模型量化 商汤 视频
2023.4.25
b站:【商汤泰坦公开课】模型量化的那些事 2020.4.9
知乎:模型量化了解一下? 视频的对应文字稿版本
本次课程由商汤研究院–链接与编译团队的两位研究员分享团队在模型量化方面的的一系列研究工作,其中包含CVPR 2020、ICCV 2019等多篇与北航刘祥龙老师团队合作的论文成果:
1、如何训练极低比特(<4bit)的网络
2、如何训练高效的二值化网络
3、如何用量化技术来加速模型训练
4、模型量化在实际场景的落地
5、模型量化与网络结构搜索结合

模型量化的几个结论和问题
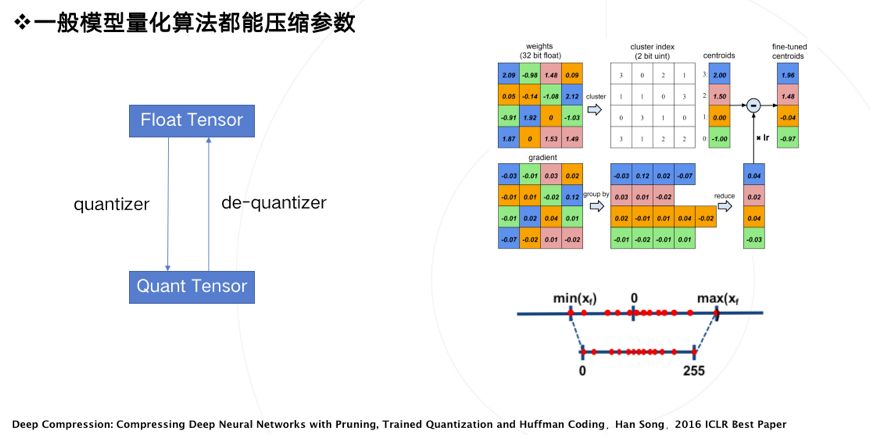
- 一般模型量化算法都能压缩参数,但是==压缩了参数大小并没有什么用==。
- ==许多量化算法都无法提升速度==,量化算法在什么条件下的可以提升速度?
- ==许多量化算法都无法降低内存占用==,量化算法在什么条件下可以降低内存占用?
- 如何生产一个量化模型?
- 是什么阻碍了量化模型的落地?
量化与反量化
衡量算法速度的指标:理论峰值性能
量化是否一定能加速计算?回答是否定的,许多量化算法都无法带来实质性加速。
引入一个概念:理论计算峰值。在高性能计算领域,这概念一般被定义为:单位时钟周期内能完成的计算个数 乘上 芯片频率。
什么样的量化方法可以带来潜在、可落地的速度提升呢?我们总结需要满足两个条件:
1、量化数值的计算在部署硬件上的峰值性能更高 。
2、量化算法引入的额外计算(overhead)少 。
要准确理解上述条件,需要有一定的高性能计算基础知识,限于篇幅就不展开讨论了。现直接给出如下结论:已知提速概率较大的量化方法主要有如下三类,
1、二值化,其可以用简单的位运算来同时计算大量的数。对比从nvdia gpu到x86平台,1bit计算分别有5到128倍的理论性能提升。且其只会引入一个额外的量化操作,该操作可以享受到SIMD(单指令多数据流)的加速收益。
2、线性量化,又可细分为非对称,对称和ristretto几种。在nvdia gpu,x86和arm平台上,均支持8bit的计算,效率提升从1倍到16倍不等,其中tensor core甚至支持4bit计算,这也是非常有潜力的方向。由于线性量化引入的额外量化/反量化计算都是标准的向量操作,也可以使用SIMD进行加速,带来的额外计算耗时不大。
3、对数量化,一个比较特殊的量化方法。可以想象一下,两个同底的幂指数进行相乘,那么等价于其指数相加,降低了计算强度。同时加法也被转变为索引计算。但没有看到有在三大平台上实现对数量化的加速库,可能其实现的加速效果不明显。只有一些专用芯片上使用了对数量化。

简单看一下二值化和线性量化两种方式,分别是下图中右上角的图和右下角的图。
总结一下,要使用量化技术来提升模型运行速度,需要满足两个条件:
1、选择适合部署的量化方案。
2、在部署平台上使用经过深度优化的量化计算库(必要的时候,可能需要撸起袖子自己上)。
首先保证你实现的低比特计算效率超过原先浮点计算,否则为何要承担精度损失的风险而使用并不加速的量化模型呢。但低比特计算效率超过浮点计算其实并不容易,因为大家在浮点的计算库上已经做了非常多细致的优化比如winograd,间接卷积等等。
为了最大限度保证实用性,后面的论文所有工作都是基于二值化、线性量化两种前提来做的,并且绝大部分工作都报告最终实际的加速效果。这也是链接与编译团队做研究的一个风格。

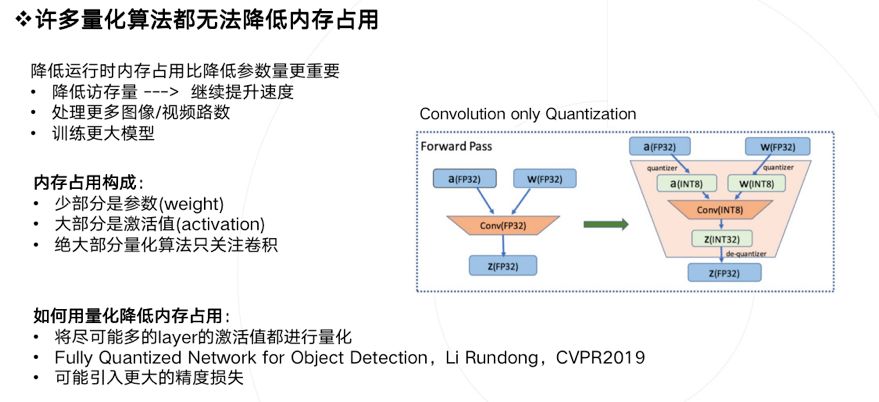
模型量化还有一个潜在的好处是降低运行时内存占用,这个特性无论是在移动端还是云端都是具有现实意义的。降低运行时内存占用比降低参数量更有意义。如果降低内存占用,可以得到如下好处:
- 降低访存量,存在提升速度的可能 。
- 在同样硬件环境下,同时处理更多视频或者视频路数 。
- 训练更大的模型。
我们分析下运行时内存都是被什么东西占用的:
- 大家关心的参数weight其实只占很少一部分。
- 大部分内存占用来自激活值activation。
- 如果你做低比特量化只关注卷积的话(很多论文其实也是只量化了卷积),那么是无法带来内存占用降低的。
如何才能用量化降低内存占用,只有一个方式:
- 将尽可能多的layer的激活值都进行量化 。比如 pooling、relu、concat等激活值。
- 在这个方向上之前商汤的一位实习生李润东也有一个工作,做了除了卷积之外更多层的量化。Fully Quantized Network for Object Detection, Li Rundong, CVPR2019
- 但是这样做会带来更多的精度损失,这可能也是大家需要关心的。
生产量化模型
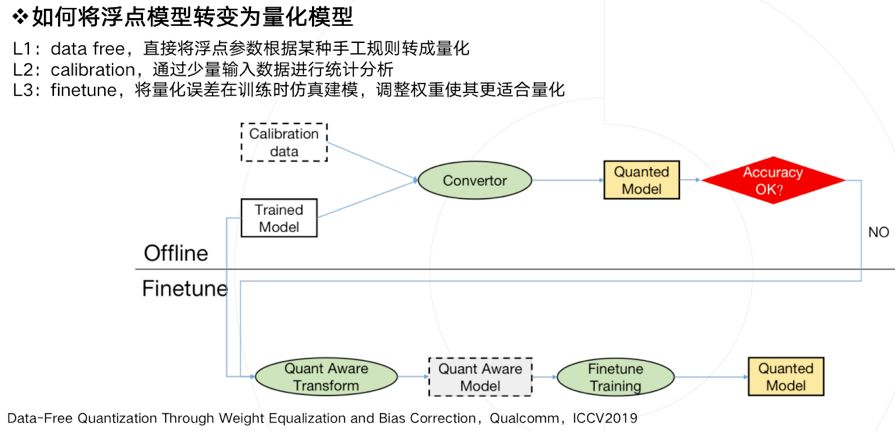
生产一个量化模型的有以下几种方法,借鉴了ICCV2019上一篇data-free量化论文的定义。
如果将浮点模型转变为量化模型:
L1:data free:直接将一个浮点参数直接转化成量化数,一般会带来很大的精度损失,但使用上非常简单。
L2:calibration:基于数据校准的方案,很多芯片都会提供这样的功能,比如tensorRT,高通,寒武纪等。它需要转模型的时候提供一些真实的计算数据。
L3:finetune:基于训练finetune的方案,有很多论文都是使用这种方法,它的好处是可以带来更大的精度提升,缺点是需要修改训练代码,实施周期比较长。
上图描述了一种实用的pipeline流程,一般会优先使用不进行finetune的offline方法,也就是离线方案。当离线方案精度损失过于严重,我们才会进行基于finetune的方法,来做进一步的抢救。
data-free quantization through weight equlization and bias correction, Qualcomm, ICCV2019
量化模型的落地
最后聊聊阻碍模型量化算法落地的几个问题,核心当然是精度问题。我们发现虽然学术界大家很早就开始做量化,但现在算法还无法大规模落地。主要存在几个Gap:
1、可落地的线性量化方案无法很好的刻画一些分布,比如高斯分布
2、比特数越低,精度损失就越大,实用性就越差
3、任务越难,精度损失越大,比如识别任务,就比分类任务要难非常多
4、小模型会比大模型更难量化
5、某些特定结构,如depthwise,对量化精度十分不友好
6、常见的对部署友好的方法比如merge BN,全量化,都会给精度带来更大的挑战
除了精度外,软硬件支持不好也是一个阻碍:
- 不同的硬件支持的低比特指令是不一样的,同样训练得到的低比特模型,无法直接部署在所有硬件上。
- 除了硬件之外,不同软件库实现的量化方案和细节也不一样,量化细节里包括量化位置、是否支持perchannel、是否混合精度等等。即使硬件支持了量化,但你会发现不是所有硬件可以在低比特上提供更好的速度提升, 造成这个状况的主要原因有多个,一方面是指令集峰值提升可能本身就并不多,而要引入较多的额外计算,另一方面也取决于软件工程师优化指令的水平,同时由于网络结构灵活多样,不一定能在不同网络结构上达到同样好的加速比,需要优化足够多的的corner case才可以解决。
相信大家对模型量化的概念和落地难点有了一个系统性的认识。我的部分就到这里结束了,下面是大家最期待的论文解读时间。

论文解读
低比特量化:
Differentiable Soft Quantization: Bridging Full-Precision and Low-Bit Neural Networks (ICCV 2019)
由于量化函数本身是离散不可导的,导致其无法像标准神经网络一样使用反向传播计算梯度,一个常用的做法是使用梯度直通估计器(STE),即在反向过程中忽略量化这一步骤产生的影响,而这也就自然的带来了梯度不准确的问题。权重经过STE拿到的梯度跟它应该拿到的梯度是不匹配的。ICLR 2020年有一篇论文通过实验具体的分析了这一现象,发现随着比特数的降低,不匹配的现象更加明显。
。。。。TODO