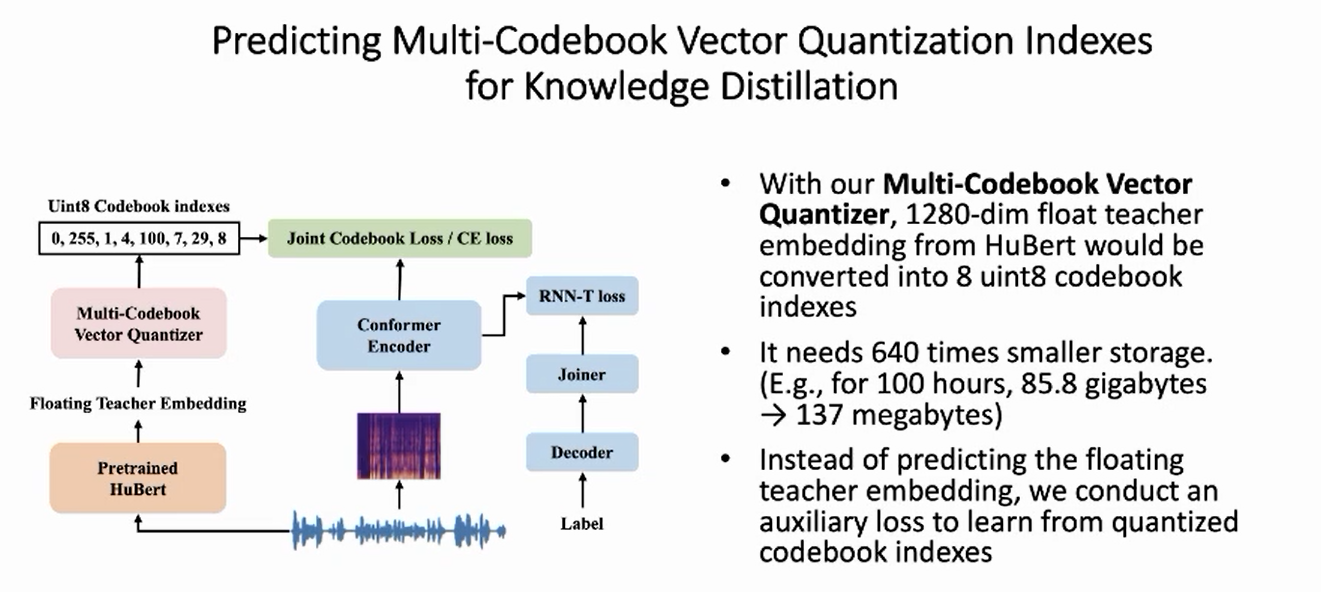
量化过程:
embedding vector里面的值不再是浮点数,而是码本的index,然后用的是8个码本的index来表示一个1280维的embedding vector,,因此有8个index,然后根据是哪个index,从codebook table里把index对应的值取出来,然后把值求和。

分治,现在每个码本是独立的,然后固定后3个码本(2、3、4),选出能让重建误差最小的第1个码本的其中两个index(重建误差最小和次小,top2),然后固定1,3,4码本,选出能让重建误差最小的第2个码本的top2的index;然后固定1,2,4码本,选出能让重建误差最小的第3个码本的top2的index;然后固定1,2,3码本,选出能让重建误差最小的第4个码本的top2的index。于是每个码本都留下了2个index。
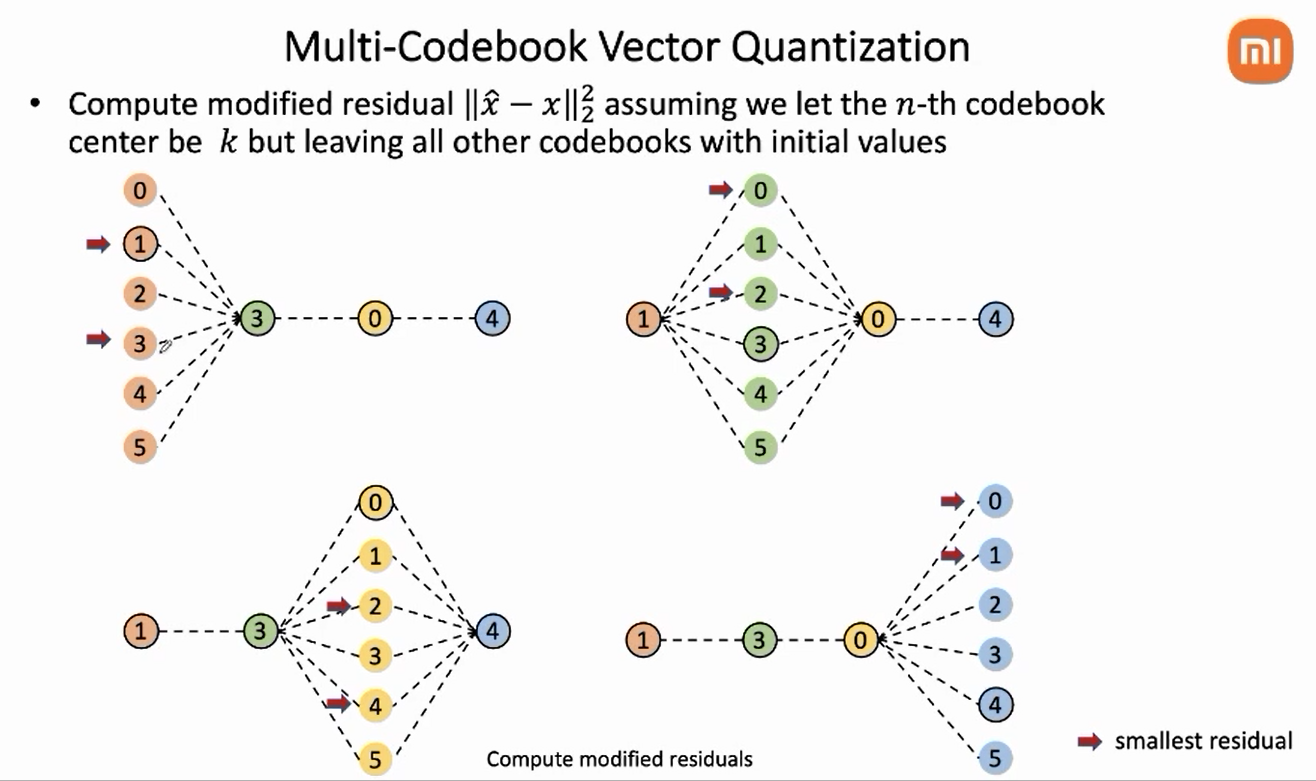
分治,合并子问题。
固定3,4码本,选出能让重建误差最小的第1、2个码本的top2的index(index连接有4种可能);然后固定1,2码本,选出能让重建误差最小的第3、4个码本的top2的index(index连接有4种可能)
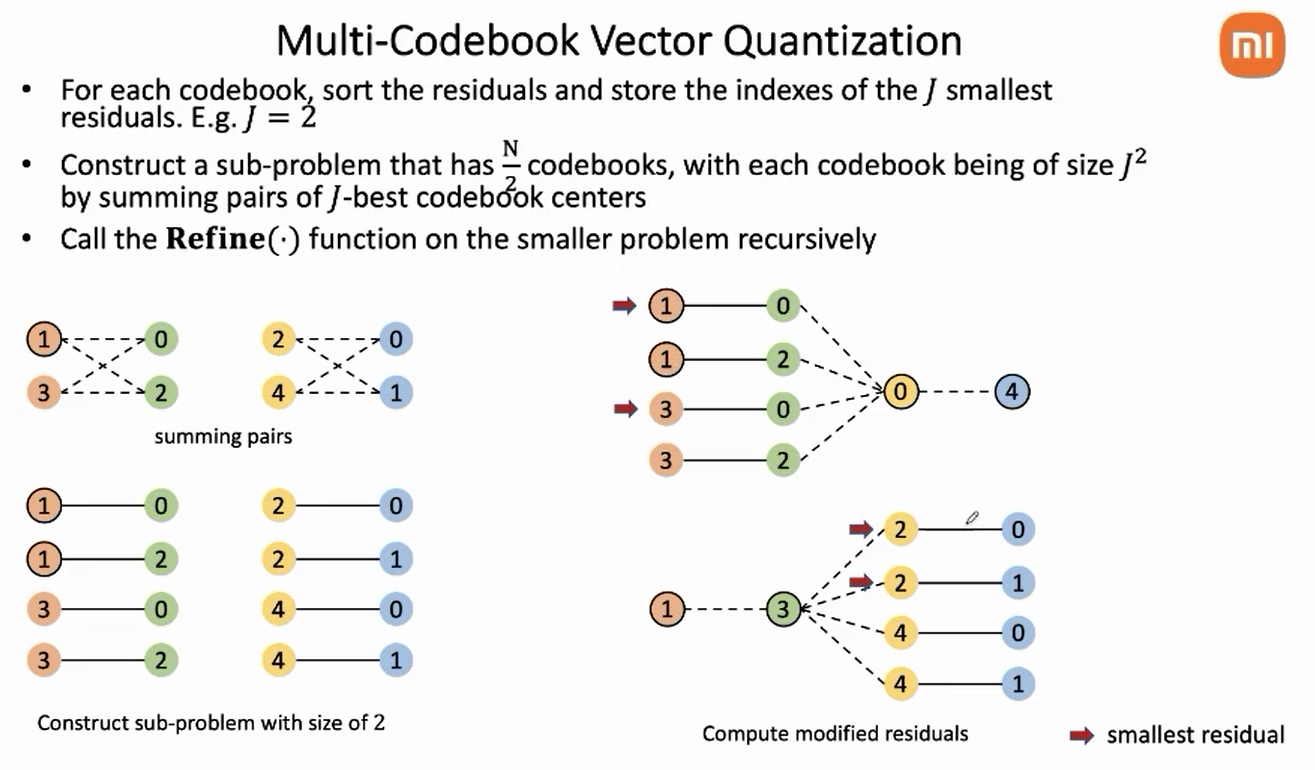
分治,再次合并子问题,固定1,2,3,4码本??,选出能让重建误差最小的top1的index(index连接有4种可能)
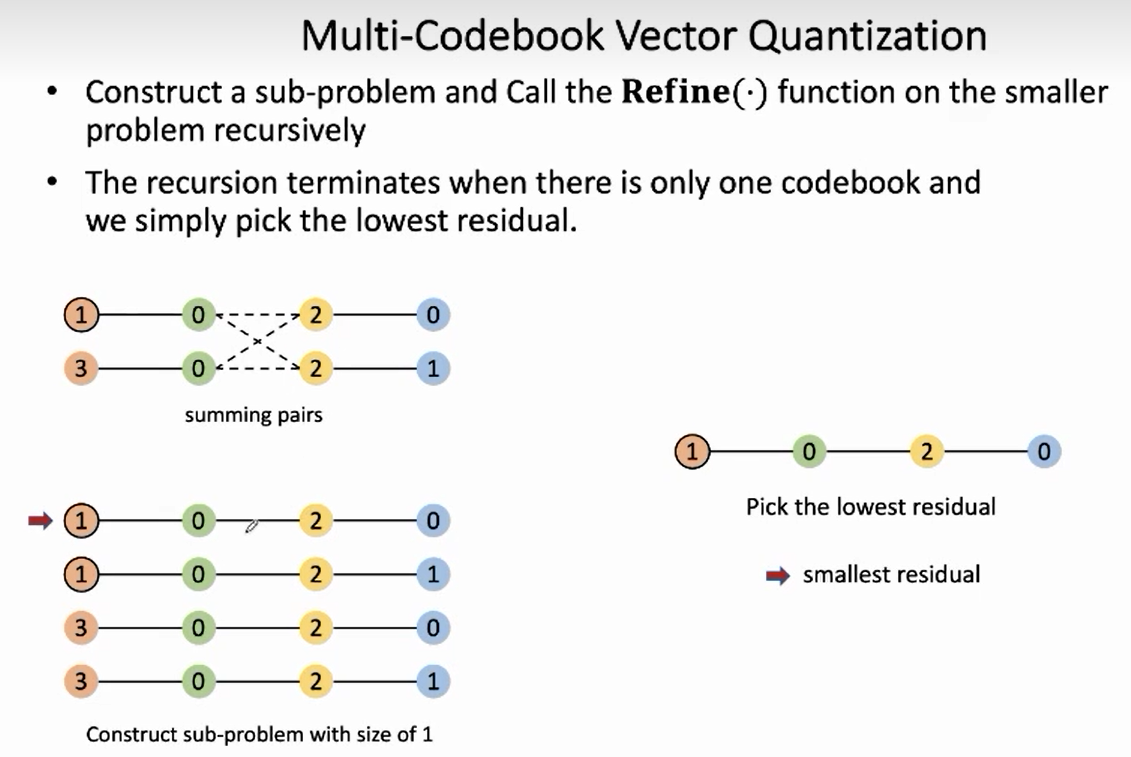
上面这个例子迭代了3次。