Knowledge Distillation 视频 李宏毅助教
PPT:https://slides.com/arvinliu/model-compression
视频:P49 Network Compression (1_2) - Knowledge Distillation (选学)1:07:53
Review
Network Pruning
方法:Network不重要的weight或neuron进行删除,再重train一次(不重train直接测试的话,效果不好,原因是模型还不适应没有那些没用的weight….要稍微重train一下)。
原因:==大NN有很多冗参数==,而小NN很难train,那就用大NN删成小NN就好了。
应用:只要他是NN(?)就可以。
Knowledge Distillation
方法:利用一个==已经学好的大model==,来教小model如何做好任务。
原因:让学生直接做对题目太难了,可以让他偷看老师是怎么想/解出题目的。
应用:通常只用在Classification,而且学生只能从头学起。
Architecture Design
方法:使用较少的参数来达到原本某些layer的效果。
原因:有些layer可能参数就是很冗,比如DNN就是个明显例子。
应用:就是直接套新的model,或者是利用新的layer来模拟旧的layer。
Parameter Quantization
方法:将原本NN常用的计算单位:float32/float64压缩成更小的单位。
原因:对NN来说,LSB可能不是那么重要。(* LSB: Least-Significant Bit, 在这里指小数点的后面其含义。)
应用:对所有已经train好的model使用,或者边train边引诱model去quantize。
Why Learn’em all?
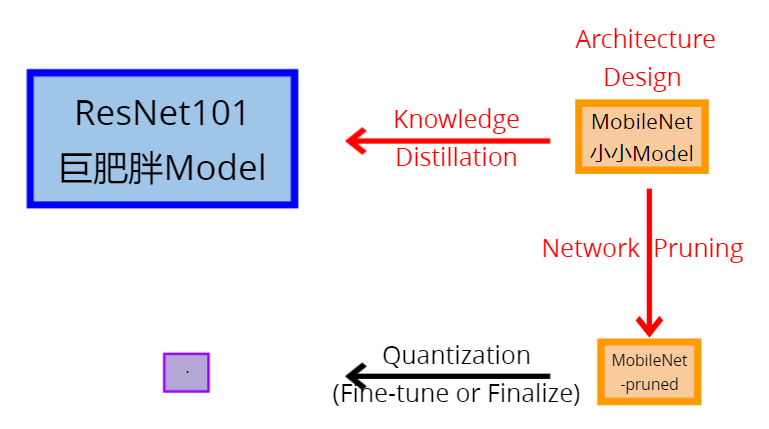
Mixed it !把这些方法混合
例如这样混合:
Knowledge Distillation
Main Question: Distill what?
- Logits(输出值)
- 直接匹配logits
- 学习一个batch里面的logits distribution
- …
- Feature(中间值)
- 直接匹配中间的Feature
- 学习Feature中间如何转换
- …
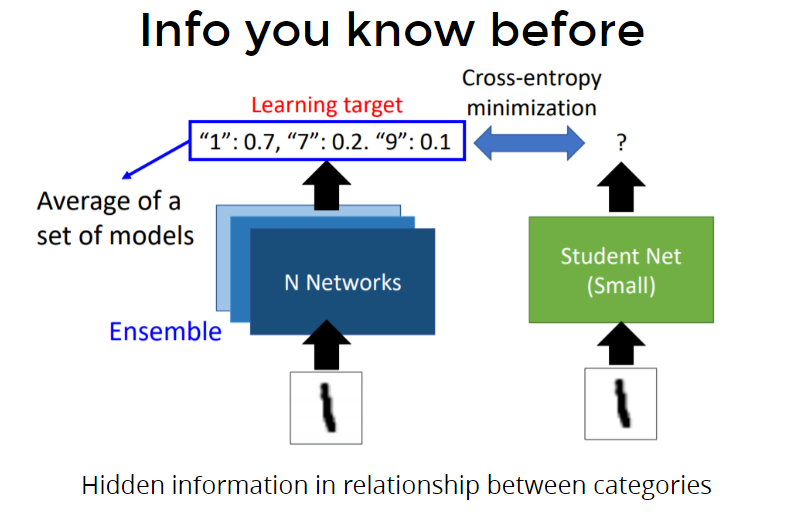
Before Logits KD…
You need to know the magic power of soften label. 为什么知识蒸馏在logit上是有用的
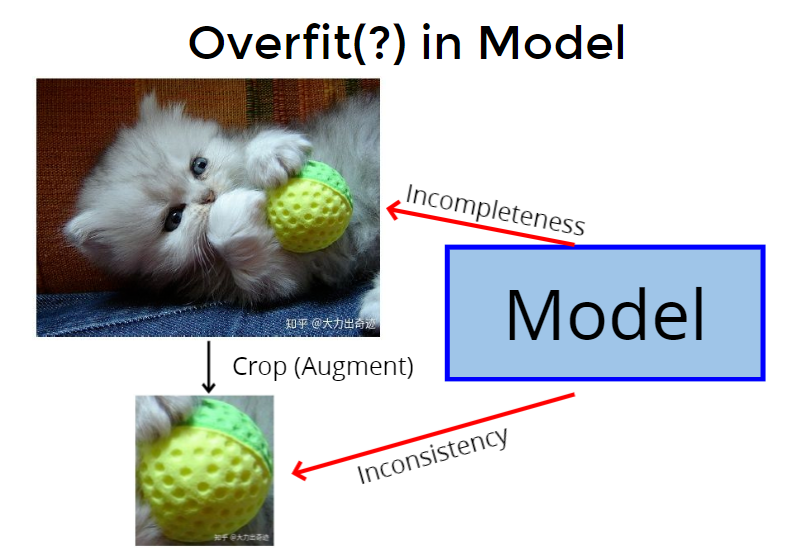
下图的训练标签是“猫”,但这是“incompleteness”的,不完整的,因为还有球、牛仔裤等,是不完全的label。然后可能训练出来的概率是0.7是猫,0.2是球,0.1是牛仔裤,这是很好的,但是模型用的one-hot,认为猫概率要更高,就变成造成“overfit”。
crop是一种augment方法,是取出图片中的一个小片段。举例来说,取出一个矩形,刚好是下图的球,但是label却还是猫,这样就会让model很confuse,造成“inconsistency” 不一致。
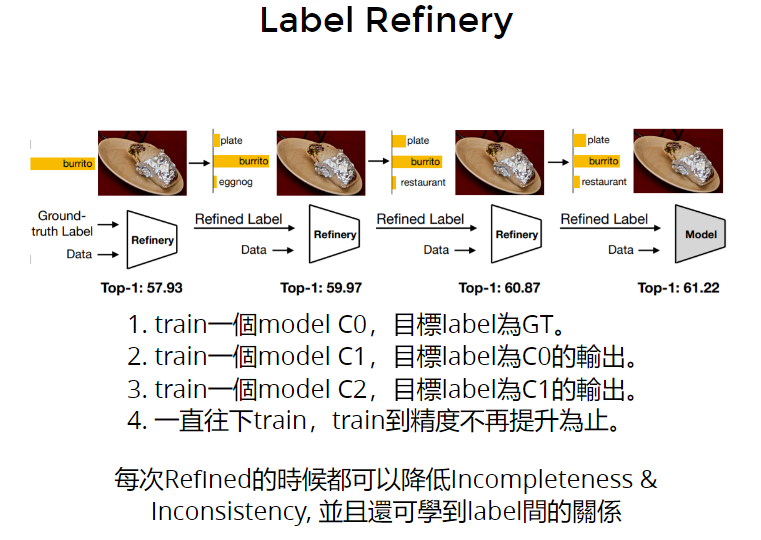
对于上述问题,有改进的方法,称为“==label refinery==” 精细化。
步骤:
- train一个model,label是groundtruth
- train一个model,label是上一个model的输出,发现会提高accuracy
- …..重复第2步,直到accuracy不再提高
label refinery可以学到label间的关系
注意看这里,每次train的model是一样的,精度却会提高。联想到知识蒸馏,student model的上界并不是teacher model!!student model的accuracy是有机会超过teacher model的!
Logits Distillation
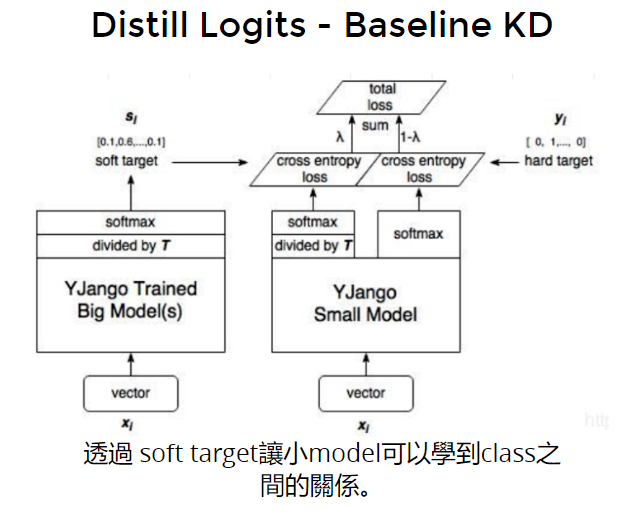
- baseline Knowledge Distillation
除以一个T,让logit不要那么激进,不要和 one-hot一样。
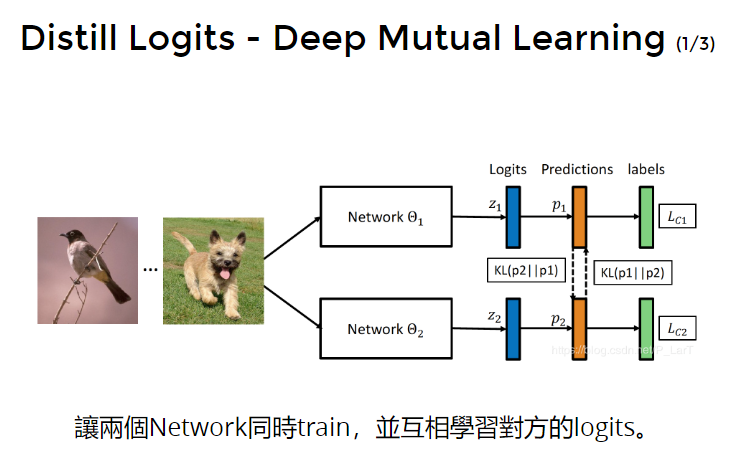
- mutual learning
train两个model,互相学习logit,当然也要学习真实label。
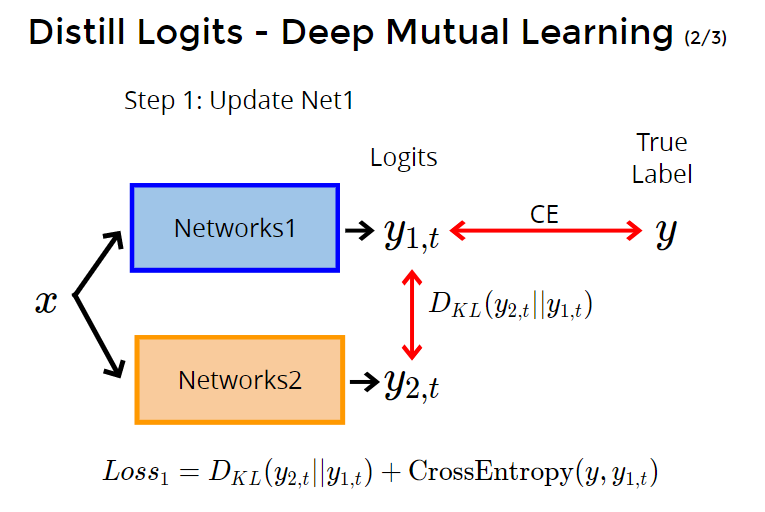
第1步:先选其中一个net进行参数更新,比如net1,计算y2(teacher)对y1(student)的kl散度,计算y1和真实y的交叉熵。
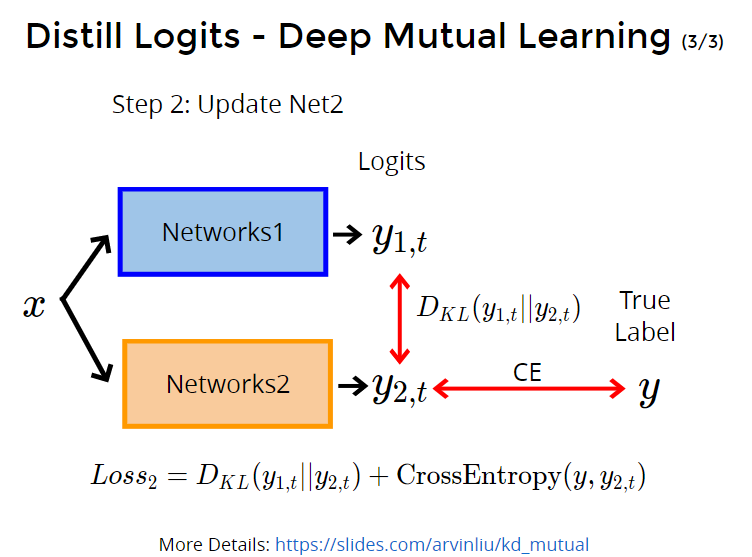
第2步:选第二个net,net2,计算y1(teacher)对y2(student)的kl散度,以及y2和真实y的交叉熵。
第3步:重复上述两步。
效果:
- 当net1和net2的结构相同时:net1和net2都会比单独训net1或net2效果好。(类似 label refinery)
- 当net1比net2结构大、参数多时:net2会训得比单独训net2效果好,net1也不一定比单独训net1效果差(我们常规会想,net2得acc不高,net1去学,相当于teacher去学student,那应该会造成不好的影响,但实际上不一定会更差,因为net2让net1看见更丰富的东西)
More Details: https://slides.com/arvinliu/kd_mutual
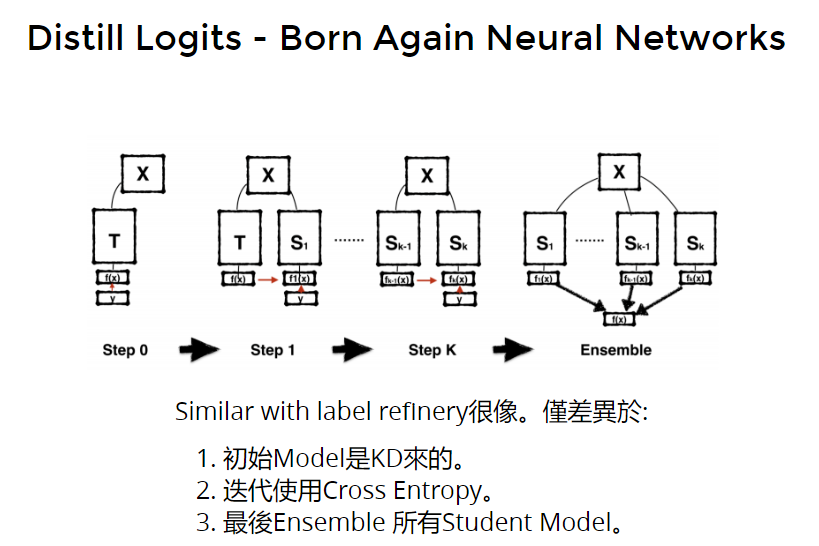
- born again 再次重生
Similar with label refinery很像。仅差异于:
- 初始Model是KD来的,是训一个teacher,后面都是student。
- born again迭代使用Cross Entropy,而label refinery使用的是kl散度。
- 最后Ensemble 所有Student Model。
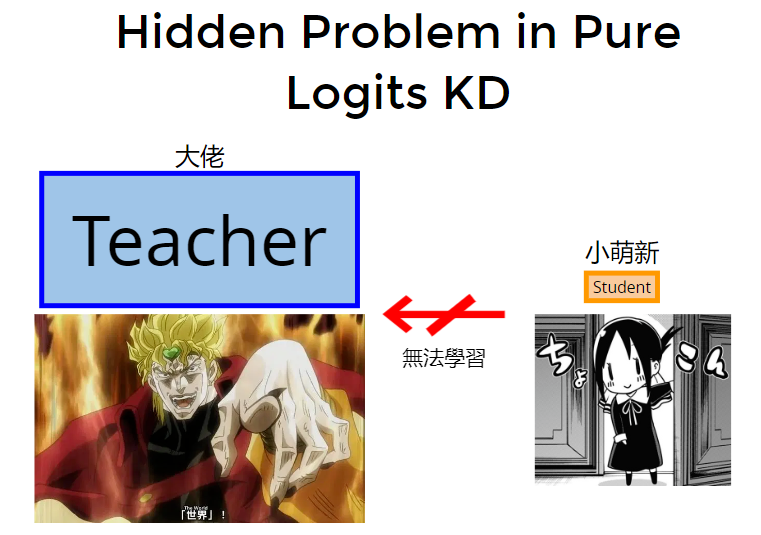
什么情况发生时,会让知识蒸馏失败or效果没有想象中的好呢:
- teacher模型参数、架构远大于student模型,student学不来teacher
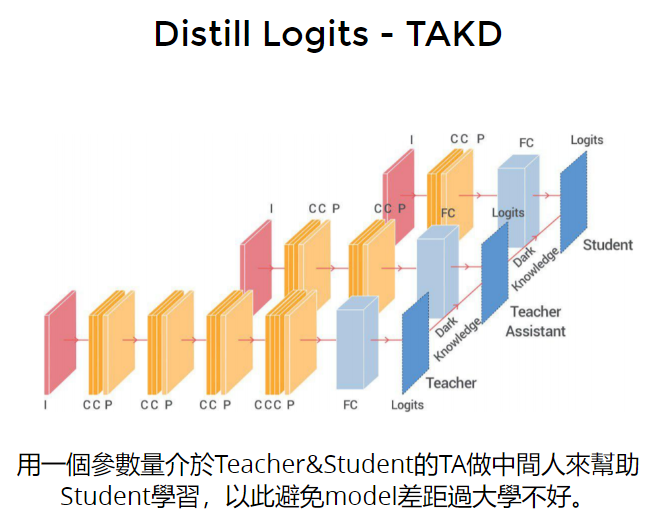
- 解决student学不来teacher的方法:用一个参数量介于Teacher&Student的TA(teacher assistant)做中间人来帮助Student学习,以此避免model差距过大学不好。
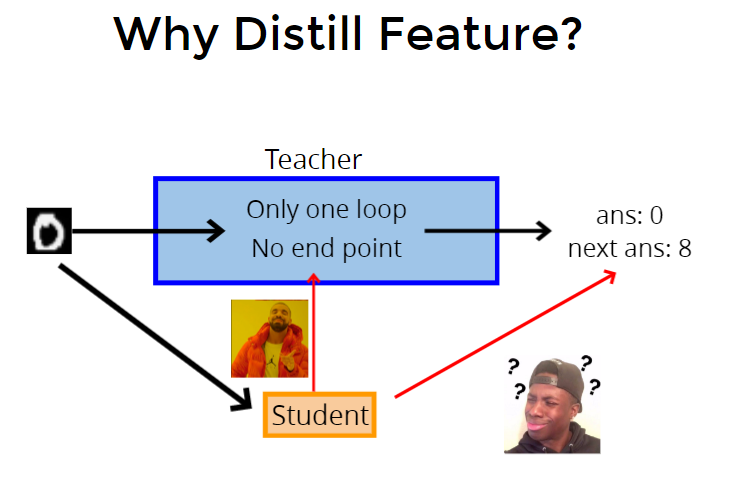
Feature Distillation
直接让student看teacher的输出,student可能无法理解,于是让student看teacher中间feature 到底在想什么。
- FitNet
先让Student学习如何产生Teacher的中间Feature,之后再使用Baseline KD。
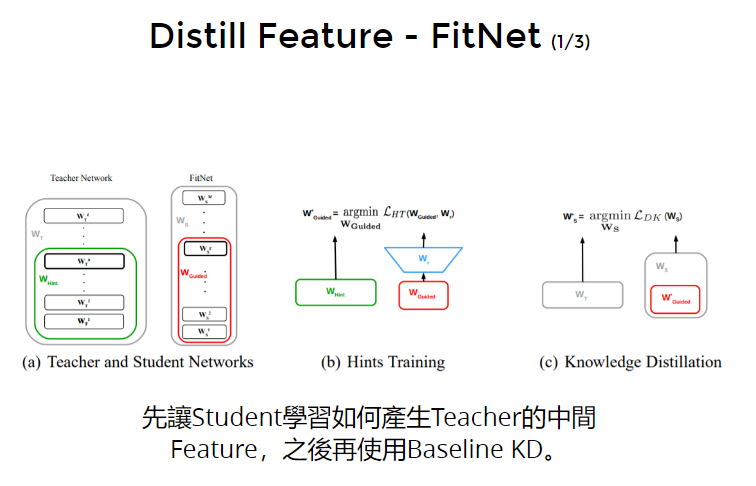
具体步骤:
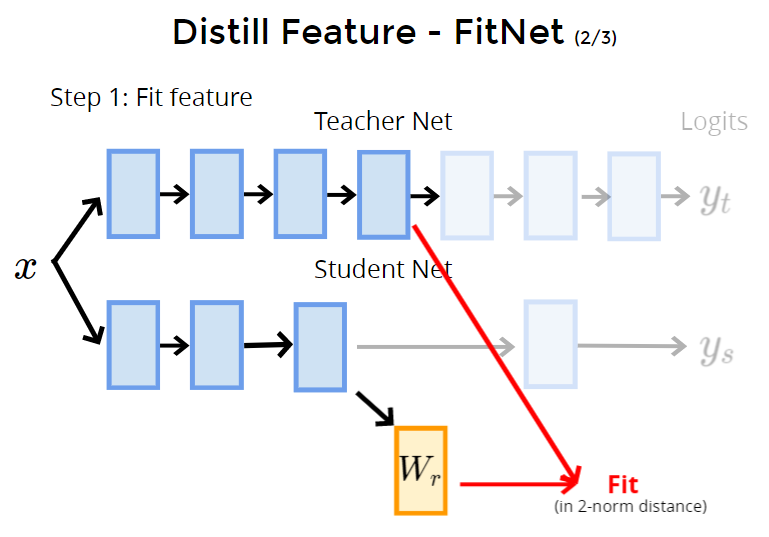
步骤1:fit feature:选出student net前几层的输出,经过一个仿射变换(目的是变换shape),然后与teacher前几层的输出之间做MSE。
因此student和teacher中间的feature就有了一定关联。
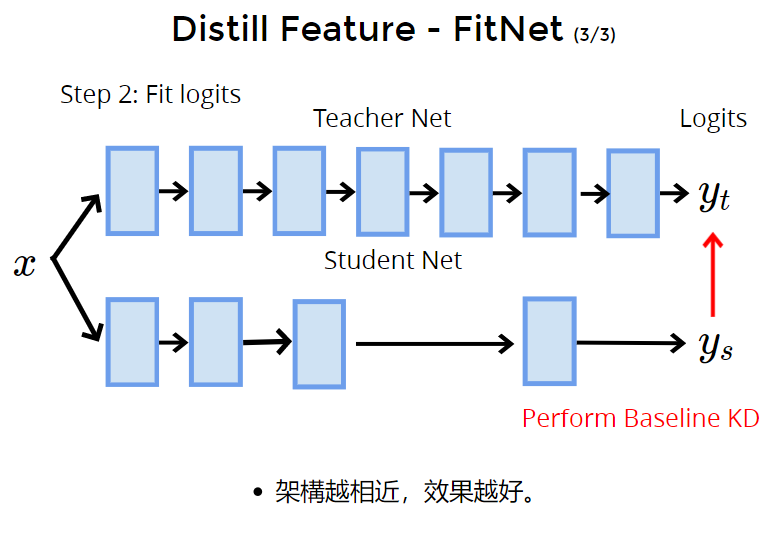
步骤2:fit logit:使用baseline kd,就是让student y学习teacher y。
实验小结论:teacher和student的结构越接近,效果越好。
fitnet存在的问题:
- Model capacity is different 模型的性能不同,student学中间feature真的能学得会吗?(一般来说feature维度比log高,认为会更难学)
- There’s lots of redundancy in Teacher Net. teacher模型有很多冗余。

解决方法:把teacher net的中间feature相成一个3维的feature map,如果有方法能做knowledge compression,压缩得更小。就能减少冗余,学到更精实的东西、并且好学一点(feature维度少一些)。
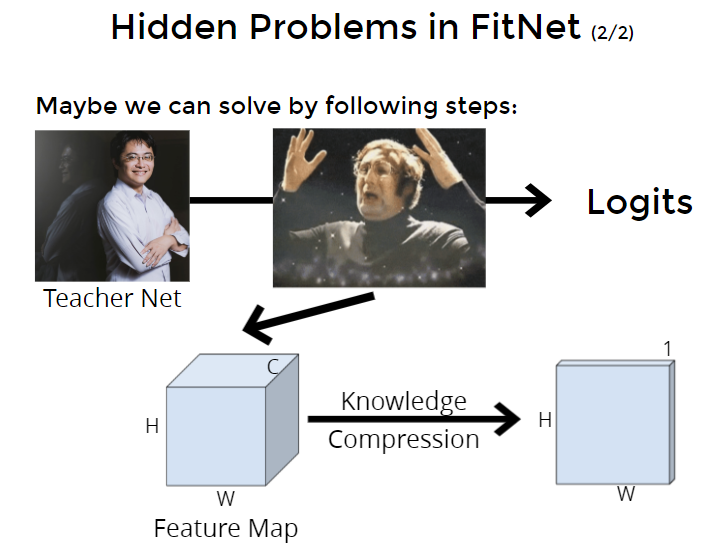
knowledge compression压缩方法:用attention map当作是压缩后的中间feature。
让teacher不同的中间层输出attention map,比如输出3张attention map,让student也输出3张attention map,让两两的attention map彼此接近。
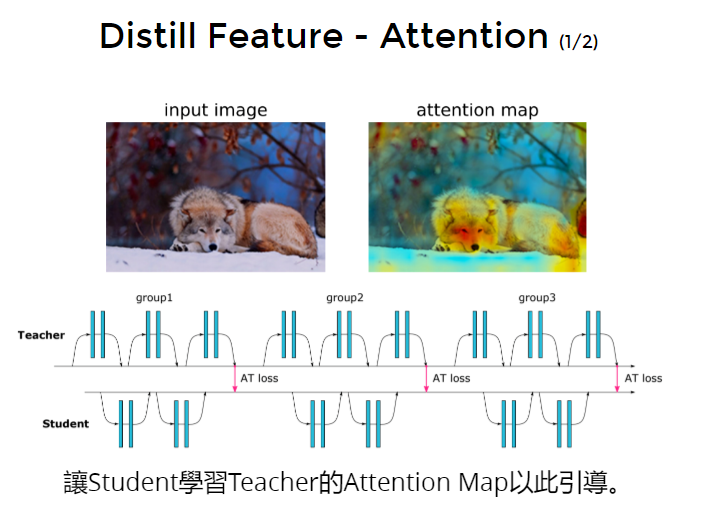
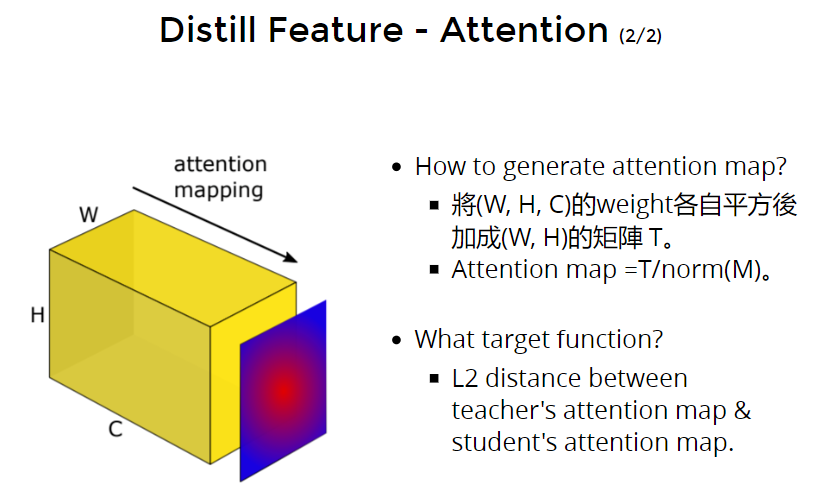
但是模型里面可能没有attention 层的,那么要怎么获得attention map呢:
- 将(W, H, C)的weight各自平方后加成(W, H)的矩阵 T。(?)
- Attention map =T/norm(M)。归一化一下。
Can we learn something from batch?
前面讲的logit或feature都是一对一的,如何在batch里做?
Relational Distillation 关系上的蒸馏
对batch里样本之间进行蒸馏
- Individual KD : 以每个sample为单位做知识蒸馏。
- Relational KD: 以sample之间的关系做知识蒸馏。
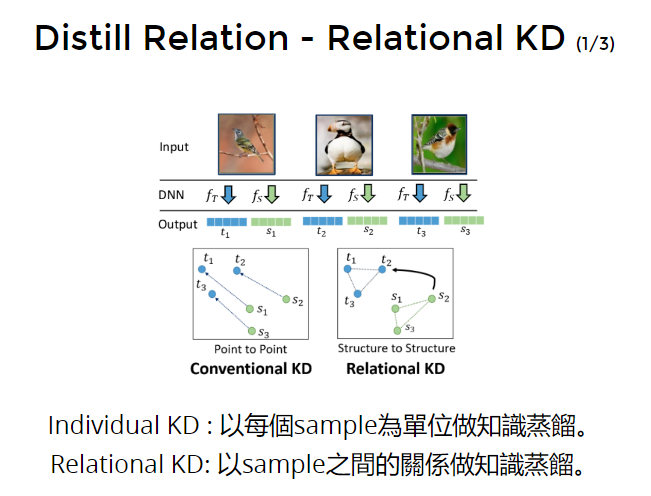
样本和样本之间的关系是某种“知识”。
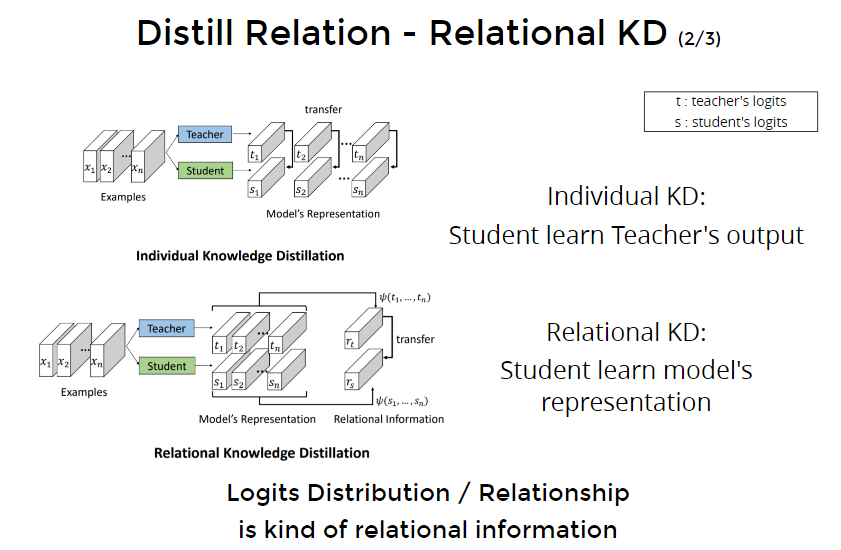
实现relational kd:
- Distance-wise KD 以距离为取样去蒸馏。 s1与sn的距离要接近 t1与tn的距离(L1、L2距离)
- Angle-wise KD。以角度为取样去蒸馏。s1到si与sj的角度要接近t1到ti于tj的角度。(t13向量与t23向量的cos值,与s13向量与s23向量的cos值之间的huber损失函数)
达到整个结构性的蒸馏。
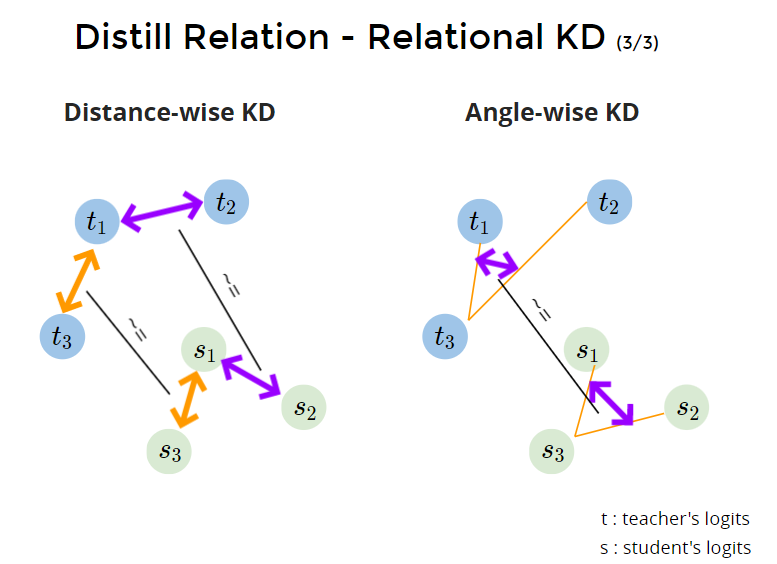
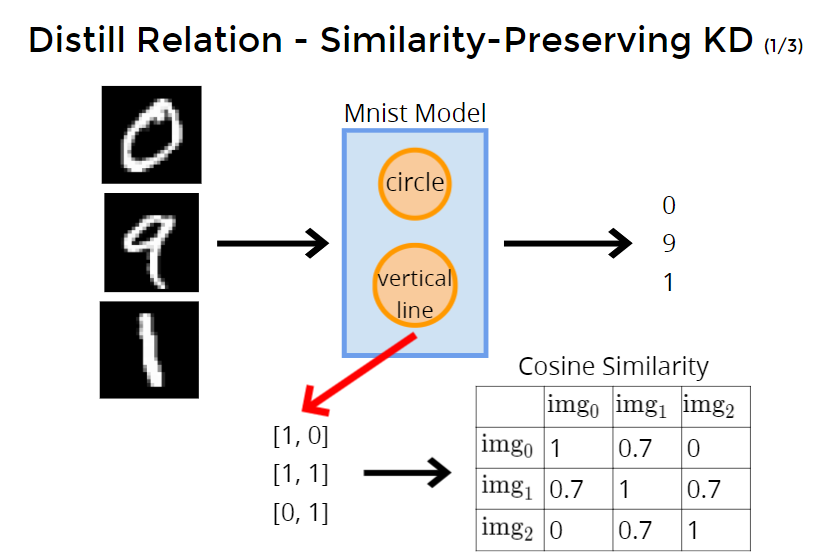
Why not distill relational information between feature? 所以feature蒸馏也同理,可以对不同样本之间feature的关系蒸馏
Of course you can.
假设model中有两个feature,分别是circle和vertical line数量。feature当作是向量,计算不同样本的feature向量之间的余弦相似度。
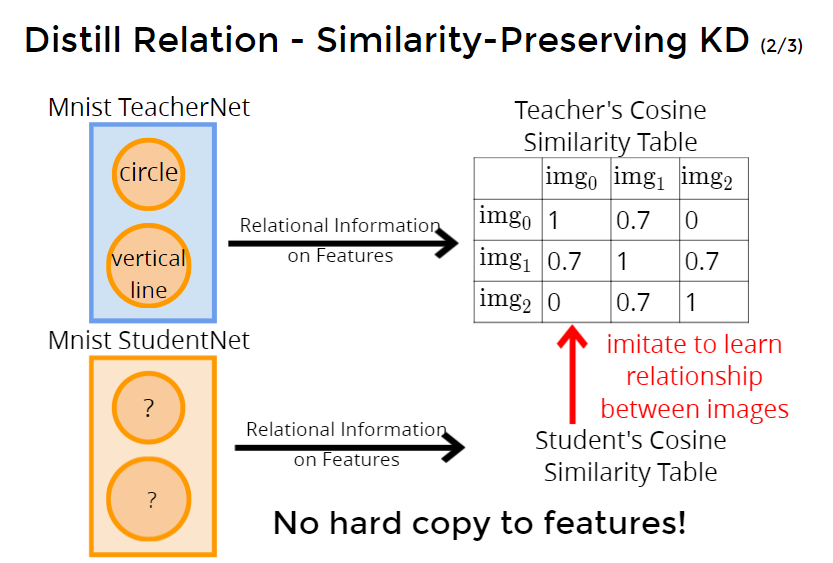
student学习teacher的cosine similarity table
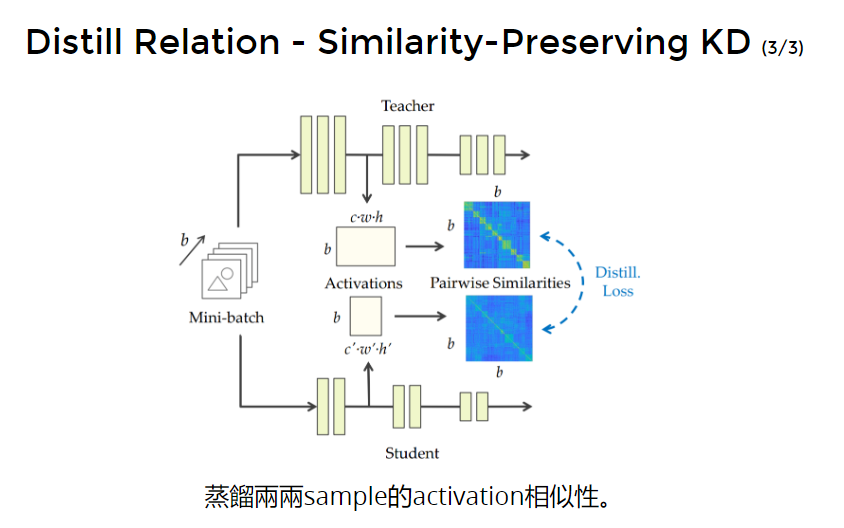
Paper Reference
- Knowledge Distillation
- Distilling the Knowledge in a Neural Network (NIPS 2014)
- Deep Mutual Learning (CVPR 2018)
- Born Again Neural Networks (ICML 2018)
- Label Refinery: Improving ImageNet Classification through Label Progression
- Improved Knowledge Distillation via Teacher Assistant (AAAI 2020)
- FitNets : Hints for Thin Deep Nets (ICLR2015)
- Paying More Attention to Attention: Improving the Performance of Convolutional Neural Networks via Attention Transfer (ICLR 2017)
- Relational Knowledge Distillation (CVPR 2019)
- Similarity-Preserving Knowledge Distillation (ICCV 2019)