计算机科学速成课(四)
2022.12.30
30. 万维网-The World Wide Web
万维网是一个程序,互联网上传输最多数据的程序。(互联网是传递数据的管道,各种程序都会用),万维网的基本单位是”单个页面“。超链接,关联式索引。
为了使网页能相互链接,每个网页需要一个唯一的地址 ,叫统一资源定位器 uniform resource location,url。
一个网页URL,比如 thecrashcourse.com/courses,网络会正常通过TCP/IP访问到thecrashcourse.com的服务器,下一步是向服务器请求”courses“这个网页页面。这种网络连接用的超文本传输协议 HTTP,(超文本指的是某个文本字段有超链接功能),比如向服务器发送指令”GET:/courses“。
超文本标记语言 HTML,不同的html指令,HTML的由来是因为指令也是以文本的形式传输,不好区分哪些是文本、哪些是超文本,因此开发了HTML,一种语言。
做一个网页:

31. 计算机安全-Cybersecurity
可以把计算机安全看成是保护系统和数据的”保密性“,”完整性“和”可用性“。
保密性:只有有权限的人,才能读取计算机系统和数据。黑客泄露别人的信用卡信息,就是攻击保密性。
完整性:只有有权限的人,才能使用和修改系统和数据。黑客知道你的邮箱密码,冒充你发邮件,就是攻击完整性。
可用性:有权限的人,可以随时访问计算机系统和数据。拒绝服务攻击(DDOS)就是黑客发大量的假请求,让网站很慢或者挂掉,这就是攻击可用性。
身份验证、访问控制(r、w、d)
32. 黑客&攻击-Hackers & Cyber Attacks
社会工程学 Social Engineering:欺骗别人让人泄露信息来获得信息,或让人电脑配置成易于攻击的系统。
钓鱼 Phishing,邮件链接,进入假网站。
假托 Pretexting,假装成it部分让人配置电脑。
木马 Trojan Horses。
NAND镜像 NAND Mirroring
漏洞利用 Exploit
缓冲区溢出 Buffer Overflow
边界检查 Bounds Checking和金丝雀
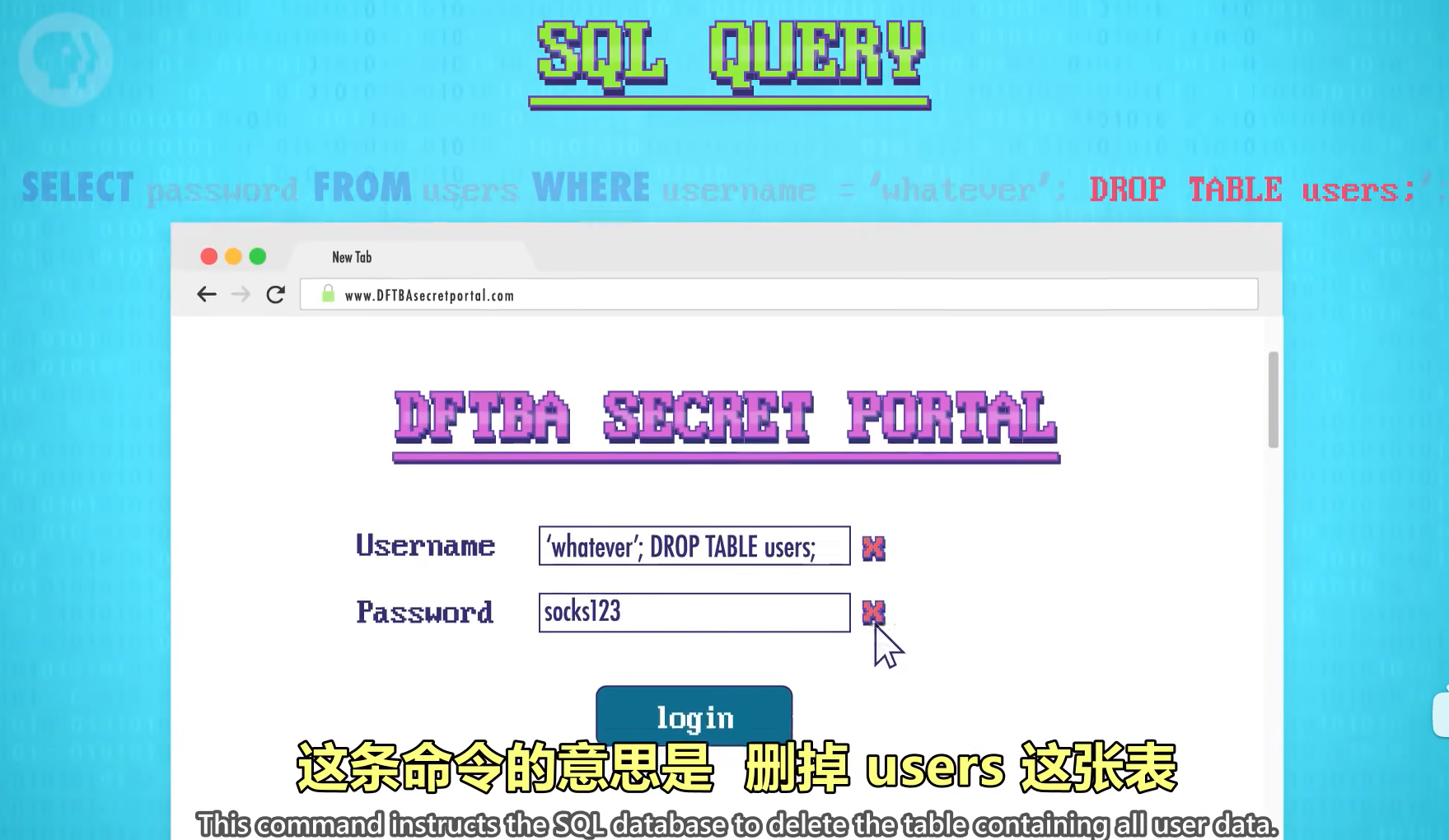
代码注入 Code Injection:攻击用数据库的网站
零日漏洞 Zero Day Vulnerability:当软件制造者不知道软件有新漏洞被发现了,这个漏洞被称为“零日漏洞”
计算机蠕虫 Worms:如果有足够多的电脑有漏洞,让恶意程序可以在电脑间互相传播,这种恶意程序叫做蠕虫
僵尸网络 Botnet:如果黑客掌握足够多电脑,那他们可以组成“僵尸网络”,然后可以比如发大量的垃圾邮件、或者用别人的电脑的计算能力和电费挖比特币。
33. 加密-Cryptography
计算机安全中最常见的防御形式,密码学Cryptography。
加密 - Encryption,解密 - Decryption
凯撒加密 Caesar cipher——一种替换加密 Substitution cipher,把字母替换成其他字母。但是没有改变字母频率,有些很高频出现的字母,替换后很容易看出来。
移位加密 Permutation cipher
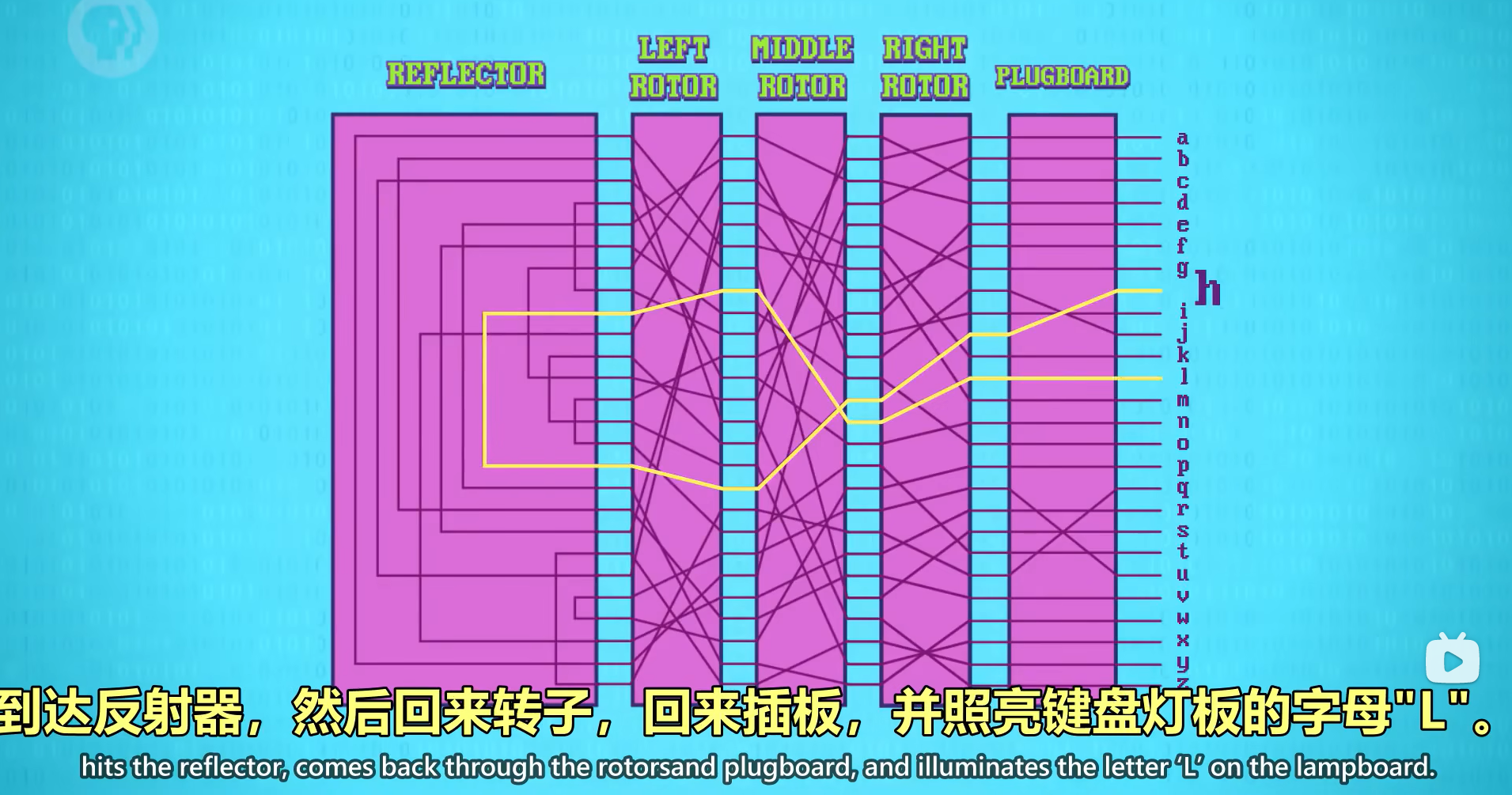
enigma 英格玛
AES密钥 128位/192位/256位 因此很难暴力破解
密码交换 key exchange ,是一种不用发送密钥,也能让两台计算机在密钥达成共识的算法。(密码由发送者发送,接收者需要解密)。举例,双方都有一个密钥,a和b,还有一个公共密钥p。a和p某种方式混合后发送给b,与b混合,得到a、p、b的混合,b和p某种方式混合后发送给a,与a混合,得到b、p、a的混合,于是双方混合后的结果相同,就得到了某个只有双方知道的密钥。而比如黑客可能可以看到a和p的混合结果,或者b和p的混合结果(在网络中传输),但是混合简单,解混合困难,a和p混合结果再拆分成a与p是困难的,因此很难知道密钥。
建立共享密钥,双方用一样的密钥加密和解密消息,这叫”对称加密“,因为密钥一样。
迪菲-赫尔曼密钥交换 diffie-hellman 数学单向函数。函数比如用模幂函数,一个数字做底数,一个数字做指数,一个数字做要除的数(模数),最后得到的余数作为密码。$B^x\mod M$ , 如果只给M和B、余数,很难猜出指数x是多少,比如3的某次方 模31,余数是7,很难猜出次方是多少。
diffie-hellman 算法 流程如下:公开的值 public value 有 基数 B (base)和 模数 M (modulus),计算机双方都选一个指数数字,a选x,b选y,然后a计算 $B^x\mod M$ ,发送给b; b计算 $B^y\mod M$ 的结果,发送给a。为了算出双方共用的密钥,a把 $B^y\mod M$ 用a的指数x进行模幂运算 $(B^y\mod M)^x=B^{yx} \mod M$ ,b把 $B^x\mod M$ 用b的指数y进行模幂运算 $(B^x\mod M)^y=B^{yx} \mod M$ 。因此双方有一样的密钥,即使从来没给对方发过各自的秘密指数(x和y)。
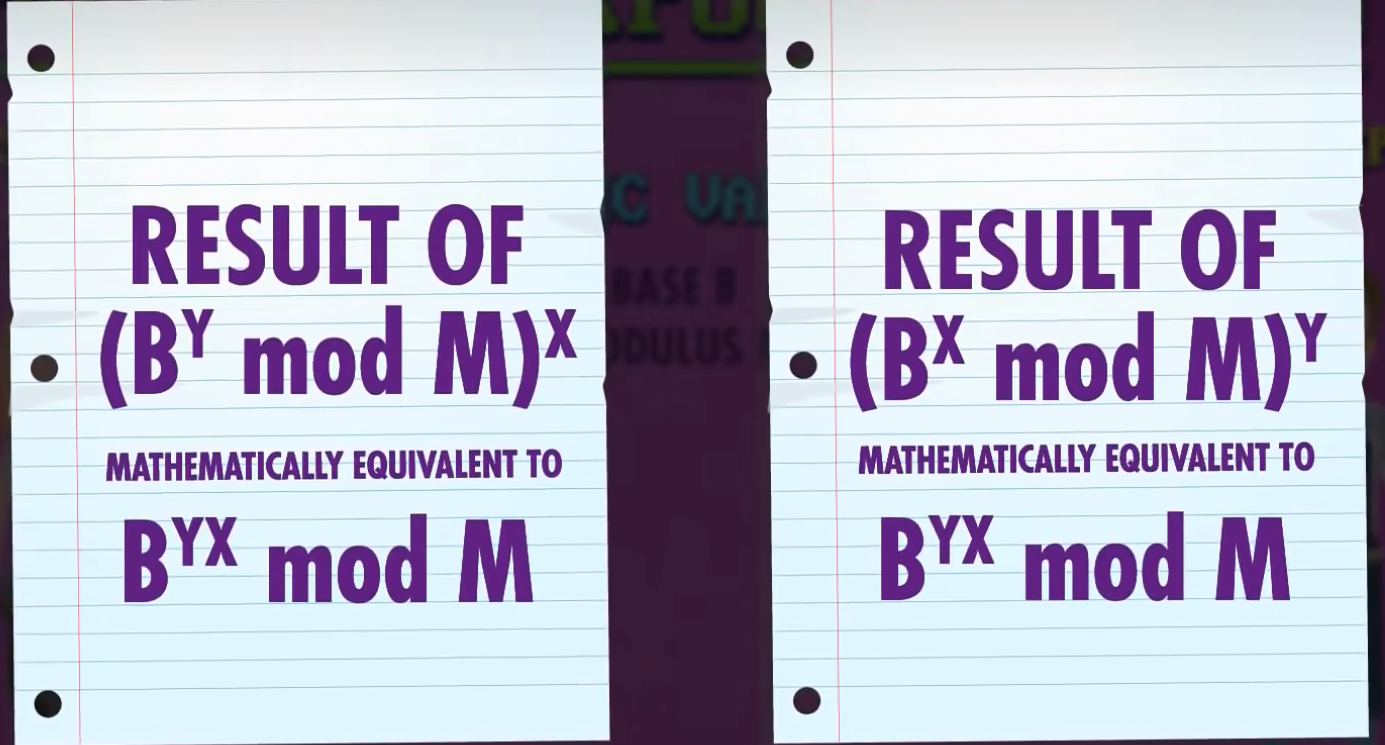
非堆成密钥 一个是公开的,一个是私有的。用公钥加密消息,只有有私钥的人能解密。反过来也可以,私钥加密后,用公钥解密。服务器用私钥加密,任何人都可以用公钥解密,RSA
34. 机器学习&人工智能-Machine Learning & Artificial Intelligence
从数据中学习。
SVM:用任意线段来切分”决策空间“,不一定是直线,可以是多项式或其他数学函数(决策边界)。
35. 计算机视觉-Computer Vision
举例:找垂直边缘的算法:认为色差大的可能是边缘。用到了卷积convolution。
卷积过程这里是把一个 [[-1,0,1],[-1,0,1],[-1,0,1]]的核作用到像素上,对应点相乘再全相加。

一张灰度图:

经过卷积后变为:

用 对水平边缘敏感的“核”,提取后:

这两个边缘增强的核叫“prewitt”算子 opterators
【inspired!!】以前总看见一开始的卷积是提取边缘,一直没有理解是什么意思,直到看到这个视频,才知道卷积核的不同,真的可以提取边缘、变模糊 等一系列操作,随着层数往上,提取的是更大范围的“不同”,比如就能看到嘴巴、鼻子了。之前一直没理解,是因为卷积核参数是神经网络更新的,而“核”的提出,一开始是人为构造里面的参数的!如果要提取垂直边缘,核参数就是 $\begin{bmatrix} -1 & 0 & 1\ -1 & 0 & 1 \ -1 & 0 & 1 \end{bmatrix}$ 。 如果要提取(突出)水平边缘 核参数就是 $\begin{bmatrix} -1 & -1 & -1\ 0 & 0 & 0 \ 1 & 1 & 1 \end{bmatrix}$ 。
核能做很多种图像转换。
比如锐化图像的核 $\begin{bmatrix} -1 & -1 & -1\ 1 & 9 & -1 \ -1 & -1 & -1 \end{bmatrix}$ :

模糊图像:

核也可以像饼干模具一样,匹配特定形状。
比如做边缘检测的核 $\begin{bmatrix} - & +\ \end{bmatrix}$ 和 $\begin{bmatrix} - \ + \end{bmatrix}$ 。会检查左右和上下的差异。
比如做出擅长找线段的核 $\begin{bmatrix} -&+&-\ \end{bmatrix}$ 和 $\begin{bmatrix} - \ + \ - \end{bmatrix}$ (比如找出鼻梁,因为鼻梁比鼻子两侧更亮)
比如包了一圈对比色的区域(比如找出眼睛)
这类核可以描述简单的形状。
核“找出”某想要的形状 的意思是卷积后这个区域的值会更高。而其他区域值会低。
计算机扫描图像,最常见的是用一个窗口扫,多个核组合,能找出人脸,虽然单个核找出脸的能力很弱,但组合在一起会相当准确,因为 “不是脸 却有一堆脸的特征在正确的位置 这种情况不太可能” ,哈哈。这叫 viola-jones face detection 维奥拉-琼斯人脸检测算法。
36. 自然语言处理-Natural Language Processing
人类语言叫“自然语言”
分析树 parse tree
短语结构规则
知识图谱 knowledge graph 。包含大量实体,以及不同实体之间的关系。
语音识别
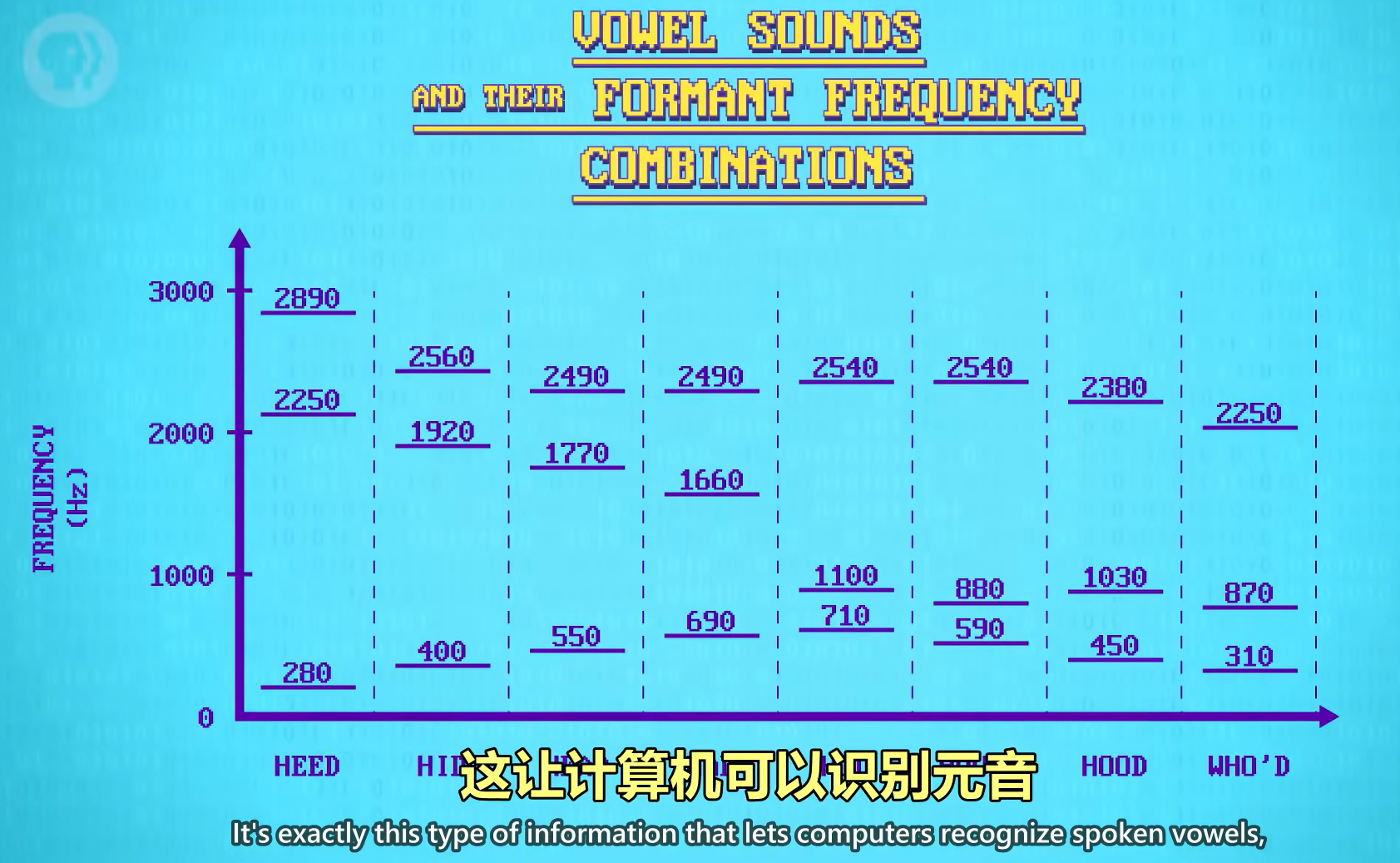
频谱图。可以看出不同音的共振峰 formant 是有区别的。因此可以通过共振峰来区分不同的音。

37. 机器人-Robots
控制回路 control loop的目的是把机器人的属性(比如当前位置)变成期望值(比如想让机器人到达某个位置)。
PID控制器
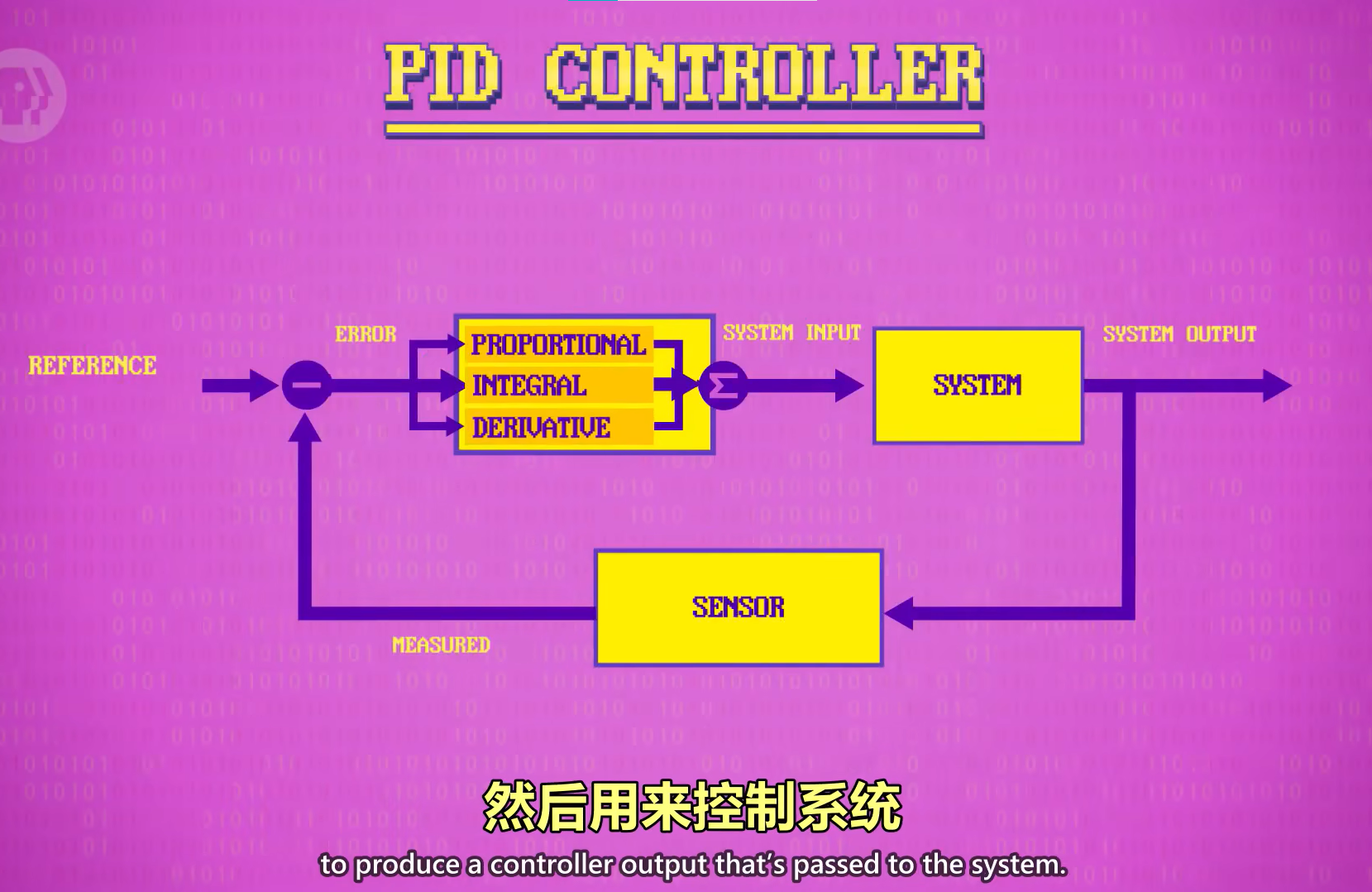
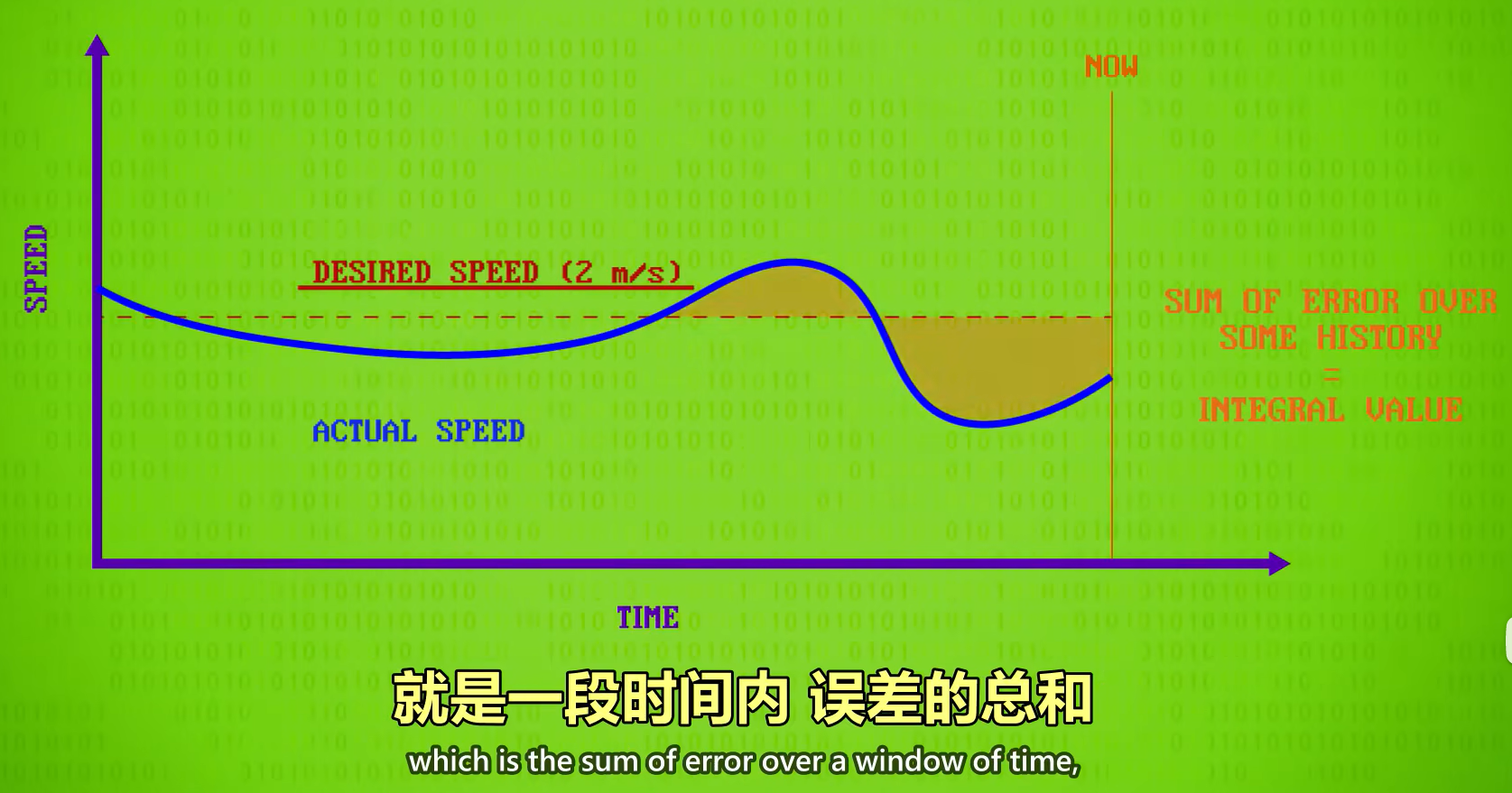
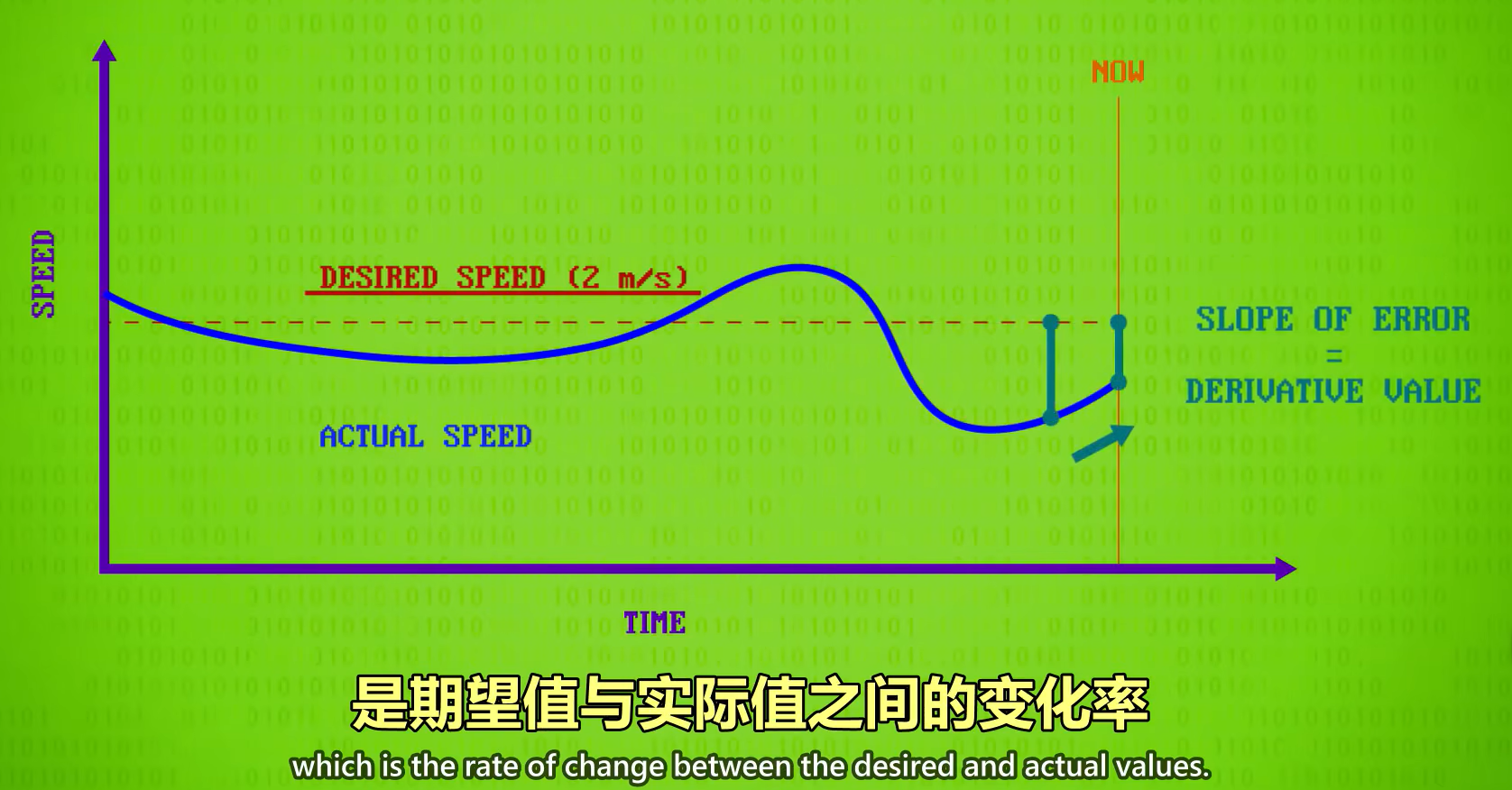
PID 原理:以速度为例,我们希望保持匀速,但是实际有外界影响,可能当前速度核理想速度不一致,PID会计算三个值,第一个值是“比例值”,就是实际值和理想值差多少,实际值和理想值的差距越大,就需要越用力,因此是“比例控制”的。第二个值是“积分值”,是一段时间内的误差总和,比如最近的几秒钟,帮助弥补误差,比如上坡(速度变慢)就会产生误差,如果这个积分值(误差值)很大,说明比例控制得不够,要继续用力前进来减少误差。第三个值是“导数值”,是理想值与实际值之间的变化率,有助于解决 未来可能出现的错误,也叫“预期控制”,比如前进得太快(导数值很大),就要放松一点,避免冲过头。这三个值会一起使用,有不同的权重,然后用来控制系统。
积分值:
导数值:
38. 计算机心理学 - Psychology of Computing
系统设计师在创造软件时,会运用社会心理学,认知心理学,行为心理学,感知心理学的原理。
增强凝视,在视频通话、会议、虚拟教室中,用计算机软件修正眼睛方向,看起来像是在凝视着对方的眼睛。
39. 教育科技-Educational Technology
主动学习的技巧可以提升学习效率。
主动学习的技巧:
- 把视频速度调整到适合你的速度,让你能理解视频,有足够时间思考;
- 暂停!在困难的部分暂停。问自己一些问题,看能不能回答。或想想视频接下来可能讲什么,然后继续播放,看猜对没有;
- 做视频中提供的练习;
智能辅导系统 intelligent tutoring system。判断规则 production rule。学生做完一个步骤后可能触发多个“判断规则”,系统虽然不能完全弄清是什么原因让学生选择了那个答案,但是可以通过“判断规则”和算法结合 判断可能原因,让学生得到有用反馈。

贝叶斯知识追踪 bayesian knowledge tracing 。记录4个概率,1.学生已经学会的概率;2.瞎猜的概率(答对但是是蒙的);3.失误的概率(答错但是是不小心填错的);4.做题过程中学会的概率(一开始不会,解决问题过程中学会了怎么做)。
mastery learning

教育数据挖掘。
neal stephenson的“钻石时代”书。
40. 奇点,天网,计算机的未来-The Singularity, Skynet, and the Future of Computing
普适计算 ubiquitous computing,我理解就是各行各业、各个地方都用上计算机。
智能科技的失控性发展叫“奇点” singularity。
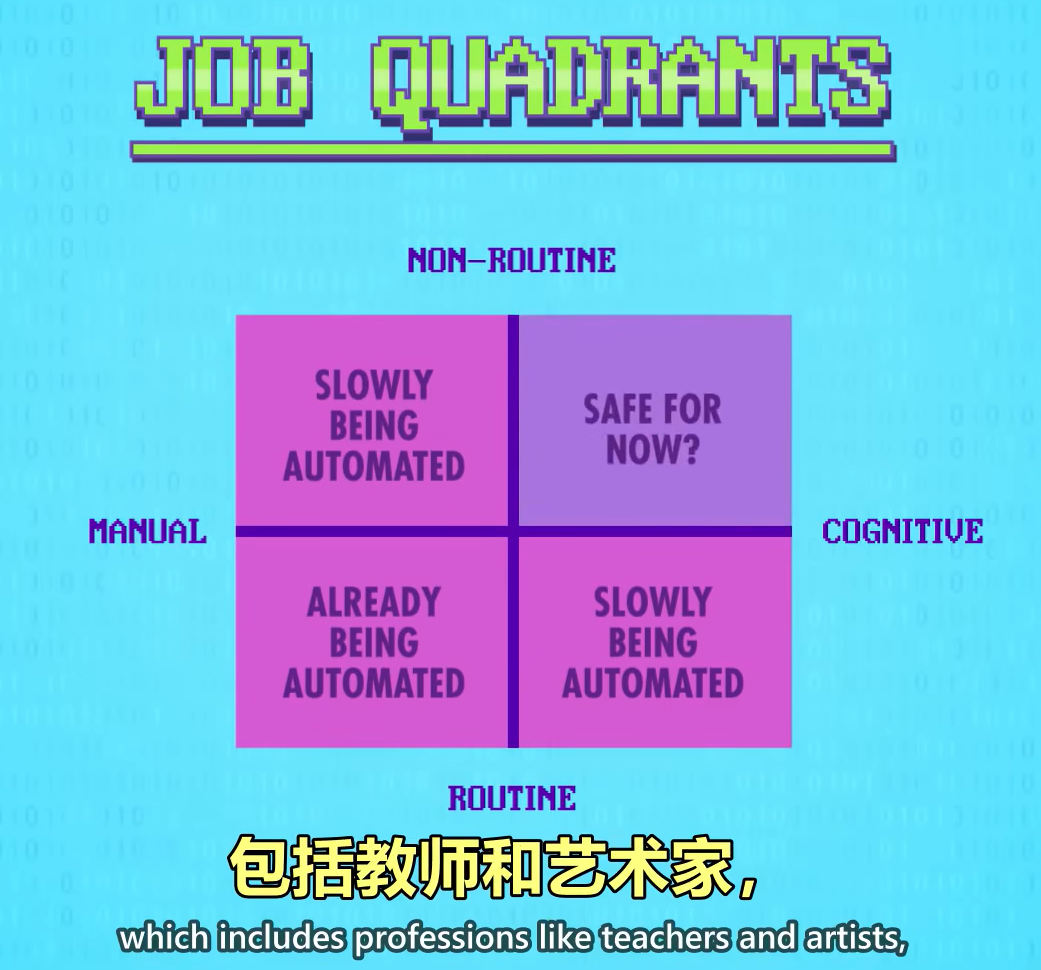
工作可以分成两个维度,分别是“从手工型到思维型”,“从重复性到非重复性”,(手工型 manual 比如组装玩具,思维型 cognitive 比如选股票)
重复性手工型工作,可以让机器自动化;
非重复性手工型工作,比如厨师、服务员、保安;
重复性思维型工作,比如客服、收银员、银行柜员和办公室助理;
非重复性思维型工作,比如教师、艺术家、小说家、律师、医生、科学家;