Socket通信
b站:socket到底是什么? 对应公众号:socket到底是什么?
百度百科粗略的一个解释
(百度百科粗略的一个解释,有浅显的一个理解,大概就是不同主机通信,收发数据的一个桥梁。)
socket(套接字):对网络中不同主机上的应用进程之间进行双向通信的端点的抽象。一个套接字就是网络上进程通信的一端,提供了应用层进程利用网络协议交换数据的机制。 Socket是由IP地址和端口结合的,提供向应用层进程传送数据包的机制。
socket表示方法:套接字Socket=(IP地址:端口号),套接字的表示方法是点分十进制的lP地址后面写上端口号,中间用冒号或逗号隔开。每一个传输层连接唯一地被通信两端的两个端点(即两个套接字)所确定。例如:如果IP地址是210.37.145.1,而端口号是23,那么得到套接字就是(210.37.145.1:23) 。
socket主要类型:
1.流套接字(SOCK_STREAM)
流套接字用于提供面向连接、可靠的数据传输服务。该服务将保证数据能够实现无差错、无重复送,并按顺序接收。流套接字之所以能够实现可靠的数据服务,原因在于其使用了传输控制协议,即TCP(The Transmission Control Protocol)协议。
2.数据报套接字(SOCK_DGRAM)
数据报套接字提供一种无连接的服务。该服务并不能保证数据传输的可靠性,数据有可能在传输过程中丢失或出现数据重复,且无法保证顺序地接收到数据。数据报套接字使用UDP( User DatagramProtocol)协议进行数据的传输。由于数据报套接字不能保证数据传输的可靠性,对于有可能出现的数据丢失情况,需要在程序中做相应的处理。
3.原始套接字(SOCK_RAW)
原始套接字与标准套接字(标准套接字指的是前面介绍的流套接字和数据报套接字)的区别在于:原始套接字可以读写内核没有处理的IP数据包,而流套接字只能读取TCP协议的数据,数据报套接字只能读取UDP协议的数据。因此,如果要访问其他协议发送的数据必须使用原始套接。
套接字之间的连接过程可以分为三个步骤:
- 服务器监听:服务器端套接字并不定位具体的客户端套接字,而是处于等待连接的状态,实时监控网络状态。
- 客户端请求:由客户端的套接字提出连接请求,要连接的目标是服务器端的套接字。为此,客户端的套接字必须首先描述它要连接的服务器的套接字,指出服务器端套接字的地址和端口号,然后就向服务器端接字提出连接请求。
- 连接确认:当服务器端套接字监听到或者说接收到客户端套接字的连接请求,就会响应客户端套接字的请求,建立一个新的线程,并把服务器端套接字的描述发送给客户端。一旦客户端确认了此描述,连接就建立好了。而服务器端套接字继续处于监听状态,接收其他客户端套接字的连接请求。
socket使用场景
将数据从A电脑的某个进程发到B电脑的某个进程。
socket白话理解
为什么操作系统没有暴露tcp udp这些协议的使用给应用,说白了太底层了,用了一层socket封装,通过socket去操作底层协议的具体实现,应用程序只需要用socket暴露的API就好了。
一个内存里的抽象数据结构,用于管理硬件网卡对数据的收发。
通信(网络传输)过程:
b站:socket到底是什么? 对应公众号:socket到底是什么?
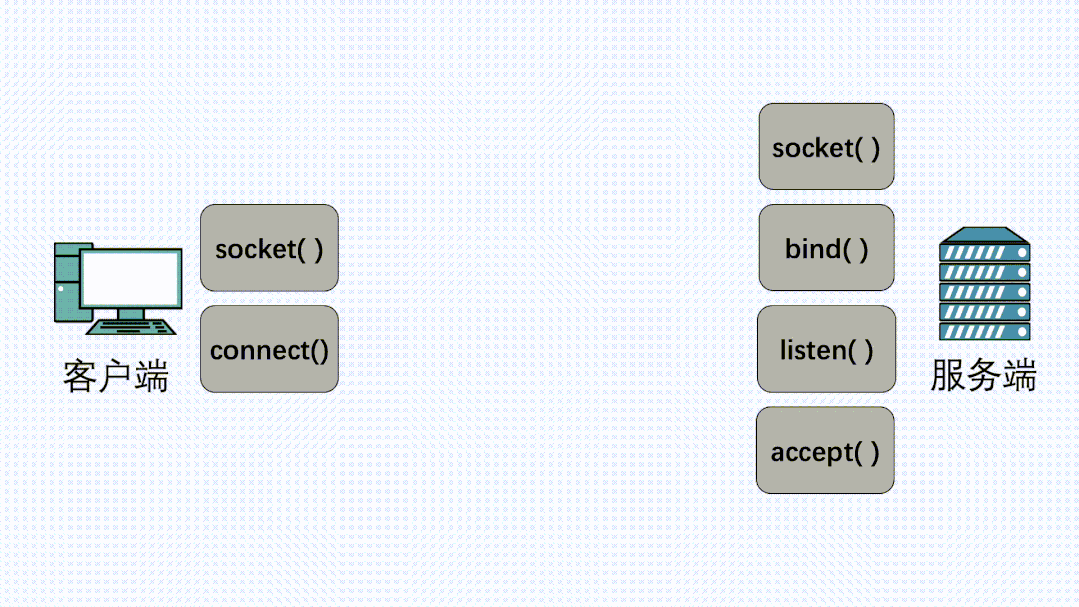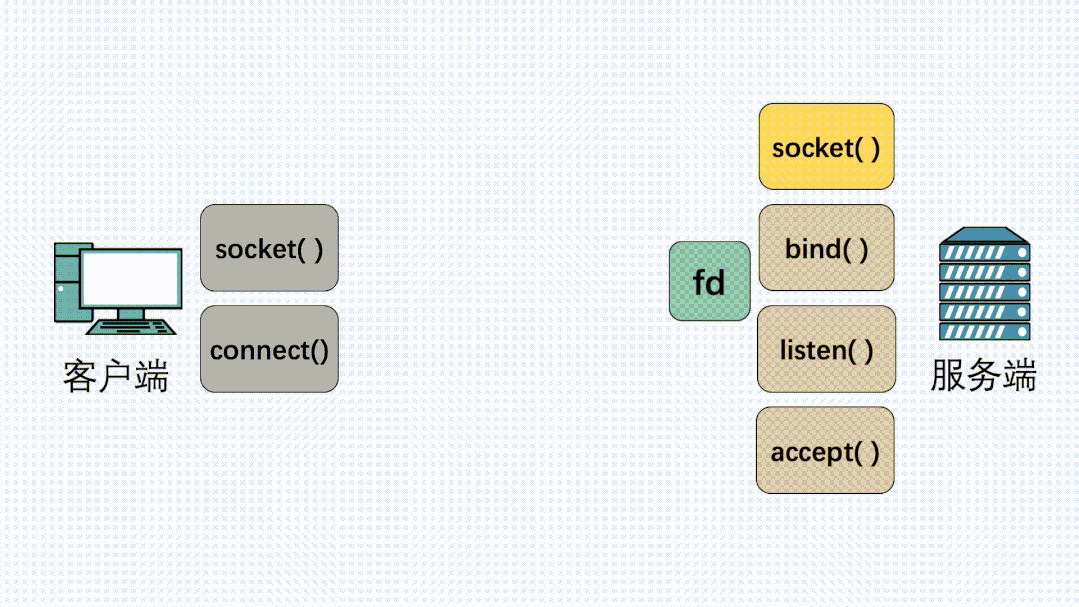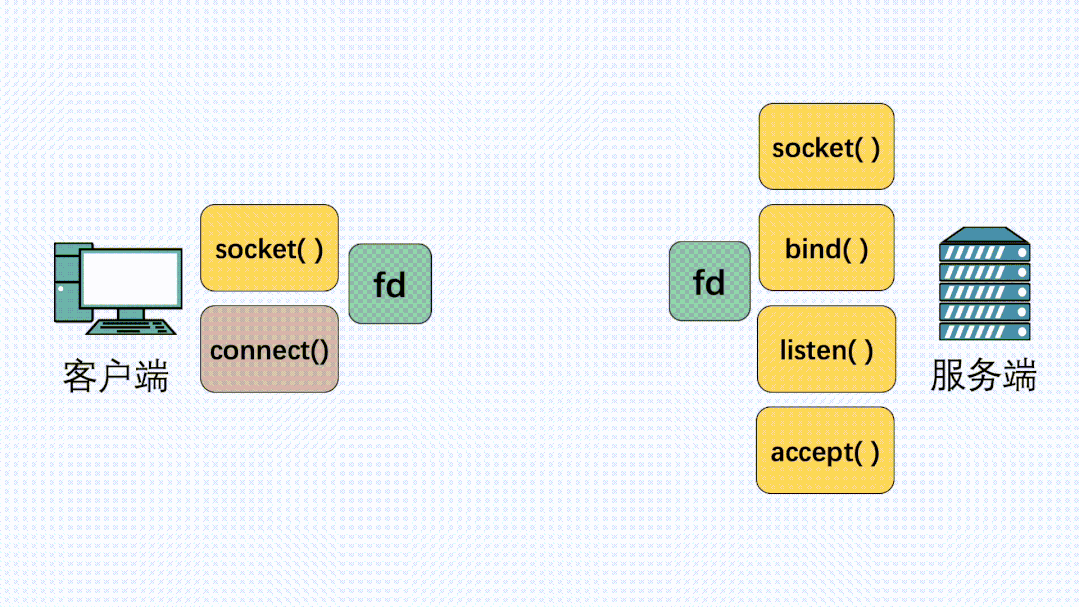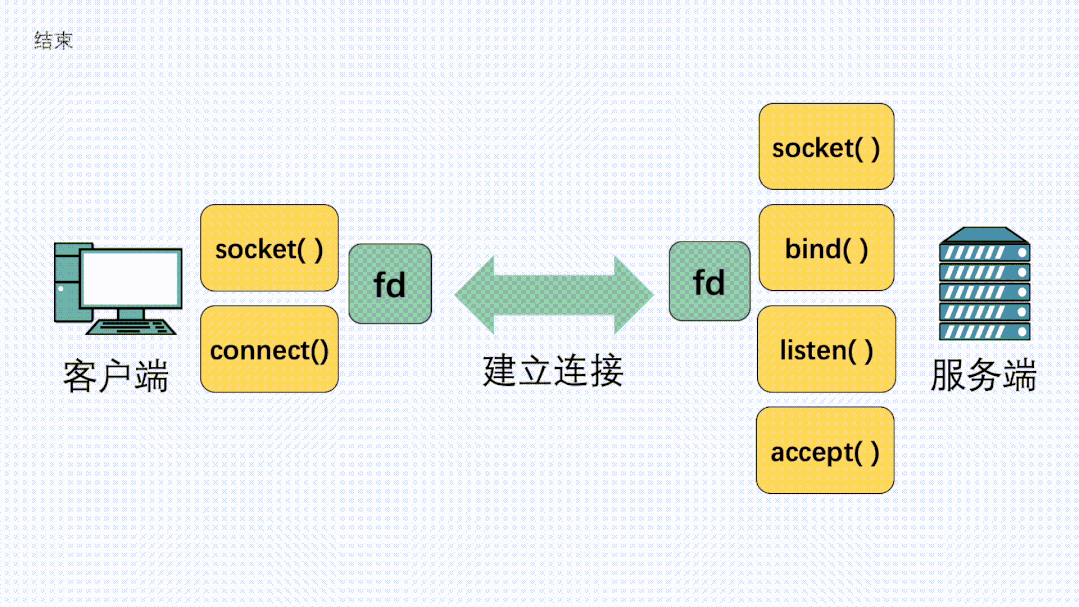
客户端、服务端各自执行socket方法,得到fd句柄之后,服务端依次执行bind、listen、accept方法,然后坐等客户端的连接请求 执行connect方法,向服务端发起建立连接的请求。连接建立完成后,客户端可以执行send方法发送消息,服务端可以执行recv()方法接收消息。反过来,服务器也可以执行send发送消息,客户端可以执行recv接收消息。
具体的:
第一步就是创建个关于TCP的socket。就像下面这样。
1 | sock_fd = socket(AF_INET, SOCK_STREAM, IPPROTO_TCP); |
这个方法会返回socket_fd,它是socket文件的句柄,是个数字,相当于socket的身份证号。
得到了socket_fd之后,对于服务端,就可以依次执行bind(), listen(), accept()方法,然后坐等客户端的连接请求。
对于客户端,得到socket_fd之后,你就可以执行connect()方法向服务端发起建立连接的请求,此时就会发生TCP三次握手。
连接建立完成后,客户端可以执行send() 方法发送消息,服务端可以执行recv()方法接收消息,反过来,服务器也可以执行send(),客户端执行recv()方法。
socket的设计
网络传输,从操作上来看,就是两端之间互相收发数据,也就是对应读数据和写数据,也就是对文件的读、写(==对远端服务器进程收发数据可以抽象为读和写==)。
用一个数据结构(类),取名叫sock,表示互相收发读写功能。下面开始完善这个类,这个类定义过程中,需要解决两个问题:
- 由于接收端和发送端不止一个,因此加入IP和端口做下区分,IP用来定位是哪台电脑,端口用来定位是这台电脑上的哪个进程。
- 发送端和接收端的传输方式有很多区别,可以是可靠的
TCP协议,也可以是不可靠的UDP协议,甚至还需要支持基于icmp协议的ping命令。
解决第1个问题:可以在sock里加入IP和端口字段。
解决第2个问题:会发现这些协议虽然各不相同,但还是有一些功能相似的地方,比如收发数据时的一些逻辑完全可以复用。按面向对象编程的思想,我们可以将不同的协议当成是不同的对象类(或结构体),将公共的部分提取出来,通过”继承“的方式,复用功能。(也就是说,不同协议是不同的类,用一个sock作为基类,不同协议类作为派生类,继承这个公共部分(基类))
基于各种sock实现网络传输功能
于是,我们将功能重新划分下,定义了一些数据结构。
继承sock的各类sock:
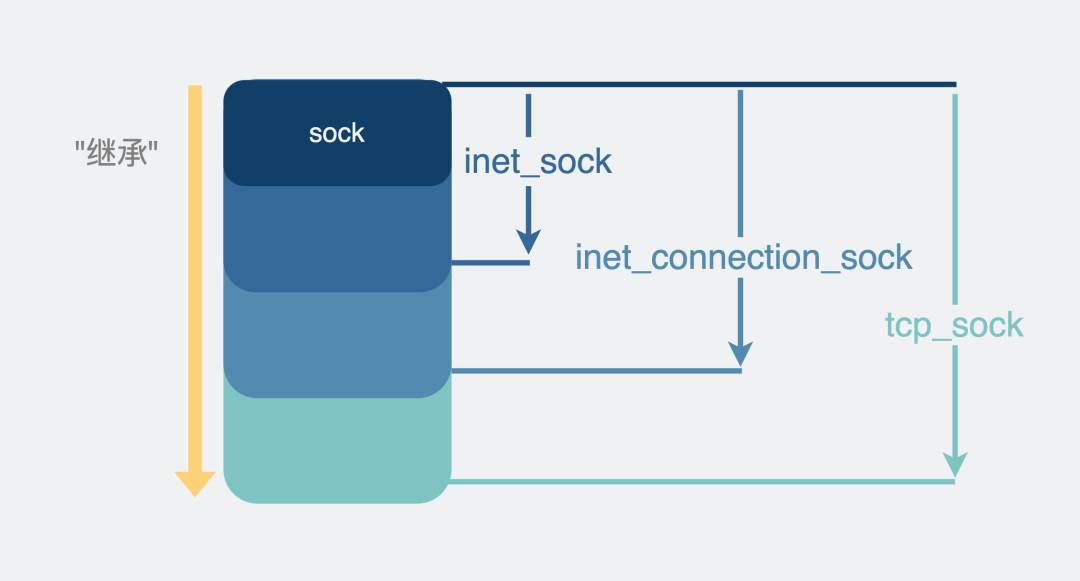
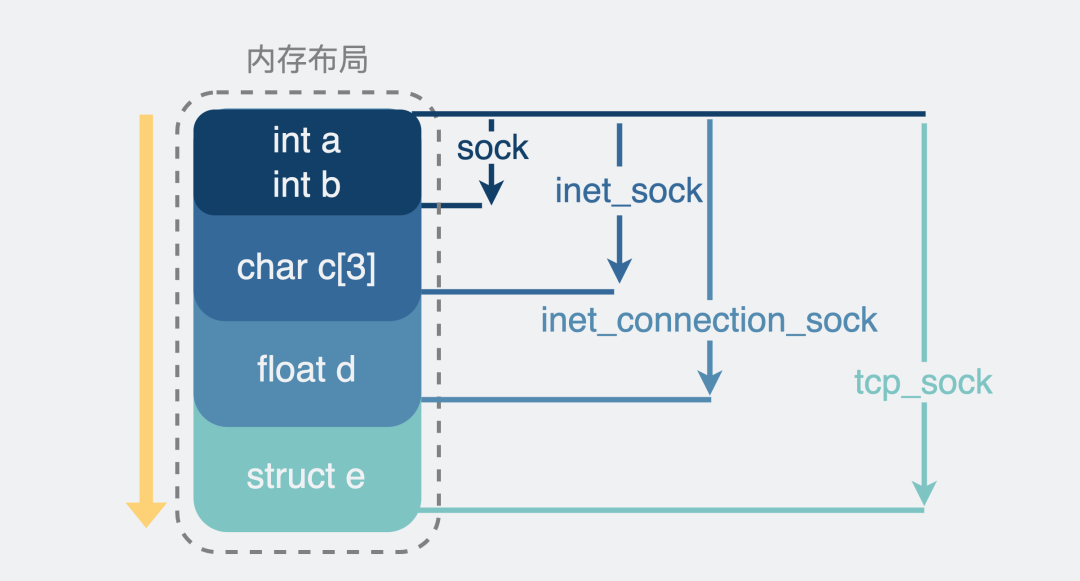
sock是最基础的结构,维护一些任何协议都有可能会用到的收发数据缓冲区。
inet_sock特指用了网络传输功能的sock,在sock的基础上还加入了TTL,端口,IP地址这些跟网络传输相关的字段信息。说到这里大家就懵了,难道还有不是用网络传输的?有,比如Unix domain socket,用于本机进程之间的通信,直接读写文件,不需要经过网络协议栈。
inet_connection_sock 是指面向连接的sock,在inet_sock的基础上加入面向连接的协议里相关字段,比如accept队列,数据包分片大小,握手失败重试次数等。虽然我们现在提到面向连接的协议就是指TCP,但设计上linux需要支持扩展其他面向连接的新协议,比如SCTP协议。
tcp_sock 就是正儿八经的tcp协议专用的sock结构了,在inet_connection_sock基础上还加入了tcp特有的滑动窗口、拥塞避免等功能。同样udp协议也会有一个专用的数据结构,叫udp_sock。
好了,现在有了这套数据结构,我们将它们跟硬件网卡对接一下,就实现了网络传输的功能。
提供socket层
可以想象得到,这里面的代码肯定非常复杂,同时还操作了网卡硬件,需要比较高的操作系统权限,再考虑到性能和安全,于是决定将它放在操作系统内核里。
既然网络传输功能做在内核里,那用户空间的应用程序想要用这部分功能的话,该怎么办呢?
这个好办,本着不重复造轮子的原则,我们将这部分功能抽象成一个个简单的接口。以后别人只需要调用这些接口,就可以驱动我们写好的这一大堆复杂的数据结构去发送数据。
那么问题来了,怎么样将这部分功能暴露出去呢?让其他程序员更方便的使用呢?
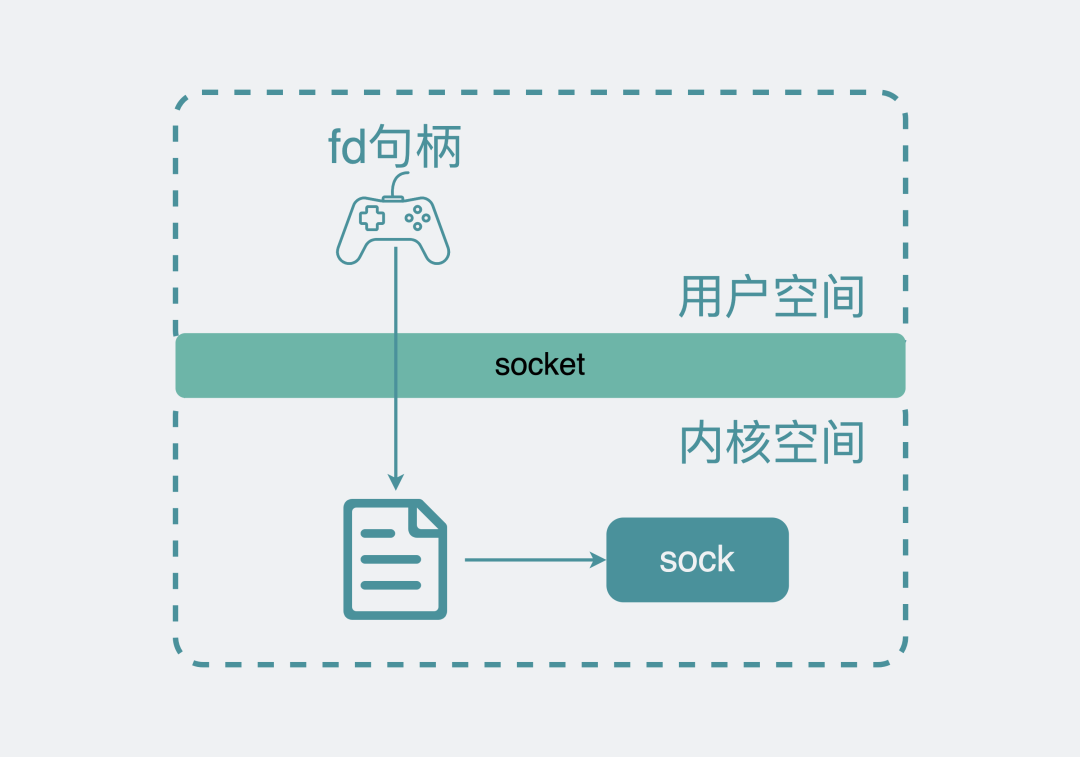
既然跟远端服务端进程收发数据可以抽象为“读和写”,操作文件也可以抽象为”读和写“,正好有句话叫,”linux里一切皆是文件“,那我们索性,==将内核的sock封装成文件就好了。创建sock的同时也创建一个文件==,文件有个句柄fd,说白了就是个文件系统里的身份证号码,通过它可以唯一确定是哪个sock。
这个文件句柄fd其实就是
sock_fd = socket(AF_INET, SOCK_STREAM, IPPROTO_TCP)里的sock_fd。
将句柄暴露给用户,之后用户就可以像操作文件句柄那样去操作这个sock句柄。在用户空间里操作这个句柄,文件系统就会将操作指向内核sock结构。
是的,操作这个特殊的文件就相当于操作内核里对应的sock。
通过文件找到sock:
有了sock_fd句柄之后,我们就需要提供一些接口方法(API),让用户更方便的实现特定的网络编程功能。这些接口,我们列了一下,发现需要有send(),recv(),bind(), listen(),connect()这些。到这里,我们的内核网络传输功能就算设计完成了。
现在是不是眼熟了,上面这些接口方法其实就是==socket==提供出来的接口。
所以说,socket其实就是个代码库 or 接口层,它介于内核和应用程序之间,提供了一些高度封装过的接口,让我们去使用内核网络传输功能。
基于sock实现网络传输功能:
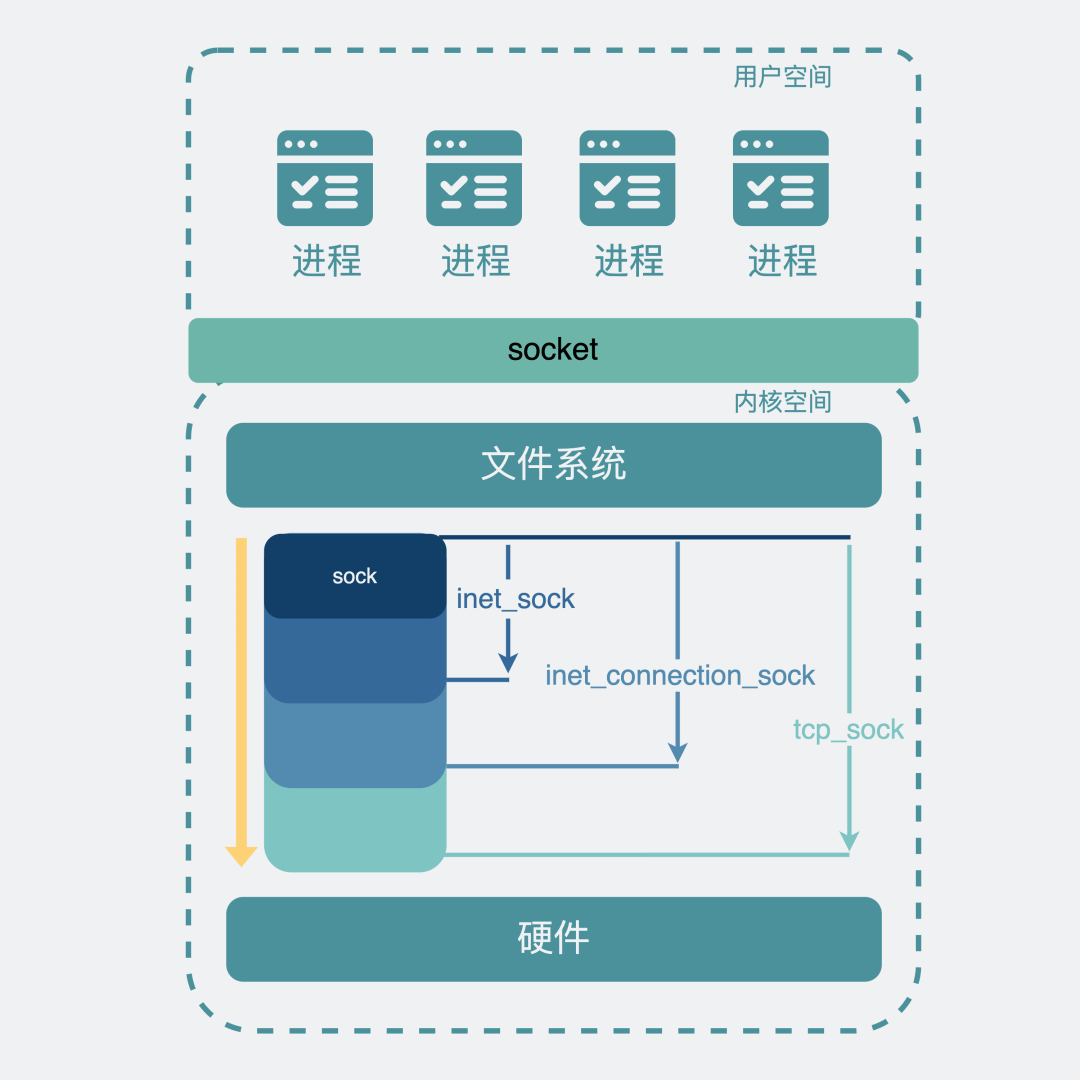
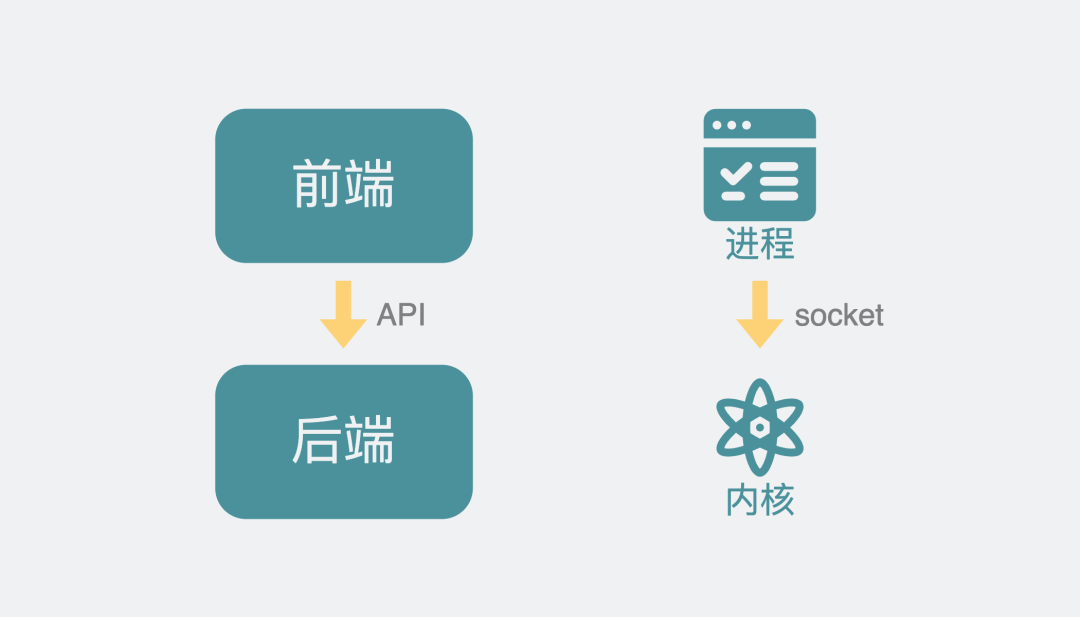
到这里,我们应该明白了。我们平时写的应用程序里代码里虽然用了socket实现了收发数据包的功能,但其实真正执行网络通信功能的,不是应用程序,而是linux内核。相当于==应用程序通过socket提供的接口,将网络传输的这部分工作外包给了linux内核==。
这听起来像不像我们最熟悉的前后端分离的服务架构,虽然这么说不太严谨,但看上去linux就像是被分成了应用程序和内核两个服务。内核就像是后端,暴露了好多个api接口,其中一类就是socket的send()和recv()这些方法。应用程序就像是前端,负责调用内核提供的接口来实现想要的功能。
进程通过socket调用内核功能:
看到这里,我担心大家会有点混乱,来做个小的总结。
==在操作系统内核空间里,实现网络传输功能的结构是sock,基于不同的协议和应用场景,会被泛化为各种类型的xx_sock,它们结合硬件,共同实现了网络传输功能。为了将这部分功能暴露给用户空间的应用程序使用,于是引入了socket层,同时将sock嵌入到文件系统的框架里,sock就变成了一个特殊的文件,用户就可以在用户空间使用文件句柄,也就是socket_fd来操作内核sock的网络传输能力。==
这个socket_fd是一个int类型的数字。现在回去看socket的中文翻译,套接字,我将它理解为一套用于连接的数字,是不是就觉得特别合理了。
网络分层与基于sock实现网络传输功能:
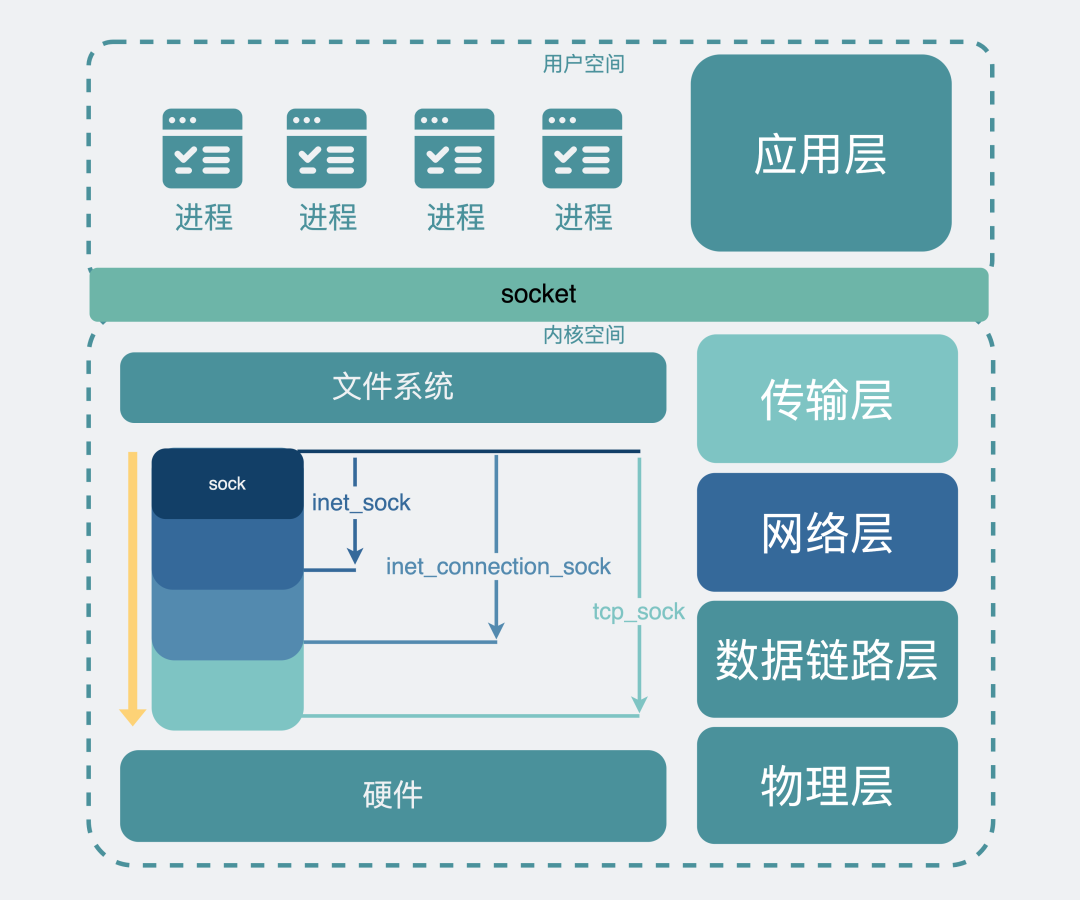
socket如何实现网络通信
以最常用的TCP协议为例,简单了解下它是怎么实现网络传输功能的。
将它分为两阶段,分别是建立连接和数据传输。
建立连接
对于TCP,要传数据,就得先在客户端和服务端中间建立连接。
在客户端,代码执行socket提供的connect(sockfd, "ip:port")方法时,会通过sockfd句柄找到对应的文件,再根据文件里的信息指向内核的sock结构。通过这个sock结构主动发起三次握手。
TCP三次握手:
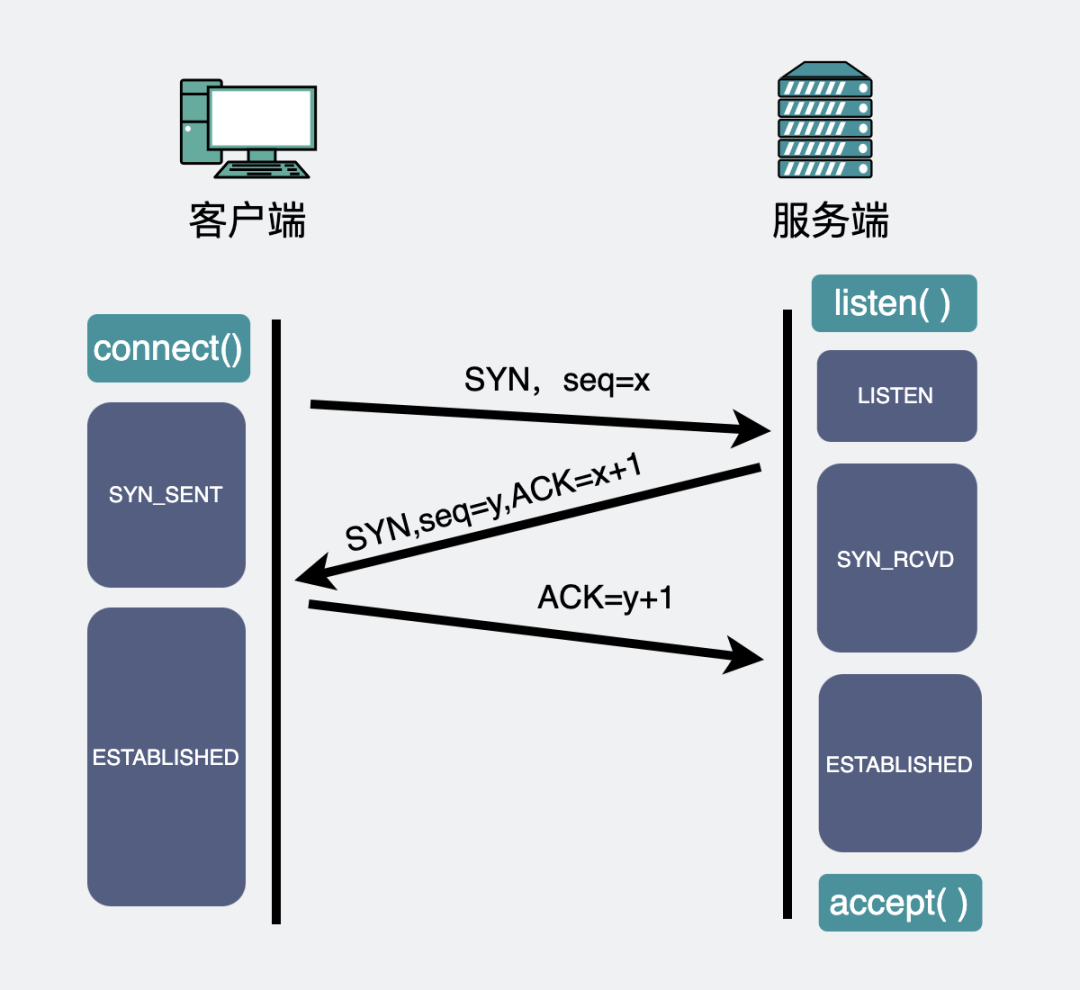
在服务端握手次数还没达到”三次”的连接,叫半连接,完成好三次握手的连接,叫全连接。它们分别会用半连接队列和全连接队列来存放,这两个队列会在你执行listen()方法的时候创建好。当服务端执行accept()方法时,就会从全连接队列里拿出一条全连接。
半连接队列和全连接队列:
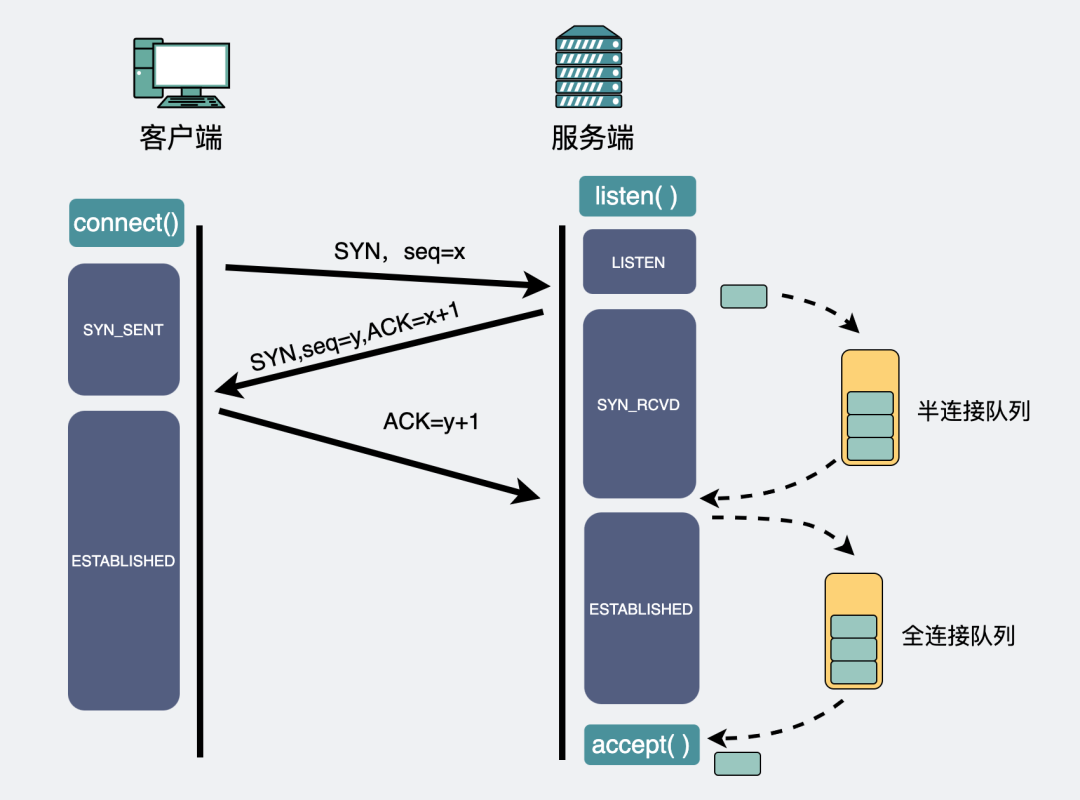
至此,连接就算准备好了,之后,就可以开始传输数据。
虽然都叫队列,但半连接队列其实是个hash表,而全连接队列其实是个链表。
那么问题来了,为什么半连接队列要设计成哈希表而全连接队列是个链表?这个在我在我之前写的《没有accept,能建立TCP连接吗?》 已经提到过,不再重复。
数据传输
为了实现发送和接收数据的功能,sock结构体里带了一个发送缓冲区和一个接收缓冲区,==说是缓冲区,但其实就是个链表==,上面挂着一个个准备要发送或接收的数据。
当应用执行send()方法发送数据时,同样也会通过sock_fd句柄找到对应的文件,根据文件指向的sock结构,找到这个sock结构里带的发送缓冲区,将数据会放到发送缓冲区,然后结束流程,内核看心情决定什么时候将这份数据发送出去。
接收数据流程也类似,当数据送到linux内核后,数据不是立马给到应用程序的,而是先放在接收缓冲区中,数据静静躺着,卑微的等待应用程序什么时候执行recv()方法来拿一下。
sock的发送和接收缓冲区:
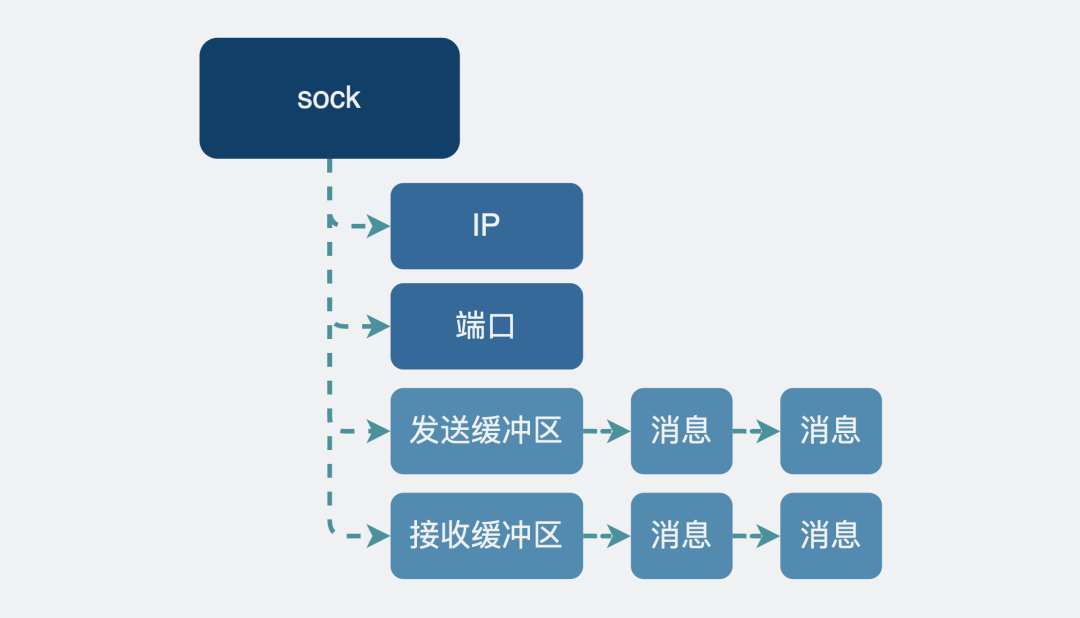
IP和端口其实不在sock下,而在inet_sock下,上面这么画只是为了简化。
那么问题来了,发送数据是应用程序主动发起,这个大家都没问题。
那接收数据呢?数据从远端发过来了,怎么通知并给到应用程序呢?
这就需要用到等待队列。
sock内的等待队列:
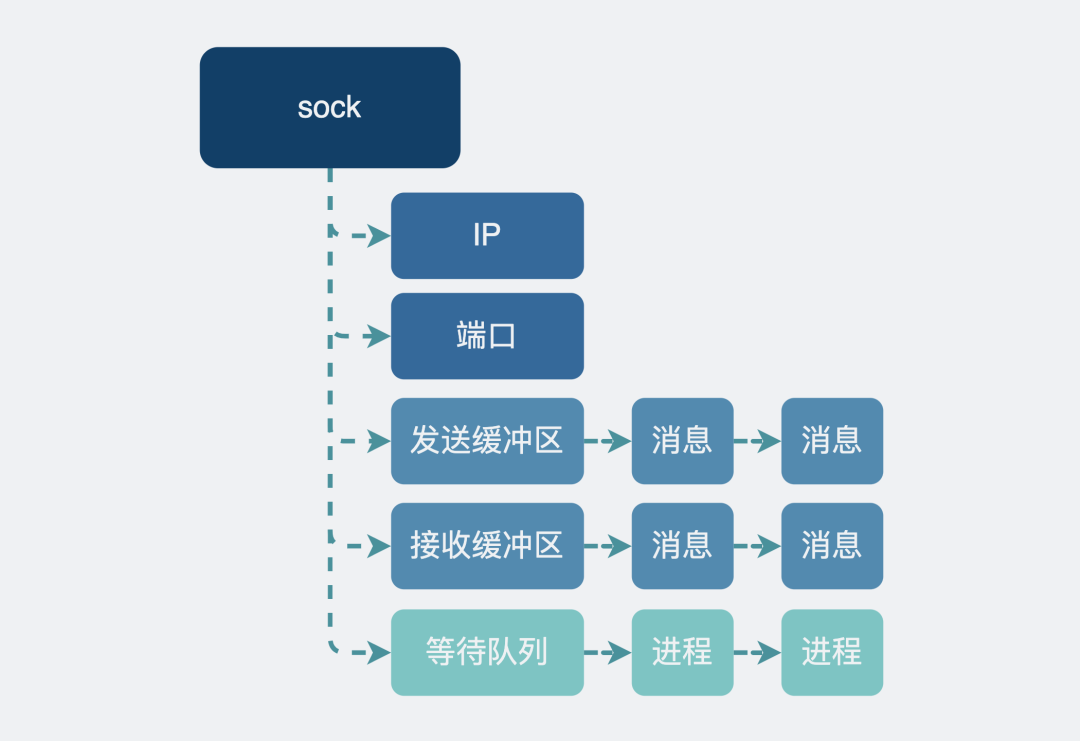
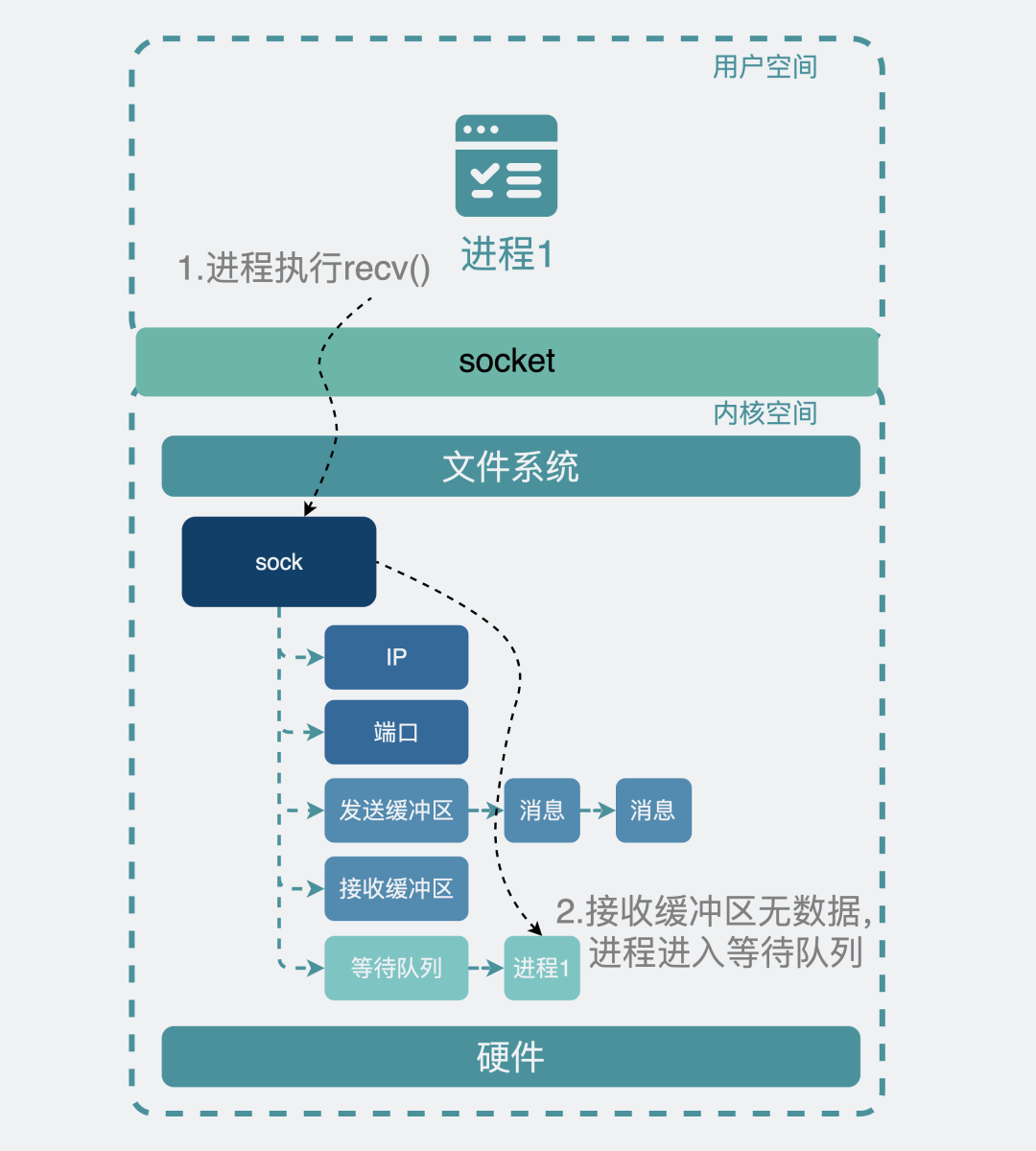
当你的应用进程执行recv()方法尝试获取(阻塞场景下)接收缓冲区的数据时。
如果有数据,那正好,取走就好了。这点没啥疑问。
但如果没数据,就会将自己的进程信息注册到这个sock用的等待队列里,然后进程休眠。如果这时候有数据从远端发过来了,数据进入到接收缓冲区时,内核就会取出sock的等待队列里的进程,唤醒进程来取数据。
recv时无数据进程进入等待队列:
有时候,你会看到多个进程通过fork的方式,listen了同一个socket_fd。在内核,它们都是同一个sock,多个进程执行listen()之后,都嗷嗷等待连接进来,所以都会将自身的进程信息注册到这个socket_fd对应的内核sock的等待队列中。如果这时真来了一个连接,是该唤醒等待队列里的哪个进程来接收连接呢?这个问题的答案比较有趣。
- 在linux 2.6以前,会唤醒等待队列里的所有进程。但最后其实只有一个进程会处理这个连接请求,其他进程又重新进入休眠,这些被唤醒了又无事可做最后只能重新回去休眠的进程会消耗一定的资源。就好像你在广东的街头,想问路,叫一声靓仔,几十个人同时回头,但你其实只需要其中一个靓仔告诉你路该怎么走。你这种一不小心惊动这群靓仔的场景,在计算机领域中,就叫惊群效应。
- 在linux 2.6之后,只会唤醒等待队列里的其中一个进程。是的,socket监听的惊群效应问题被修复了。
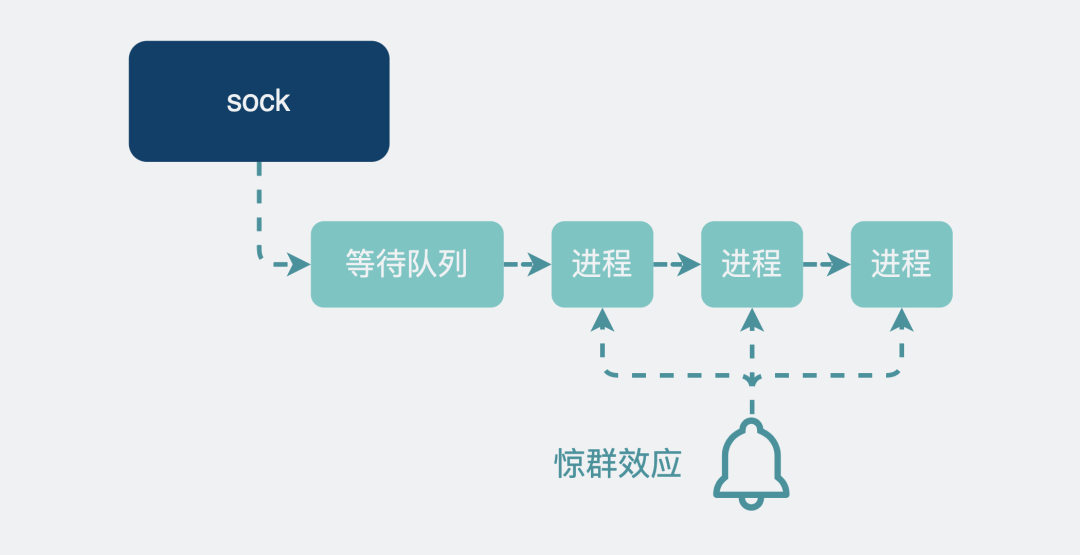
惊群效应
看到这里,问题又来了。
服务端 listen 的时候,那么多数据到一个 socket 怎么区分多个客户端的?
以TCP为例,服务端执行listen方法后,会等待客户端发送数据来。客户端发来的数据包上会有源IP地址和端口,以及目的IP地址和端口,这四个元素构成一个四元组,可以用于唯一标记一个客户端。
其实说四元组并不严谨,因为过程中还有很多其他信息,也可以说是五元组。。。但大概理解就好,就这样吧。。。
四元组:
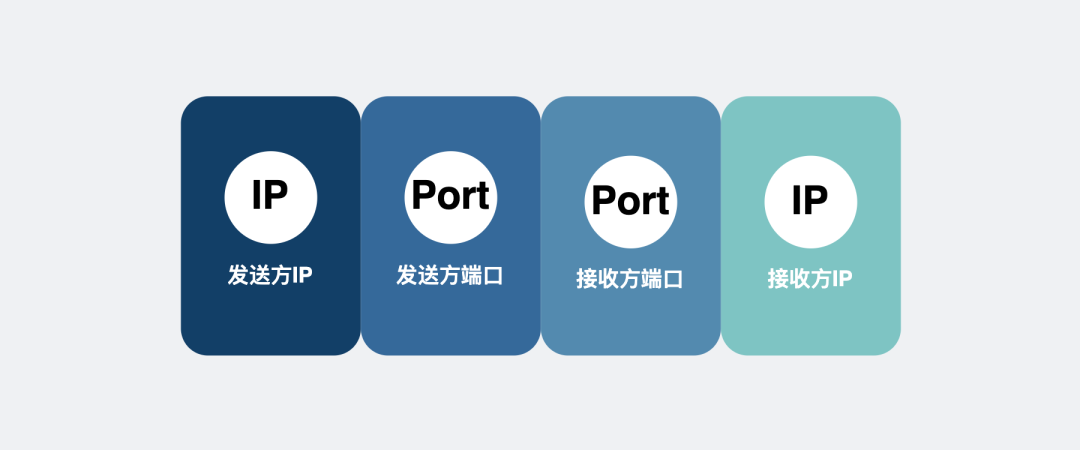
服务端会创建一个新的内核sock,并用四元组生成一个hash key,将它放入到一个hash表中。
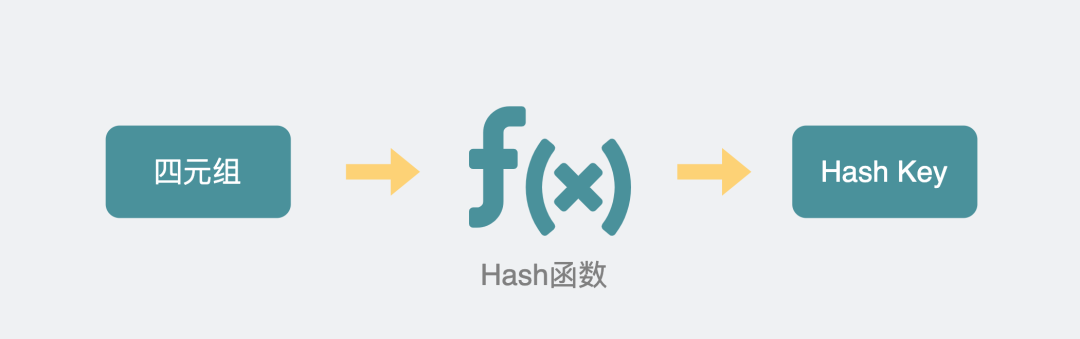
四元组映射成hash键
下次再有消息进来的时候,通过消息自带的四元组生成hash key再到这个hash表里重新取出对应的sock就好了。所以说服务端是通过四元组来区分多个客户端的。
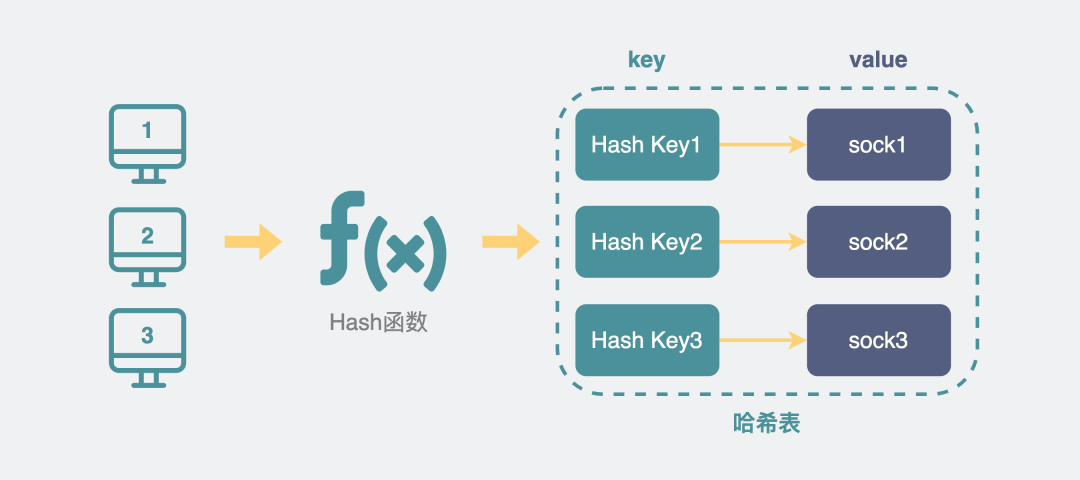
多个hash_key对应多个客户端
sock怎么实现”继承”
最后遗留一个问题。
大家都知道linux内核是C语言实现的,而C语言没有类也没有继承的特性,是怎么做到”继承”的效果的呢?
在C语言里,结构体里的内存是连续的,将要继承的”父类”,放到结构体的第一位,就像下面这样。
1 | struct tcp_sock { |
然后我们就可以通过结构体名的长度来强行截取内存,这样就能转换结构体,从而实现类似”继承”的效果。
1 | // sock 转为 tcp_sock |
总结
- socket中文套接字,我理解为一套用于连接的数字。
- sock在内核,socket_fd在用户空间,socket层介于内核和用户空间之间。
- 在操作系统内核空间里,实现网络传输功能的结构是sock,基于不同的协议和应用场景,会被泛化为各种类型的xx_sock,它们结合硬件,共同实现了网络传输功能。为了将这部分功能暴露给用户空间的应用程序使用,于是引入了socket层,同时将sock嵌入到文件系统的框架里,sock就变成了一个特殊的文件,用户就可以在用户空间使用文件句柄,也就是socket_fd来操作内核sock的网络传输能力。
- 服务端可以通过四元组来区分多个客户端。
- 内核通过c语言”结构体里的内存是连续的”这一特点实现了类似继承的效果。