视频 基于多码本向量量化的蒸馏方案
b站视频:姚增伟 【语音之家】AI产业沙龙—如何应用k2开发语音识别系统 或 https://xjw.h5.xeknow.com/sl/2yOtKa 22分钟起
Guo, Liyong, et al. “Predicting Multi-Codebook Vector Quantization Indexes for Knowledge Distillation.” arXiv preprint arXiv:2211.00508 (2022). 郭理勇
微信公众号 新一代Kaldi: 新一代 Kaldi 中基于量化的蒸馏实验
相关代码:https://github.com/k2-fsa/multi_quantization.git
相关代码:https://github.com/k2-fsa/icefall/tree/master/egs/librispeech/ASR/pruned_transducer_stateless6
D:\typora\typora笔记\语音\k2\Predicting Multi-Codebook Vector Quantization Indexes for Knowledge Distillation.md
以下文字和图片主要来自《微信公众号 新一代 Kaldi 中基于量化的蒸馏实验》和《b站视频:姚增伟 【语音之家】AI产业沙龙—如何应用k2开发语音识别系统 22分钟起》
基于多码本向量量化的蒸馏方案,通过将 teacher 模型的高维(如 1280 维)的 float 向量量化为极少数个(如 8 个)uint8 类型的码本索引,显著地降低了存储空间,并基于量化结果进行高效蒸馏。
1 动机与方案概述
1.1 动机
预训练在语音识别中不断刷新 SOTA,但真正用的时候又会有模型太大、流式等问题;
可以使用知识蒸馏的方式用预训练模型 hubert 教 ASR 模型。
假设以 hubert 作为 teacher 模型,其 embedding 将传递给 student 模型用于辅助训练, 传统的蒸馏学习的一种实现方式如下图所示:
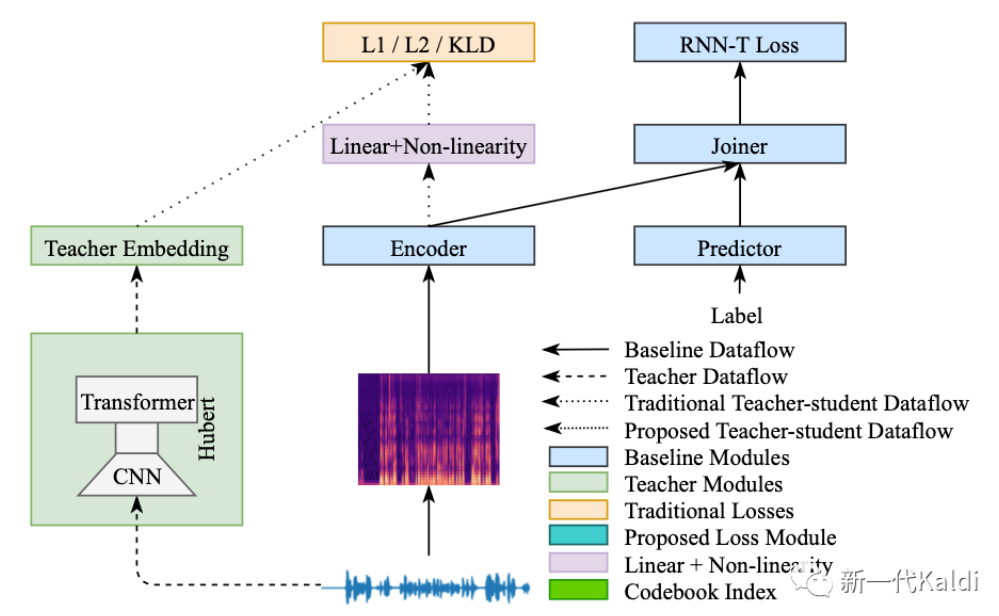
为了获取 teacher embedding, 一般有 online 和 offline 两种方式:
online 的方式需要在训练 student 模型过程中前向 teacher 模型,获取当前 batch 数据对应的 teacher embedding。该方案存在大量重复计算,即每个 epoch 都要把数据过一次 teacher 模型。而且 teacher 模型需要长期驻留显存,如果其参数量过大,还会导致训练过程中只能使用较小的 batch_size, 有可能导致收敛不稳定。
offline 的方式需要在训练 student 模型之前,先把所有的训练数据过一次 teacher 模型,将相应的 teacher embedding 全部存储到磁盘之中,在 student 模型训练时直接从磁盘读取。该方案解决了上述 online 方式的问题,缺陷是可能需要很大的磁盘存储空间。以 HuBERT Extra Large 模型为例,输出帧率为50 frame/s,输出维度为1280,因此100小时音频对应的 teacher embedding 需要存储空间 4 * 1280 * 50 * 3600 * 100 Byte = 92160000000 Byte = 85.8G。在 icefal 的实验设置中,一般会再加上3倍语音增广,因此全量1000小时数据对应的 teacher embedding 需要的存储空间为 85.8 * 10 * 3 = 2.51T。这还只是从 teacher 模型中抽取一层,如果是多层的话,所需存储空间还要相应增大。
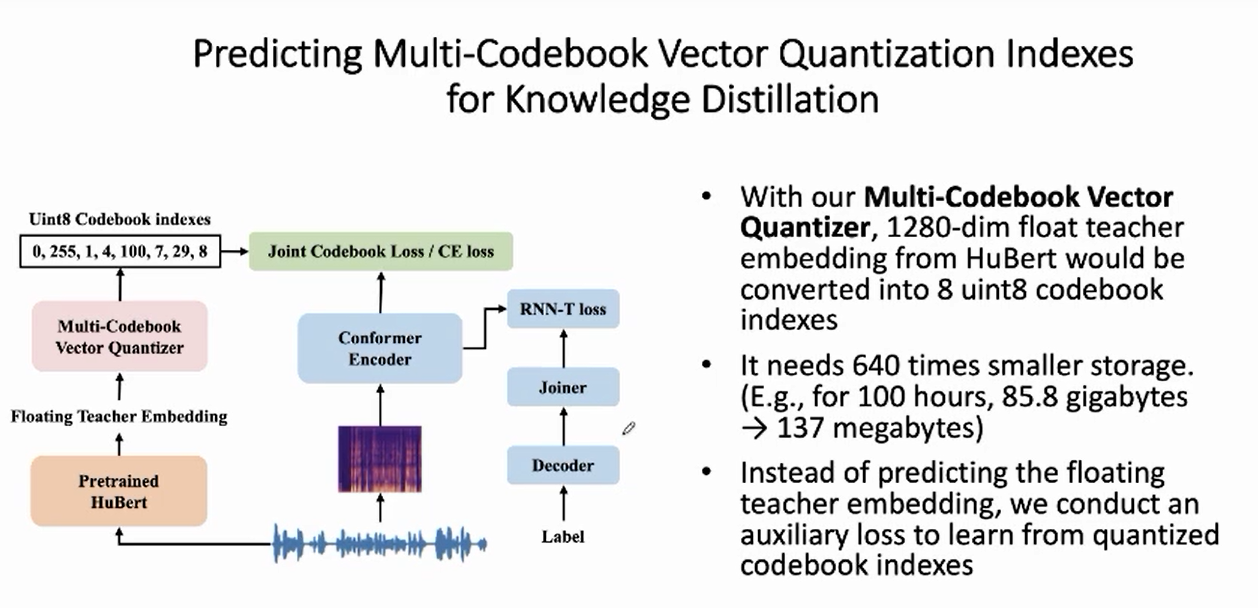
1.2 方案概述
相对于传统的蒸馏方案, Dan哥变革性地提出了使用量化方式进行知识蒸馏。
对于 offline 方式,我们把一个浮点向量 (float embedding) 量化为一组整数 codebook indexes(CI), 且每个整数的范围仅为[0, 255], 因此每个整数仅需一个Byte的磁盘空间。比如上述1280维的浮点向量,量化前需要 1280 * 4 Byte空间; 如果我们将浮点向量量化成8个无符号整数,则仅需 8个 Byte(uint8,一个byte是8bit,0-255), 所需存储空间仅为量化前的 $\frac{1}{640}$ 。
依托这一组量化所得的整数 codebook index 进行蒸馏实验,降低 student 模型语音识别模型错误率。
改进后的蒸馏方案如下图所示,其中最大的变化就是把 teacher embedding 转化为 CI:
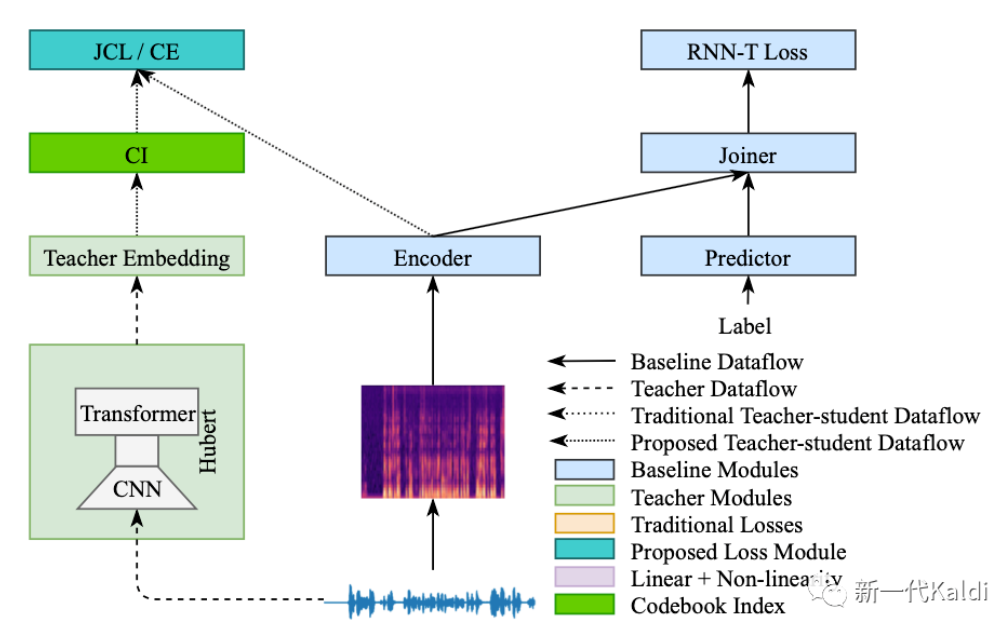
2 术语字典
为了消除本文中潜在的歧义,部分关键的高频词汇简介如下:
浮点向量 (float embedding) : 一般指 teacher 模型中某层的输出向量,作为量化工具的输入;比如 HuBERT Extra Large 的第36层的输出。
codebook index(CI): 浮点向量(float embedding)对应生成的一组整数,取值范围[0, 255],只需一个Byte存储;如果不专门强调,CI 一般指量化所得的一组整数。
num_codebooks: codebook index 包含的整数个数,一般为2的幂,比如2,4,8,16,32;在本文实验中,该参数设置为8。
quantizer: 量化器;输入一个浮点向量,生成对应的 codebook index;其主要包含 encoder 和 decoder 两大模块;encoder 负责将 float embedding 量化为 CI, decoder 负责将 CI 重构为 float embedding。
hubert 模型:在下文蒸馏实验中,用到了 **fairseq 提供的 HuBERT Extra Large Fintuend model**作为 teacher 模型,该模型使用6万小时 Libri-Light 无监督数据预训练,960小时的 LibriSpeech 做 finetune。为了行文方便,有时候简记为 hubert。
teacher embedding: 从 teacher 模型某一层的输出的 float embedding, 此概念着重强调其来自于一个 teacher 模型,用于指导 student 模型的训练。
cd_init: codebook_index initialized value,由 quantizer.encoder模块通过(to_logits + argmax) 生成, to_logits 本质上是 nn.linear。
cd_refined: codebook_index refined value,由 quantizer.encoder 模块通过函数 _refine_indexes 在 $cd_init$ 的基础上优化生成。最终蒸馏实验用的 CI 一般对应该参数。
3 代码仓库
3.1 量化相关代码
最初的代码仓库为 Danpovey/quantizaiton 后来在Dan哥的建议下,迁移至 k2-fsa/multi_quantization 并发布到 pypi, 因此可以采用两种方式安装:
1 | pip install git+https:git@github.com:k2-fsa/multi_quantization.git |
理论上两种方式是等效的,后续我们也会尽量实现二者的同步更新。
3.2 蒸馏实验相关代码
主要涉及 icefall 中的 librispeech/pruned_transducer_stateless6 该 recipe 可以分为两大部分:
quantizer 使用示例,包含数据准备,quantizer 训练,以及 codebook index 提取。
使用 codebook index 进行 ASR 蒸馏实验 该实验中使用 fairseq 驱动其提供的 HuBERT Extra Large 模型作为 teacher 模型。机器配置资源较低的环境可能需要较长的时间提取相应的 codebook indexes. 因此我们已将提取所得的 codebook indexes 开源出来,有需要的朋友可以在示例脚本**distillation_with_hubert**中设置 use_extracted_codebook=True, 跳过提取过程,下载开源的 codebook index 后,进行 ASR 蒸馏实验。
4 quantizer 相关代码解析
4.1 quantizer 训练代码示例
在Dan哥给出的 **quantizer 训练示例代码**中,核心代码及注释如下所示:
1 | # 初始化一个 QuantizerTrainer, |
4.2 quantizer 对 float embedding 的量化与反量化示例
下述代码片段来自 Dan哥提供的 示例代码 ,为了便于添加注释,稍做改动:
1 | # 加载训练所得的 quantizer |
4.3 quantizer 训练算法解析
本节主要介绍上述 trainer.step(x)背后的主要算法细节
强烈建议结合 quantization.py 源码看下面的解析
quantizer 结构如图所示:
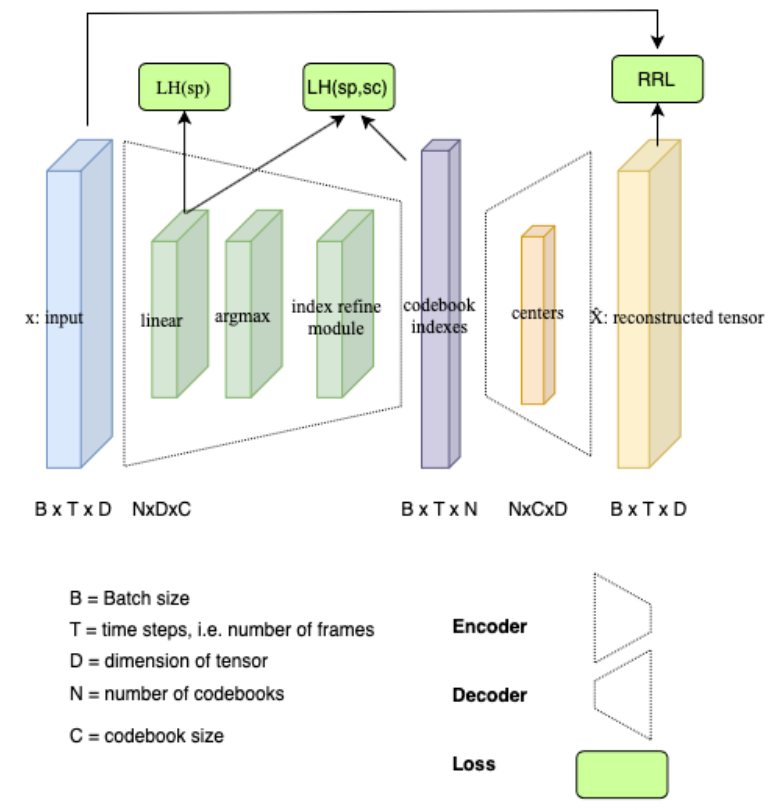
图中RRL对应代码中的 Relative Reconstruction Loss;LH(sp, sc)对应代码中的 logprob_loss; LH(sp) 对应 logits_entropy_loss。如Dan哥在注释中所说,logits_entropy_loss 起的作用较小,有时候甚至不用,本文只重点介绍 RRL 与 logprob_loss。
从总体框架上看,其核心思想与自编码器(Autoencoder, AE)类似,即encoder把输入 转化为中间表示,decoder 把该中间表示重构为输出 , 通过不断降低输入 和输出 之间的重构误差,使中间表示能够有效的承载输入 中的信息。在Dan哥的 multi_quantion 项目中,使用的是相对重构误差(Relative Reconstruction Loss, RRL), 摘抄dan哥在注释中的定义如下:
1 | RRL = sum-squared of (x - reconstructed_x) / (sum-squared of x-x_mean) |
相对于上述经典的自编码器autoencoder, Dan哥在 multi_quantizaiton 项目中做出了如下优化:
中间表示 codebook index,取值范围为[0, 255]; 因此由 float embedding 量化所得的每个整数仅需一个 Byte 的存储空间。
在训练 quantizer 过程中, 通过 _refine_indexes 函数(迭代搜索 codebook_indexes 全局最优函数),迭代搜索 codebook_indexes 的最佳组合,使 encoder 得到的量化结果接近全局最优的效果。
在经典重构误差函数(Relative Reconstruction Loss, RRL) 的基础上,添加 logprob_loss (logprob_loss定义),使得神经网络
encoder直接计算出来的codebook_indexes 不断逼近通过迭代搜索的全局最优组合。(**Dan哥注释原文**(logprob_loss作用):This is added to the loss function, so we can select reasonable classes before refining the indexes)
4.3.1 quantizer 模块分析
下述代码抽取于 class Quantizer 定义:
1 | class Quantizer(nn.Module): |
在上述__init__函数中,有四处值得注意的点:
本质上 Quantize 是一个 nn.Module,所以它本质上是 neural net(nn).
其子模块 self.to_logits 是一个 nn.Linear; 该模块是 encoder 的主要参数。它将一个输入为
dim的向量转化为codebook_size * num_codebooks;比如 dim = 1280; codebook_size * num_codebooks = 256 * 8; 在量化过程中,float embedding 转化为 整数codebook_index代码 摘出来即:
1 | # x 即 float embedding |
argmax 找最大值的索引,作为indexes。
- self.centers 包含了 num_codebooks * codebook_size * dim 个参数,它是 decoder 的主要载体,把整数 codebook_index 重构回 float embedding 的代码摘出来即:
1 | chosen_codebooks = torch.gather(centers, dim=1, index=indexes_expanded) |
- 一些 logits_scale/centers_scale 参数,这些 scale 参数与 reworked conformer 中的 scale 参数异曲同工,都起到帮助模型收敛的目的。
看到上面 encoder 和 decoder 的相关代码,熟悉 pytorch 的朋友可能本能地觉得 “Ah, 就这! encoder 就做个线性变换,取个 argmax 得到个位置 index 就说是 整数 codebook_index;decoder 用这个 位置index 从 parameters 矩阵找到对应的 embedding 加一块“就是重构结果。
在深入解析Dan哥代码之前,先算一笔小账,encoder 输出的 codebook_indexes 理论上大概有多少种可能?能够重构出来的向量大概又有多少种?
假设 codebook_size=256,num_codebooks=1, (当然实际应用中最好不要这样设置,毕竟这个项目的名字就叫 multi_quantization, 让 num_codebooks=1 白瞎了这个名字).
在 num_codebooks=1 时,任意的输入向量 $x$ , 最后都被压缩[0, 255]中的一个整数,自然 codebook_indexes 只有 256种可能,而 decoder 重构出来的结果与 codebook_indexes 一一对应,自然也只有256种可能。
当 num_codebooks=2 时,encoder 会输出两个整数,每个数的范围都是[0, 255], 他们的组合有256 * 256 种可能,而 decoder 重构出来的结果与 codebook_indexes 一一对应,自然也有256 * 256种可能。
当 num_codebooks=8 时,encoder 的输出为 种组合,这个数已经相当大了,是不是1800亿亿?,姑且记作 $Total$ 吧。
而接下来我们要探讨的就是如何从这个巨大的 $Total$ 个候选中,如何不断逼近全局最优组合。
4.3.2 神奇的 _refine_indexes 函数:如何不断逼近全局最优组合
接下来要介绍的_refine_indexes函数 可以说是 multi_quantization 项目中最难的一个函数; 从代码行数可见一斑,算上辅助函数 quantization.py 也只有820行,而这个函数独占L308-L547共计240行!
下面解析中假设 num_codebooks=8, 即一个 float embedding 被量化为 8 个整数。首先根据 encoder 中的 linear + argmax 可以获得一组 codebook_index, 包含8个属于 $[0,255]$ 的整数, 不 妨记作 $c d _i n i t$, 它必然是上面提到的 Total 个组合之一。假设其对应的重构误差为 $R R L _i n i t$ , 现在需要思考一个问题, cd_init 是 Total 中这么多组合中重构误差最小的那么个吗? 或者 说有没有如何找到一组 codebook_index, 让它的重构误差比 $c d$ init 还要来的小?
针对这个问题, 先探究一个特别粗䊁的方案, 记为草量级版本。假设 $c d _i n i t=\left[i_1, i_2, i_3, i_4, i_5, i_6, i_7, i_8\right] ;$ 其中 $i_k$ 是一个属于 $[0,255]$ 的整数。假设暂时不动 $\left[i_2, \ldots, i_7, i_8\right]$ 这 7 个数, 我们把 $i_1$ 位置上的其余 256 种可能性都尝试一遍, 不妨记这些所有的 可能性为 $c d _a l l{ }_ 2 56$, 它们对应的重构误差记为 $R R L _a l l _256$; 然后对 $R R L _a l l _256$ 进行排 序, 取最小值对应的组合作为优化后的量化结果,记为 $c d _r e f i n e d$, 对应的重构误差为 $R R L _$refined, 很明显 $R R L _refined \leq R R L _i n i t$ 。
函数 $_refine_index$ 充分发挥上述 定余求一 的思想, 在 $c d _i n i t$ 的基础上, 通过多轮迭代优化, 最终获得RRL更低的 $c d _r e f i n e d$ 。
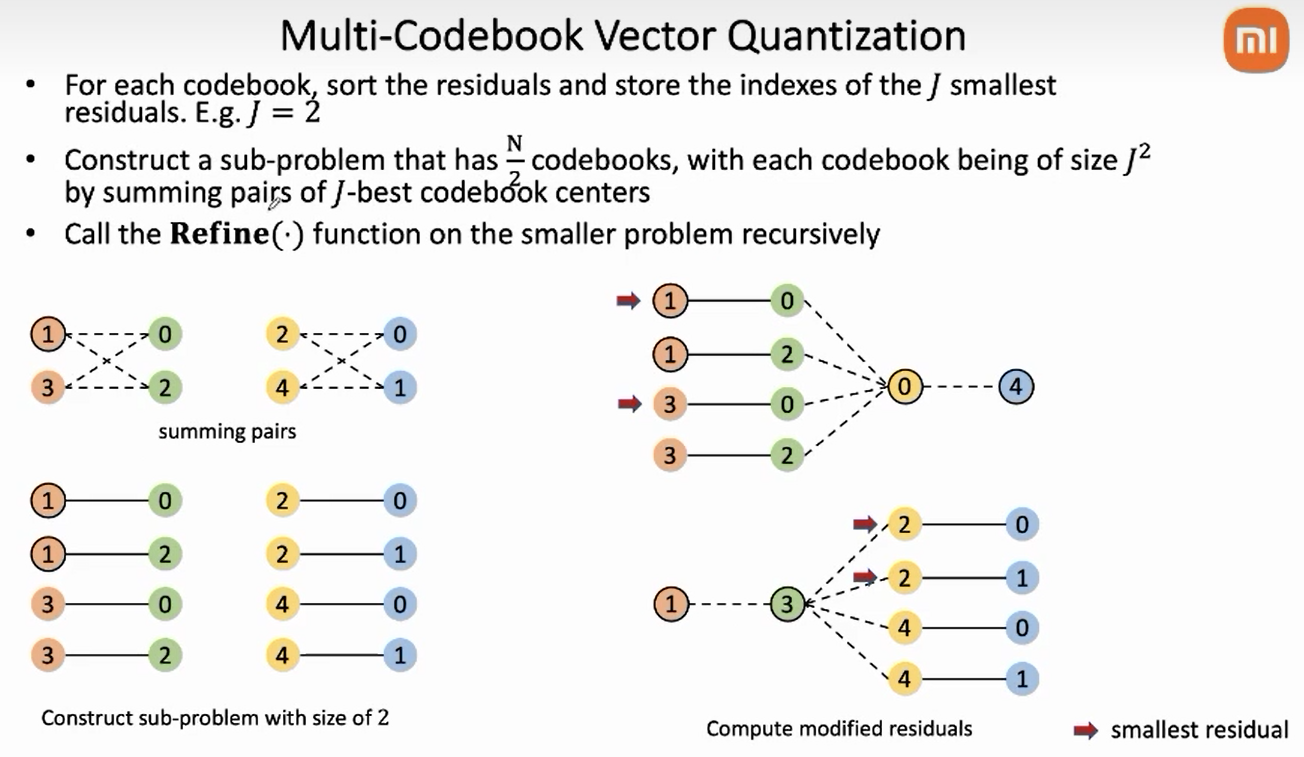
该函数中有三个关键的变量N, K, L, 下图自下而上列出迭代搜索过程中,N-K-L三个数值的变化:
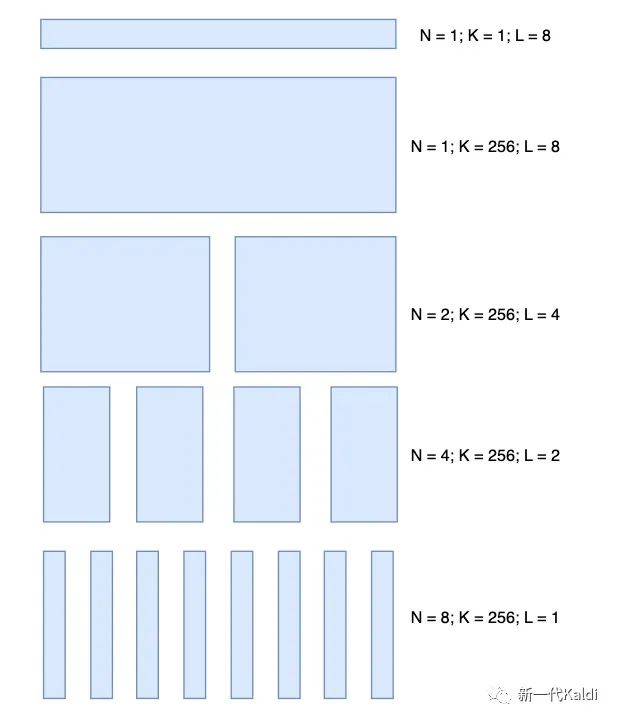
上图每一层代表一轮搜索的过程。其中第一层,可以看做是前述草量级版本的 并行化,记为轻量级版本。其思想在于对于 个位点中的每个 , 穷举其所有的 种可能性,并结合另外7个来自于 的 计算RRL; 对于每个位点,根据RRL的大小对 个候选进行排序,选其中最优的 个进入下一轮迭代。此处对应**Dan哥注释** (K_cutoff注释):
1 | reduce K to K_cutoff by sorting and taking the K_cutoff best possibilities for each choice. |
值得注意的是,每个位点是并行处理的。每个位点在确定自己的最优个 $K_cutoff$ 时,并不知道对方的搜索结果。这就面临一个风险, $i_1$ 位置上的最优个 $K_cutoff$ 个候选是和其余7个来自 $c_init$ 中的 index 一起计算 RRL,但是这7个数在它们对应位置的筛选过程中可能被淘汰掉了。理论上来说,甚至会出现 $RRL_refined > RRL_init$情况!!!
举例:假设 dim=1, num_codebooks=2;即我们要把一个float 量化为两个整数,每个整数的分布范围是[0, 4],self.centers 包含的参数维度[num_codebooks, codebook_size, dim] = [2, 5, 1],其值为:
1 | 忽略最后维度1, 即 shape = [2,5] |
根据以上假设条件, 如果待量化的输入 $x=0.52$, encoder 通过 linear + argmax 得到的 $c d _i n i t=[2,2]$; 此时得到的重构结果为 $\hat{x}=0.3+0.3=0.6$ 。采用上述并行化的轻量级算法, 假设 $K _c u t o f f=1$, 对于位点 $i_1$, 由于 $i_2=2$, 遍历 $i_1$ 的 5 种全部候选值, 显然最佳结果为 $i_1=1$, 即操作 $i_1$ 位置的这部分算法认为它修改后的重构结果应该是 $\hat{x}=0.2+0.3=0.5$;
但是此刻还有一个并行的算法在操作位点 $i_2$, 在位点 $i_1$ 做出决定时, 它在 $c d _i n i t$ 中的 $i_1=2$ 的 基础上做出了 $i_2=1$ 的选择, 即它认为它修改后的的重构结果应该为 $\hat{x}=0.3+0.2=0.5$;
由于 $ K_cutoff =1$, 它们都返回了一个最佳候选, 两路并行程序给出的结果汇总后, 得到 cd_refine $=[1,1]$, 即 $\hat{x}=0.2+0.2=0.4$.
综上, 本来重构结果与目标距离 $-0.08=0.52-0.6$, 一番操作猛如虎之后, 与目标距离成了 $0.12=0.52-0.4$, 反倒还增大了 $50 %$ 。!!!
(就像《麦琪的礼物》)
在实际训练过程中,函数 [_refine_indexes] 一般也不会遇到上面给出的极端反例,一般情况下,$R R L _refined \leq R R L _i n i t$ , 如下所示为 连续5次使用函数 _refine_indexes 重构误差RRL的变化:
1 | loss_per_iter=[0.496, 0.451, 0.439, 0.437, 0.436, 0.435], |
另外引入的 logprob_loss 也可以一定程度上缓解这种情况,详见后文。
言归正传, 回归到 num_codebooks=8, K_cutoff=16 的设定, 采用上述轻量级算法的搜索之后, $\left[i_1, i_2, \ldots, i_8\right]$ 每个位置都从 256 个候选中挑出了 k_cutoff $=16$ 个候选, 他们的排列组合共有 $16^8=4,294,967,296$ 个, 确实比最开始的 1800 亿亿个小了很多, 但是依然很大, 而且后续怎 么处理? 要穷举这个 40 亿个潜在结果吗?
针对上述问题, multi_quantization 项目在轻量级算法的基础上新增加一个 ==Combine pairs of choices== 的机制。将引入该机制后的算法记为重量级算法。
假设 $\left[i_1, i_2, \ldots, i_8\right]$ 每个位点已选出的 $K_cutoff$ 个候选, combine 机制将相邻两个位点分为一 组, 得到 $\frac{N}{2}$, 穷举每组内部的两个位点的所有组合, 共 $K _c u t o f f * K _c u t o f f$ 个; 结合定余求一的思想, 结合 $c _i n i t$ 中其它位点的值, 计算这 $K_{-}$cutoff * K_cutoff 个组合对应的 RRL, 并根 据RRL 取较小的 $K$ _cutoff 个进入下一轮排序。由于此时计算 RRL, 参与排序的是两个相邻位点 的组合, 所以在后续的迭代过程中, 这两个位点要一直捆绑在一起, 即此时 $\mathrm{L}=2$ 。依此类推, 在下一轮次的相邻组 combine 后, $\mathrm{L}$ 会进一步翻倍为 $\mathrm{L}=4$ 。上述解析对应Dan哥代码注释 (N/K/L的变化):
(如上图所示)
采用这种相邻配对分组计算, 定余求一的方法, 不需要穷举上文提到的 40 亿种组合, 仅需计 算 $K _$cutoff $* K _$cutoff $* \frac{N}{2}=16 * 16 * 4=1024$ 种组合,而且它们还可以并行计算, 极大 地提高了搜索效率。
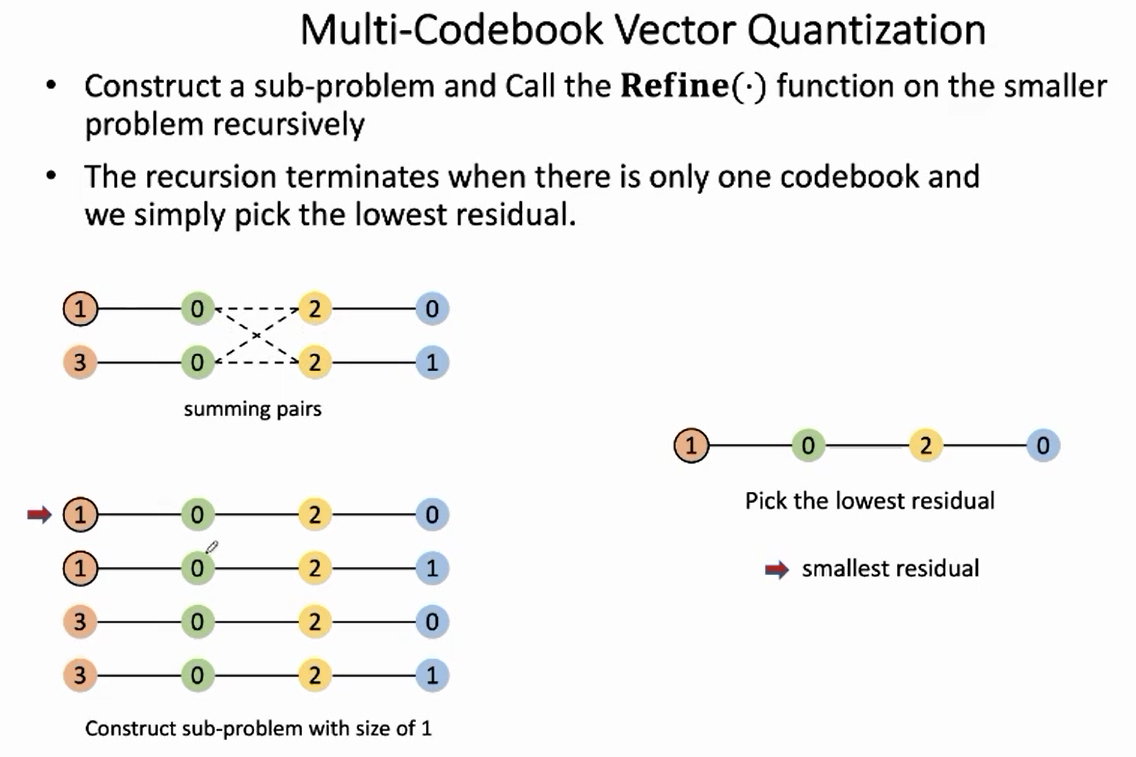
回顾一下上面迭代 refine 的示意图, 每一层都代表一次相邻组配对, 基于定余求一的基本思 想, 对于每个配对的组合选出 $K_{-}$cutoff 个最有候选。每次迭代后, 单个组合的元素个数 L 都 会扩大一倍, 最终 L = num_codebooks, 此时最小值 RRL 对应的组合即为需要求解的 cd_refined。
该算法解析即将进入尾声,最后介绍代码中穷举相邻组两两配对的 trick,**代码如下**:
1 | even_indexes = even_indexes.unsqueeze(3).expand(B, new_N, K, K, L).reshape(B, new_N, new_K, L) |
这两行代码高度相似,只是 unsqueeze(3) 和 unsqueeze(2) 的区别,该处差异刚好穷举了 even_indexes 和 odd_indexes 的两两组合,简单示例如下:
1 | import torch |
【TODO】我只理解大概意思,需要详细结合代码理解。。。。。。。。。。
4.3.3 logprob_loss 的作用
在上文 $c d _r e f i n e d$ 迭代搜索过程中, 一个很重要思想就是定余求一, 也就是说我们在搜索某 一个位点上的较佳候选时, 其余的位点是直接用了用 quantizer.to_logits 对应的 (linear + argmax) 计算出来的 $c d _i n i t$ 的值。万一这个初始值 $c d _i n i t$ 很坑怎么办? 在上文中, 我们也 给出来一个案例, 一通操作之后, 重构出来的结果误差还更大了。在 multi_quantizaiton 库 中, Dan哥给出的优化方案让 quantizer.to_logits 模块去学习 refine 之后的结果, 这样 (linear + argmax)给出的 $c d _i n i t$ 就会不断向 cd_refined 组合逼近。对应的代码为
1 | # Get logprob loss and class-entropy loss |
如Dan哥在注释中所说, 本质上这就是个交叉墒损失函数(Cross-Entropy loss, CE)。从 CE 的 角度看, 相当于以 $c d _r e f i n e d$ 为 label, 去训练 quantizer.to_logits 模块, 从而促使 $c d _i n i t$ 逐 渐接近 $c$ __refined。
至此,我们浅析了 quantizer 背后的一些关键思想,然而Dan哥的设计前后呼应,非常巧妙;上述解析必然有疏漏之处,读者海涵。
5 蒸馏方案解析
5.1 codebook indexes 对应的损失函数
如果跳过层层细节,multi_quantization 的功能就是把一个 float embedding 转化为一组整数 code bookindex。在蒸馏实验中,由于teacher embedding 往往是frame-level的,所以对应的codebook indexes 也是 frame-level 的。
喔,一组 frame-level 的整数,且分布范围是有限的类别(一般在[0, 255]之间)。这看起来和 alignment 非常相似!对于这样的 target, 大家的第一想法恐怕都是用 CE 作为损失函数吧。只不过相对于经典的CE,现在每个 frame 对应多个 target(一组包含多个整数的 codebook index.
在 multi_quantizaiton 库里,提供了一个 JointCodebookLoss 类,当其 is_joint=False 时,就是完全标准的CE损失函数,下述实验的结果即采用此配置得到。把CE又重新包装为 JointCodebookLoss(JCL) 是出于两方面的考虑:
在CE之前加一个linear layer,用于连接 student 网络的输出和 codebook index。
探索 codebook loss 的除了CE之外的使用方式,比如设置 is_joint=True 时,在上述 linear 的基础上,增加了一个利用已知部分CI预测其余位置CI的 regression 分支,目前JCL和CE在不同设置下互有胜负,现阶段暂时推荐使用CE损失函数。
5.2 pruned_transducer_stateless6中的实验配置
5.2.1 采用 hubert 作为 teacher 模型的配置
当前的实验使用的是48层的 HuBERT Extra Large finetuned 后的模型,其输入为 raw audio, 没有 fbank/mfcc 等特征提取环节,输出帧率为50,即1s的输入音频,可以得到50 frames的 teacher embedding。
5.2.2 采用 reworked conformer 作为 studnet 模型
其与 stateless4 中的 reworked conformer结构完全一致,只不过它的第6层被链接到 codebook index 对应的蒸馏 loss。
即实现 hubert 48层模型中的第36层 “连接“到 conformer 12层模型中的第6层的蒸馏方案。
值得注意的是 conformer 的帧率是25, 为 hubert teacher 模型帧率50的一半。为了解决这种 mismatch, 我们将 hubert 得到的相邻两帧 codebook indexs 拼做一帧。即提取过程中设置的的 num_codebooks = 8, 在蒸馏过程中,conformer 每帧对应的其实是16个整数 target.
5.2.3 quantizer 配置
quantizer 的训练不需要太多的数据,在该实验配置中,我们选择了 LibriSpeech train-clean-100的前1000条语音对应的 teacher embedding 作为 quantizer 的训练数据。值得一提的是,在训练 quantizer 之前这些来自不同语音的 teacher embedding 会完全 mix 在一起,充分的 shuffle, 避免 quantizer 学习了一些句内信息。
由于 quantizer 是对 frame-level 的 level 的 teacher embedding 做量化,为了保证来自 teacher 模型的 codebook index 与 student 模型的输出在时间上对齐, 使用 codebook index 做蒸馏时建议关掉 time_warp。
6. 实验结果
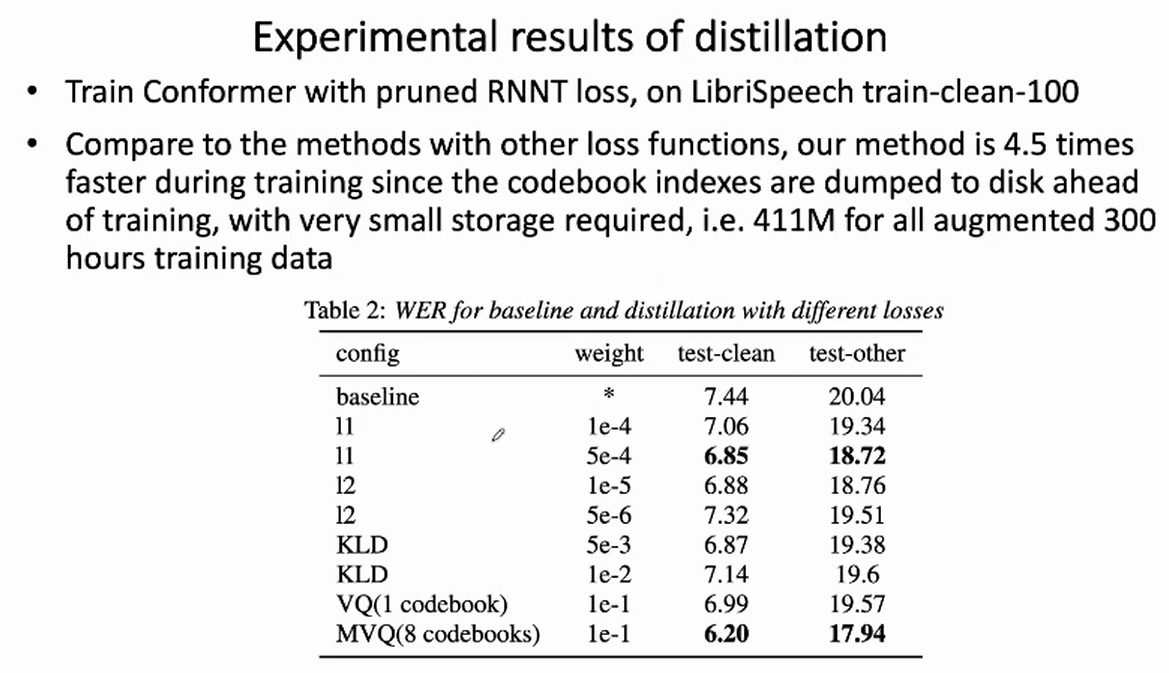
6.1 采用clean-100h实验结果分析
表格中结果分别是在(test-clean||test-other)的(Word Error Rate, WER)。
| - | epoch-20-avg-10 | epoch-30-avg-10 | epoch-40-avg-10 | epoch-50-avg-10 |
|---|---|---|---|---|
| baseline no distillation | 7.09||18.88 | 6.83||18.19 | 6.73||17.79 | 6.75||17.68 |
| distillation with hubert | 5.82||15.98 | 5.52||15.15 | 5.45||14.94 | 5.50||14.77 |
在 icefall中,基于 LibriSpeech 的训练一般不推荐超过30个 epoch。上表中的实验刻意训练了50个epoch。在引入 hubert teacher 模型后,从上表可得出两个比较重要的结论:
由epoch-20/30的结果,可以看出收敛速度速度大大加快,
由epoch-40/50的结果,可以看出其极限WER也更低。
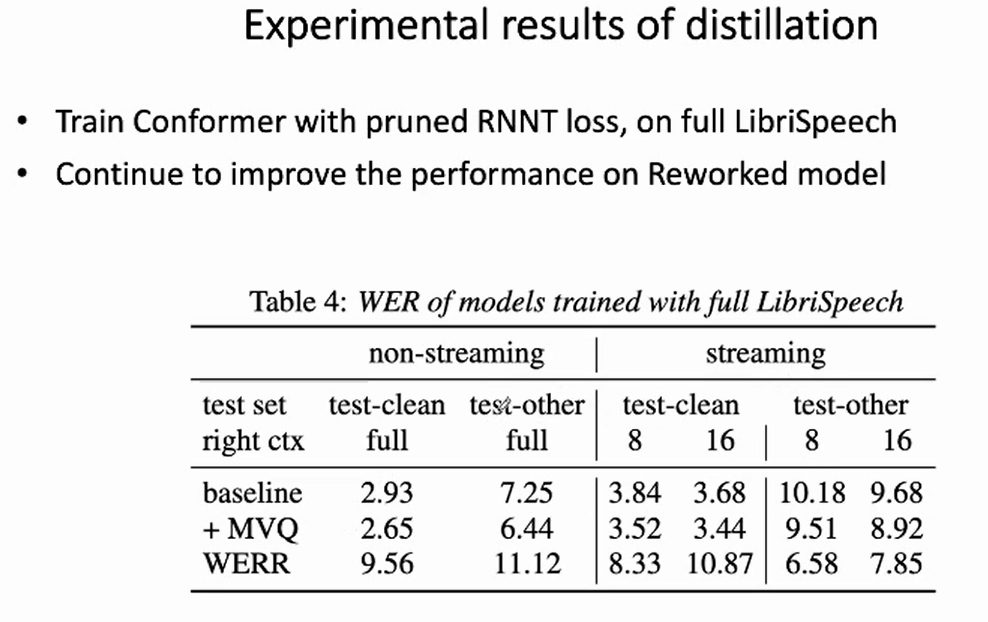
6.2 采用 full librispeech 960h 实验结果分析
6.2.1 non-streaming teacher model 结合 non-streaming student model 结果分析
训练30个 epoch,解码方法为m odified_beam_search
| - | test-clean | test-other |
|---|---|---|
| baseline no distillation | 2.63 | 6.19 |
| ditillation with hubert | 2.30 | 5.57 |
6.2.2 non-streaming teacher model 结合 streaming student model结果分析
训练30个 epoch, 解码配置为 left_context_64, chunk_size=16, right_context=9;
| - | test-clean | test-other |
|---|---|---|
| baseline no distillation | 3.13 | 8.06 |
| ditillation with hubert | 2.93 | 7.43 |
上述两个全量的实验,可以得出两个比较重要的结论:
一个非流式的 teacher 模型不仅能够提升非流式的 student 模型,也可以提升流式 student 模型。
由于该 hubert teacher 模型训练时用到的有标签数据也是 LibriSpeech, 其它数据均为无监督数据。而且该蒸馏方案并没有侵入 student 模型结构,为了蒸馏添加的 JointCodebookLoss 分支在测试和上线的时候可以拿掉。因此该方案给出了一种无需增加标注数据的模型,无需修改已有模型结构,仅使用大量无监督数据即可优化已有模型的方案(可以完全复用已有的模型导出/量化/产线部署工具)。
7. 展望
上文设计的实验仅介绍了该量化工具在 ASR 领域的一些应用实例,然而它的功能远不止于此:
- 更为丰富的蒸馏实验设置。
上文介绍的蒸馏实验仅使用了一个 teacher 模型,一个 student 模型,二者均各取一层。或许拓展为从 teacher 模型中抽取多层的信息甚至使用多个 teacher 模型,共同指导 student 模型不同层的学习,或许能够得到更好地蒸馏效果。
- 该方案应该也可以拓展到其他机器学习领域,比如唤醒、声纹、NLP等任何可以用到蒸馏学习的任务。
8. 总结
本文介绍了Dan哥提出的量化工具 multi_quantization 的基本原理及其在 ASR 蒸馏学习领域内的应用。相较于传统的蒸馏方法,该方案能够大幅度降低所需的存储空间,同时取得了良好的蒸馏效果。该系统通过结合 hubert 模型,给出了一种在不增加标注数据,不修改模型结构及上线逻辑的情况下,依托海量无监督数据提升产线模型性能的可能性。最后提出了一些潜在的实验方向,希望能够有机会与各位业界同仁一起研究,共同进步。
9. 致谢
感谢小米技术委AI实验室孔玉祥、姚增伟、王全东博士和中科院声学所朱涵博士针对该方案的宝贵建议和辛勤付出。
encoder作用:将1280维float向量转成8维uint8的整数,每个整数代表每一个码本对应的索引index。
目标:编码解码重构出的$\hat x$,尽量接近输入的x。
如左图所示,N表示码本数,K表示embedding维度(这里是6,用的时候是256),x进来会先经过一个logit逻辑回归分类器,作为初始码本embedding选择,然后迭代优化。

迭代式的编码策略。
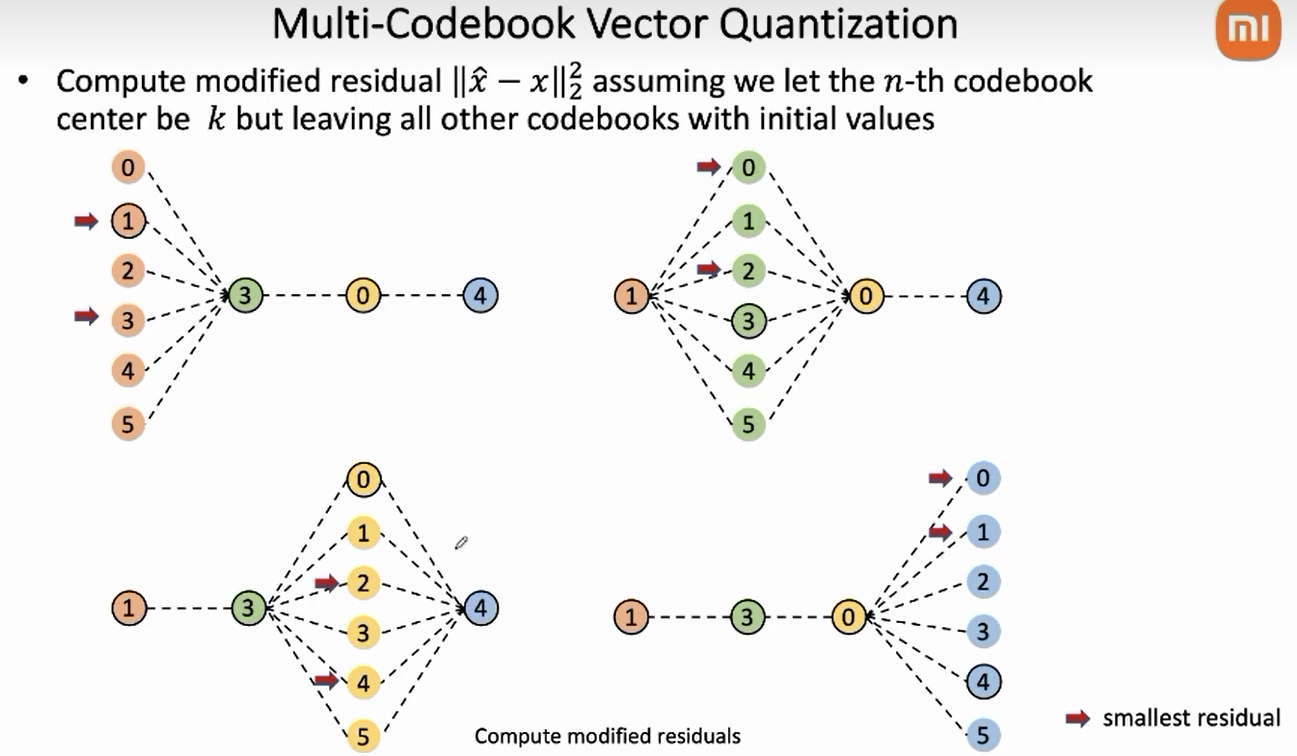
分治