WFST解码器
厦门大学洪青阳教授的公开课:《语音识别值WFST解码器——基于WFST的维特比解码过程》
- token:保存解码的中间结果
- WFST解码本质上也是Viterbi解码,根据输入的特征序列,进行帧同步对齐,寻求最佳状态序列。
- 注意这里的状态不是HMM状态,而是HCLG的状态节点,所遍历状态节点之间的衔接,可能是==产生观察值==的转移弧(如状态𝑆1和𝑆2、 𝑆2和𝑆3之间的实线),也可能==不产生观察值==的转移弧(如状态𝑆4和𝑆5之间的虚线)。

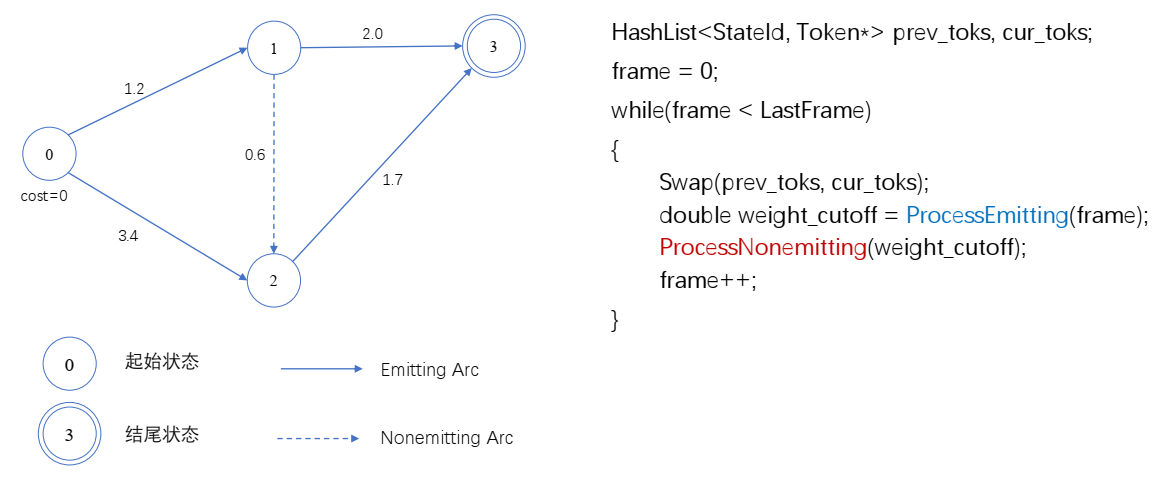
- Emitting arc:发射转移弧,会产生观察值,观察值产生声学分数(acoustic_cost),非0的输入标签(ilabel!=0).
- Nonemitting arc:非发射转移弧,不会产生观察值,没有声学分数,但是状态间能够跳转。简单理解可以想成 o—语:语文—o—文: $\epsilon$ —o 。0的输入标签(ilabel=0)
- graph_cost:图代价,每条转移弧对应的权重。
- weight_cutoff:要剪枝的阈值

- cost越小越好
- arc.weight:包含hmm 转移概率、词典概率、语言模型概率(不包含am发射概率)(负对数)
- acoustic_cost:am发射概率(负对数)
- 若cost更小,存在该token,有就替换,没有就添加

- 若cost更小,存在该token,有就替换,没有就创建一个

基于token的viterbi解码
类似HMM的解码过程, WFST的Viterbi解码也是逐帧推进,分别计算每帧的声学得分,然后结合转移弧的权重,得到每个时刻扩展路径的累计代价,这些代价用Token的cost保存。
WFST的Viterbi解码通过对比指向同一个状态的不同路径的由Token(==该Token与状态节点关联==,如果状态节点还没有Token,则创建一个新的Token)保存的累计代价(cost) ,选择值更小的并更新Token信息。
Viterbi算法的每个状态最多只有一个Token,如果有多条路径到某个状态,则Token可能存在冲突,根据值更小原则保持或进行替代 。
token:当走到某状态,会有一个token(没走到不会创建),token中的cost会更新
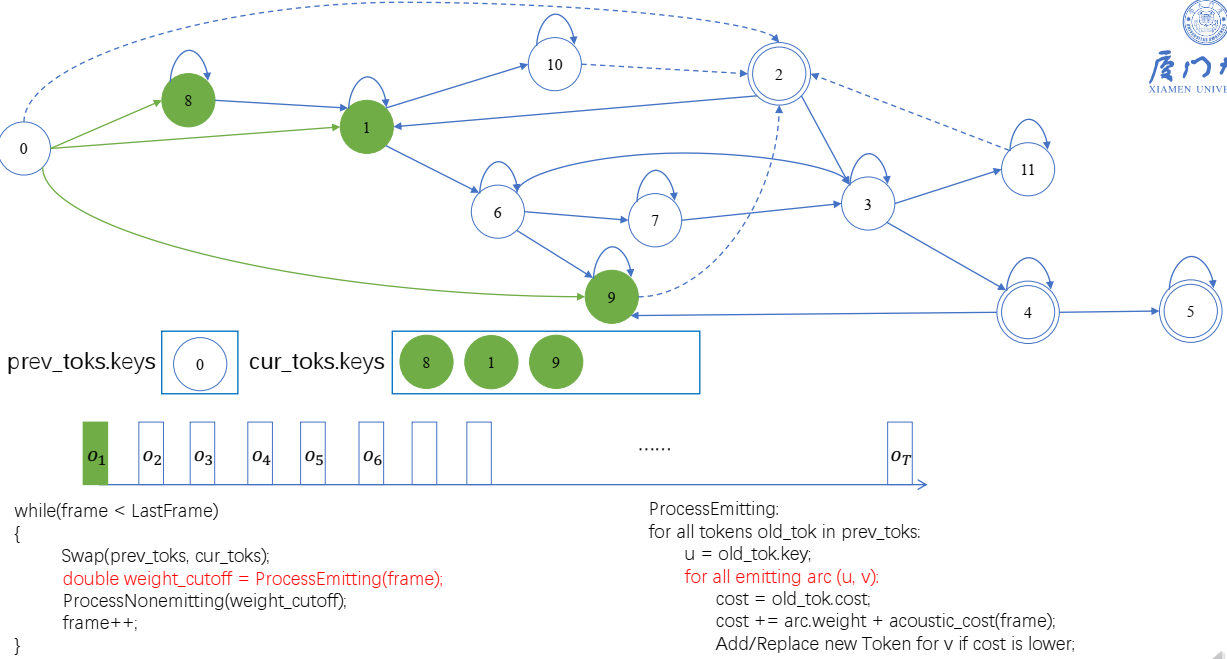
- prev_toks:历史token
- cur_toks:当前token
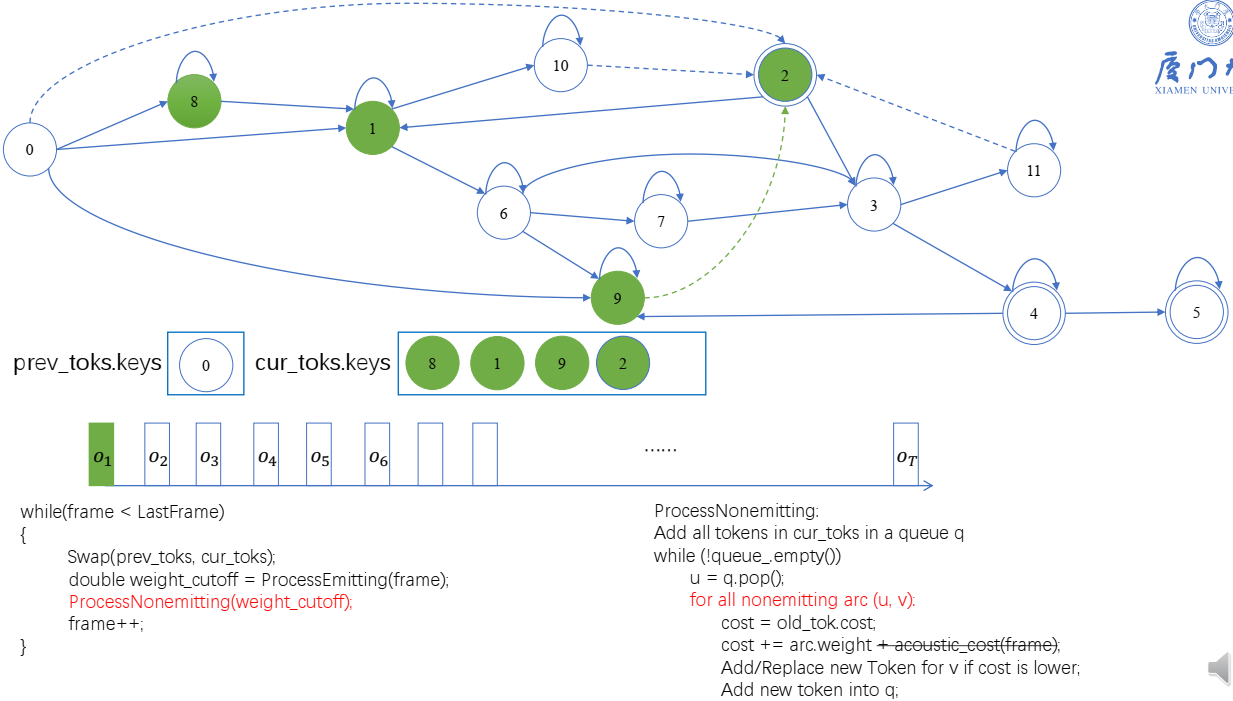
- 当前帧的token:状态0,会遍历,cur_token会依次放进8,1,9,第一次,是创建token。9还会走processnonemitting,走到2,创建状态2的token
第二帧:
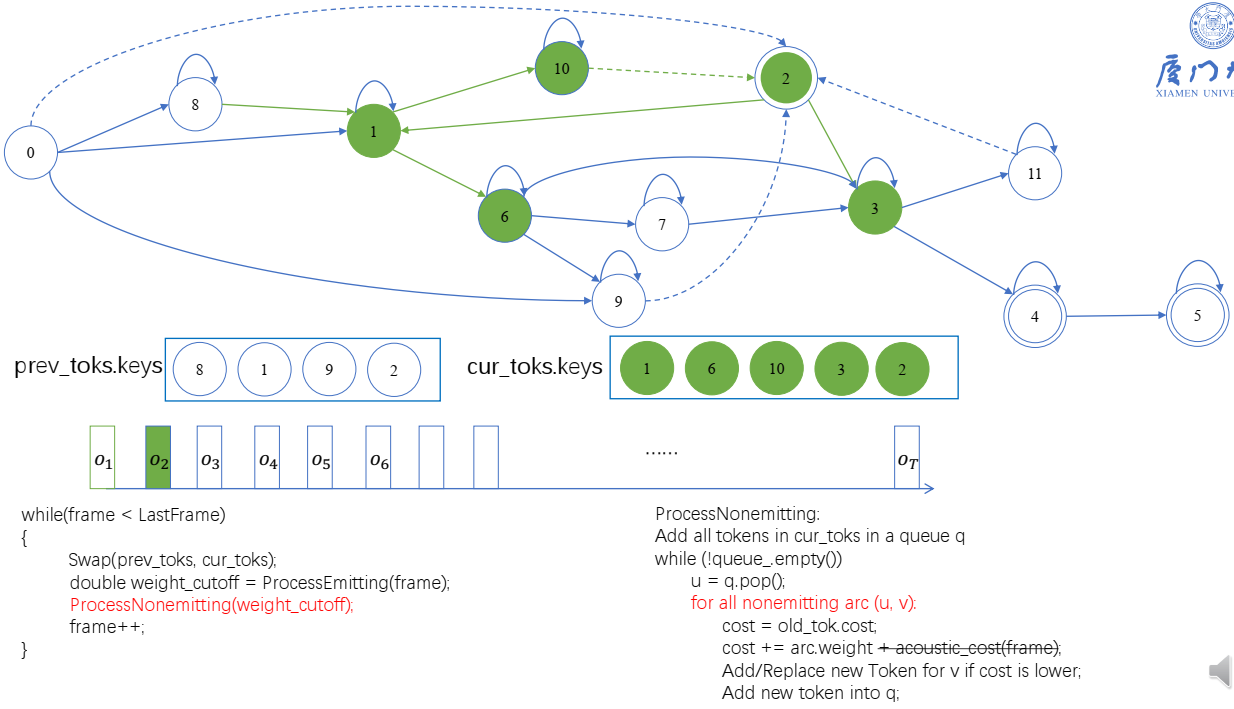
- 10->2:看看状态2的token的cost有没有更小,要不要更新2的token cost
回溯:
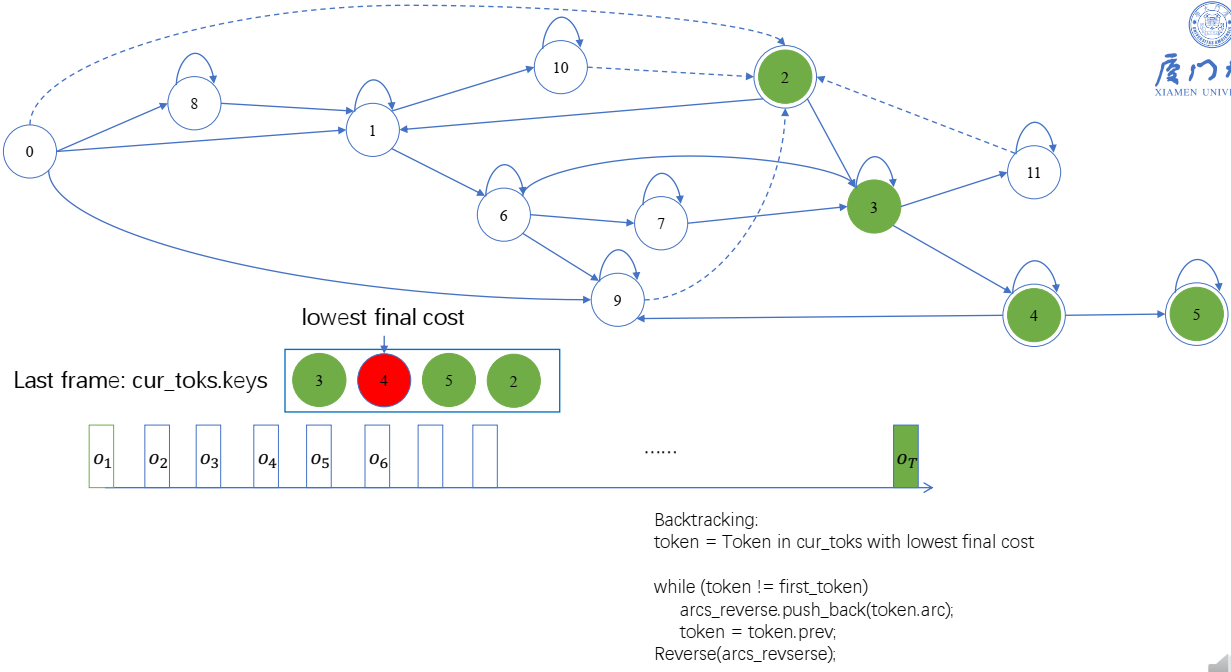
beam:指的是一个窗口范围,对于一个token,到下一个状态弧在不在这个范围里,不在就舍弃,而不是取前beam个,是beam对应的窗口范围