语音云平台
《语音识别原理与技术》洪青阳 工业应用实践 书、PPT 15.2
语音云平台可通过RESTful的方式给开发者提供一个通用的HTTP接口。
如图所示,系统通过HTTP的协议来进行调用。客户端采用HTTP Post,发Post请求到服务器,然后获取服务器的响应,根据响应的代码,判断操作是否成功。客户端负责语音的采集,并将采集后的语音上传到服务端,由服务端进行语音识别,并将结果返回到客户端。
部署不是一个识别引擎,so就够了,底层还要有一个服务程序,服务程序来调用识别引擎,服务程序再和外围客户端去交互。
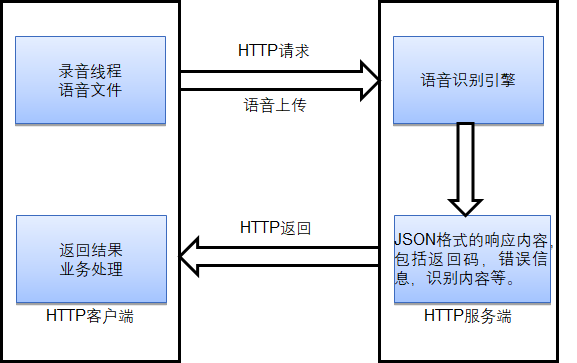
HTTP协议服务一般通过高级语言,如go、Python或Java等语言实现,接收HTTP多路并发请求,使用多线程技术调用引擎进行识别,并用JSON格式返回识别结果。
HTTP接口协议包括如下:
1 | 传送字节流 |
以下是客户端采用C代码实现CURL调用的例子。上传一句话的buffer,然后返回识别结果。
1 |
|
语音云平台在服务器上运行,一般有强大的计算能力,因此可在其上使用复杂的声学模型和较大的语言模型,以支持各种场景的“任意说”识别,并通过 HTTP接口支持各种客户端调用。除了公有云,语音云平台也应支持私有云部署,以避免数据泄密。
语音云平台—流识别
语音云平台还可通过流的方式进行语音识别,
如语音云平台的客户端一次可送200ms左右的片段,服务端接收后进行拼接,累计到1s 时长时即可开始识别。这个识别过程也是部分解码,只是令牌传播过程可以显示中间结果。等句子传送结束后,再进行 Lattice 回溯解码,得到最后识别结果。
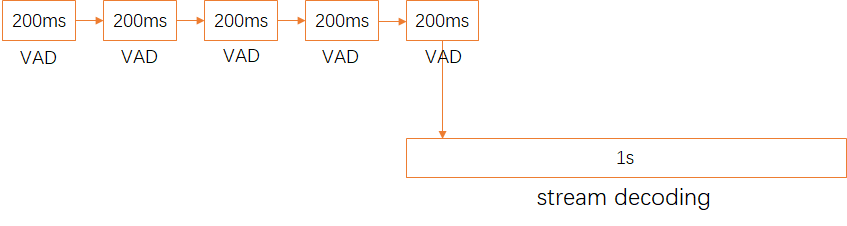
流识别结果跟整句识别略微有差别,但影响不大,能够保证实用性能。流识别方式可以边说边识别,大大缩短时延,有效提升响应速度。
现在工业界部署的云平台,普遍采用流识别方式。