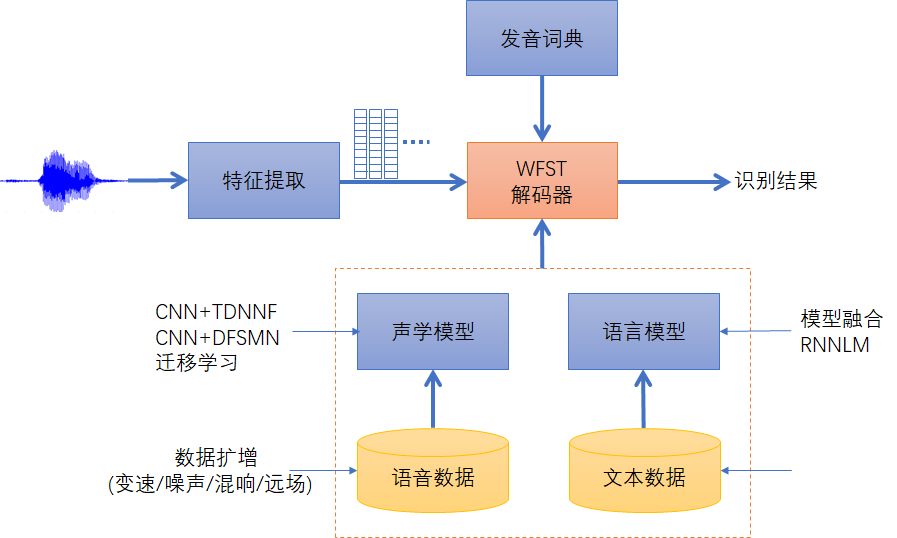
识别引擎优化
《语音识别原理与技术》洪青阳 工业应用实践 书、PPT 15.3
- 加快响应速度
- 定制语言模型
- 定制声学模型
加快响应速度
语音识别的响应速度可用实时率(RTF)来衡量,即识别时间与语音时长的比值,越低越好。响应速度也可采用倍实时指标,倍实时跟RTF正好相反,是语音时长与识别时间的比值,越高越好。
为加快响应速度,可从算法优化和工程优化两方面入手。算法优化主要针对WFST解码器优化。WFST的令牌传播机制和Lattice解码都有剪枝过程,默认的最大活跃节点数和剪枝阈值为:
max-active=7000
beam=15.0
lattice-beam=8.0
对响应速度影响较大的是前两个参数,实验表明,识别率略微变差情况下,max-active和beam值可以减小如下:
max-active=3000
beam=10.0
lattice-beam=8.0
修改后响应速度可大幅提升,比如3秒语音只要0.5秒即可识别出结果,即RTF<0.2。
==矩阵运算用到了线性代数运算加速库,可用库版本包括 ATLAS、OpenBLAS 和 MKL。离线测试结果显示 MKL 的加速性能最优。==
另外,采用 GPU 解码加速声学模型计算过程,也可大幅提升响应速度。
定制语言模型
- 通用语言模型一般使用日常生活、工作、新闻等范畴的文本语料训练而成,对书面语或日常用语识别较好,但针对口语化表达或特定行业,如司法、证券、电力、医疗等,因为有其专业的术语,往往识别不好。
- 专用语言模型可以只用特定行业的句子表达来训练,但语料规模一般偏少,需要人为地设计一些类似的句子,尽可能覆盖到实际可能用的表达,使训练出来的统计模型覆盖更全面。
直接用语料混合的话,由于专有语料数量少,可能起不到什么作用。因此用各自训练一个语言模型,然后进行模型融合(线性加权)

重新训练完语言模型后,要将其与声学模型合并,生成HCLG。
定制声学模型
如果采集设备比较特殊,跟常用的PC或手机麦克风差异较大,而声学模型的训练数据没有覆盖到这种录音,则识别性能会急剧下降,这也是一种跨信道问题。
一种解决方案是扩大声学模型的训练数据覆盖范围,尽量使其包含跟实际场景相配的录音。但这种方案代价较大,需要重新训练 GMM-HMM或DNN-HMM,以及 Chain 模型,周期长,难以匹配项目进度。
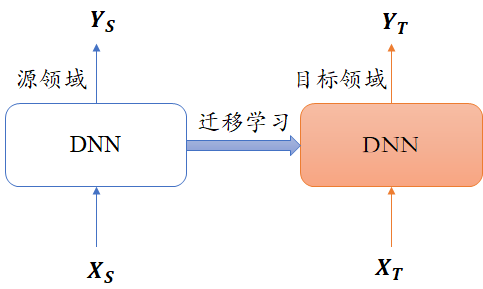
还有一种方案是采用迁移学习,基于源领域已有的通用模型,用目标领域的小批量训练数据(建议 50h 以上)重新训练,得到更匹配的声学模型。迁移学习原理很简单,保持DNN 的隐藏层参数不变,只改变输出层(从 Ys改为Y),然后用目标数据X-重新微调训练。
定制声学模型——迁移学习
DNN迁移学习:适配不同场景(包括不同终端,不同格式等),迁移完的识别模型就是专有领域的了,也不适用于通用领域。
迁移学习方法:
- 用基础模型作为base,专有数据在上面继续训练;
- 冻结基础模型的几层神经层,参数更新;
- 用教师学生模型,软标签,蒸馏。
8K电话语音识别
工业界:识别准确率普遍在80~90%,与手机APP识别(16k)差距较大。
信道差异最明显的是 16kHz 采样的麦克风录音与8kHz 采样的电话录音,它们互相之间兼容性不强,即使把 16 kHz 录音降采样到 8kHz 录音,再去训练声学模型,识别效果也不一定会改善。由于现在很多APP 应用用手机麦克风采集录音,即采样格式为 16kHz,16bits 宽带录音,所以针对近场手机的场景,识别效果可以很好,准确率大多可达到95%以上。但电话8kHz信道的录音普遍很少,难以训练出一个鲁棒性很强的声学模型,再加上电话通话一般是聊天式的口语化表达,语言模型较难覆盖,因此电话语音识别效果仍不太理想,准确率一般在80%~90%之间,难以超越 90%,和16kHz的录音识别效果差距还较大。
在8kHz的一些受限场景下,语言表达相对固定,采集信道固定,此时仍然的 可以用 16 kHz 声学模型作为基准模型,再用实际场景带标注的录音语料做迁移学习,这在一定程度上可提升识别效果。从 在实际应用中,还存在口音重、语速快、双语混杂等问题,导致识别率急剧下降,对此问题建议采用匹配训练数据的方法来解决。
如何平衡专用语料和通用语料的比重,包括平衡声学模型和语言模型的比重,避免过度偏向某种口音或场景,也是一个难题,需要在实践中不断总结。
声学模型存在问题:
- 采样率8kHz:采集信道与麦克风差异很大,不能直接用16k模型识别;
- 特种设备:量化编码存在失真;
- 快语速:识别变差;
语言模型存在问题:
- 口语化表达难以覆盖;
- 通用领域与专业领域较难平衡;
可归结为两大原因:
- 信道差异
- 口语化识别
模型优化方案
改进方案:
采用数据扩增,进行多类型、多条件训练。
采用更先进的声学模型。
DNN迁移学习。