动态库封装
《语音识别原理与技术》洪青阳 工业应用实践 书、PPT 15.1
- 函数接口
- 动态库编译
- 动态库调用
函数接口
1 | /*************************************************************************************************************************/ |
根据ASR_recSpeechBuf函数的输入和输出参数,我们==改写==了Kaldi的在线解码程序,包括以下函数:
- ASR_recSpeechBuf函数:与外面调用程序交互,首先判断分配到的句柄handle是否空闲,如果忙则返回ASR_STATE_ERROR,表示已被占用;如果检查通过,则调用KaldiDecode函数进行解码,并把词序列索引转化为文本内容,保存到输出参数text,即为识别后的句子。
- KaldiDecode函数:实现从语音缓冲buffer到识别结果的具体解码过程,首先完成输入buffer到SubVector
wave_part的转化过程,然后调用feature_pipeline.AcceptWaveform(samp_freq, wave_part)进行声学特征提取,注意声学特征一般有做倒谱均值减(CMN),因此在函数内部还要加上这步操作,接着调用decoder.AdvanceDecoding()进行分片段识别,得到中间解码结果,保存在Lattice里,随后采用decoder.FinalizeDecoding()进行Lattice解码,修正中间部分结果。最后调用GetDiagnosticsAndPrintOutput函数得到解码后的词序列索引。 - GetDiagnosticsAndPrintOutput函数:根据输入的CompactLattice进行Lattice最优路径搜索并返回得到词序列和基于最小贝叶斯风险算出来的置信度,分别存放在输出参数words和words_conf(confidence置信度)。
改写后:
1 | // 根据输入的CompactLattice进行Lattice最优路径搜索 |
函数接口——返回值
函数返回结果是return_ASR_code类型,它包含运行中可能出现的各种情况,用枚举类型定义。
1 | enum return_ASR_Code |
用返回值来诊断引擎出现的问题。
为了提高可读性, 还需对识别后的句子进行加标点等后处理。加标点的操作可采用语言模型,该模型通过对规范的文本语料训练得到。
由于声学模型和 WFST 解码用的 HCLG 文件很大, 通用版本大小一般有 5GB 以上, 故只能在系统初始化阶段加载, 并且只需要加载一次。其相关代码如下:
1 | // 加载声学模型 |
函数接口—引擎初始化和关闭
对于引擎初始化,我们专门定义一个函数ASR_Init。
ASR_Init 函数除了进行引擎文件的加载外, 同时也检查线路授权, 分配能同时并发的路数, 以支持多路调用。调用 ASR_Init 函数后, 如果返回函数值为 ASR_SUCCEEDED_OK, 则表示初始化成功。如果要关闭语音识别服务, 则需要调用 ASR_Release 函数释放相关资源。
1 | /*************************************************************************************************************************/ |
函数接口—句柄打开和关闭
由于涉及多线程调用, 所以需要为每个线程分配专门的句柄, 因此还需要 ASR_Open 和 ASR_Close 两个函数。调用 ASR_Open 函数分配到句柄后,执行完相关操作也要及时调用 ASR_Close 函数释放句柄。这两个函数属于标准化的操作, 这里不再细述。
1 | /*************************************************************************************************************************/ |
动态库编译
完成函数接口定义后,需要把引擎代码编译成动态库。接下来介绍Linux环境下so的编译过程。
动态库编译—Linux环境
Linux环境不方便修改及调试代码,为便于操作,我们建议采用跨平台工具,开发环境可采用 ==CodeBlocks==,读者可下载最新版本并安装到Windows系统。以CodeBlocks16.01版本为例,一旦安装完成后,在文件菜单里选择新建->工程->动态库(New -> Project -> DLL),打开codeblock动态库创建窗口,如图所示。
然后根据提示一步步创建,选择存放的目录,输入工程名,直到工程环境创建成功,如图所示。这时在工程目录会生成一个.cbp的工程文件,如asr.cbp。根据Kaldi函数调用关系,我们需要把在线解码需要的源程序全部加载到工程,并加入必要的外部支撑文件,用来读取配置文件,输出日志信息等。
工程配置保存完,把整个工程目录传到Linux环境,Linux的编译需要Makefile配置文件。为提高效率,可采用cbp2make工具(可网上下载)把asr.cbp工程文件转化为Makefile文件。有了Makefile文件,即可==在Linux环境进行make编译==。
我理解的流程是:先在windows新建工程(codeblock),把所以依赖文件放进来,然后把windows上的这个工程,转成makefile,再放到linux平台上编译,再根据报错情况,再在win平台上的codeblock工程进行修改,然后再转成makefile放到linux里进行编译,直到编译通过,生成.so文件(动态库)。
用了哪些库,比如数学的库,就要把这些库的头文件的路径在makefile里包含、引用进来。
由于kaldi需要调用第三方提供的数学加速库,如Atlas或MKL,因此需要在Makefile中进行如下配置:
1 | [采用Atlas库] |
Linux环境差异大,包括centos,ubuntu等不同版本,安装库的位置也可能不同,需要根据实际环境,修改makefile里面关于这些库的访问路径配置。服务器一般采用centos。
由于Kaldi代码众多,包含很多子模块,函数互相之间关联度较强,加载的文件可能存在冗余或冲突,导致各种编译错误,读者需要根据报错信息一一修正,直至编译成功,最后生成so动态库文件。
这个so动态库需配套相应的头文件,包含可调用的函数接口及参数说明,供外部调用参照。
.so有release版本和debug版本,我们要用release版本,速度快。
动态库编译—Windows环境
Windows环境编译的是dll动态库,主要采用Visual Studio开发工具。由于Kaldi代码采用C++ 11标准,需要安装Visual Studio 2015或更新的版本。另外,Windows环境的加速库只能采用Intel MKL或OpenBLAS。MKL集成相对容易,但需要安装Intel的配套工具,安装完MKL与Visual Studio 2015集成环境如图所示。
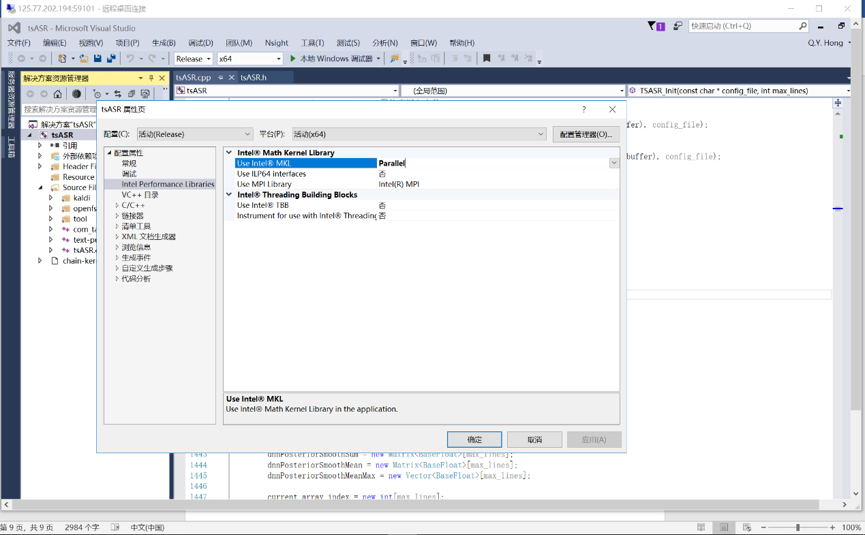
由于 Kaldi 默认在 Linux 环境下编译, 对 Windows 的支持不是很到位, 因此 部分变量和代码在编译时会出现问题, 需要修改, 例如在 kaldi-math.h 文件中需要补充针对_MSC_VER (Visual Studio 开发环境) 的定义。
1 |
|
动态库调用
外部程序调用编译好的动态库,要先集成到工程里,如Linux在Makefile里配置如下:
1 | CC = gcc |
程序要调用时,先初始化引擎,然后分配句柄,再调用相关的识别函数,识别完关闭句柄。程序到最后还要关闭引擎,释放资源。
1 | //初始化引擎 |