Network Compression 视频 李宏毅
课程视频(B站):李宏毅2020机器学习深度学习(完整版)国语 P43-P50
课程官网:http://speech.ee.ntu.edu.tw/~tlkagk/courses_ML20.html
课程笔记(知乎):https://www.zhihu.com/column/c_1325525429269671936
网友github代码:https://github.com/chouxianyu/LHY_ML2020_Codes
github:https://github.com/jacobgil/pytorch-pruning 待看!!!
Outline
- Network Pruning
- Knowledge Distillation
- Parameter Quantization
- Architecture Design
- Dynamic Computation
Network Pruning 剪枝
Network can be pruned
网络一般都是“over-parameterized”,对于任务来说训练太多参数。 看一些neuron的output总是0,或者一些weight很接近0,对output无影响
剪掉的weight、neuron是没意义的解空间,不影响最优解(和最优解的距离不变)。
neuron理解为上一层经过某些连接的输出;weight是连接的值,就是神经元之间连接上的权重。
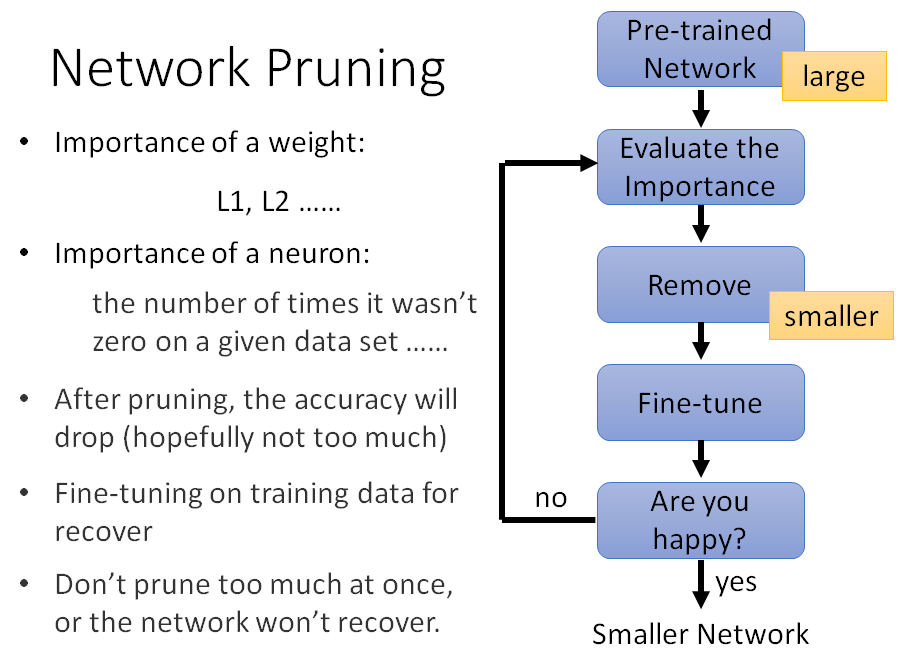
剪枝流程
- 有一个训好的大network
- 评估neuron或weight的重要性(直接看weight的数值,接近0不重要,很正或很负重要;neuron的output总是0不重要)
- 把pruned后的network再去训练集finetue一下(recover)(因为pruned会使得模型精度下降,要finetune补回来、恢复回来)
迭代地进行,一次pruned一点点参数,再finetune,再pruned,再finetune,直到模型参数符合要求(因为一次pruned太多,recover不回来)。
Why Pruning?
为什么不直接train一个小network:因为小network比较难train,有文章理论上证明只要network够大,能找到global optimize全局最优。
- How about simply train a smaller network?
- It is widely known that smaller network is more difficult to learn successfully.
- Larger network is easier to optimize?
https://www.youtube.com/watch?v=_VuWvQUMQVk - Lottery Ticket Hypothesis 大乐透假设
https://arxiv.org/abs/1803.03635
- Larger network is easier to optimize?
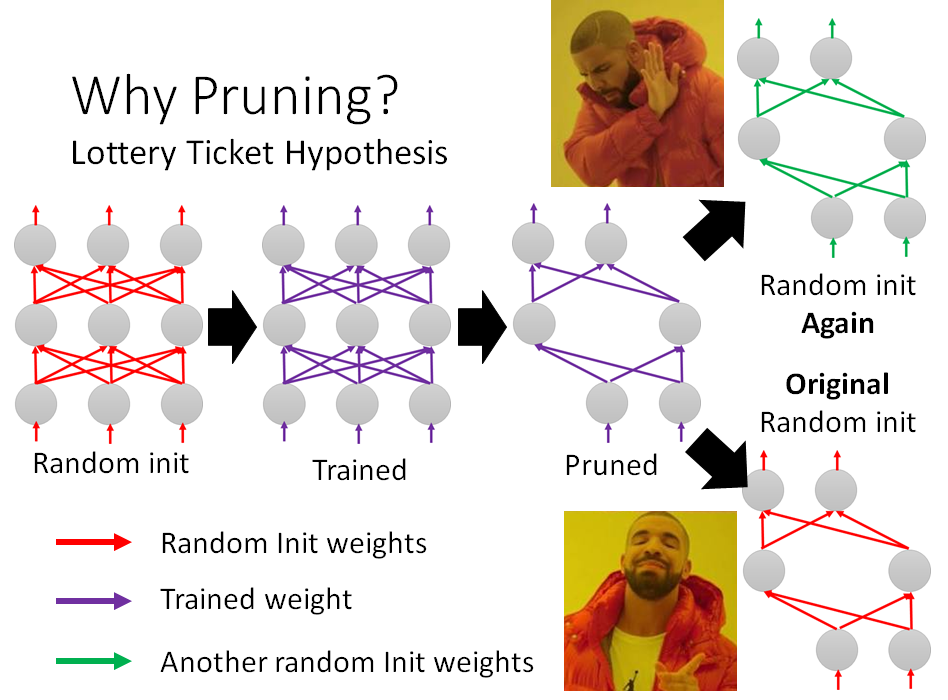
Lottery Ticket Hypothesis 大乐透假设:
不同随机初始化有时候train得起来,有时候train不起来。一个巨大的network想象成由很多小的network所组成,每一个是sub network,每一个小network就是一种可能的初始化,这些小network有的train得起来,有的train不起来,而大的network之所以能够train得起来,是因为大的network里面只要有某一个小的network能够train起来,整个network就train起来,然后把大network做pruned,取出小network。
这解释了下图右下,取大network的初始化一样的参数的小network初始化能够train起来。
不需要大乐透假说?直接train能train起来:

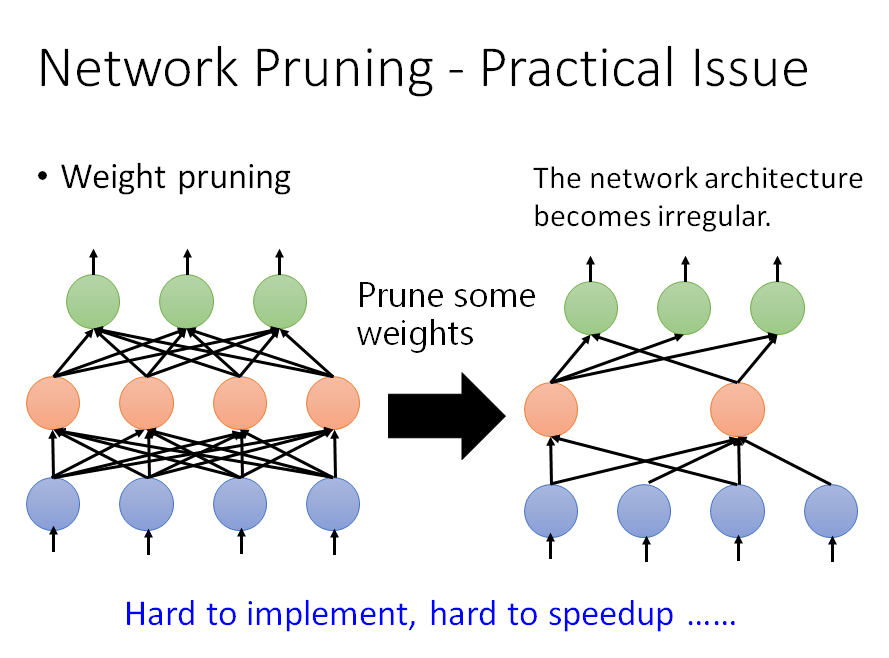
Weight pruning
直接把pruned的weight挖空,不利于gpu加速计算(gpu对象是矩阵),所以做法是把要pruned的weight置0。但是补0后的network模型大小没有变化。
pruning得即使很多(95%都pruned掉了),精度也没怎么掉,但是加速变慢了(小于1)有些pruning了结果还更慢了。

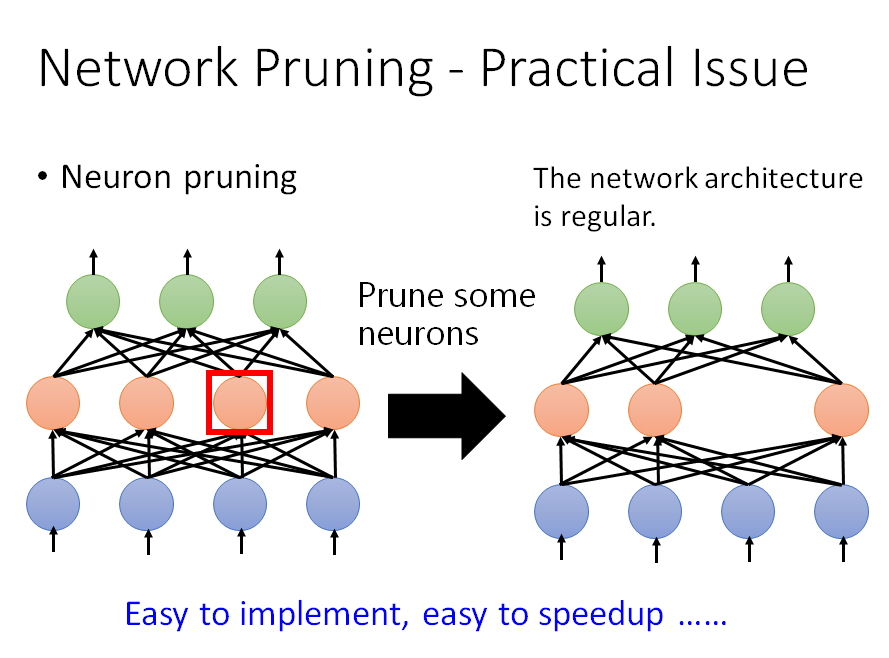
Neuron pruning
相比于weight pruning,neuron pruning是一种更好的方式,把neuron前面和后面连接的weight拿掉,直接拿掉某一个hidden neuron。
Knowledge Distillation
Knowledge Distillation:https://arxiv.org/pdf/1503.02531.pdf
Do Deep Nets Really Need to be Deep?https://arxiv.org/pdf/1312.6184.pdf
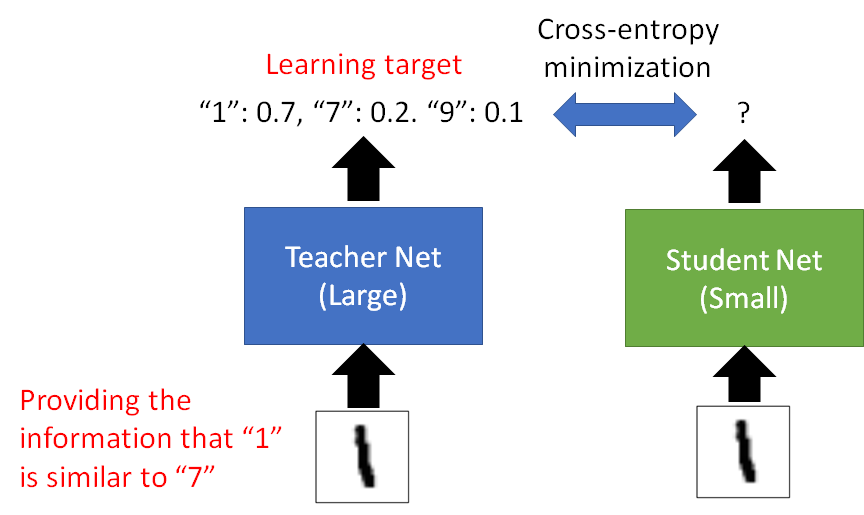
能学会1长得和7很像,1也长得像9
论文里做了一个有趣的实验:训练集里没给student看过7的数据,但是蒸馏后,student也可能能分类出7,因为student知道7和1、7和9挺像。
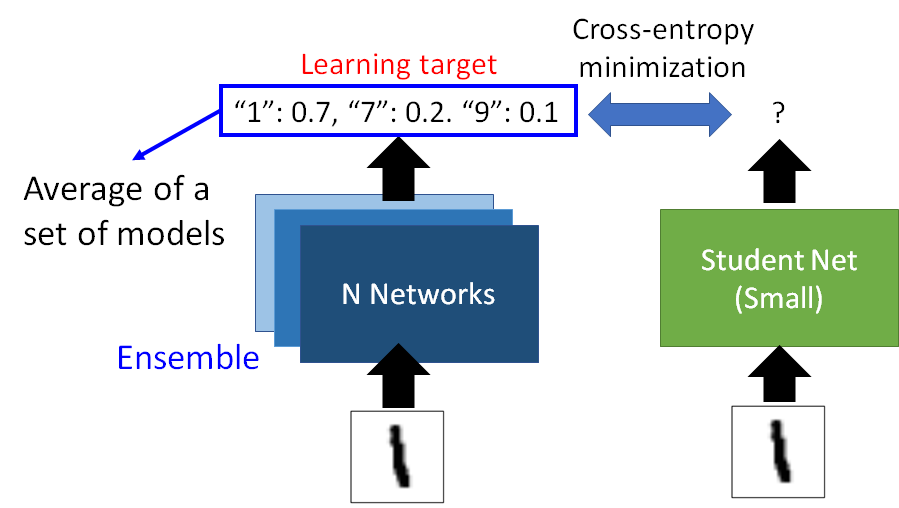
打比赛通常是ensemble很多,用集成方法组合多个模型。
知识蒸馏的teacher model把ensemble的模型并起来,比如输出是多个模型的平均,这个输出让student model去学习,最后student就能学到接近ensemble的结果。
temperature
通常 $T>1$ ,提出temperature的目的就是不希望因为teacher model输出概率很“确定”,比如接近1或0,这样就很像label,这样和直接让student学习数据,学习label(0、1) 没区别,就失去了用teacher model的意义,于是用一个temperature缓解一下。
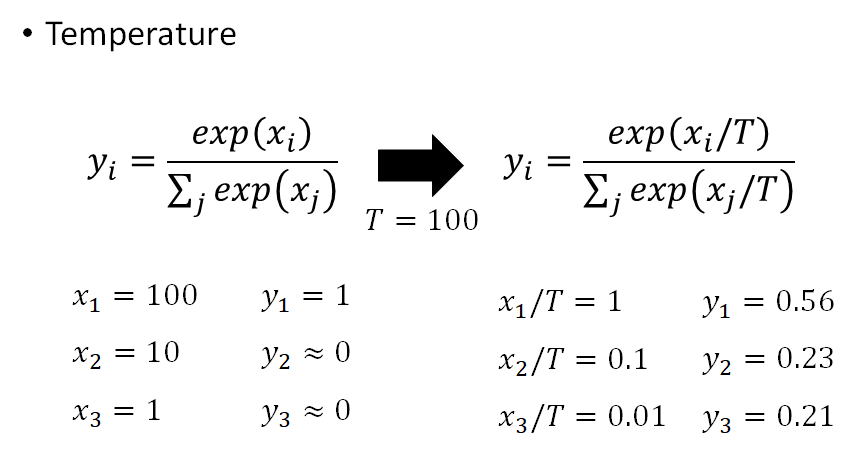
李宏毅实践发现Knowledge Distillation没有特别有用。
Parameter Quantization
- Using less bits to represent a value
- Weight clustering
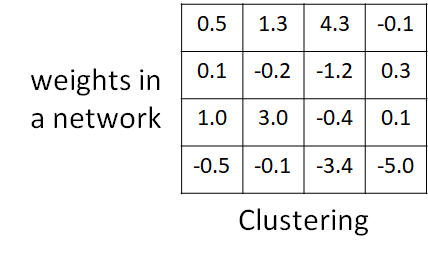
聚类,比如聚成4类,就用2个bit就能表示4个类,然后每个类的值(table)用所属类的值的平均值表示。
这样可能不够精准
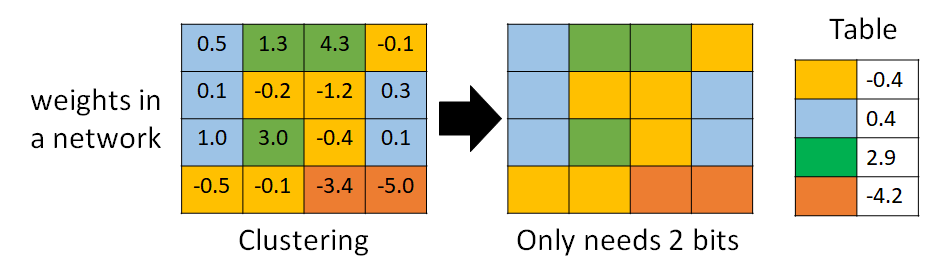
- Represent frequent clusters by less bits, represent rare clusters by more bits
- e.g. Huffman encoding 哈夫曼编码,把比较常出现的token用较少的bit表示,比较少出现的token用较多的bit表示
Binary Weights
Binary Connect: https://arxiv.org/abs/1511.00363
Binary Network: https://arxiv.org/abs/1602.02830
XNOR-net: https://arxiv.org/abs/1603.05279
Your weights are always +1 or -1
- Binary Connect
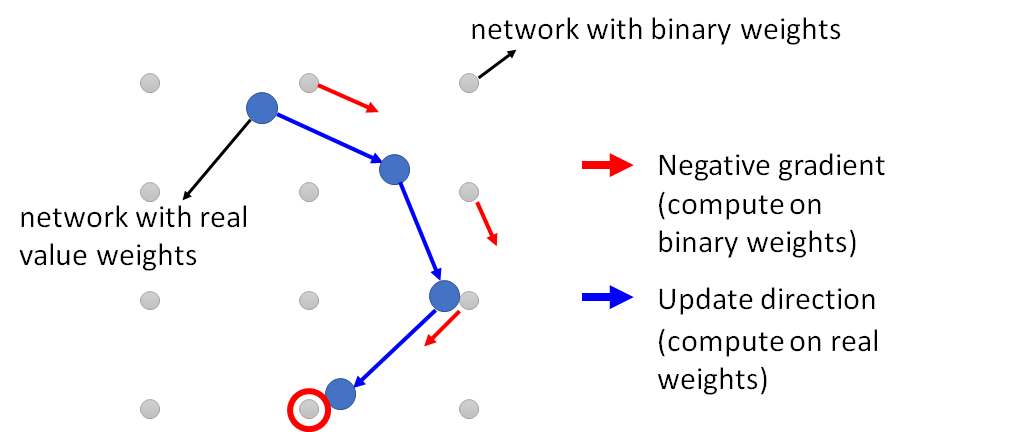
流程:随机初始化参数,然后找到参数最接近的二值化参数,计算该二值化参数的梯度,认为是原参数的梯度(非二值化),然后用这个梯度作为原参数的更新方向,更新后的参数值,再去找最接近的二值化参数,再去计算该二值化参数的梯度,再用这个梯度更新real value 参数。直到迭代完了,最后这个最接近real value的二值化参数,作为最终的参数使用。
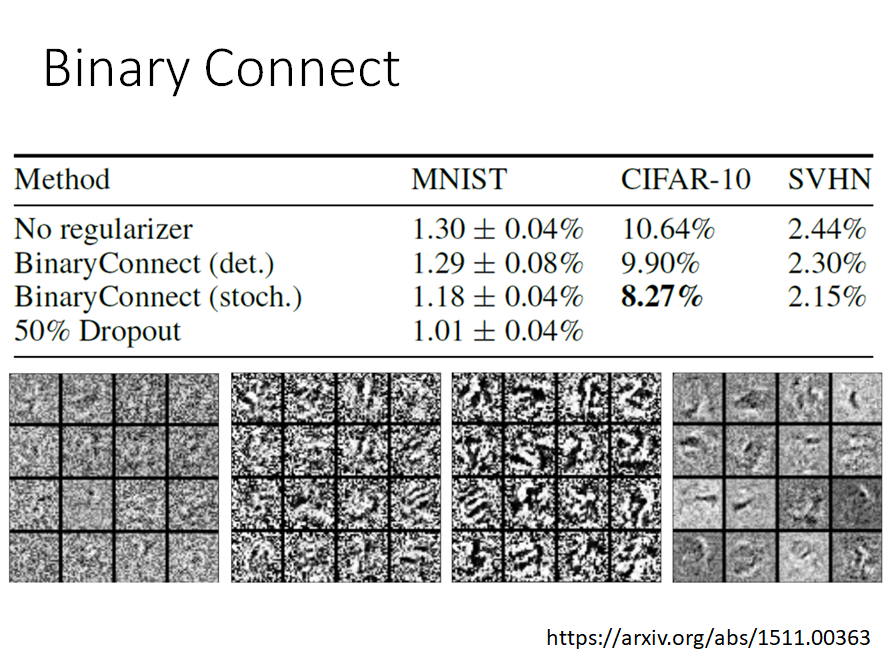
binary connect 结果
论文发现用binary connect结果居然还变好了,一开始认为参数二值化可能会更差,没想到更好,分析是binary connect有点像正则,起到正则作用,二值化。
Architecture Design
应该是实践中最有效的做法
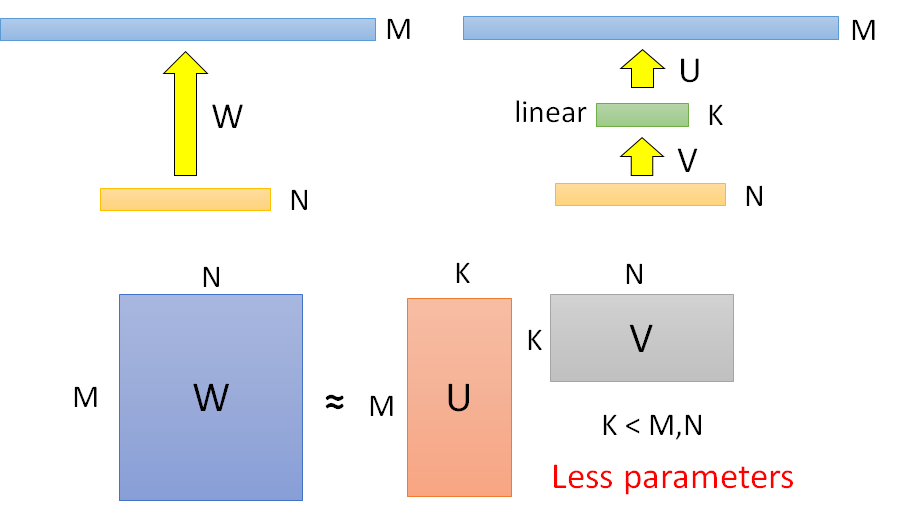
Low rank approximation
fully connect:
中间插入一层(没有激活函数,纯linear),是做SVD奇异值分解。
参数大小来说 $W>U+V$ ,因此减少了参数量;
但是 $W$ 能做到 $UV$ 所做不到的事(解空间),因为 $K\ge rank(UV)$ 也就是 $U*V$的秩小于等于K,但 W没有限制。
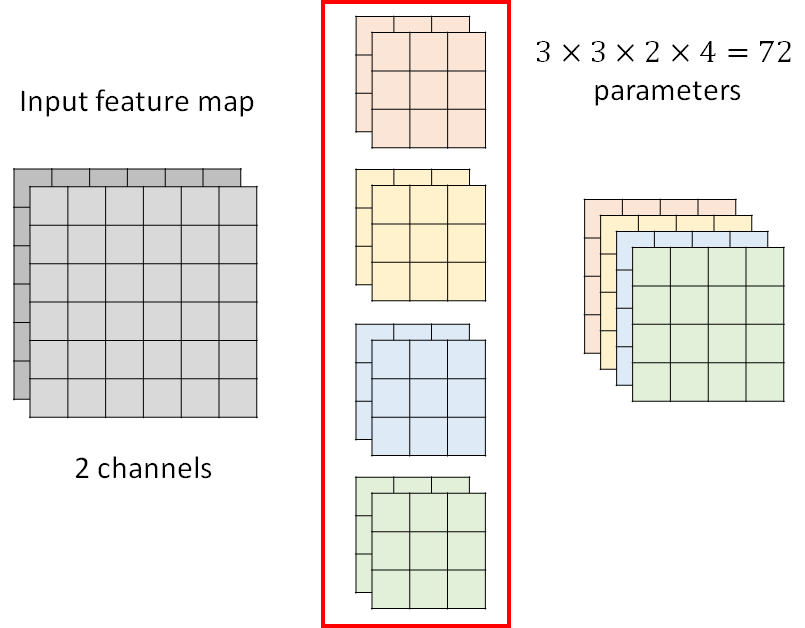
Review: Standard CNN
feature的channel有几个,filter的channel就要有几个,然后根据filter的数量,得到output的数量
Depthwise Separable Convolution
1. Depthwise Convolution
每个filter负责一个channel的input(之前每个filter负责所有channel的input,所以每个filter是三维的(有channel通道))现在没有channel通道了,二维的。
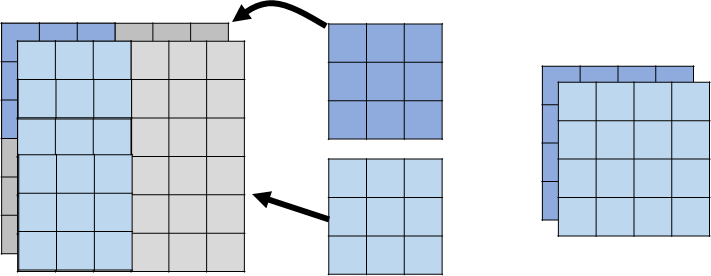
- Filter number = Input channel number
- Each filter only considers one channel.
- The filters are $k\times k$ matrices
- There is no interaction between channels
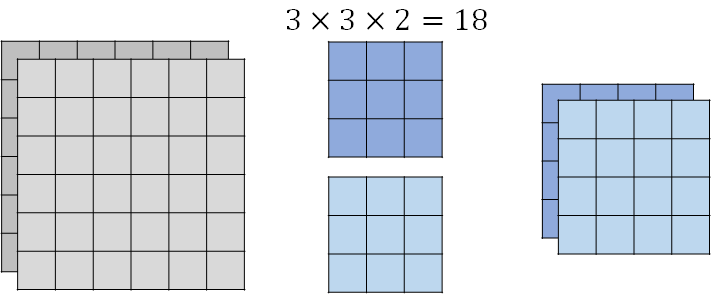
2. Pointwise Convolution
前一个步骤(Depthwise Convolution)得到的feature map,用1 * 1 filter去扫,卷积核是1 * 1,channel和feature map的channel数量一样。
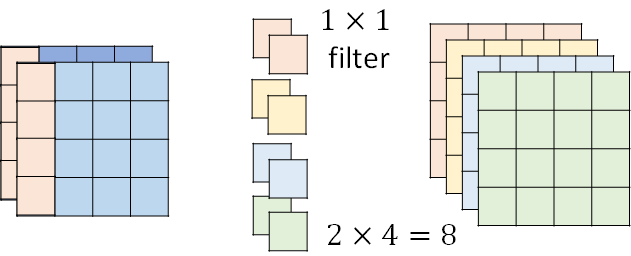
总共用了18+8=26个参数。
普通卷积:比如要得到(右上图形)橙色的左上角的值,是由(左上图形)左上18个值和filter做dot product再求和得到的。
ds卷积:(左下图形)feature map 被第二层filler作用时,feature map的参数是“共用的”,既给橙色filler用、又给黄色filler用。因此参数量少了。
不同filler间,共用同样的参数。
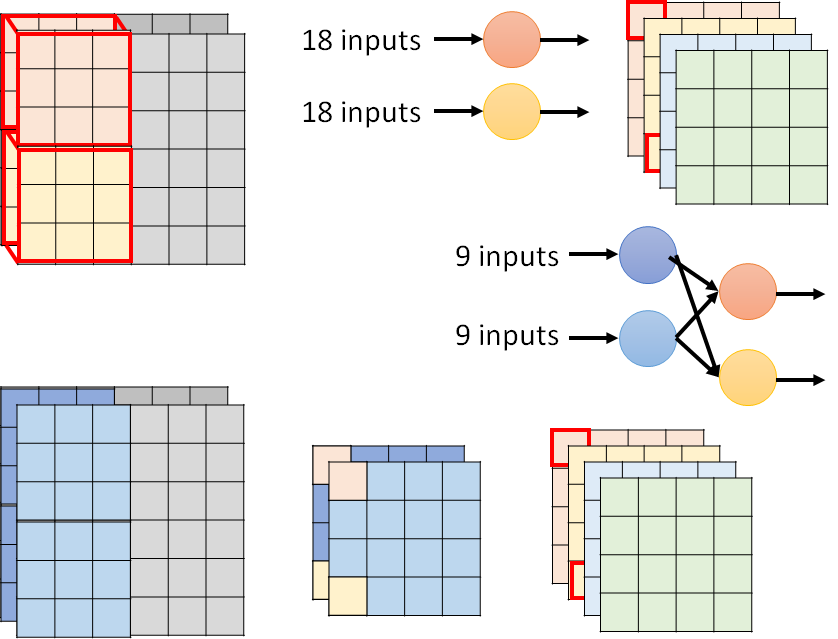
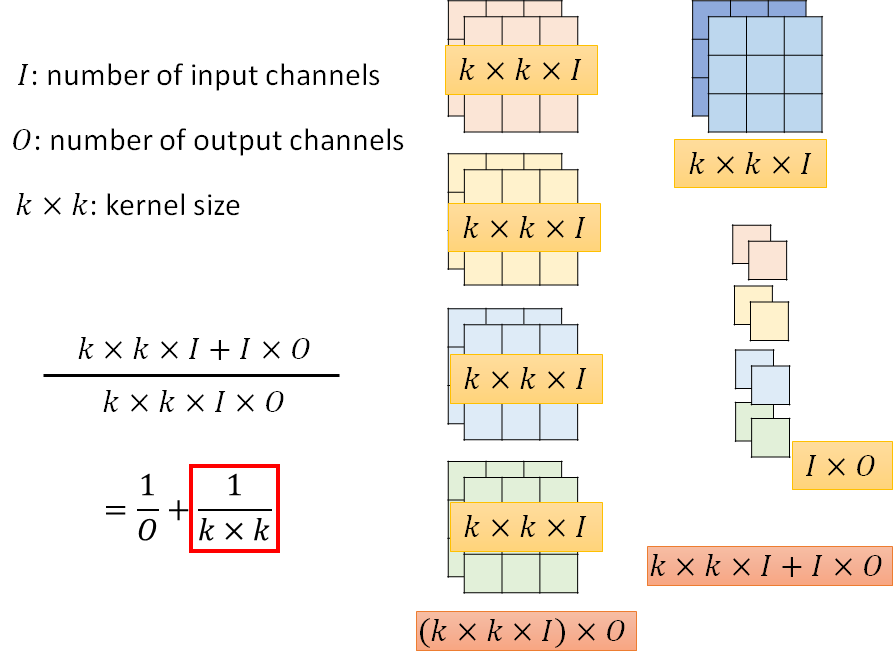
参数计算:
- 普通cnn:有几个output channel,就有几个filler
一般O是512、128等,1/O可忽略,因此可以缩小到1/K^2,比如1/9。
待看的论文:
- SqueezeNet:https://arxiv.org/abs/1602.07360
- MobileNet:https://arxiv.org/abs/1704.04861 用在手机上
- ShuffleNet:https://arxiv.org/abs/1707.01083
- Xception:https://arxiv.org/abs/1610.02357
Dynamic Computation
要想在设备上用,但是每个设备的资源不一样,要怎么样在不同设备上都能用一个好的模型呢
- Train multiple classifiers 训练一批网络模型,根据设备资源的不同,选择其中某个模型。
- Classifiers at the intermedia layer 取模型的不同中间层输出,看输出的分类器是否满足效果需求,看中间层就输出是否满足设备资源的需求。(虽然比如模型是20层,这样功耗比较高,但如果不拿完,就是比如只做前面15层,拿15层的输出做分类,可能功耗没那么高,并且效果也还行)
左下图的意思是,拿初始几层(接近input特征)的输出做分类的结果,不太好,越往后面层拿,效果会越好。因为初始几层input,CNN抽出来的pattern比较简单。
右下图的意思是:本来的模型是只有最后一层有分类器,现在中间好多层都接了分类器,这样多个分类器训练出来的模型效果是不好的。尤其是初始几层就接分类器,会更影响模型效果。(后面几层接分类器,不是很影响效果),这是因为中间层接分类器,会影响到原来整个模型的布局,比如一开始模型就是希望初始几层是抽取初级特征,现在初始几层就接分类器了,相当于让初级特征强行学习高级特征,就会破坏原来布局。
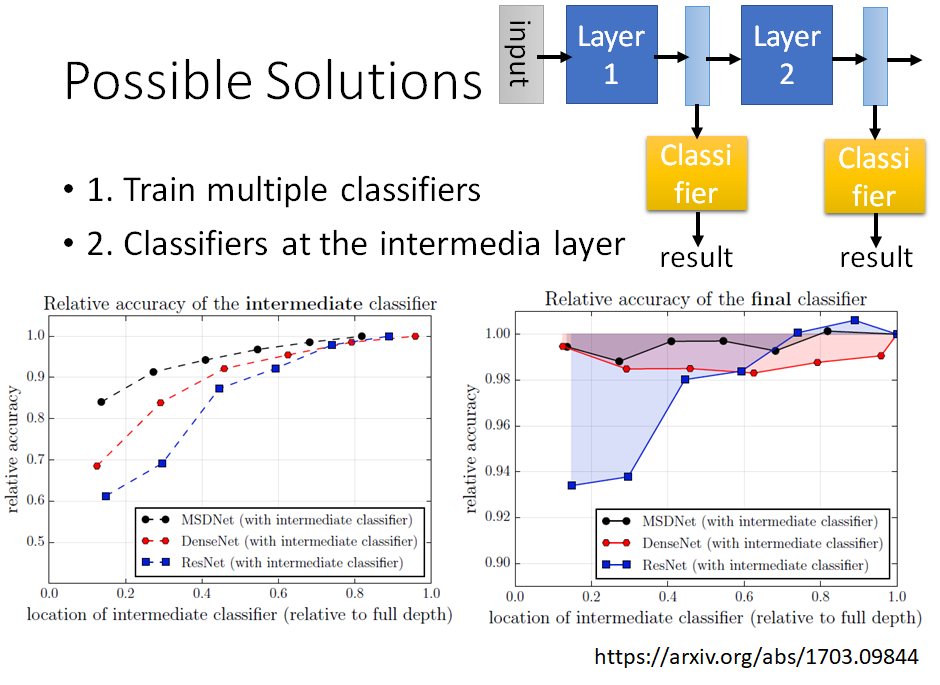
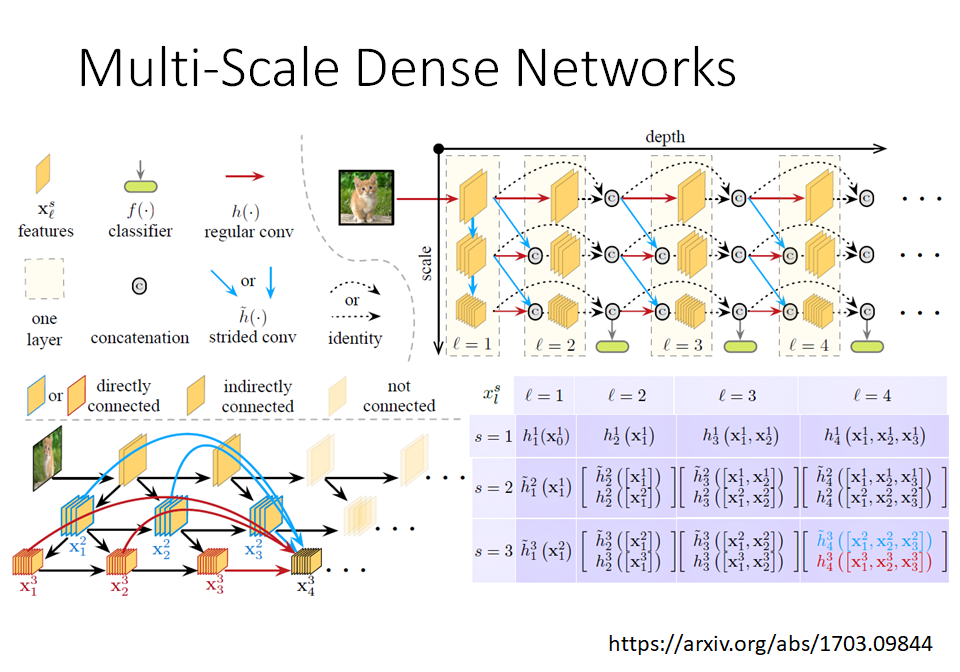
MSD net