端到端合成论文——声码器——Melgan
Kumar, Kundan, et al. “Melgan: Generative adversarial networks for conditional waveform synthesis.” Advances in neural information processing systems 32 (2019). citations:561 Lyrebird AI 、蒙特利尔大学
github:https://github.com/descriptinc/melgan-neurips
试听音频:https://melgan-neurips.github.io
相关应用:https://www.descript.com/overdub
知乎:MelGAN解构与分析
解决什么问题
基于GAN的vocoder合成waveform效果不好的问题;
用了什么方法
提出一个基于GAN的vocoder,叫melgan,在语音合成、音乐翻译(music domain translation)和 unconditional 音乐合成领域都有好的效果,说明该vocoder的适用性很广;
效果如何
轻量级架构,全卷积结构;
合成速度快,在GTX 1080Ti GPU上运行是realtime的100倍快,在CPU上运行是realtime的2倍快;
存在什么问题
音质不够好,MOS=3.09;
相关工作
vocoder分三类:
Pure signal processing approaches
代表为 Griffin-Lim (Griffin & Lim, 1984) 、WORLD vocoder (MORISE et al., 2016) ,world vocoder是attention based的RNN结构,用于Char2Wav 等模型;
Autoregressive neural-networks-based models
代表为 WaveNet (Van Den Oord et al., 2016) 、SampleRNN (Mehri et al., 2016) 、WaveRNN (Kalchbrenner et al., 2018) 、FFTNet(wavnenet的改进)
Non autoregressive models
- flow-based:Parallel Wavenet (Oord et al., 2017) 、Clarinet (Ping et al., 2018) ,蒸馏一个自回归教师模型,基于flow的卷积学生模型,loss为学生教师分布之间的KL散度;
- based on Glow :WaveGlow (Prenger et al., 2019) 基于Glow的flow-based生成模型,模型较大;
这篇论文提出之前的GAN用于合成vocoder的做法:有使用GANs通过建模STFT的幅值和相位角来生成音乐音色,而不是直接建模原始波形、有用GAN映射mel谱到幅度谱、有用GAN蒸馏自回归模型;
思路
- 提出MelGAN,这是第一个成功训练基于GAN输出波形的模型,不需要通过蒸馏手段或感知loss作为辅助;
- 通过在通用音乐翻译、文本到语音生成和无条件音乐合成方面的实验,我们表明自回归模型可以很容易地被快速并行的MelGAN解码器取代,用于生成原始波形,尽管质量略有下降。
- 合成速度快,比目前最快的model快10倍;
模型
生成器
结构
输入mel谱(mel-spectrogram)s,输出波形x,因为输入维度小于输出维度(时间分辨率低256倍),因此堆叠一堆卷积层进行上采样;
结构全由卷积层构成:转置卷积 👉 残差结构的空洞卷积 ,作为一个block,堆叠N个block;
和传统GAN不同,不是用噪声作为输入,也不是用噪声作为辅助输入,因为发现辅助噪声对波形没帮助,这很反直觉,因为一般合成输入到输出是一到多映射,因此加点噪声有助于合成音频,但是可能因为mel谱信息太丰富,噪声没什么用了;
Induced receptive field
在conv神经网络的生成器中,由于诱导感受野之间的高度重叠,存在一种诱导偏差,即空间上靠近的像素点是相关的。我们设计我们的生成器架构,把一个归纳偏差,在音频时间步之间有长范围的相关性。在每个上采样层之后,我们添加了带有膨胀dilated的residual block,以便每个后续层的远端输出激活具有显著的重叠输入。dilated conv layer叠加的感受野随层数呈指数增长。因此,生成器允许有效地增加每个输出时间步的诱导接受野,即在相隔很远的时间步的诱导感受野中有更大的重叠,从而导致更好的长范围相关性。
Checkerboard artifacts
棋盘效应,repeated patterns 会导致高频有嘶嘶声,要小心选择解卷积层的kernel-size和stride、dilated,即kernel-size是stride的整数倍,dilation是kerenl-size的幂次;
Normalization technique
选择不同的归一化方法直接影响合成质量;图像GAN里用的instance normalization,但音频GAN里instance normalization会冲掉pitch信息,使音频听起来像金属声;用谱归一化spectral normalization 效果也不好,用 Weight normalization (Salimans & Kingma, 2016) 效果好;Weight normalization通过解耦权重向量的尺度与方向解耦来重新参数化权重矩阵;
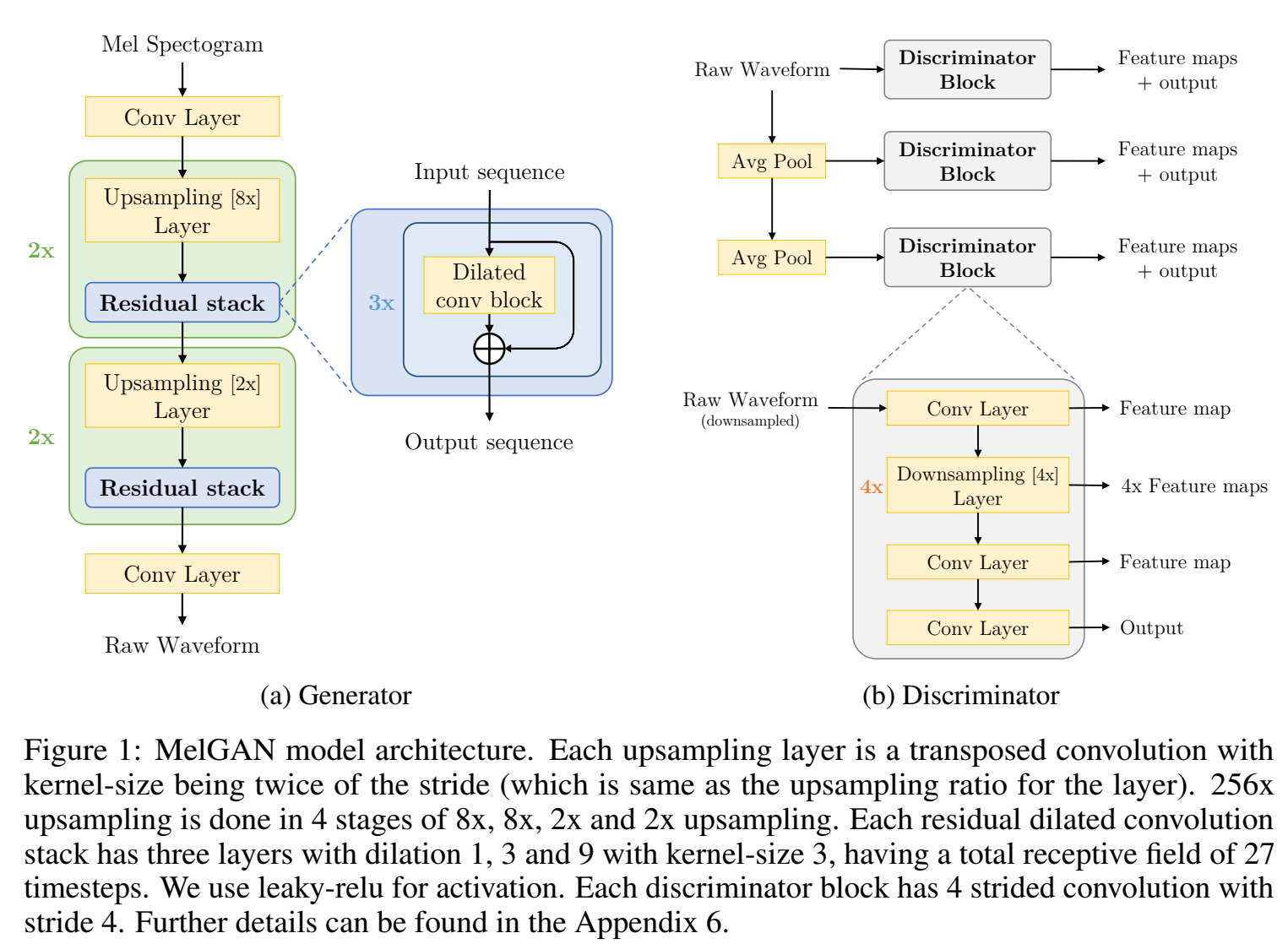
判别器
Multi-Scale Architecture 多尺度判别器
判别器用的MSD,这个在后续工作hifigan中使用了;用的3个子判别器,第一个判别器输入是生成器的输出waveform,第二个判别器输入是下采样(平均池化)2倍的waveform,第三个判别器是下采样(平均池化)4倍后的waveform作为输入;三个输入表示了不同尺度的音频特征,即不同频带特征;下采样的后的音频就没有高频了,因此输入是下采样过的子判别器会倾向于学习低频;(由傅里叶变换可知,信号是由无数个正弦波信号叠加而成的,多个子判别器的设置,分别处理不同降采样倍率的信号,以学习音频中不同频段的“模式”,假设采样频率为22k(信号频率最大11k):第一个MSD判别器能采的信号频率为0 ~ 11K;第二个为0 ~ 5.5K;第三个为0 ~ 2.25K;)
Window-based objective
之前的判别器分类的对象是整条音频样本,而用窗口判别器,分类的是音频片段,窗口是overlap的窗口,每个窗口长度等于判别器的感受野,判别器的特点是卷积层的kernel-size很大(window长度也不短,不然不好分类音频了)(用group conv让卷积层参数量不会很大);
windows判别器的优势是可以捕捉高频特征?;
结构上也用的weight norm;
目标函数
GAN的loss,采用的是 hinge loss 版本的GAN目标,并用的最小二乘 least-squares (LSGAN) 来改善原始的hinge loss;
GAN loss
$$
\begin{aligned}
&\min {D_k} \mathbb{E}x\left[\min \left(0,1-D_k(x)\right)\right]+\mathbb{E}{s, z}\left[\min \left(0,1+D_k(G(s, z))\right)\right], \forall k=1,2,3 \
&\min G \mathbb{E}{s, z}\left[\sum{k=1,2,3}-D_k(G(s, z))\right]
\end{aligned}
$$
其中 $x$ 表示真实波形,$s$ 表示conditioning information(比如mel谱),$z$ 表示高斯噪声向量;
Feature Matching
feature matching objective用来辅助生成器更新,注意这里和hifi-gan不同,hifi-gan用的是mel谱之间的L1距离(频域),这里用的判别器输出的L1距离,应该算是时域(波形);但是如果直接用x和G(s)计算L1距离作为辅助loss,合成的音质反而会有噪声,会更差!(这个图像领域的gan的结论相反)因此这里是用判别器输出来计算L1距离;
$$
\mathcal{L}{FM}(G,D_k)=\mathbb{E}{x, s\sim p_{data}}\left[\sum_{i=1}^T \frac{1}{N_i}\left|D_k^i(x)-D_k^i(G(s))\right|_1\right]
$$
其中,$D_k^{(i)}$ 表示第 $k$ 个判别器的第 $i$ 层 feature map输出(中间层);$N_i$ 表示每层的神经元梳理;Feature matching 和感知loss(perceptual loss)很像;
生成器的Final loss
$$
\min G \left(\mathbb{E}{s, z}\left[\sum_{k=1,2,3}-D_k(G(s, z))\right]+\lambda\sum_{k=1}^3\mathcal L_{FM}(G,D_k) \right)
$$
其中,$\lambda=10$ ;
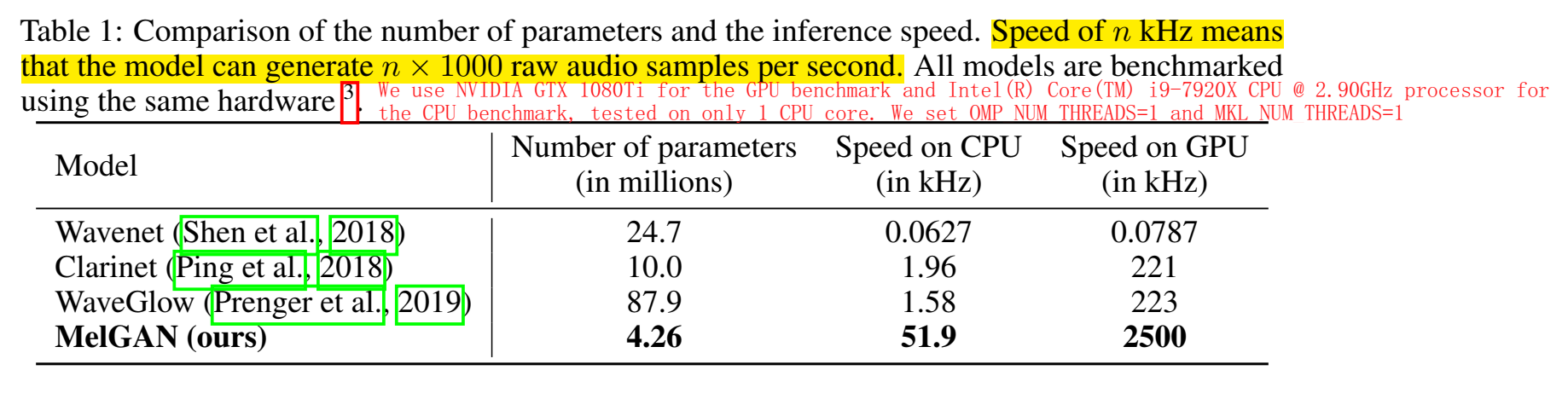
参数量和推理速度
在GTX1080 Ti GPU in full precision 上的合成速度为 2500kHz,在CPU上的合成速度为 50kHz
Speed of n kHz means that the model can generate n × 1000 raw audio samples per second.
实验
Ground truth mel-spectrogram inversion
Ablation study
数据集 LJ Speech dataset ,训练 400k次迭代;
MOS分比较:
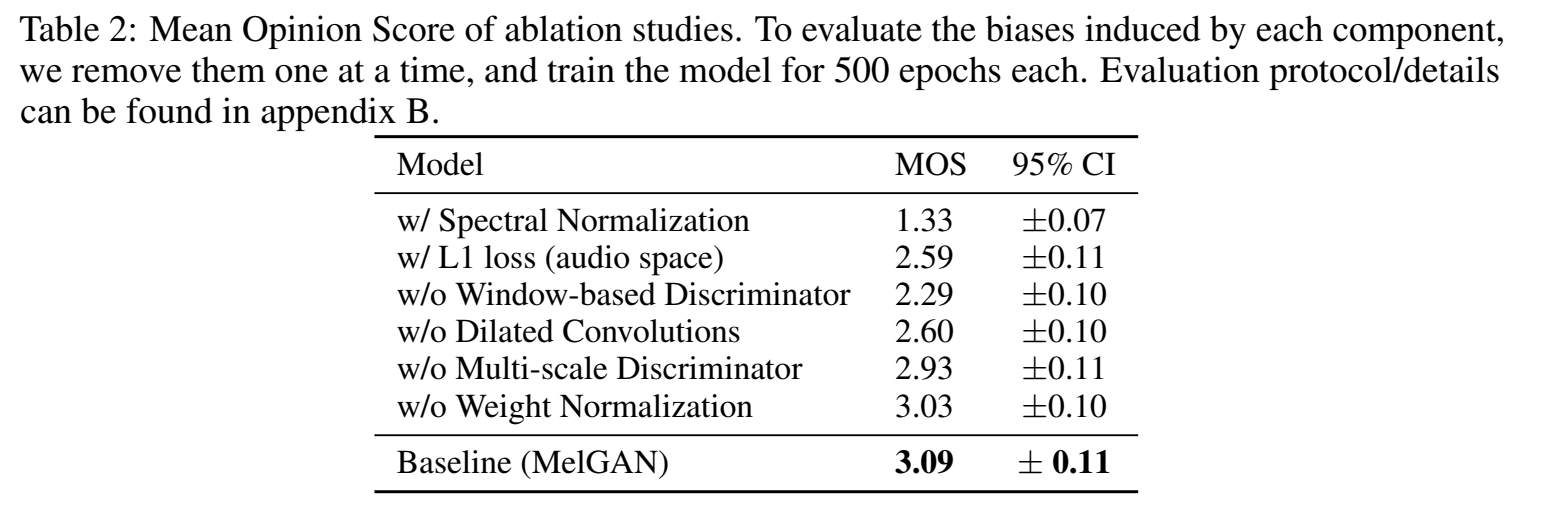
可以看出,有spec norm和L1 loss(audio space)都会影响音质,其中melgan里的Window-based Discriminator 对音质的帮助最大;
根据实验结果有几个结论
- 生成器没有dilated conv stack,或少了weight norm,会导致高频伪影(high frequency artifacts);
- 只使用单个判别器(而不是多尺度判别器)会产生金属声音(metallic audio)(当说话人有呼吸声就会更明显),并且会跳过一些单词没读!
- 用spec norm或不用window-based 判别器 loss,会很难学到sharp高频pattern,导致音频听起来有明显噪声;
- 添加波形的L1 loss使得合成音频听起来像金属声,并且有额外的高频伪影 high frequency artifacts(高频伪影可以通过denoiser降噪器去除);
Benchmarking competing models
不同的vocoder之间进行比较,输入为真实音频的mel谱,melgan训练了2.5M次迭代:
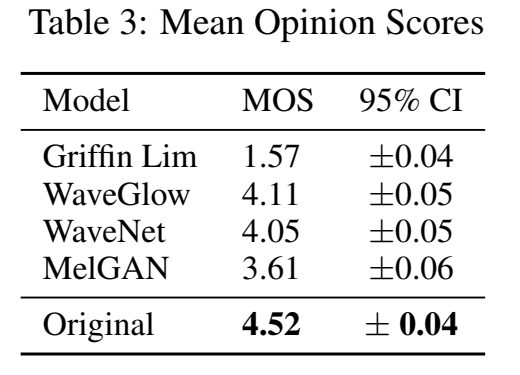
melgan音质相比于wavenet、waveglow来说都差了一些;
Generalization to unseen speakers
用说话人的数据集训练melgan,模型可以生成训练集没有的说话人声音,该实验表明了melgan可以学到的是说话人不变的(speaker -invariant)mel谱到waveform的映射;
End-to-end speech synthesis
用声学模型+不同声码器,验证该声码器效果
MOS分对比如下:
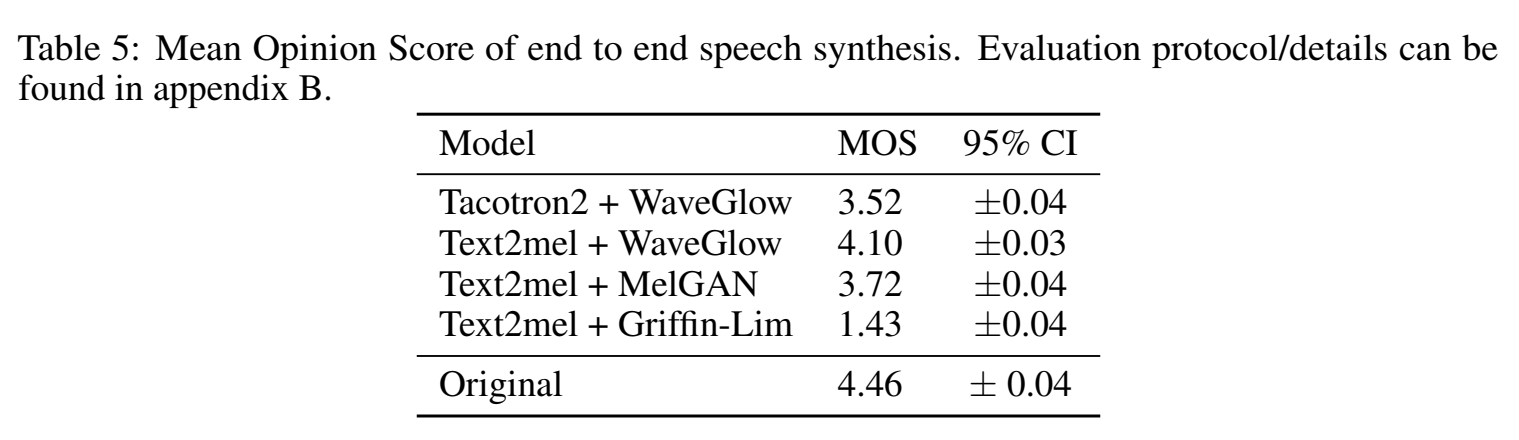
其中,Text2mel是一个开源的char2wav model;
图上没有wavenet的实验结果,因为text2mel+wavenet的mos为3.4,可能是开源的模型有点问题?
图上的tacotron2+waveglow是开源的,作为对比,并没有实现tacotron2+melgan的实验,感觉这篇论文实验不是很充分;
Non autoregressive decoder for music translation
为了表现melgan的普适性,在music translation领域上的表现。
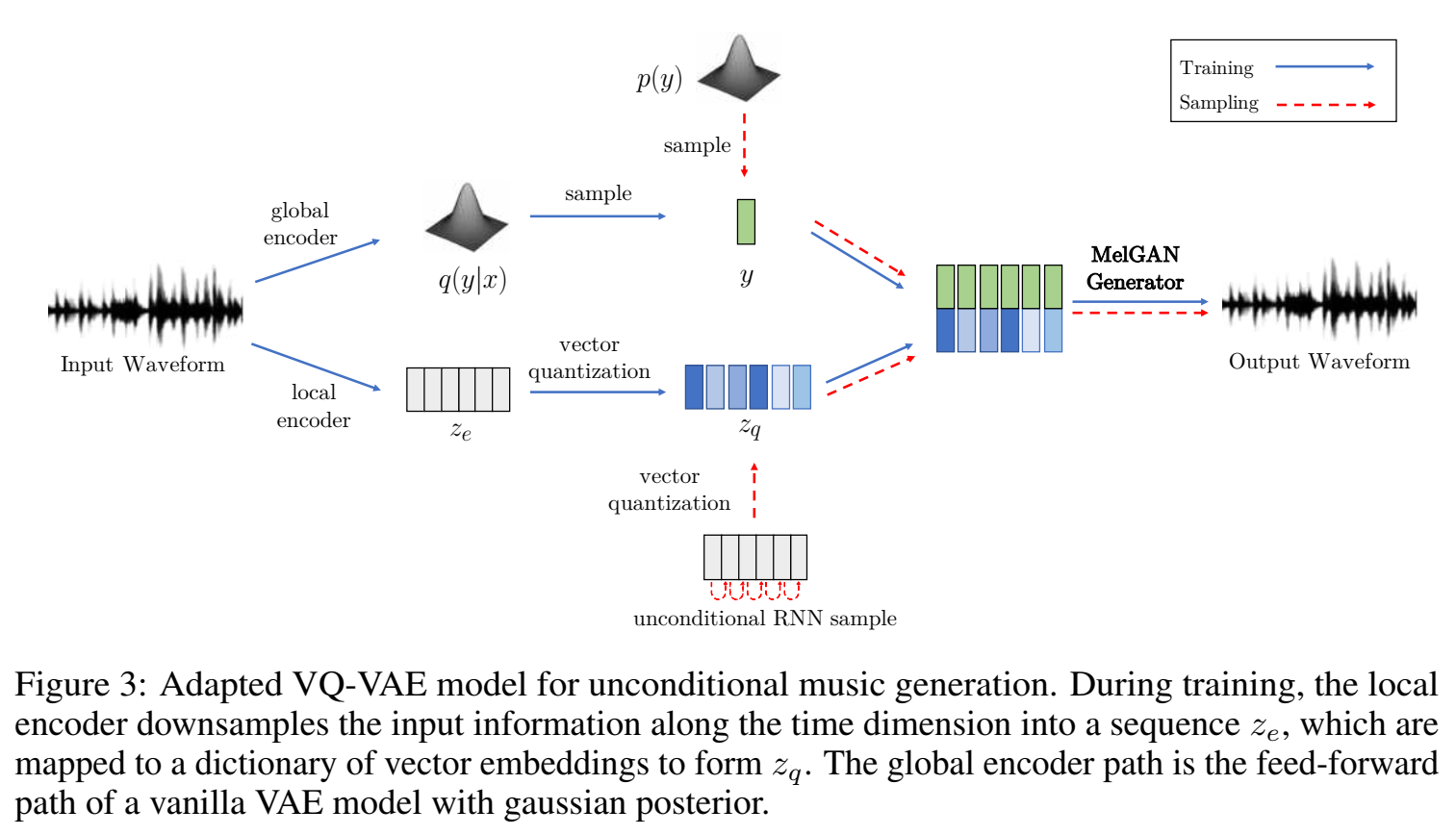
Non-autoregressive decoder for VQ-VAE
为了进一步表现melgan的普适性,与Vector-Quantized VAEs (van den Oord et al., 2017) 进行对比。
TODO
结论
提出一种条件语音合成(条件指的是mel谱)架构,基于GAN,叫melgan,定性定量分析了它,melgan有以下几个特点:lightweight轻量级,训练在单GPU上也能很快收敛,有较快的推理速度;但它受到时间对齐条件信息要求的限制;
评价
提出一个基于GAN的vocoder,是一篇改进模型和loss的论文,主要特点我觉得是用了multi-scale判别器,window-based objective,从音质出发,实验了对模型和目标的哪些改变能改进音质,这里音质不好包括了高频伪影、金属声、噪声,我们训练模型时出现了这些问题,可以从文章提出的解决思路去尝试;