BIGO的端到端语音识别技术
在缺乏成对语音文本数据的任务中,浅层融合对识别率提升有很大的帮助。但一般的融合技术仅会选用一种外部LM,RNNLM (Recurrent Neural Network, RNNLM) 或n-gram LM。由于n-gram LM和RNNLM的固有特性不同,对不同场景的建模能力也不同。为了让模型更好地学习不同场景的上下文信息,BIGO设计two-pass机制汲取RNNLM及n-gram LM两者各自优势在不同场景彼此互补。
当有大量训练数据可用时,使用n-gram LM可以获得良好的泛化性能。但统计语言建模的关键问题是,对远程上下文相关性进行建模时往往会伴随数据稀疏问题。为解决此问题,可用基于连续和较低维向量空间中表示较长跨度历史环境的语言建模技术,例如RNNLM。
基于统计信息的语言模型用固定长度上下文,但是递归神经网络不使用有限的上下文。通过使用循环连接,信息可以在这些网络中循环任意长时间。基于递归神经网络的语言模型 (RNNLM) 提供了进一步的概括:代替仅考虑几个先前的单词,具有来自递归连接的输入的神经元被认为代表了短期记忆。这种神经网络方法可以解决稀疏问题,并且与n元语法模型相比,在困惑方面也能很好地概括。但是,这种方法的主要缺点是训练和测试时间很长。这个实际问题限制了RNNLM的数据量和可能的应用区域数量。
由于n-gram LM和RNNLM的固有特性不同的, BIGO设计two-pass机制汲取两者各自优势在不同场景可彼此互补。==在第一遍解码中,解码器仅使用通用模型来生成多个识别假设,从中提取n-best列表==。在第二遍解码中,使用特定领域的LM(例如==高阶n-gram LM或RNNLM==)==对n-最佳列表的假设进行重新评分==,然后获得最佳新假设。使用 n-gram 作为 E2E ASR 重打分。n-gram 作为一个统计模型,其最大的好处是,权重作为显式的表征,可以方便的做灵活的微调以适应各个不同的场景,以及实现不同用户的个性化识别结果。
集束搜索算法的每个解码步上,Attention-Decoder 和 CTC 根据编码结果h和之前的解码结果y<给出当前解码步的语言学单位的后验概率,而RNNLM也根据之前的解码结果 给出当前解码步的语言学单位的后验概率,而后这两者的结果根据浅层融合架构结合。其过程表示为:
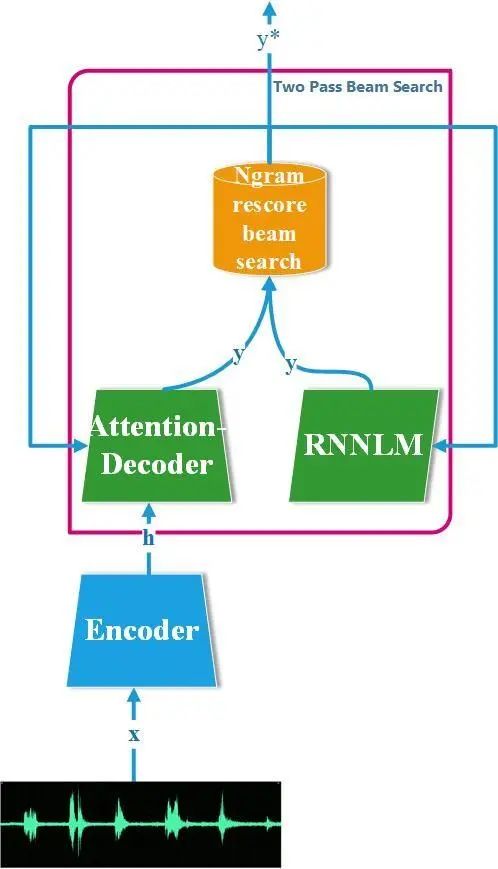

在 CTC-ATT 实现的基础之上,==得到的的 shallow fusion 的 N-best 结果送入 n-gram 做 context bias re-score==,然后得到 1-best,故式3可以重写为:

这个其中需要特别指出的是,CTC和传统的HMM系统其实都是时间对齐的模型,也就是说输出的语言学序列标签长度是正比于特征序列长度的。但是attention-decoder 和 RNNLM 输出确是标签对齐的模型,输出的语言学序列的期望长度确是等于语言学序列长度的。故这两个联合模型需要统一CTC这个时间对齐的输出到标签对齐。这个算法在 [3] 给出过完整的解释,如何将CTC给出的标签分类,然后前向结合变成标签对齐的。