序列区分性训练
《语音识别原理与应用》洪青阳 第11章
《11. 序列区分性训练.pptx》
原理公式 直接看PPT或者书就行。
MMI 求导
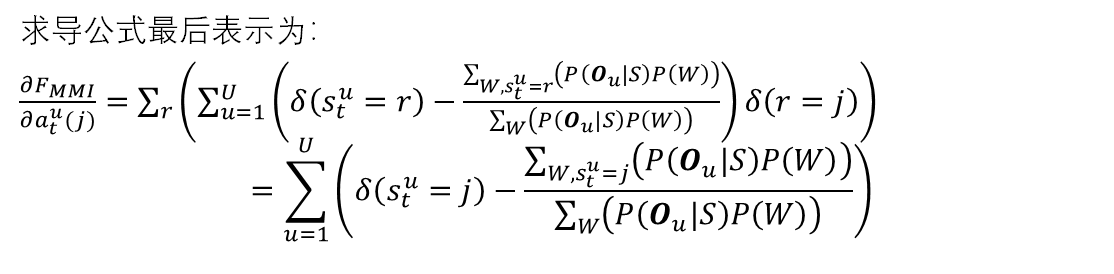
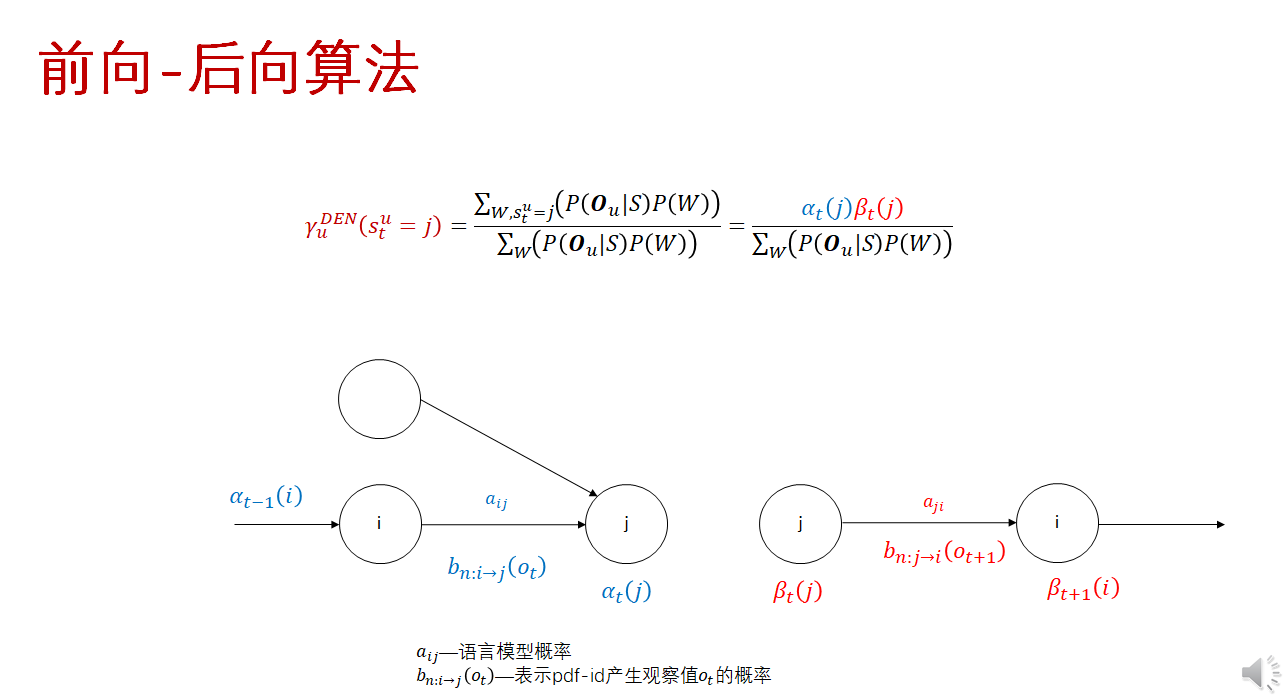
其中,$\alpha_t^u(j)$ 为第 $u$ 条句子 $t$ 时刻的观察值$ o_t^u$ 的在DNN输出节点(状态) $j$ 的激活输出。

$\gamma_u^{NUM}(s_t^u=j)$ 是针对训练标注,$t$ 时刻为状态 $j$ 的后验概率,其计算采用标准的前向-后向算法,复杂度相对较低。而 $\gamma_u^{DEN}(s_t^u=j)$ 虽然也是 $t$ 时刻为状态 $j$ 的后验概率,但要穷举所有可能的词序列对应的状态序列,计算量巨大无比。
我自己的理解:
- 分子网是要计算到某个标注(对齐)状态的所有可能路径(到某个状态的所有可能路径求和通过前后向算法),然后整个对齐标注状态序列,就是对所有时刻 t的状态 j 连乘 就得到分子网(偏导对象是某个时刻t,某个时刻j,这里其实没有算连乘)。
- 分母网也是到某个时刻t的状态j的可能路径概率求和,但是很多不同词序列都有可能在某个时刻t能够处在状态j,因此要对这些所有的不同词序列求和。而分子网考虑的文本序列就是标注序列。
Lattice-based MMI
分母网用n-best代替所有路径的方案比较粗糙,更好的方案是为每个训练句子生成一个词图lattice,来近似mmi的分母部分。
这样, $\gamma_u^{\mathrm{DEN}}\left(s_t^u=j\right)$ 就可通过汇总 Lattice 所有可能的词序列的概率得到。由 于 Lattice 的路径有限, 故需要的计算量将大为降低。
事实上, $\gamma_u^{\mathrm{NUM}}\left(s_t^u=j\right)$ 的前向和后向概率也可通过 Lattice 计算。因此, 每条训练句子均需要生成正确标注和竞争路径对应的 Lattice,包含采用音素 (不需词典) 的简化版语言模型。
基于DNN-HMM的Lattice-based MMI训练流程如下:
- Step1:基于CE准则,训练一个DNN-HMM做为种子模型,并用该模型做状态级别的强制对齐,并生成正确标注对应的Lattice,即MMI分子部分对应的Numerator Lattice;
- Step2:基于一元语言模型构建HCLG,然后对每条训练句子做识别,得到各种竞争路径,保存为MMI分母部分对应的Denominator Lattice。
- Step3:进行Lattice-based MMI训练。
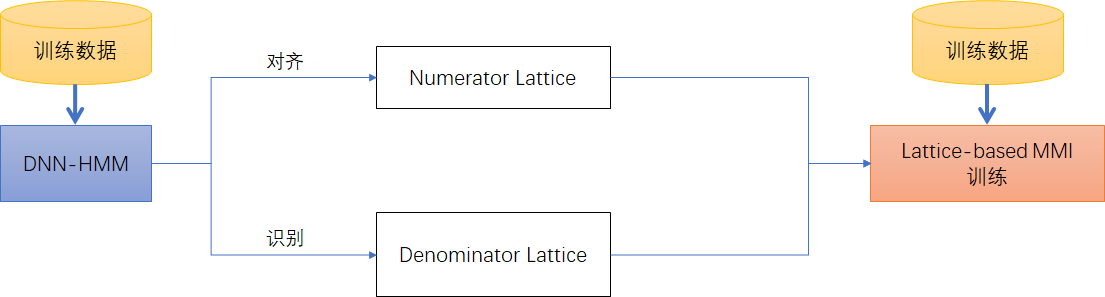
分母网也是用DNN-HMM生成的。分母网是固定的状态序列,无法根据新训练的声学模型动态更新。
Lattice-free MMI
2016年,D. Povey等人提出Lattice-free MMI方案,把分母部分用音素级别的有限状态转换器(FST)图表示,这样可以不用Lattice,做到纯序列区分性训练(Sequence Discriminative Training)。
Lattice-free MMI(LF-MMI)采用音素语言模型(Phone LM)替代词语言模型(Word LM),这样就不需要词典,因此HCLG精简为HCP,其中C由决策树生成,P代表Phone LM,Kaldi设为4-gram,基于训练数据的对齐音素序列训练而成,并且低于3元不采用回退和插值,即3元组合本身不存在的话,不考虑更低元的语言模型,以免引起更多混淆。
由于音素个数比词个数少很多,因此Phone LM产生的FST图很小,最后得到的HCP(即针对MMI分母的FST图)也会小很多,可以直接放到GPU训练。事实上,这个HCP可认为是串接HMM的FST形式,MMI训练的前后-后向计算将基于该FST图进行,HMM 状态之间的转移概率也可根据 FST 找到对应值。
Lattice-free MMI 对应 $\gamma_u^{N U M}\left(s_t^u=j\right)$ 的 FST 的前向-后向计算量较少, 可在 CPU 中运行。而对应 $\gamma_u^{\mathrm{DEN}}\left(s_t^u=j\right)$ 的 FST 的前向-后向计算量较大, 一般要在 GPU 中 运行, 并且有两处特殊处理:
- 不采用对数和指数运算, 为了避免目标函数值突变, 同时需对前向和后向 计算结果做规整。
- 先做 $\gamma_u^{\mathrm{DEN}}\left(s_t^u=j\right)$ 计算, 再做 $\gamma_u^{\mathrm{NUM}}\left(s_t^u=j\right)$ 计算,以减少内存占用。
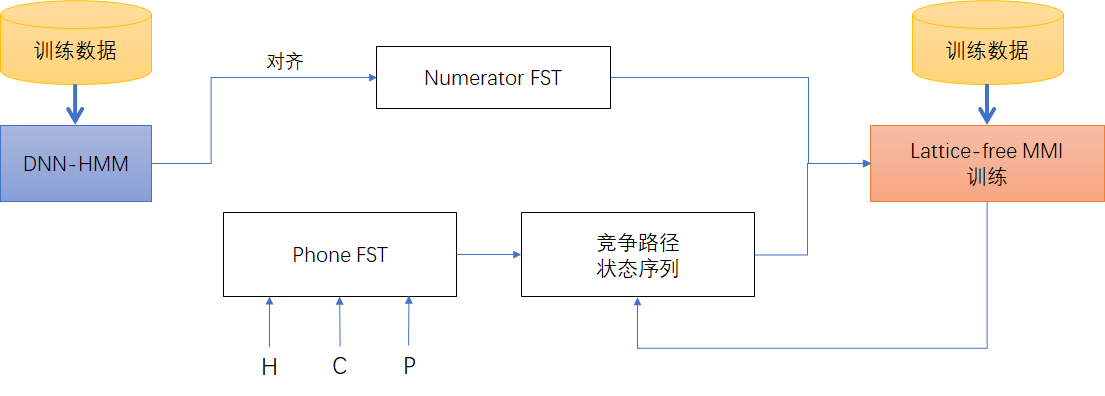
Lattice-free MMI 的训练流程
- Step1:MMI分母部分 $\gamma_u^{\mathrm{DEN}}\left(s_t^u=j\right)$ 的FST前向-后向计算直接使用音素级别的FST图,不需要每个句子分别解码得到的Lattice;
- Step2:基于GMM-HMM或DNN-HMM对齐得到句子的Lattice(以FST形式保存),进行MMI分子部分 $\gamma_u^{\mathrm{NUM}}\left(s_t^u=j\right)$ 的前向-后向计算。
- Step3:进行Lattice-free MMI训练。