Pruned RNN-T for fast, memory-efficient ASR training. Pruned RNN-T loss
Kuang, Fangjun, et al. “Pruned RNN-T for fast, memory-efficient ASR training.” arXiv preprint arXiv:2206.13236 (2022). citations:9
公众号 新一代Kaldi:多快好省的 RNN-T 训练
公众号 新一代Kaldi:Pruned RNN-T 何以又快又好
开源代码 rnnt_loss.py:https://github.com/k2-fsa/k2/blob/master/k2/python/k2/rnnt_loss.py
Bechmark 的开源代码 transducer-loss-benchmarking:https://github.com/csukuangfj/transducer-loss-benchmarking
- 简介
新一代 Kaldi 针对 RNN-T 损失函数的创新性改进。原始的 RNN-T 损失函数在处理长文本或者长语音的时候显存占用较大,训练时间较长。对此,我们提出对 RNN-T 的 log-probability lattice 进行裁剪,能够在不损失训练精度的前提下大幅缩短 RNN-T 损失函数的计算时间。该工作已经被Interspeech2022 收录。
- 解决什么问题
在 CTC 模型、RNN-T 模型和 attention-based 模型中,RNN-T 是最适合用于产线部署的流式解码模型。但 RNN-T 具有以下几个痛点:
- 训练时,与其他模型相比,占用的内存至少高一个数量级
- 解码时,很难通过以 batch 的方式实现并行解码
用了什么方法
- 提出 pruned RNN-T,改变了 RNN-T 模型中最后一层的输出维度:从
(N, T, U, C)变成了(N, T, S, C),其中 $U \gg S$ 。矩阵变小了,内存使用就降低了。 - 矩阵变小了,Pruned RNN-T 进入 joiner 网络的是更小得多的
(N,T,S,V)向量 ,所以 joiner 网络里面的非线性层和 Linear 层的计算量大大减小,从而大大提高了计算速度。 - Pruned RNN-T 的快部分来自高效的代码实现。
- 提出 pruned RNN-T,改变了 RNN-T 模型中最后一层的输出维度:从
效果如何
具有以下特点:
“多”
- 可以用更大的 batch size
- 可以用更大的 vocabulary size
“快”
- 目前为止,所有常用开源实现中,训练速度最快
- 训练出来的模型,在不降低性能的前提下,解码速度更快
“好”
- 训练出来的模型,在 GigaSpeech 和 WenetSpeech 的 Leaderboard 上,排名第一
“省”
- 省内存
- 目前为止,所有常用开源实现中,所需内存最少
针对问题1,训练部分,展开介绍。
存在问题:RNNT训练时占用内存高
RNN-T 模型最后一层的输出是一个 4-D 的 tensor,维度是 (N, T, U, C), 其中
N: batch size。数值大小: 一般是几十T: encoder 的输出帧数。数值大小:一般是好几百(CTC network,encoder)U: decoder 的输出帧数。数值大小:几十至上百(prediction network,decoder)C: vocabulary size。数值大小:几百至上千
所以,RNN-T 训练时,所需的内存(显存)正比于 N, T , U, C 这 4 个数的乘积 NTUC。训练 CTC 或者 attention-based 模型时,所需的内存(显存)一般与 NTC 或者 NUC 成正比。相比较之下,RNN-T 模型的训练,对内存的要求高了一个数量级。
这样一个大的向量需要占据很大的显存,导致没法使用大的 batch size 来训练,另外,如此大的向量也造成 joiner 网络的计算量非常大,从而增加单次迭代的时间。
为了避免训练时出现 out-of-memory (OOM) 错误,通常的做法是:
- 减少
N,使用一个小的 batch size- 减少
C,使用一个较小的 vocabulary size- 降低模型参数量
但是,使用小的 batch size 会增加模型训练所需的时间;而使用小的 vocabulary size, 可能会影响模型的性能。例如,若以单个汉字为建模单元,vocabulary size 一般是 4000 到 7000 之间。如果使用一个很小的 vocabulary size,那么对于 out-of-vocabulary (OOV) 这种问题,就会更加常见。而降低模型的参数量,也会影响模型的性能。)
那么如何在不降低模型性能的前提下,做到以下几点呢?
- 降低训练时所需的内存
- 降低训练所需的时间
相似工作
微软 Improving RNN Transducer Modeling for End-to-End Speech Recognition:通过移除一个 batch 中所需的 padding 来减少内存的占用量。作者对这个方法提供了一个开源的实现,链接如下: optimized_transducer。相关 benchmark 数据表明,这种方法在所有标准的 RNN-T 开源实现中,所需内存最低。
解决方法
提出 pruned RNN-T,pruned RNN-T 改变了 RNN-T 模型中最后一层的输出维度:
- 从
(N, T, U, C)变成了(N, T, S, C)
其中,S 是用户指定的一个参数。我们所做的实验中,一般选用 5;而 U 则一般是几十甚至上百。
结果就是,所需的内存与 NTSC 成正比,而不再是 NTUC。
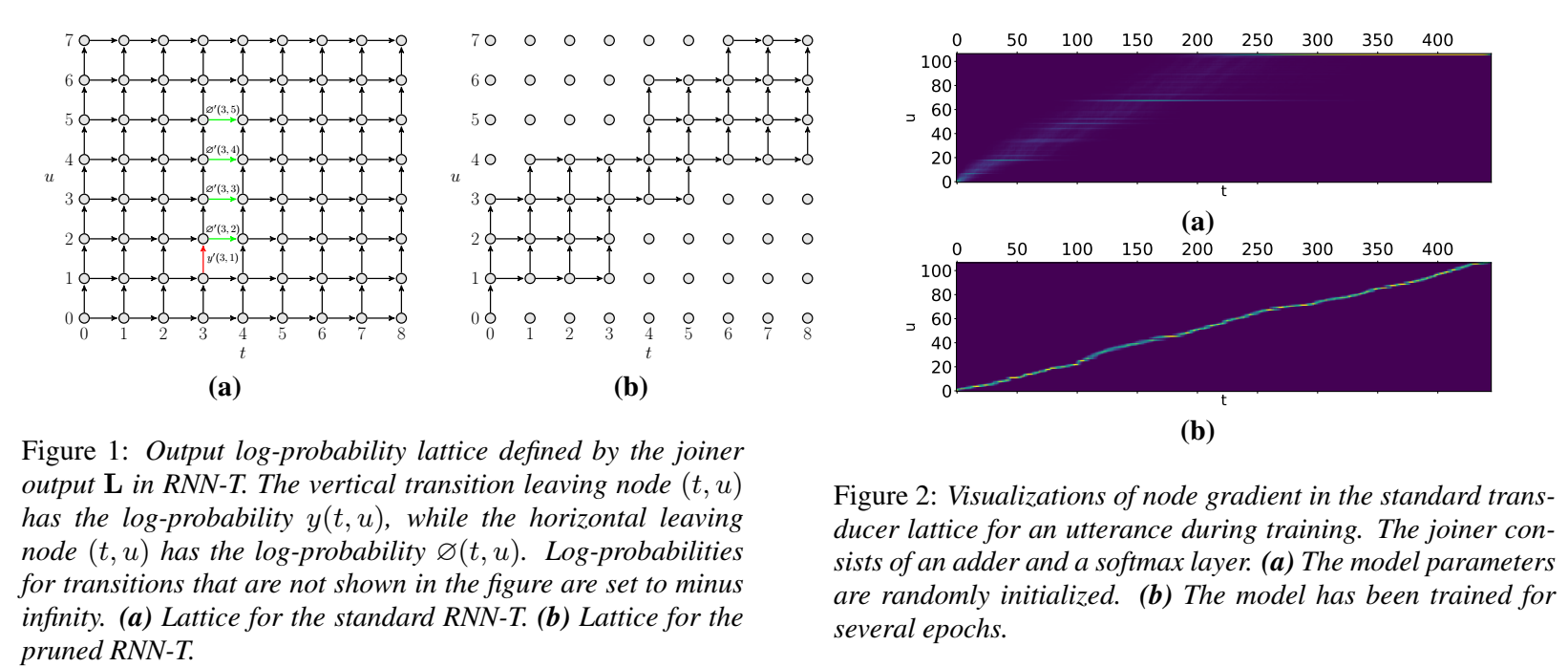
图1(a)是针对标准的 RNN-T,图中所有的结点都参与了RNN-T loss 的计算。
作者提出一个很有意思的问题:是不是所有的结点都应该参与计算?然后做出论证,如图2所示。
图2 显示了图 1(a)中每个结点在训练时某一时刻的梯度。我们可以看到,==随着训练的进行,靠近对角线上的结点对计算起到的作用最大。也就是说,不同位置的结点,在训练中起到的作用不同。==
图1(b)则是针对 pruned RNN-T,图中只有部分结点参与了 RNN-T loss 的计算。
参与计算的结点数量越少,所需的计算量则越少、计算速度就越快,并且所需的内存也越少。
- 哪些结点应该被选出来参与计算呢?
- 又如何选择这些结点呢?
音频和文本的单调对应特性决定了 lattice 中的大多数节点对最终的 Loss 几乎没有贡献。
trivial joiner 平凡联合网络
为了确定剪裁的边界,我们提出了一个“平凡联合网络”(trivial joiner)的概念,这个 trivial joiner 是 encoder 和 predictor 的简单相加,即 am + lm。使用这样一个简单的 joiner 网络是为了在不生成四维向量的情况下得到一个 lattice,以便在这个 lattice 上求得剪裁边界。下图是 Pruned RNN-T 计算的流程图,我们实际上计算了两次损失函数,一次是在上述的 trivial joiner 上,一次是在正常的包含非线性层的 joiner 上(下图中的 s_range 就是上面提到的 S)。
.png)
在一个 lattice 中,每一个节点包含了两个概率,即 $y(t, u)$ 和 $\varnothing(t, u) $, $ y(t, u)$ 表示在第 $t$ 帧给定 $y_{0 . . u}$ 的情况下发射 $y_{u+1}$ 的对数概率, $\varnothing(t, u)$ 则代表在第 $t$ 帧给定 $y_{0 . . u}$ 的情况下 发射 blank 的对数概率。由于 trivial joiner 是个简单的相加,所以我们不需要在相加之 后的向量中来获取这两个概率,只需分别在 $a m$ 和 $l m$ 中获得这两个概率,然后将 $a m$ 和 $l m$ 中得到的概率分别加起来就行。获取概率的操作就是个简单的查询,在代码中使用 torc h. gather 来实现,这个过程和乘法分配律非常相似。
注:两个 shape 不一样的向量相加得先统一 shape,即
logit = am.unsqueeze(2) + lm.unsqueeze(1),所以如果相加之后再获取概率,我们就不得不生成一个四维向量。
剪裁边界的确定
TODO。。。。。。
实验及结果
pruned RNN-T 在以下几方面的结果:
- 训练速度
- 训练所需内存
- 在LibriSpeech test-clean 测试集上的 WER 及 RTF
在进行 benchmark 时,我们采用 LibriSpeech test-clean 测试集来生成 RNN-T 模型训练时所需的维度信息, 而不是针对特定的维度进行 benchmark。这样可以考虑每个 batch 中 padding 所造成的影响,尽量还原真实的应用场景。
我们设置了两种 bechmark 模式:
- (1) 以随机的方式组成 batch。batch size 为 30。
- (2) 按照样本时长进行排序的方式组成 batch。每个 batch 中最多包含 1万 帧特征。
在论文中,我们对比了 pruned RNN-T 和 常用的开源 RNN-T loss 实现的性能。结果如表 1 和 表 2 所示。我们可以看出,不管是在训练时间还是在内存使用量上, pruned RNN-T 与其他实现相比,都有很大的优势。