Lattice解码用到的数据结构
《语音识别原理与应用》 洪青阳 P185
LatticeSimpleDecoder
lattice-faster-decoder
哈希表 HashList<StateId, Token*> 建立状态节点stateid和token之间的映射关系。
链表:token之间用链表连接,以便解码结束时跟踪到更多的匹配路径。前向链接ForwardLink,令牌列表TokenList
在语音识别中,经常用 Lattice 来保存多种候选的识别结果(单个回溯是不够的),以便后续进行其地处理(如二次解码)。针对有Latice的解码,需要保存多条搜索路径,包括中同遍历的多条路径信息,因此 Token 之间还需要有链表息,以便解码结束时跟踪到更多的匹配路径。
参照 Kaldi 的lattice-faster-decoder 写法,我们给出用于 Lattice 解码的 Token和相关的数据结构定义,包括前向链接 ForwardLink 和令牌列表 TokenList。
ForwardLink 与在快速解码部分定义的转移弧 Arc 不同,它用来链接前后两帧之间的发射转移弧之间的Token,或同一时刻非发射转移弧之间的 Token,ForvardLink 保存的图代价和声学代价更方便后续的 Lattice 剪枝处理。
TokenList 用来和帧索引建立关联,每帧对应一个 TokenList,这样能保证随时访自已解码过的任一时刻创建的 Token 列表,而在快速解码部分(之前的那种解码)定义的 Token 和Arc信息则无法关联时间戳信息,只能利用它们做简单的回溯处理。
ForwardLink
1 | struct ForwardLink { |
Token
1 | struct Token { |
TokenList
1 | struct TokenList { |
令牌传播过程
在进行 Lattice 解码时,从输人语音提取声学特征(T 帧),然后通过令牌(Token)传播,逐帧处理。首先在 WFST 的起始节点,产生一个 Token;然后针对每个活跃节点,把 Token 传播到与该节点相连的转移弧;如果转移弧的输人标签不是 0,则把激活的 Token 对应的帧数加 1,相当于移动到下一帧,实现帧与转移弧(即 HMM 状态的 transition-id)的对齐。
每个 Token 都记录了累计总代价,即之前最优代价加上转移弧对应的图代价graph_cost(包含语言模型、转移概率、发音词典三部分的代价)和声学代价acoustic_cost,其中acoustic_cost 是根据声学特征和声学模型实时计算得出后验概率,然后取反得出的,因此原始后验概率越高,acoustic_cost 代价越小。
由于解码图庞大,因此 Token 的传播可能会有多条路径,对应t时刻的帧会有多个Token。这些 Token 通过 WFST 解码图的节点标号 StateID区分,即通过t和 StateID可以找到唯一的 Token。
如下图所示,同一时刻的 Token 被汇总到一个 TokenList 保存,T帧则有T个TokenList 来保存,因此 TokenList构成一个数组,其中 数组元素索引与帧索引一一对应。单个TokenList 元素里面可能包含多个Token,即同一帧对应多个 Token,如第1帧特征 $o_t$,对应 Token 集合 TokenList[1],由初始状态0转移产生,其包含 4个Token,标为 Token8、Token1、Token9 和 Token2,分别与状态节点8、1、9、2关联,每个Token 都有累计代价cost。其中,Token2 是状态节点9经非发射转移弧到达状态节点2产生的,注意,其仍然属于第1帧,因此在 Token9 和 Token2之间产生的 ForwardLink 属于同一帧不同 Token 之间的链接。第2帧、第3帧及后续帧的解码过程依此类推。
WFST 的 Lattice 解码图:
第一帧:
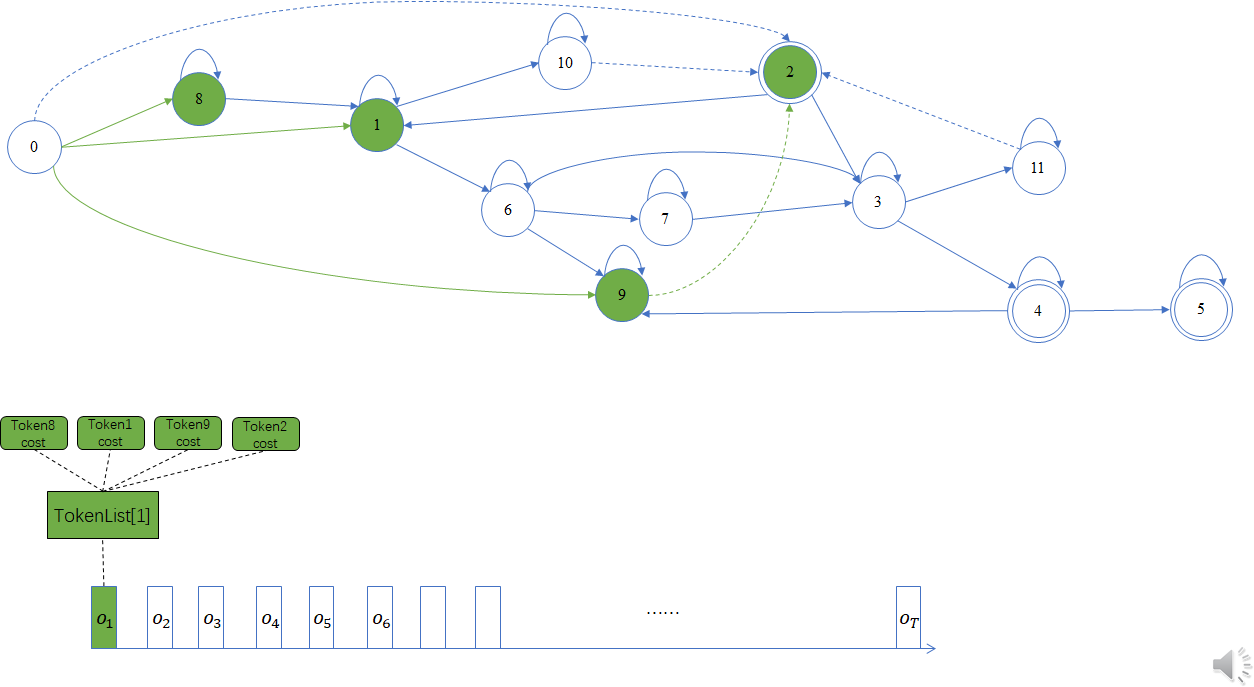
第二帧:
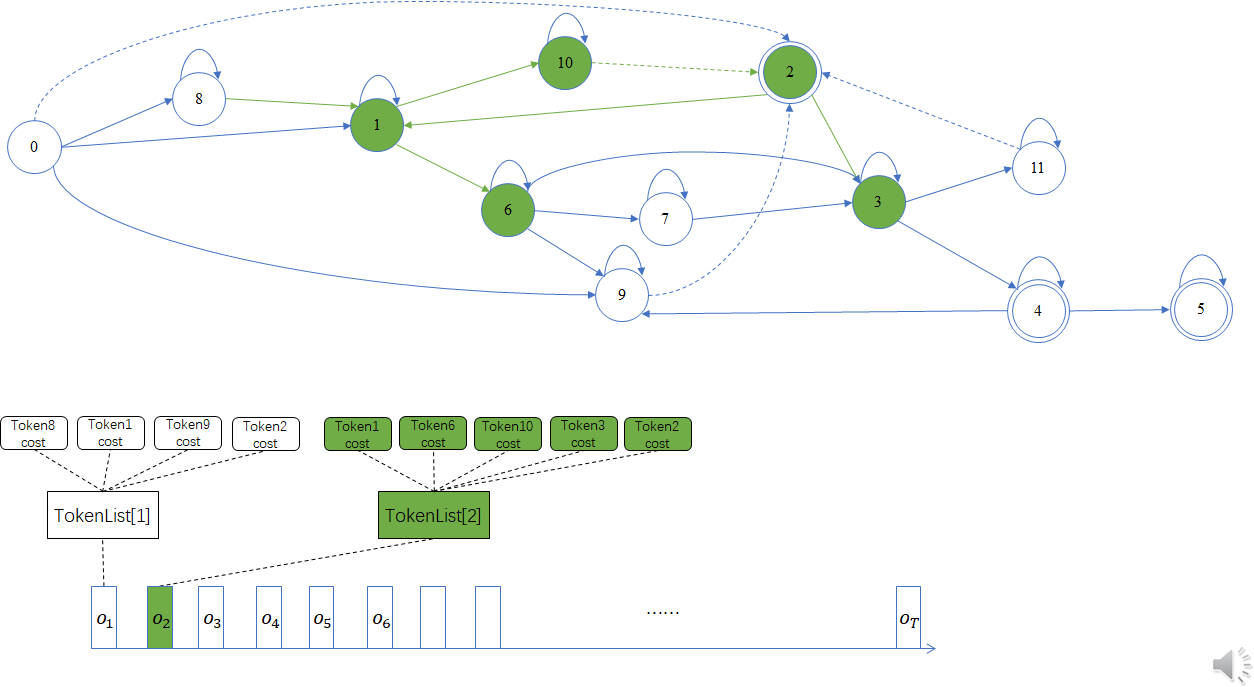
第三帧:
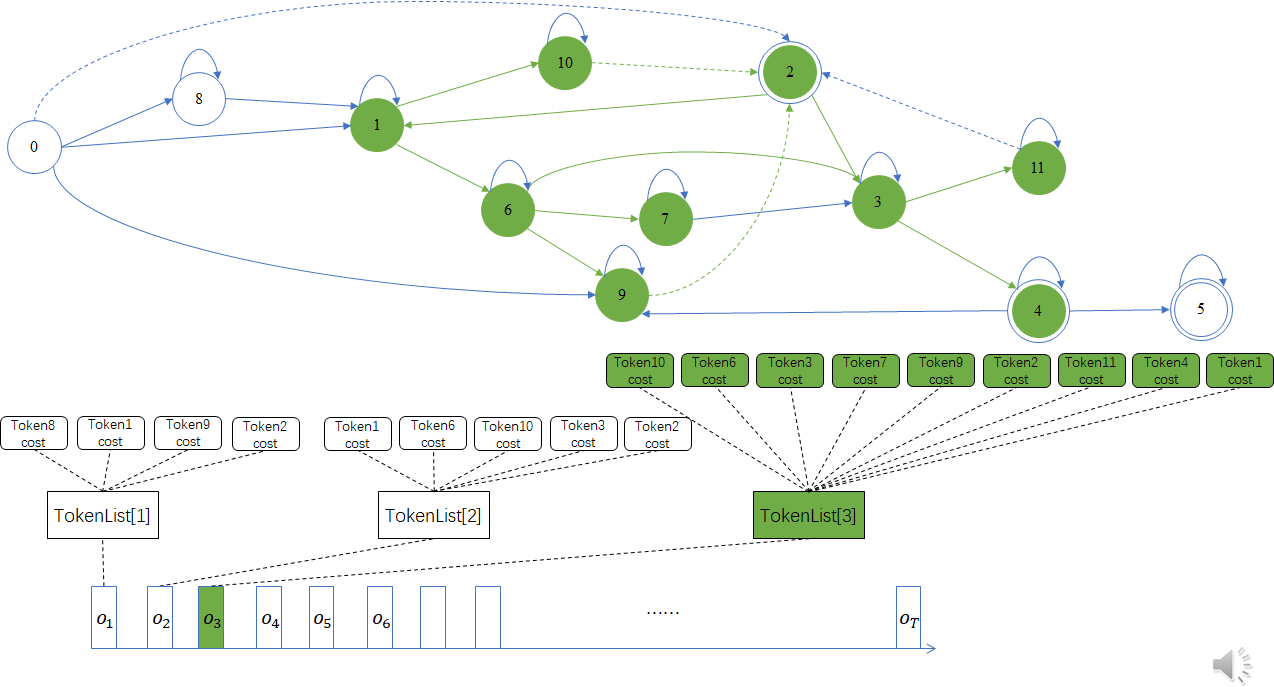
Lattice 解码会保存不同时刻的 TokenList。 如下图所示,每个 TokenList包含同一时刻的多个Token,TokenList 指向第一个 Token,如 TokenList[1]先指向Token8,然后通过 Token8 的next 指针再链接到同一时刻产生的 Token1,依此类推。其中 Token2 由 Token9 通过非发射较移孤产生,因此同时有 ForwardLink 关联。
带Lattice解码的令牌传递过程:
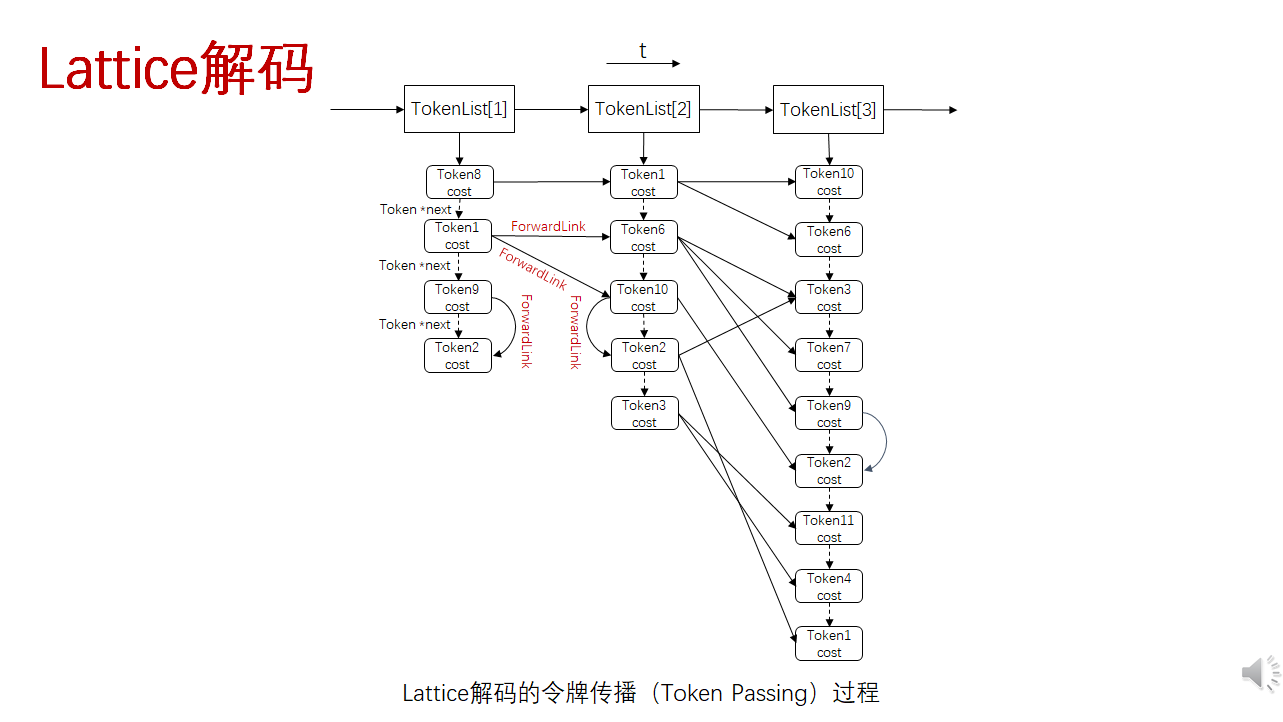
在下一时刻即第2帧,TokenList[1]]包含的 Token1被传播到 TokenList[2J的Token6 和 Token10,并通过 ForwardLink 保存链接信息,如 Token1 和 Token6之间有一条 Forwardlink,该链接保存了两个 Token 对应状态节点(即 1和6)之间的转移弧输入标签和输出标签,同时还有该转移弧对应的图代价和针对第2帧的声学得分。Token2 由于是Token10 在同一帧通过 PrOcessNonemitting 产生的,因此它们之间有 ForwardLink 链接。
在第3帧,TokenList[2]的 Token6 被进一步传播到 TokenList[3]的 Token3、Token7 和 Token9, Token10 传播到 Token2, Token2 传播到 Token3 和 Token1,Token3传播到 Token11 和 Token4。注意,TokenList[3]中的 Token3 同时来自TokenList[2]的 Token6 和Token2,此时只会保存 cost 最小的那个Token。
整个 HCLG 编译的 WFST 是庞大的网络,随着帧数的推进,其他 Token 也可扩张到更多的 Token,同时通过 ForwardLink 建立链接关系。一直到最后一帧结束,才停止 Token 的扩张,此时再从 TokenList 寻求最佳路径对应的最后一个Token。如果指定最优结尾 Token, 一定要从 HCLG 的结尾状态(双圆圈)中选择,对比所有结尾状态对应 Token 的cost,选择值最低的,然后从该 Token 倒推得到最优路径对应的转移弧序列。
剪枝策略
随着 Token 的扩张,每一帧可能对应很多个 Token,这样会导致解码变慢。为加快解码速度,需要采用剪枝策略,即事先设定一个剪枝阈值 ( beam),然后针对每一帧动态调整剪枝上限。剪枝的具体步骤如下:
在解码过程中,针对当前帧找出最低代价(best_cost)的 Token,即最优的 Token,根据该 Token 设定剪枝上限(cur_cost),其值为 best_cost+beam。同时对该Token 进行后续一帧的扩张,计算每个转移弧新的 cost,结合 beam 阈值得到后续扩张的剪枝上限(next_cost)。
第一轮。对同一帧所有Token 做一次剪枝,抑制一批代价超过 cur_cost 的Token,即这批Token 不再扩张,如下图所示的 Token9。
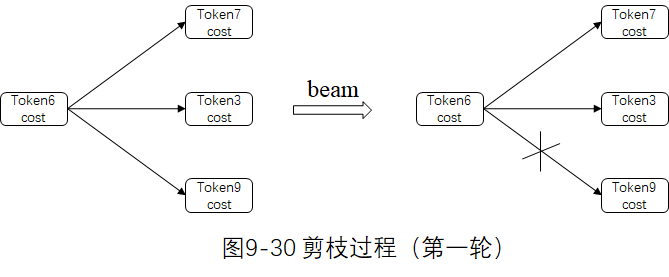
第二轮。对当前帧除了最优 Token 之外的其他 Token,也对后续的转移弧计算更新的cost,如果超过扩张剪枝上限next_cost,则该转移弧不再扩张。如下图所示,Token7到Token3的转移弧被剪枝,实际上是不生成Token3。
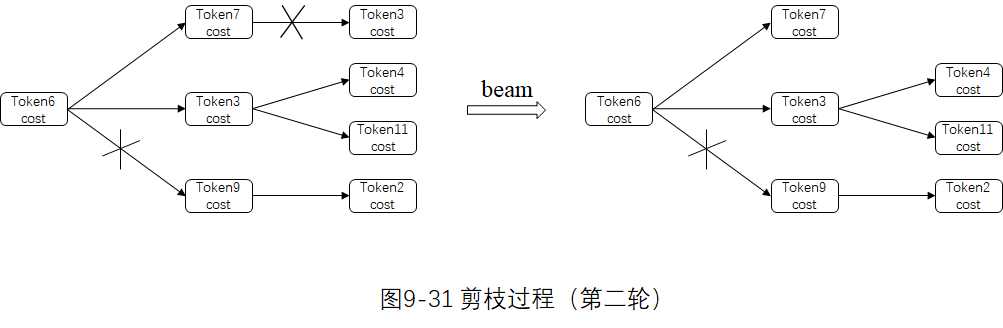
除了默认剪枝阈值 beam,还可设定最大活跃节点数 max_active。对 Token按cost 排序后只保留max active 个有效节点,对应的剪枝國值为 adaptive_beam。
WFST 中的每个状态节点和一个Token 对应,后面不同时刻的特征帧也可能对齐到该状态,即对应到相同的 Token。此时需要比较 cost 值,如果新 Token 的cost 值更低,则替换原有 Token。
以上是通用的剪枝策略,其也适用于上一节的快速解码。对于 Lattice 解码,还可间隔多帧(如25 帧)再做一次基于 ForwardLink 的 Lattice 剪枝。根据每帧TokenList 访问并算出每一条 ForwardLink 和最优路径的cost 差异,如果差值超过Lattice 剪枝阈值就剪掉该 ForwardLink。
Lattice
语音识别中,Lattice用来保存多种候选结果,每个节点可对应到具体的时间(帧索引),节点之间的弧包含了候选词信息。HTK用Standard Lattice Format(SLF)保存Lattice,而Kaldi则用FST形式保存,但也可转化成SLF形式。
Kaldi Lattice是在解码后,通过每个时刻的TokenList包含的Token和与之关联的ForwardLink遍历生成,并用转移弧Arc保存路径信息。具体实现可查看decoder的GetRawLattice函数。
Lattice的基础结构可以表示为{input, output, weight},即Lattice包括输入、输出和权重。Lattice每条弧上的状态输入为transition-id,状态输出为words,其中权重weight包含两个值,即图代价(graph_cost)和声学代价(acoustic_cost)。可从ForwardLink参数获取这两个值。
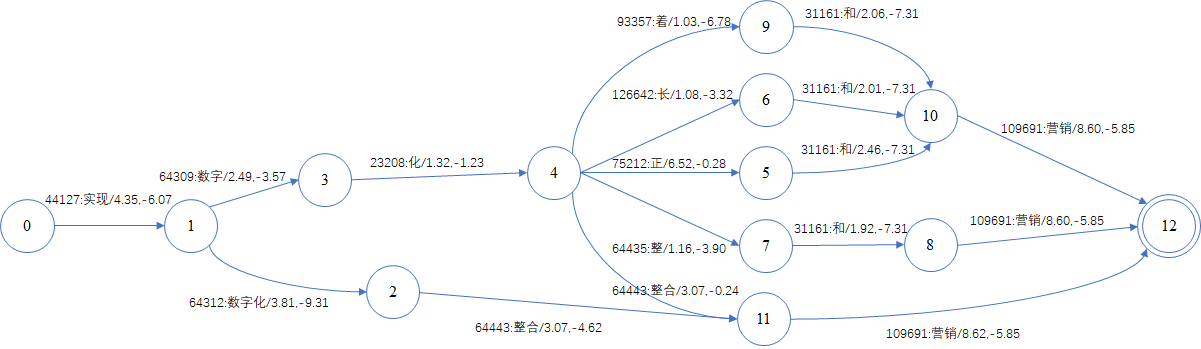
Lattice有多条路径,按最后的cost排序,最小的排在前面,即可从Lattice得到最优路径。注意最优路径也可在解码结束时直接获取,无需经过Lattice。
最优路径只包含一个结果,如图所示,即识别结果为“实现数字化整合营销”。

如果要保留多个识别结果,则可采用 lattice-nbest 进行转换,将N条弧从起始状态传播到结尾状态,得到N个最好的不同单词序列。
利用得到的 Latice 还可进行二次解码,引人更复杂的语言模型,如递归神经网络语言模型,更新 Lattice 中路径上的得分(注意不能简单替换图代价,因为还有词典和转移概率),得到更优的识别结果。
如果想查看不同输出级别的 Lattice 信息,也可以将词级别的 Lattice 转换成音素级别的 Lattice,但这一步操作会耗费比较多的时间,尤其是在人声嘈杂环境下的识别。
也可将 Lattice 保存成紧凑形式的CompactLattice(本质上是一种 WFSA),每条弧的输人和输出都是words,它把可能的输人标签序列 transition-ids 全部放在了权重里面,即权重信息包括 {graph_ cost, acoustic_cost, transition-ids sequence}。 Latice 和 CompactLattice 两者结构稍有不同,如下表所示,但这两者包含了相同的内容,因此可以互相转换。