wav2vec: Unsupervised pre-training for speech recognition
==Schneider, Steffen, et al. “wav2vec: Unsupervised pre-training for speech recognition.” arXiv preprint arXiv:1904.05862 (2019).==Facebook citations:883
解决什么问题
打破了语音识别声学模型要大量标注数据才能训练好的常规认知。通过学习原始音频表征来探索语音识别的无监督预训练。
提出什么方法
用一批无标签的训练数据,通过contrastive loss,训练一个分类真实音频的无监督模型。(正样本来自无标签数据,负样本来自从噪声中采样)
效果如何
用1000个小时的无标签数据预训练,在WSJ 数据集达到sota。比Deep Speech2论文里在character-based system的效果更好,WER从3.1%下降到2.43%,并且训练数据比其少两个数量级。
超越了frame-wise phoneme classification。
还有什么问题
思路
- 提出一种用无监督预训练来改善有监督语音识别的方法;训练一个无监督预训练模型,用来给下游的语音识别任务作为输入;
- 该无监督预训练模型叫做wav2vec;该模型输入是原始音频,输出是embedding,这个embedding是用大量无标签音频训练得到的,能表示一定的输入音频信息,模型结构用的CNN;loss function是contrastive loss,从negative中鉴别出哪个是真实的 future audio sample;
方法
模型结构全由卷积构成。
输入原始音频x通过encoder network $f:X -> Z$ ,得到具有上下文表示的输出z;
The encoder layers have kernel sizes (10; 8; 4; 4; 4) and strides (5; 4; 2; 2; 2).
causal convolution with 512 channels, a group normalization layer and a ReLU nonlinearity.
输入30ms窗长,10ms窗移,16kHz音频,输出低频特征表示;
然后经过一个context network $g:Z -> C$ ,把encoder的输出z,多个z concat起来经过g得到c:$\large c_i=g(z_i…z_{i-v})$,其中v是感受野,是一个超参;
The context network has nine layers with kernel size three and stride one ,感受野210ms;
encoder network和context network的结构:causal convolution with 512 channels, a group normalization layer and a ReLU nonlinearity.
group norm:在特征和时间维度上对每个样本进行归一化,这相当于用一个单个的归一化组进行group normalization。
发现选择一种对输入的缩放和偏移量无关的归一化方案是很重要的,该归一化方法对于跨数据集泛化性更好;
为了在更大的数据集上训练,还做了一个更大点的模型(“wav2vec large”),在encoder中使用两个额外的linear层和一个相当大的context network(由12个层组成,kernel size不断增加(2,3,…,13))。
在这种情况下,发现在aggregator中引入skip connections来帮助收敛是很重要的。因此,总receptive field增加到 810 ms。
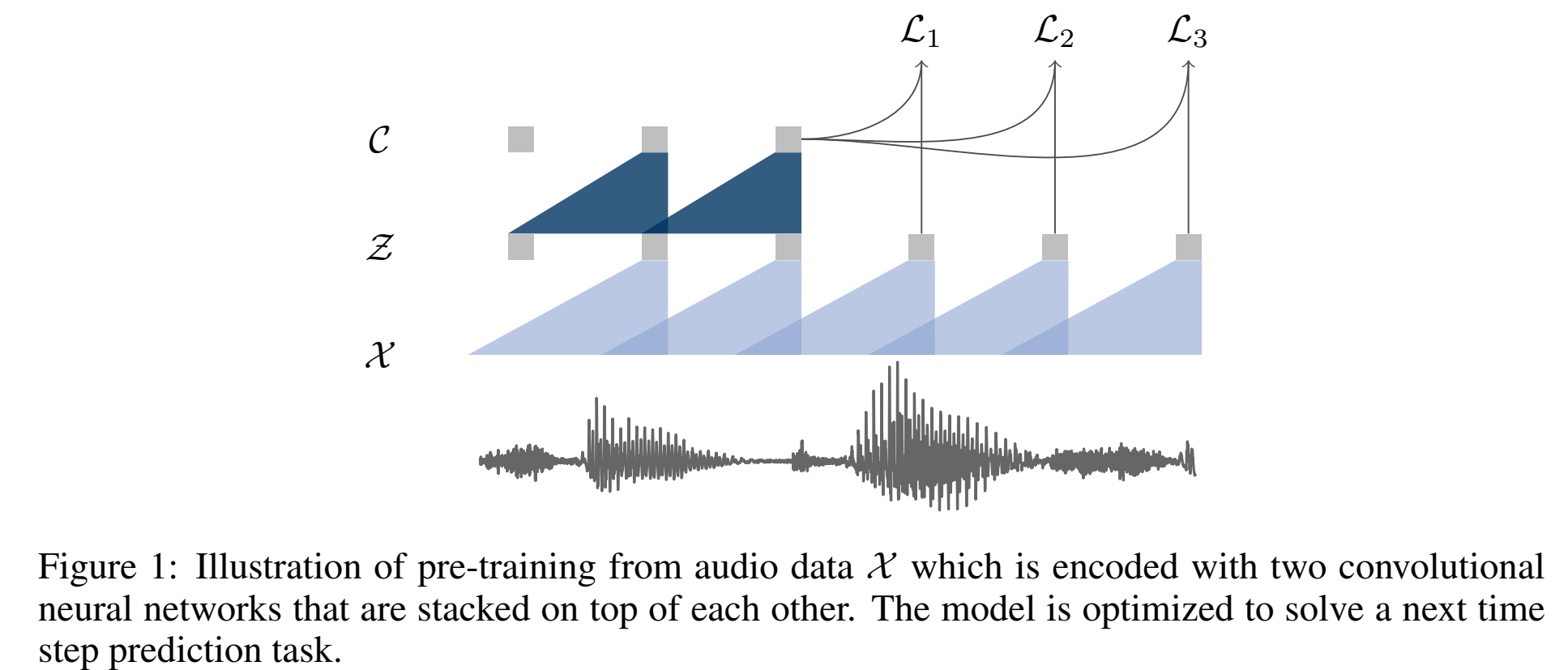
目标函数
loss function:预测未来样本。不是对 $p(x)$ 建模,而是在时间轴建模 $\large p(z_{i+k}|z_i…z_{i-r})/p(z_{i+k})$
作者利用了负采样技术,作者从一个概率分布 $p_n$ 中采样出负样本 $\tilde z$,,最终模型的loss为区分正例和反例的contrastive loss:
训练一个模型,从带有干扰噪声 $\tilde{\mathbf{z}}$(服从$p_n$分布)中区分出、预测出真实样本的未来样本 $\mathbf{z}_{i+k}$,这里 $\mathrm{k}$ 是未来的$\mathrm{k}$步。
最小化 contrastive loss for each step $k=$ $1, \ldots, K$ :
$$
\mathcal{L}k=-\sum{i=1}^{T-k}\left(\log \sigma\left(\mathbf{z}_{i+k}^{\top} h_k\left(\mathbf{c}_i\right)\right)+\underset{\tilde{\mathbf{z}} \sim p_n}{\lambda \mathbb{E}}\left[\log \sigma\left(-\tilde{\mathbf{z}}^{\top} h_k\left(\mathbf{c}i\right)\right)\right]\right)
$$
其中,$c$ 是context network的输出(仿射变换前);sigmoid $\sigma(x)=1 /(1+\exp (-x))$, 因此 $\sigma\left(\mathbf{z}{i+k}^{\top} h_k\left(\mathbf{c}i\right)\right)$ 表示 $\mathbf{z}{i+k}$ 是真实样本的概率。
放射变换每一步的参数都不同? step-specific affine transformation $h_k\left(\mathbf{c}_i\right)=W_k \mathbf{c}_i+\mathbf{b}_k$ for each step $k$, that is applied to $\mathbf{c}_i$ (van den Oord et al., 2018).
把所有步累加起来,最优化loss $\mathcal{L}=\sum_{k=1}^K \mathcal{L}_k$ 。
公式的意思就是希望 真实未来样本和第k步网络输出(anchor)作用后的概率尽可能大,干扰样本和第k步网络输出(anchor)作用后的概率尽可能小。
比如 k=2,未来第2步,T=100,则 $L_2$ 是要累加i=1到i=98那么多帧。这里的 $c_i$ 就是anchor。
i=1时,$\mathbf{z}=\mathbf{z}_3$(在第3帧),$c=c_1$(在第1帧),负样本$\tilde{\mathbf{z}}$ 是除$\mathbf{z}_3$之外的序列其他帧的采样$\lambda$个的均值;
i=2时,$\mathbf{z}=\mathbf{z}_4$(在第4帧),$c=c_2$(在第2帧),负样本$\tilde{\mathbf{z}}$ 是除$\mathbf{z}_4$之外的序列其他帧的采样$\lambda$个的均值;
(还挺神奇???希望当前输入下能输出未来时刻的可能性越高越好,而不是当前输入下输出当前时刻的可能性越高越好,也就是和当前时刻连接最紧密的居然是未来时刻???)
负样本来源:每个音频序列中均匀选择10个干扰样本作为负样本(这样能接近期望,更能混淆),服从的分布表达式为 $p_n(\mathbf{z})=\frac{1}{T}$ (均匀分布)。其中 $T$ 是序列长度, $\lambda$ 是负样本数。
如果负样本是从不同音频、不同说话人里采样的,效果会差。
下游任务
把encoder-context network输出的$c$ 作为embedding,声学特征,作为下游任务的输入,也就是语音识别声学模型的输入(替换掉 FBank 特征)。