新一代 Kaldi 中的 Reworked Conformer 模型
b站视频:姚增伟 【语音之家】AI产业沙龙—如何应用k2开发语音识别系统 或 https://xjw.h5.xeknow.com/sl/2yOtKa
微信公众号 语音之家:【语音之家】AI产业沙龙—如何应用k2开发语音识别系统 、沙龙回顾 | AI产业沙龙—如何应用k2开发语音识别系统
微信公众号 新一代Kaldi:Reworked Conformer
Next-gen Kaldi: Reworked Conformer Model
Dan K2 #23 Reworked Conformer Model: BAAI Conference P3
Reworked Conformer模型代码: github:https://github.com/k2-fsa/icefall/tree/master/egs/librispeech/ASR/pruned_transducer_stateless2 、 https://github.com/k2-fsa/icefall/tree/master/egs/librispeech/ASR/pruned_transducer_stateless5
本报告将介绍近期新一代 Kaldi 项目的两个核心贡献点。针对 Conformer 模型存在的问题进行改进,实现了训练稳定、性能更优的 Reworked Conformer 模型,其核心思想已拓展应用于 Emformer 和 LSTM 等模型中。

我们使用的 Conformer 模型包含了 12 个 encoder layer,每个 encoder layer 包含了四个模块:Feed-forward + Self-attention + Convolution + Feed-forward,每个模块的输入处以及 encoder layer 的最后输出处各有一个 LayerNorm。
通过使用模型分析工具 ==diagnostics== 对 Conformer 进行分析,我们发现了模型存在的一些问题,并针对问题作出改进,得到 Reworked Conformer。
模型分析工具 diagnostics 实现于 icefall 中,可用于查看模型的参数、激活值及梯度的多种统计量,方便用户分析模型是否训练正常。
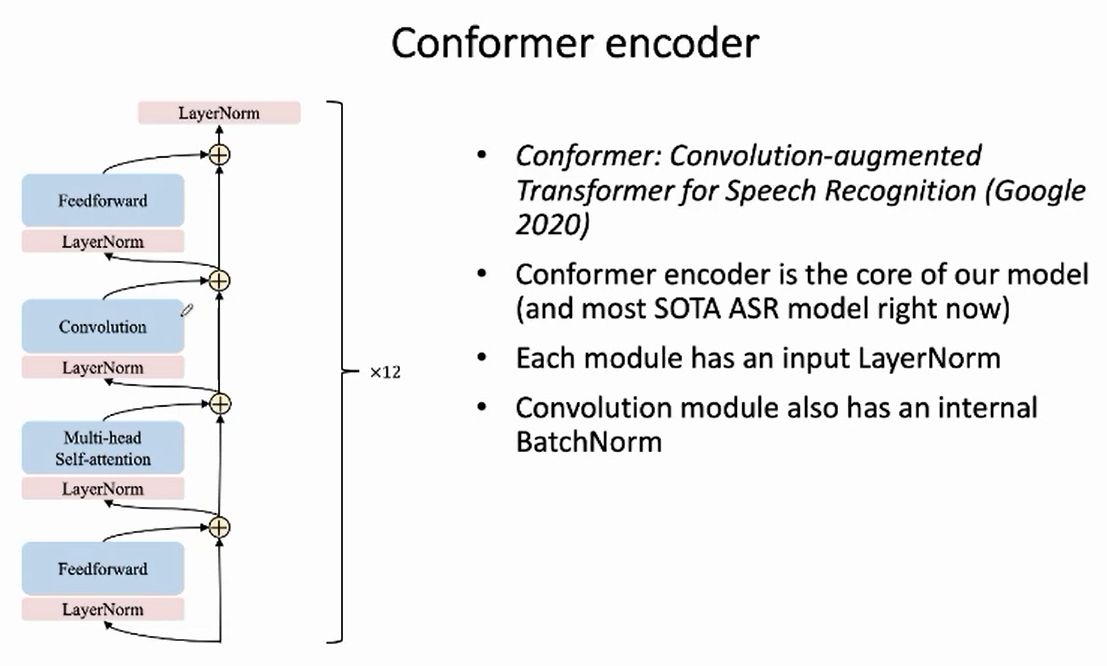
1. 将 LayerNorm 替换为 BasicNorm
batchnorm中两个会更新的超参 $\gamma$ 和 $\beta$ 用来缩放和偏置。

BatchNorm 和 LayerNorm的主要区别在于:
- BatchNorm 的统计维度为 $(B,T)$,在训练过程中累计统计量(均值、方差),测试时使用训练中累计的统计量;
- LayerNorm 的统计维度为 $(C)$,无论训练或测试,都要重新计算统计量。
BatchNorm 假设了 minibatch 中不同的句子(样本)服从独立同分布(iid)。然而,该假设在ASR模型训练过程中,可能会遇到不成立的情况,例如:
- 按照句子长度划分 minibatch;
- 使用多个数据集训练,在不同 minibatch 使用不同数据集。

因此,我们首先将 Conformer 中所有的 BatchNorm 替换为 LayerNorm。
为什么需要 LayerNorm
LayerNorm 的作用主要包括:
- 规范化值的范围,避免在训练中因为值太大或太小而导致 loss 出现 nan 或者 inf ;对于任意长度的向量,LayerNorm 会将其长度规范化为 $\sqrt{C}$,其中 $C$ 为特征通道个数。
- 利用可学习的参数 $\gamma$,调整对应模块对整体模型的贡献。
想去除一些layernorm,加快运行。
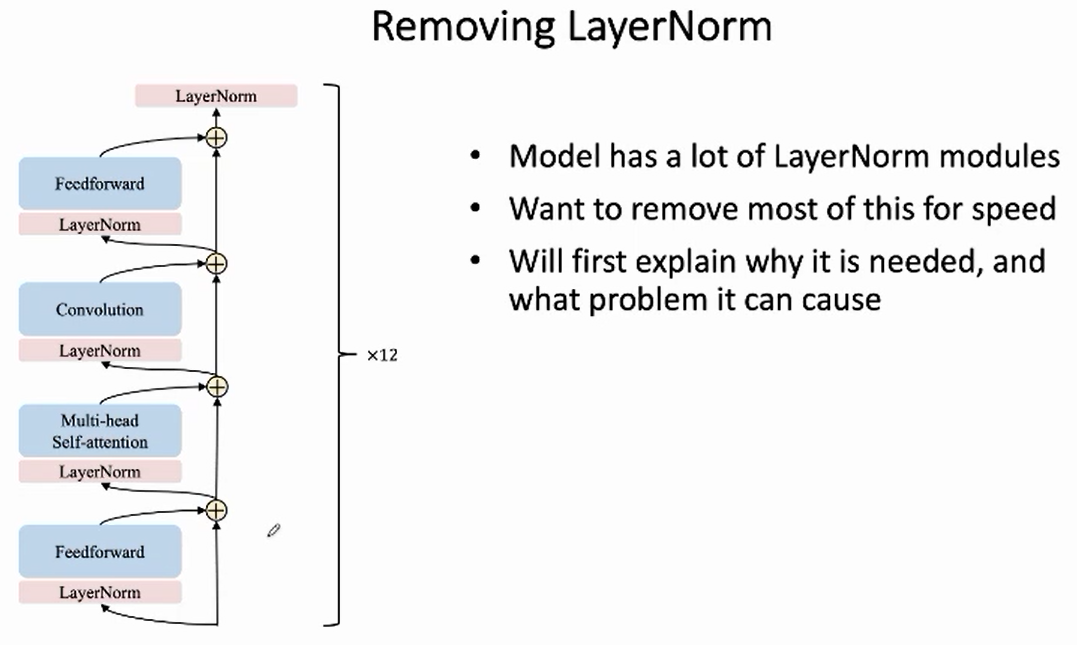
为什么可以去除layernorm:从公式上看:$y=\frac{x-\mathrm{E}[x]}{\sqrt{\operatorname{Var}[x]+\epsilon}} * \gamma+\beta$ , 中的均值 $x-\mathrm{E}[x]$ 是线性操作,可以认为是不必要的。
分母归一化到 $\sqrt{dim}$

- 为什么需要layernorm:
防止激活层后值太大或太小。
$\gamma$ 可以衡量每个模块的激活值对整个模型的贡献程度。
如果用没有weight decay的adam优化器,会有一个问题,就是和学习率有关,随着训练进行,参数的均方根会变大,模型参数会增大。
因此 $\gamma$ 可以起到缩放越来越大的模型参数的作用。

- layernorm存在的问题:
module death
发现有些模块在训练之后一直输出很小的值(比如1e-6),因为早期训练过程中,这个模块还没work,则 $\gamma$ 会缩放到一个接近0的值,相当于“关掉这个模块了”,则layernorm里的下层模块的梯度会一直振荡,则这个模块难以学会有用信息,整个模型优化点相当于陷入了鞍点。

Large constant channel
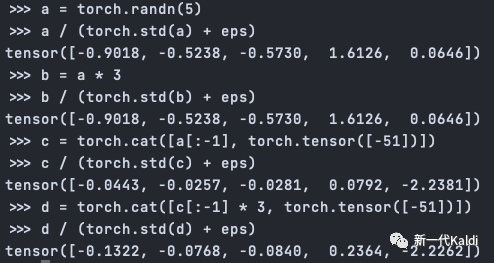
对于一个训练好的模型,观测layernorm的输入,发现总是会有一个维度(channel)的输入值(绝对值)特别大,且恒定的值:-51+-1。出现这个现象的原因可能是,模型企图抵抗 LayerNorm 去除向量长度的机制。因为layernorm会规范化归一化掉,它的目的似乎是为了“击败”layernorm,和layernorm对抗一样,变成一个非常大的$\epsilon$,从而保留(除了该channel之外的)长度信息(因为layernorm归一化会去除长度信息)。
对于这个值特别大的维度,可以认为是“异常值”,需要手动丢掉这个维度。

以下图为例, 向量 $a$ 和向量 $b=a \times 3$ 经过长度规范化后, 长度关系丢失; 向量 $c$ 和向量 $d$ 的 最后一个 channel是一个绝对值很大的恒定值 - 51 , 对于除了该 channel 外的所有 channel, 两 者之间的长度关系 $d[:-1]=c[:-1] \times 3$ 在长度规范化的同时也得到保留。
解释一下,这里向量a、b是一个样本,维度是5,5维理解成是长度length为5,长度里的每个元素由channel向量组成,这里channel只有一个元素,长度为1。所以这里的矩阵维度是 [2, 5, 1],分别是batch、sentence_length、embedding_dim?。。。。
BasicNorm
针对上述问题,对 LayerNorm 作出修改,得到 BasicNorm:
去除layernorm,变成“basicnorm”,把分母的方差换成x平方的均值,加一个可学习的值$\epsilon$(起到异常值的作用)
更新参数通过 $\epsilon .\exp()$ 因此都是正数(前面的 $\gamma$ 不一定正数,可能会在0附近方向振荡,难以学习)

Learnable scales
- 首先,去掉了分子中移除向量均值的操作,因为该操作是一个线性变换,其前面接的是线性层,没有必要进行连续的两次线性变换。
- 在分母中,**引入一个可学习的参数 $\epsilon$**,充当上述的 large constant channel 的角色,目的是在作长度规范化的同时,保留向量的长度信息。此时,输入的向量长度越大,输出向量的长度就越大。
- $\epsilon$ 初始值为 0.25,学习的是该参数的 log 值,用的时候取 exp,确保是正数。
现在 BasicNorm 中没有可学习的放缩因子参数 ,为了保留其权衡不同模块贡献的功能,在每个模块中引入可学习的参数 scales:
1 | self.weight -> self.weight * self.weight_scale.exp() |
由于 scales 是在 log 空间学习,使用时取 exp,为正数,避免了上述由于在 0 左右震荡导致的对应模块参数梯度翻转的问题。
2. ActivationBalancer调整激活值范围
给swish激活层的输入存在两个激活值异常问题:
- 负数问题 Dead neuron:
如果feedforward(LayerNorm + Linear + Swish + Linear)模块里,linear输出的特征有很多都是“负数”,那么经过下一层激活层时,由于激活层用的是swish激活层,就会有很多值接近于零,这些值也是没用的,浪费的。

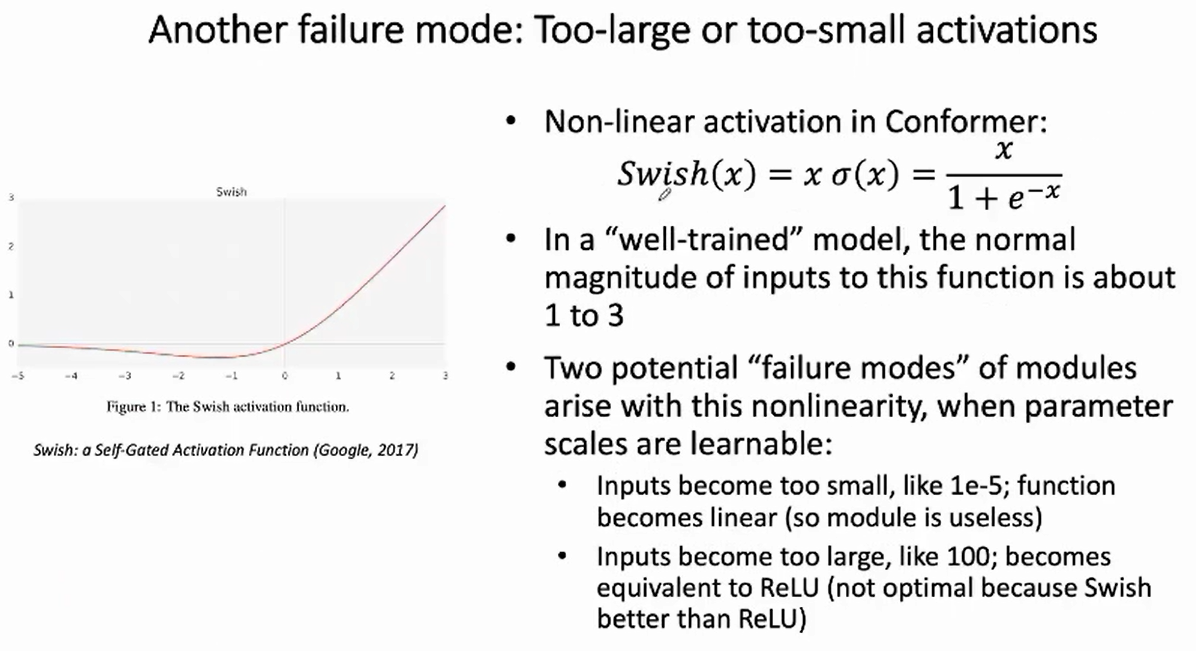
- 范围异常问题 Wrong dynamic range:
对于一个训练好的模型,给swish激活层的输入的数值应该是“1”到”3“之间,(这个是一个比较好的范围)
观察线性层的输出(也就是下一层激活层的输入)发现,存在两种范围异常的情况:一种是太小,1e-5,swish激活会退化成一个线性函数,就没有起到非线性的效果;一种是太大,swish会退化成relu。
为了解决上述两个问题,提出activationbalancer模块,放在linear和swish中间,这个模块包含两个函数,forward和backward,继承自autograd function,子类。
forward pass 前向计算过程中,没有实际做什么操作,只统计记录了哪些通道是有问题的。
backward pass 反向传播过程中,根据forward pass统计的,对应去修改梯度。比如只有5%的值大于0,接下来就惩罚变成负数。
要达到这个目的,还有另一个做法:增加一个loss,作为正则项。发现这个方法不work,因为会使得padding的地方变成一个很大的数。
作者采用的方法是 在反向过程中修改梯度 , 将梯度值放缩到 $1+\epsilon$ 或 $1-\epsilon$ (加号还是减号取决于激活值符号和梯度符号)。
没有直接改变数值,而是在梯度值层面上改变!!好神奇,我没有直接对反向传播的梯度进行过操作。
例如,当统计发现激活值太小的时候:
- 若梯度为负,激活值会朝着数轴的正方向走,这是我们所希望的,此时应当放大梯度;
- 若梯度为正,激活值会朝着数轴的负方向走,这不是我们所希望的,此时应当缩小梯度。
梯度更新要朝着梯度减小的方向走,激活值很小时朝着数轴正方向走才会数值变大,是我们希望的。

3. 效果更好的DoubleSwish
发现使用两次swish能得到更好的效果,于是设计了一个函数,叫doubleswish,函数关系是 $x\sigma (x-1)$ (这里并不是直接swish作用两次)
并且这里有个好处,省内存,梯度值和函数值 很有关系,要求梯度只需保留两个变量 一个是函数值 doubleswish(x),一个是 $\sigma(x-1)$。如果用swish,还需保留变量 $x$(三个变量),因此用doubleswish能起到省内存的作用。

4. 固定参数范数,让学习率控制参数相对变化
参数范数会增大的问题,用layernorm或batchnorm可缓解(因为用可学的放缩因子$\gamma$ 来压下来),但是还存在:
难以直接控制学习率的问题,因为相对变化的大小除以当前模型的范数。。。
参数值很大,那么$\gamma$要很小,会出现梯度振荡,模型难以学习,训练不稳定。
随着训练进行,模型参数范数 RMS(Root-Mean-Square)会随之变大,此时学习率无法直接控制模型参数的相对变化大小。尽管,在参数范数 RMS 增大时,LayerNorm 或BatchNorm 中可学习的参数 $\gamma$ 可以通过缩小来控制值的范围,但是 $\gamma$ 太小的时候会导致上述的训练不稳定的问题。
因此,我们在优化器 AdamW 的基础上修改得到优化器 Eve,其核心思想是对于每个非标量参数,当其范数 RMS 超过 0.1 时,对其进行 weight decay,缩小参数范数。
固定参数范数的操作并不会影响模型的性能,原因是我们在每个模块中引入了可学习的参数 scales。

解决方法:fixed parameter norms
限制每个参数向量的rms模到0.1,对adam优化器加惩罚,adamW,

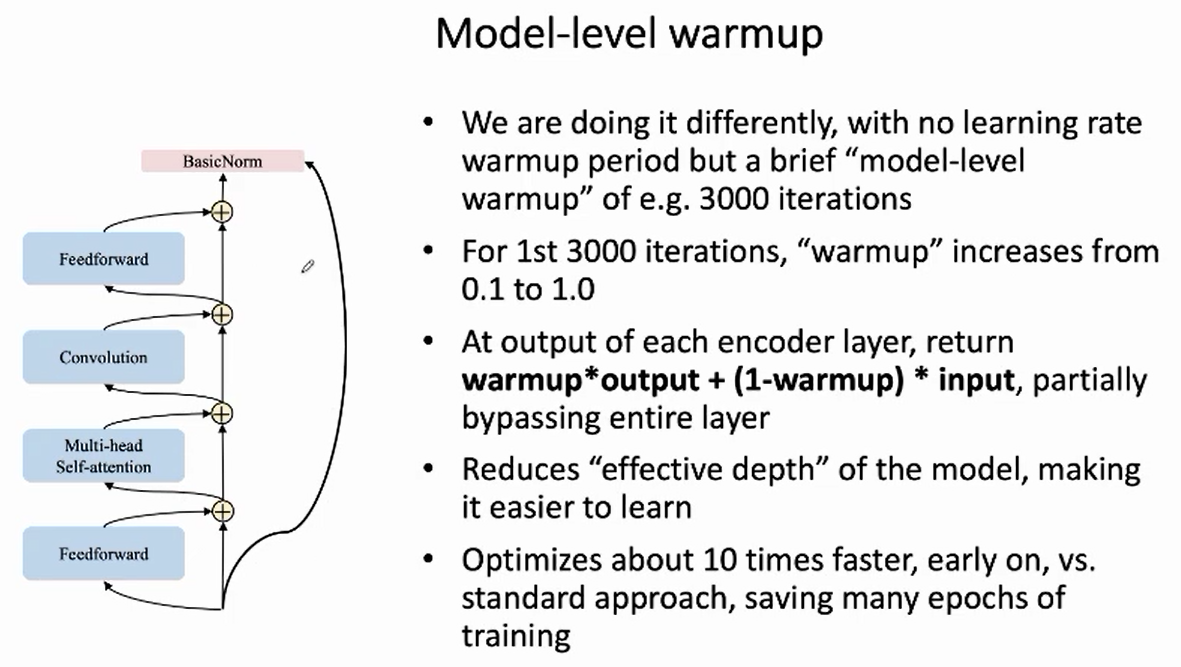
5. 使用Model-level Warmup 机制,加快收敛
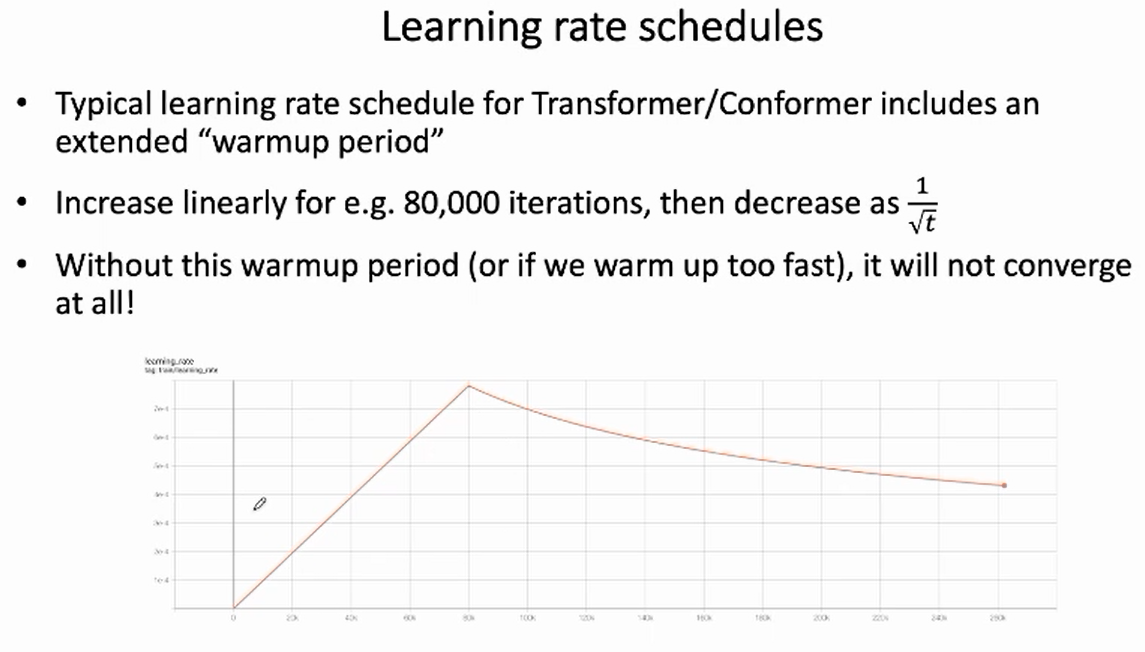
在传统的Transformer训练中,通常采用先升后降的学习率 warmup 机制,这是一种在训练深层模型中常用的策略。如下图所示,在前面 80,000 个 iteration 线性地增加学习率,然后再按照 $\frac{1}{\sqrt{t}}$减少学习率。
接近残差思想
我们提出 model-level warmup 机制,代替上述的学习率 warmup 机制。在前 3,000 个 iteration 中,逐步将 warmup 值从 0.1 增加到 1.0,在每一个 encoder layer 中,返回值为 $warmup*output+(1-warmup)*input$。==该机制相当于在早期的训练阶段,减小模型的有效深度,使得训练更加容易==。
此时,我们不再需要采用先升后降的学习率 warmup 机制。我们在开始的时候使用较大的学习率,然后逐步降低学习率,如下图所示:
缓解受gpu worker数量影响
我们采用的学习率更新策略,兼顾了当前的 epoch 计数 $n$ 和 iteration $t$ 计数 :
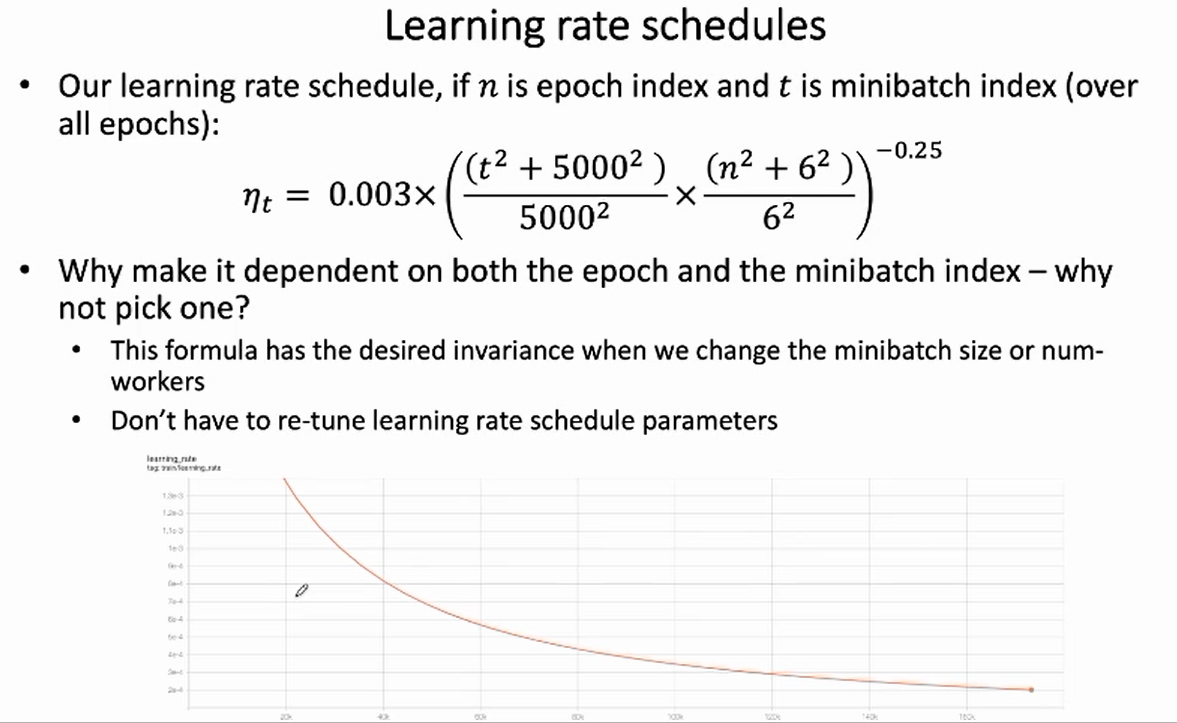
该策略的优势在于,由于同时考虑了 epoch 计数,不再需要因为 minibatch 大小改变而调整学习率更新策略。
实验结果
如下图所示,相比较于原来的模型(橙色),Reworked Conformer(蓝色)在训练开始阶段的收敛速度显著提升,且能收敛到更低的 loss 值。
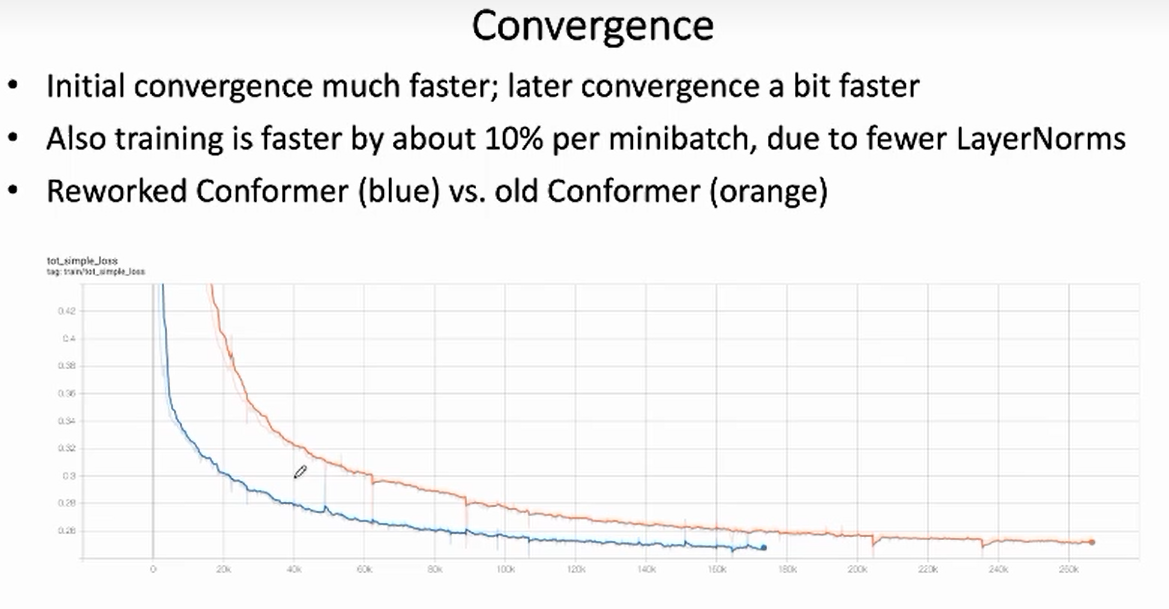
由于 Reworked Conformer 中移除了大部分 LayerNorm ,对于每个 minibatch,训练速度大约加快了 10%。
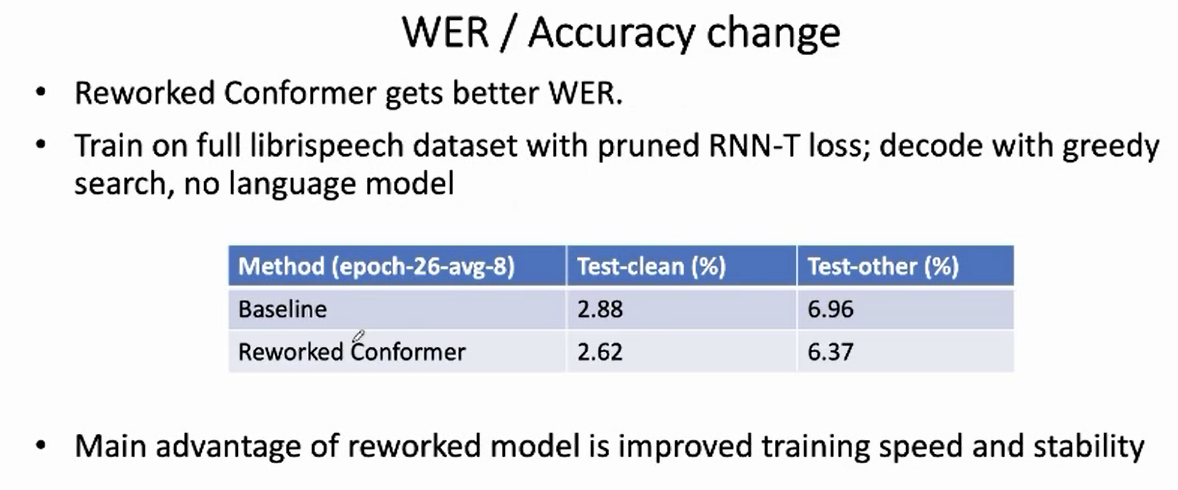
更低的WER
下面的表格比较了原来的 Conformer 和 Reworked Conformer 的 WER。两者都采用了 Pruned RNN-T 损失函数,在 full-librispeech 数据集上训练了 26 个 epoch (avg-8),使用 greedy search 解码方法。可以看出,Reworked Conformer 在 两个测试集上都取得了更低的 WER。
总 结
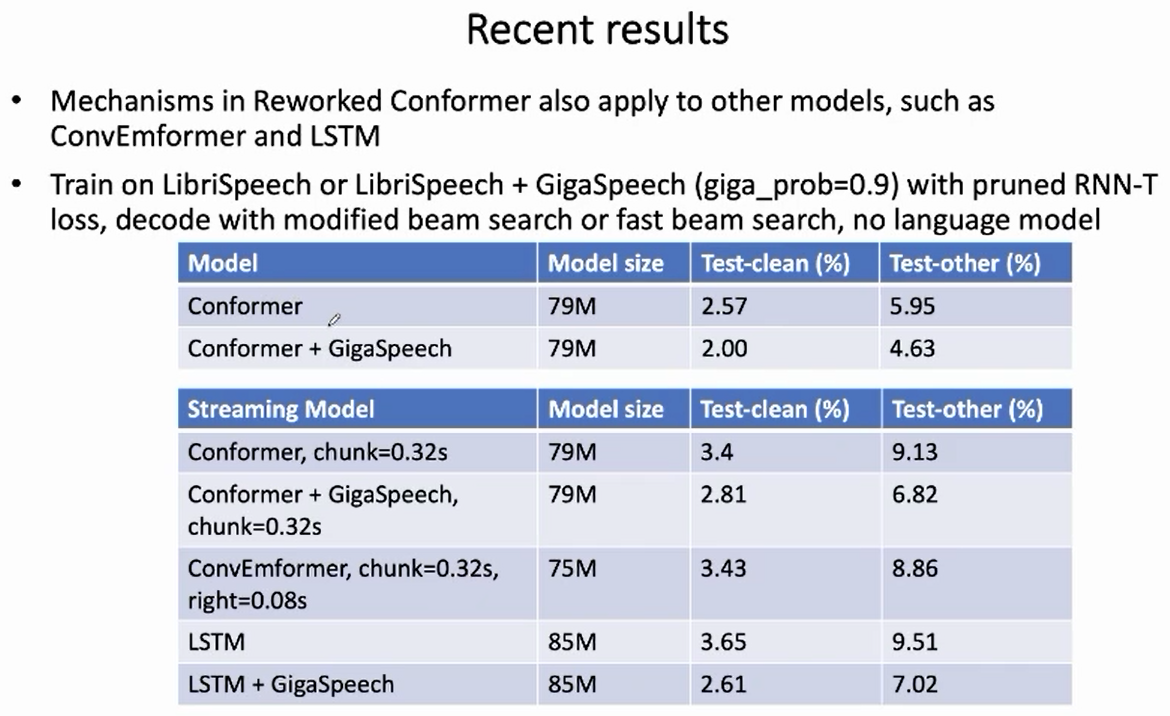
本文介绍了新一代 Kaldi 改进后的 Corformer 模型 —— Reworked Conformer,该模型目前已被用于 icefall 的多个 recipe 中,经过大量实验验证了其优越性、稳定性和可靠性。其中涉及到的改进思想,不仅限于 Conformer,也可泛化到其他模型,欢迎大家尝试。
小结:
reworked conformer这个工作虽然没有写成论文,但是工作量和想法是很多的,出发点是先观察模型中间层的数值,然后考虑该数值对后续层的影响,要怎么解决这些问题。值得一提的是:
- 看出了不同层的输入输出、梯度数值异常;
- 分析了数值异常的原因;
- 从各种角度解决数值问题;