RNN LM
《语音识别原理与技术》洪青阳 P152
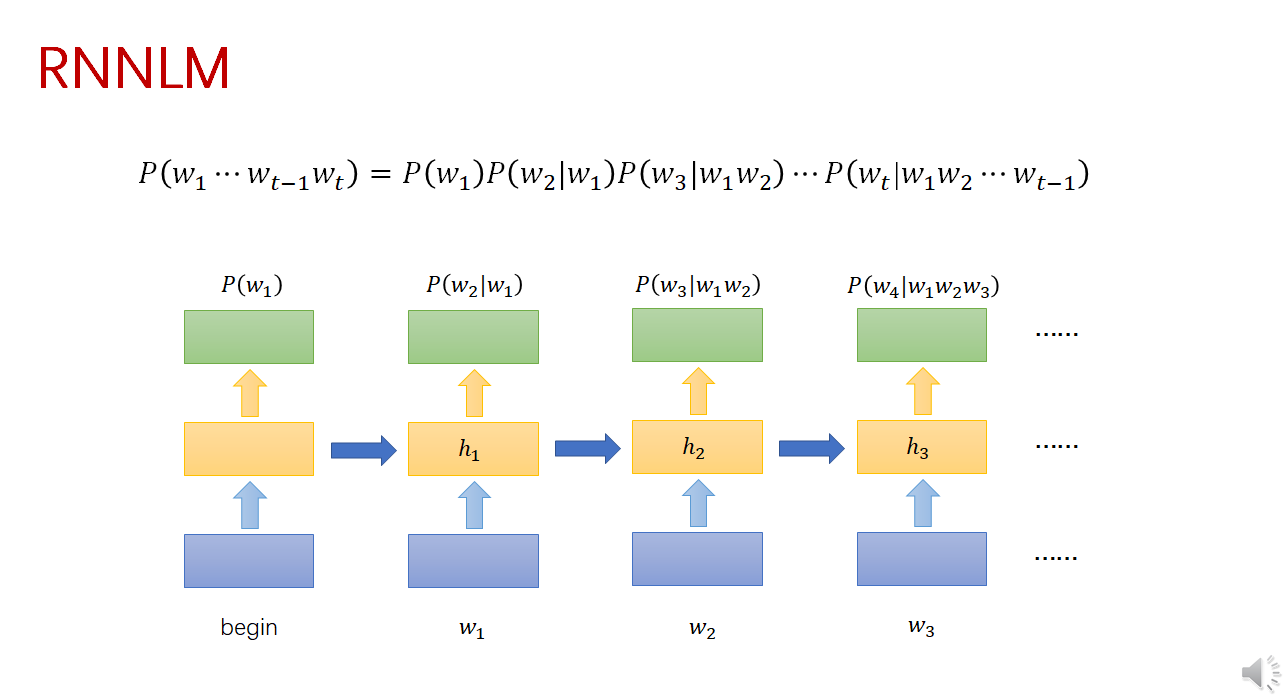
在 RNNLM 中, 词统计概率表示如下:
$$
P\left(w_t \mid w_1 \cdots w_{t-1}\right) \approx P\left(w_t \mid w_{t-1}, h_{t-1}\right)=P\left(w_t \mid h_t\right)
$$
其中, $h_{t-1}$ 是隐藏层向量, 代表 $t$ 时刻之前的词序列 $w_1 \cdots w_{t-1}$ 。
在 RNN 的输人层, 每个词都被映射为 $N$ 维的 1-of- $N$ 向量, 即只有该词对应 的元素为 1 , 向量其余元素为 0 。如在以上词典中, “一个” 对应的 $1-\mathrm{of}-~ N$ 向量为 ${1,0,0,0, \cdots, 0,0}$ 。
输人的词 $w_t$ 被转换为 1-of-N 向量后, 将其输人 RNN 网络。 输出层的输出 $y_t$ 也是一个向量, 向量的每个元素与词典的词一一对应, 即 $y_t$ 的维度也是 $N$ 。(输入输出维度相同,每维代表的意义相同)

由于词很多 N会很大,运算复杂度很高,并且会很稀疏(one-hot编码)。一种有效办法是对单词进行分类。按类别训练语言模型。
$$
P\left(w_{t+1} \mid w_c\right)=P\left(C_{t+1} \mid C_t\right) P\left(w_t \mid C_t\right) P\left(w_{t+1} \mid C_{t+1}\right)
$$
例如:
$$
P(\text { 北京 } \mid \text { 中国 })=P(\text { 名词|名词 }) P(\text { 中国|名词 }) P(\text { 北京|名词 })
$$
其中, 词与类别的组合概率可通过词频数统计得到。这样,即使在训练语料里没 有 “中国 北京” 的组合,但通过类别间概率和词与类别的概率,也可间接计算出这两个词的组合概率, 从而有效地避免了训练数据的稀疏。