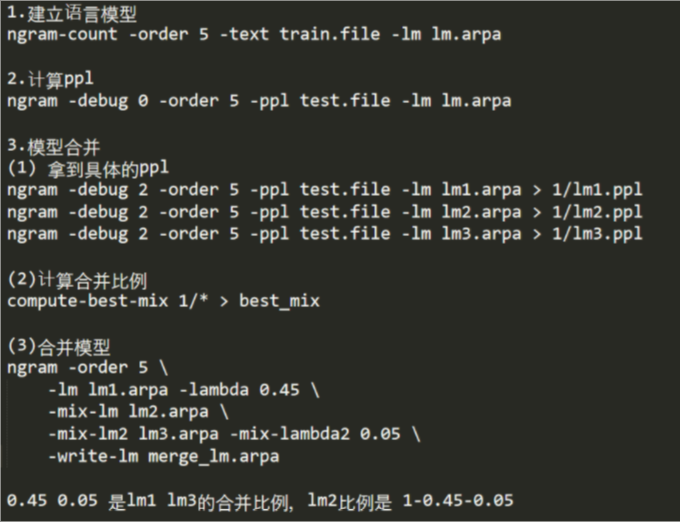
Ngram LM
- 训练一个ngram LM:数据:train set(2715万条,带英文的212万条)
1 | local/train_lms_1gram.sh ngram_test/lang_char.txt.bpe_500_eng1000_chi5200_all6200 ngram_test/text_token_bpe500 ngram_test/lm |
计算句子ppl:
- 先把10best的脚本,spm.decode恢复(注意这里不把▁替换回来),然后过一遍bpe.model进行encode,得到encode后的文本(ngram_test/test/text)
- 计算1.4w条测试集总体的PPL:
file ngram_test/test/text: 14504 sentences, 587117 words, 0 OOVs
0 zeroprobs, logprob= -1166876 ppl= 87.00666 ppl1= 97.15536
1 | ngram -debug 2 -lm ngram_test/lm/srilm/srilm.o3g.kn.gz -ppl ngram_test/test/text > ngram_test/test/ppl |
ngram计算ppl说明:
1 | ngram |
计算10best的每句话的ppl:
首先把10best 带 bpe 的句子英文以空格区分开【也可以不用下面这个操作!,直接用 tools/text2token.py -s 1 -n 1 -m data/lang_char/train_unigram500.model exp/seewo/conformer/test_xueyuan1/text_bpe --trans_type cn_char_en_bpe 就行【甚至更好】!】:
(不是bpe格式的加空格方法:tools/text2token.py -s 0 -n 1 text --trans_type phn > ...)
add_space.py
1 | import sentencepiece as spm |
然后计算逐句ppl,存到文件中
逐句的PPL:在python脚本里调用:暂时不会
计算wer
1 | python compute_wer_lm.py --char=1 --v=1 data/xueyuan/wav/text exp/seewo/conformer/test_xueyuan1/ppl_ngram > exp/seewo/conformer/test_xueyuan1/wer_am_lm_alpha_14 |
结果最好为: wer_am_lm_alpha_0.1:
1 | Overall -> 4.15 % N=57114 C=55071 S=1576 D=467 I=326 |
用5gram:
1 | local/train_lms_1gram.sh ngram_test/lang_char.txt.bpe_500_eng1000_chi5200_all6200 ngram_test/text_token_bpe500 ngram_test/lm_5gram |
结果
- am_logprob + lm_logprob: wer_am_lm_alpha_0.3
1 | Overall -> 4.18 % N=57114 C=55005 S=1557 D=552 I=276 |
比3gram还差,应该是数据更稀疏?但是ppl又有一丢丢提升,说明不是数据稀疏,而是就该用lm的ppl,不该用logprob?
- am_logprob + lm_ppl: wer_am_lm_alpha_0.06
1 | Overall -> 4.13 % N=57114 C=55078 S=1578 D=458 I=324 |
增加数据:
用7G test set(1302万条,带英文的437万条):
1 | tools/text2token.py -s 1 -n 1 -m data_4000_add_we/lang_char/train_unigram500.model data_4000_add_we_bpe/test/text --trans_type cn_char_en_bpe > data_4000_add_we_bpe/test/text_token_bpe500 |
总数据就有4018万条,带英文的650万条
分别尝试字典:
- 英文bpe500,对应1000个分词,中文5200(对应 ngram_test/lang_char.txt.bpe_500_eng1000_chi5200_all6200 )
1 | local/train_lms_1gram.sh ngram_test/lang_char.txt.bpe_500_eng1000_chi5200_all6200 ngram_7g_train/text_token_bpe500 ngram_7g_train/lm |
结果:
1 |
|
- 英文bpe500,对应1000个分词,中文用4018万条去重的所有的(对应ngram_7g_train/lexicon_bpe500)
1 | local/train_lms_1gram.sh ngram_7g_train/lexicon_bpe500 ngram_7g_train/text_token_bpe500 ngram_7g_train/lm_all_cn/ |
结果:
1 | wer_am_lm_alpha_0.13 |
==7G数据有用==
可能更多的中文词,对于该测试集刚好是相同的,所以第二个实验和第一个实验结果相同;
ngram LM 的英文用word建模,不用bpe了,中文用字
直接用:/home/yelong/data/wenet/examples/multi_cn/s0/data_4000_add_we/test_7g/text 通过add_space 得到中文字、英文词,空格区分,见 test_7g/text_space
加上上面的训练集
lexicon就用所有的中文字/英文词作为lexicon:
1 | echo "<UNK> 0" >> lexicon_cn_char_en_char |
英文有点太多,都2.6万个词了?其实也还好,中文才8千个字
生成ngram LM:
1 | local/train_lms_1gram.sh ngram_test/lexicon_cn_char_en_char ngram_test/text_space ngram_test/lm_cn_char_en_char_3gram |
计算1.4w条的ppl:
1 | ngram -debug 2 -lm ngram_test/lm_cn_char_en_char_3gram/srilm/srilm.o3g.kn.gz -ppl ngram_test/test/text_space > ngram_test/test/ppl_space |
计算wer:
1 | python compute_wer_lm.py --char=1 --v=1 data/xueyuan/wav/text exp/seewo/conformer/test_xueyuan1/ppl_3gram_space > exp/seewo/conformer/test_xueyuan1/wer_am_lm_alpha_0.01 |
一般般 WER:4.17%
不太行,肯定要稀疏了?,不然英文用大的bpe(上面用的500,dict是1000),比如1000个建模好了?(实际dict 1500)
训练 3gram LM
ngram LM 的英文用word建模,不用bpe了,中文用词 ,解码nbest先jieba分词,再用ngram计算ppl
离了大谱了,中文有70万个词?,不然先用其他的lexicon:花哥说:先用DaCidian,英文也用公开的词典
Dacidian有50万个词,也很多
- 只用训练集,先用自有词典(76万个词),生成ngram LM:
1 | local/train_lms_1gram.sh ngram_train_word/lexicon_word ngram_train_word/text ngram_train_word/lm |
- 测试集直接jieba分词:
- 直接测试:结果不好,计算ppl时分词了太多OOV了,最好jieba还是给定词典再分词比较好【不好,还是很多OOV】
- 把测试集OOV添加进words.txt中:然后需要重新训练LM!不能不训练,不然LM没变化;
- 测试集分词,遇到words.txt没有的词,再次分词(脚本word_segment_again.py):
- 直接拆成字:结果:结果不好
- 最大匹配算法,再次拆成词:结果:TODO
1 | python word_segment_again.py > ngram_train_word/text_10best_word_again |
word_segment_again.py
1 | import jieba |
word_segment_again.old.py:【错!不要分!就要保留oov,这样错误的词概率才低!!】
[2022.7.25]别用jieba了!用lac
1 | import jieba |
- 用训练集+7G数据:10.22.24.2:multi_cn/s0/data_4000_add_we/test_7g_train/text;或 24.4:librispeech1/s5/ngram_7g_train_word
给定词典:
词典:lm_seewo/words.txt
需要重新对文本做一个分词,不然太多oov了
local/train_lms_1gram.sh lm_seewo/words.txt ngram_7g_train_word/text ngram_7g_train_word/lm_seewo python word_segment_again.py > ngram_7g_train_word/text_10best_word_seewo ngram -debug 2 -lm ngram_7g_train_word/lm/srilm/srilm.o3g.kn.gz -ppl ngram_7g_train_word/text_10best_word_seewo > ngram_7g_train_word/lm_seewo/ppl_value1
2
3
4
5
6
7
8
9
10
11
12
13
-
- 去重的词典 (暂时先用train去重的词典ngram_train_word/lexicon_word)
- ```shell
local/train_lms_1gram.sh ngram_train_word/lexicon_word ngram_7g_train_word/text ngram_7g_train_word/lm_train
python word_segment_again.py > ngram_7g_train_word/text_10best_word_train
ngram -debug 2 -lm ngram_7g_train_word/lm_train/srilm/srilm.o3g.kn.gz -ppl ngram_7g_train_word/text_10best_word_train > ngram_7g_train_word/lm_train/ppl_value
python compute_wer_lm.py --char=1 --v=1 data/xueyuan/wav/text exp/seewo/conformer/test_xueyuan1/ppl_lm_7g_train_word > exp/seewo/conformer/test_xueyuan1/wer_am_lm_alpha_0.01结果:
1
2
3
4
5
6wer_am_lm_alpha_0.005
Overall -> 4.13 % N=57162 C=55106 S=1575 D=481 I=303
Mandarin -> 3.79 % N=56894 C=55038 S=1491 D=365 I=300
English -> 75.56 % N=266 C=68 S=84 D=114 I=3
Other -> 100.00 % N=2 C=0 S=0 D=2 I=0
提升4.6%测试文本分词重新做一次,测试文本不word_segment_again到最小单元,只是进行分词,如果分到的词,词典里没有,不管!不要强行拆分!!oov概率低,这句话ppl大!符合我们想要的!!
python word_segment.py > ngram_train_word/text_10best_word_train ngram -debug 2 -lm ngram_7g_train_word/lm_train/srilm/srilm.o3g.kn.gz -ppl ngram_train_word/text_10best_word_train > ngram_7g_train_word/lm_train/ppl_value_oov python compute_wer_lm.py --char=1 --v=1 data/xueyuan/wav/text exp/seewo/conformer/test_xueyuan1/ppl_7g_train_word_oov > exp/seewo/conformer/test_xueyuan1/wer_am_lm_alpha_0.011
2
3
4
5
6
7
8
9
10
11
12
- 修改 ngram_7g_train_word/lm_train/srilm/srilm.o3g.kn.gz,因为oov的logprob为-inf,都没有累计到!因此把这个oov变成随便一个概率很低的word!
注意,jieba分词时不要给词典会好一点(不要jieba.set_dictionary('ngram_train_word/lexicon_word'))不然会出现“ 如果 想收 集 画板”这种分词分得很不好的情况
用概率,不用ppl
- ```shell
# 注意,jieba分词时不要给词典会好一点(不要jieba.set_dictionary('ngram_train_word/lexicon_word'))不然会出现“ 如果 想收 集 画板”这种分词分得很不好的情况
ngram -debug 2 -map-unk ABELL -lm ngram_7g_train_word/lm_train/srilm/srilm.o3g.kn.gz -ppl ngram_7g_train_word/text_10best_word_train > ngram_7g_train_word/lm_train/ppl_value_oov_unk
python compute_wer_lm.py --char=1 --v=1 data/xueyuan/wav/text exp/seewo/conformer/test_xueyuan1/ppl_7g_train_word_oov_unk > exp/seewo/conformer/test_xueyuan1/wer_am_lm_alpha_0.01结果:
```shell
wer_am_lm_alpha_0.6
Overall -> 4.08 % N=57162 C=55066 S=1489 D=607 I=236
Mandarin -> 3.74 % N=56894 C=54999 S=1416 D=479 I=233
English -> 75.94 % N=266 C=67 S=73 D=126 I=3
Other -> 100.00 % N=2 C=0 S=0 D=2 I=01
2
3
4
5
6
7
8
9
-
**他们的words.txt,他们的TLG里的G是词,有59万个词(9万个英文,50万字中文词)** 路径:24.2:/home/yelong/data/wenet/examples/aishell/s0/lm_seewo
按他们的words.txt对7G+train set进行分词:
```shell
python word_segment_again.py > /home/yelong/data/wenet/examples/multi_cn/s0/data_4000_add_we/train/split_word_by_seewo_words/2
最好不要有OOV,把测试集的没在词典里的都添加进词典里?
琳姐训练的ngram LM,测试
路径:10.22.24.4:/home/data/data_to_yelong/lm_from_wanglin//bigfat_30w10wlwwCE_merge_20190709_7e-10.lm;词典,英文8千个词,中文12万个词,5gram
1 | python word_segment_again.py > ngram_lin/text_10best_word_lin |
结果:
1 | wer_am_lm_alpha_0.005 |
ngram LM 的中文英文都用bpe分词 ,解码nbest先jieba分词,再bpe分词,再用ngram计算ppl
预感效果介于字和词之间,不想做了。
ngram LM 的英文用bpe1000建模,中文用词 ,解码nbest先jieba分词,再用ngram计算ppl
ngram LM 的英文用bpe1000建模,中文用词 ,解码nbest先jieba分词,再用ngram计算ppl
最好的CTC rescore后,attention再rescore
1 | attention score + ctc*0.5 + \lambda PPL |
结果:
1 | wer_am_lm_alpha_0.13 |
词建模的ngram的TLG 进行解码,限制,然后再 NN LM rescore
TODO
词建模的ngram的TLG 进行解码,限制,然后再 ngram LM rescore
10.22.23.17 docker
1 | ./tools/decode.sh --nj 1 --beam 10.0 --lattice_beam 7.5 --max_active 7000 --blank_skip_thresh 0.98 --ctc_weight 0.5 --rescoring_weight 1.0 --chunk_size -1 --fst_path /home/data/yelong/docker_seewo/seewo/lm_seewo/TLG.fst /home/data/yelong/docker_seewo/corpus/seewo/wav.scp /home/data/yelong/docker_seewo/corpus/seewo/text /home/data/yelong/docker_seewo/seewo/final.zip /home/data/yelong/docker_seewo/seewo/lm_seewo/words.txt exp/seewo/conformer/lm_with_runtime |
词建模ngram、字建模ngram,连同声学模型分数,三者加权求和,作为最后的分数
旺旺教的