wav2vec 2.0: A framework for self-supervised learning of speech representations
==Baevski, Alexei, et al. “wav2vec 2.0: A framework for self-supervised learning of speech representations.” Advances in Neural Information Processing Systems 33 (2020): 12449-12460.== citations:2004
解决什么问题
提供自监督学习里一个好的语音表示。
提出什么方法
mask一部分特征,量化表示,改进loss。
效果如何
- 在Librispeech数据集训练,在clean/other测试集上的WER为1.8/3.3;
- 如果只用1小时训练,效果优于之前方法用100小时训练的结果;
- 只用10分钟有标签训练,53K无标签预训练,WER为4.8/8.2。
还存在什么问题
模型
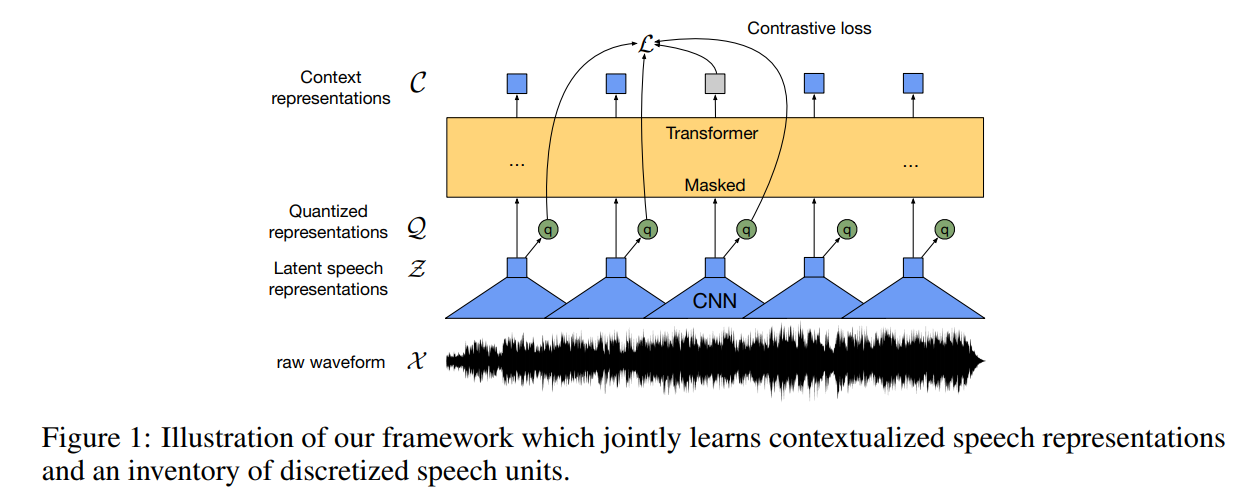
Feature encoder:
$f: \mathcal{X} \mapsto \mathcal{Z}$ 。 结构是多层TCN卷积接LN,接GELU激活。输入encoder的原始波形归一化为零均值和单位方差
Contextualized representations with Transformers (context network):
$g: \mathcal{Z} \mapsto \mathcal{C}$ 。结构是用了卷积做相对位置编码。用了残差,把input接GELU激活加上卷积层输出的和,再接LN。
Quantization module:
$ \mathcal{Z} \mapsto \mathcal{Q}$ 量化encoder的输出,量化后的q来表示自监督目标里的target。用的product quantization:先学discrete units离散单元,再学上下文表示,具体做法相当于从多个码本中选择量化表示,再拼接起来。
给定$G$个码本、$V$个entries $e \in$ $\mathbb{R}^{V \times d / G}$ ,从每个码本里选择一个entry(条目),将得到的向量连接起来 $e_1, \ldots, e_G$ ;
再经过一个linear变换 $\mathbb{R}^d \mapsto \mathbb{R}^f$ ,得到量化表示 $\mathbf{q} \in \mathbb{R}^f$ 。
Gumbel softmax能够以可导的方式选择离散的码本条目。使用straight-through estimator ,设置 $G$ 硬Gumbel softmax操作,则feature encoder的输出 $\mathbf{z}$ 映射到 $\mathbf{l} \in \mathbb{R}^{G \times V}$ logits ,选第 $v$ 个码本entry,对于 group $g$ 的表达式:
$$
p_{g, v}=\frac{\exp \left(l_{g, v}+n_v\right) / \tau}{\sum_{k=1}^V \exp \left(l_{g, k}+n_k\right) / \tau},
$$
其中, $\tau$ is a 非负 temperature; $n=-\log (-\log (u))$ , $u$ 是从均匀分布 $\mathcal{U}(0,1)$ 中采样的的样本;
前向传播中, codeword $i$ 是由 $i=\operatorname{argmax}j p{g, j}$ ;反向传播中,使用Gumbel softmax输出的真实梯度。
。。。。量化这块不懂,TODO
训练
类似BERT的做法,在 latent feature encoder space 中mask一部分time steps。训练目标要求为每个mask时间步,在一组带有干扰项(噪声)中分类出真实的quantized latent audio representation。
Masking
mask一部分feature encoder outputs ,替换为所有mask时间步之间共享的训练过的特征向量。quantization module 的输入不mask。
具体mask操作为:在所有时间步长中随机抽取一定比例p作为起始indces,然后从每个采样index中mask后面的M个连续时间步长,跨度可能重叠。
Objective
用了wav2vec1.0论文里的contrastive task $L_m$,还有增加了一个codebook diversity loss 码本多样性loss $L_d$,鼓励模型多多使用码本entry。
$$
\mathcal{L}=\mathcal{L}_m+\alpha\mathcal{L}_d
$$
其中,$\alpha$是一个超参。
Contrastive Loss
模型要从K个干扰项、1个真实量化latent speech表示$q_t$ 中分类出这个真实的$q_t$。干扰项来自每句话mask的时间步里进行均匀分布采样得到。
Contrastive loss表示为:
$$
\mathcal{L}_m=-\log \frac{\exp \left(\operatorname{sim}\left(\mathbf{c}_t, \mathbf{q}t\right) / \kappa\right)}{\sum{\tilde{\mathbf{q}} \sim \mathbf{Q}_t} \exp \left(\operatorname{sim}\left(\mathbf{c}_t, \tilde{\mathbf{q}}\right) / \kappa\right)}
$$
其中,计算了quantized latent speech representations和context representations之间的余弦相似度 $\operatorname{sim}(\mathbf{a}, \mathbf{b})=\mathbf{a}^T \mathbf{b} /|\mathbf{a}||\mathbf{b}|$ 。
Diversity Loss
为了鼓励每个G码本中equal地使用 V entry,对每个码本$\bar{p}g$最大化averaged softmax distribution $\mathbf{l}$ ,表达式为:
$$
\mathcal{L}d=\frac{1}{G V} \sum{g=1}^G-H\left(\bar{p}g\right)=\frac{1}{G V} \sum{g=1}^G \sum{v=1}^V \bar{p}{g, v} \log \bar{p}{g, v}
$$
公式里不包括temperature 和gumbel noise。
实现上,是最大化 perplexity:
$$
\frac{GV-\sum_{g=1}^G \exp(-\sum_{v=1}^Vp_{gv}\log p_{gv})}{GV}
$$
和上式等价。
Fine-tuning
在context network 后接一个linear层,输出vocabulary大小的分类。