预训练语言模型
开源预训练语言模型合集
github:https://github.com/ZhuiyiTechnology/pretrained-models
[好] github:https://github.com/lonePatient/awesome-pretrained-chinese-nlp-models
github:https://github.com/ymcui/Chinese-BERT-wwm
https://huggingface.co/docs/transformers/index
github:OpenCLaP:多领域开源中文预训练语言模型仓库
github:https://github.com/BrikerMan/Kashgari
github:https://github.com/fighting41love/funNLP
github:https://github.com/ymcui/Chinese-XLNet https://cloud.tencent.com/developer/article/1865707
github:好未来:https://github.com/tal-tech/edu-bert
https://www.oschina.net/p/chinese-bert
https://lonepatient.top/archives/
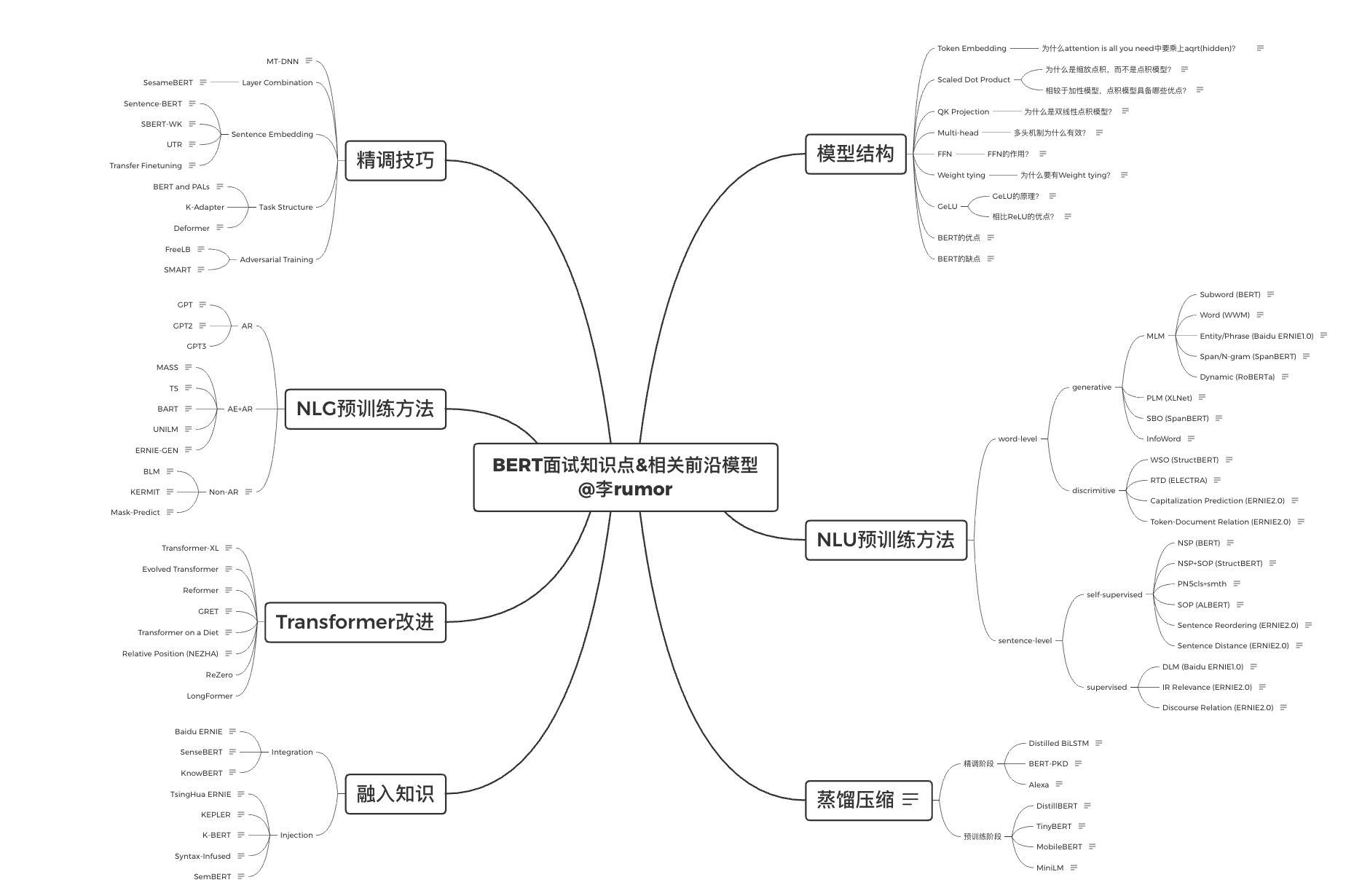
预训练语言模型
知乎:nlp中的预训练语言模型总结(单向模型、BERT系列模型、XLNet) 、 NLP算法面试必备!PTMs:NLP预训练模型的全面总结
预训练语言模型解释:
预训练语言模型已经形成了一种新的 NLP 范式: 使用大规模文本语料库进行预训练,对特定任务的小数据集微调,降低单个 NLP 任务的难度。
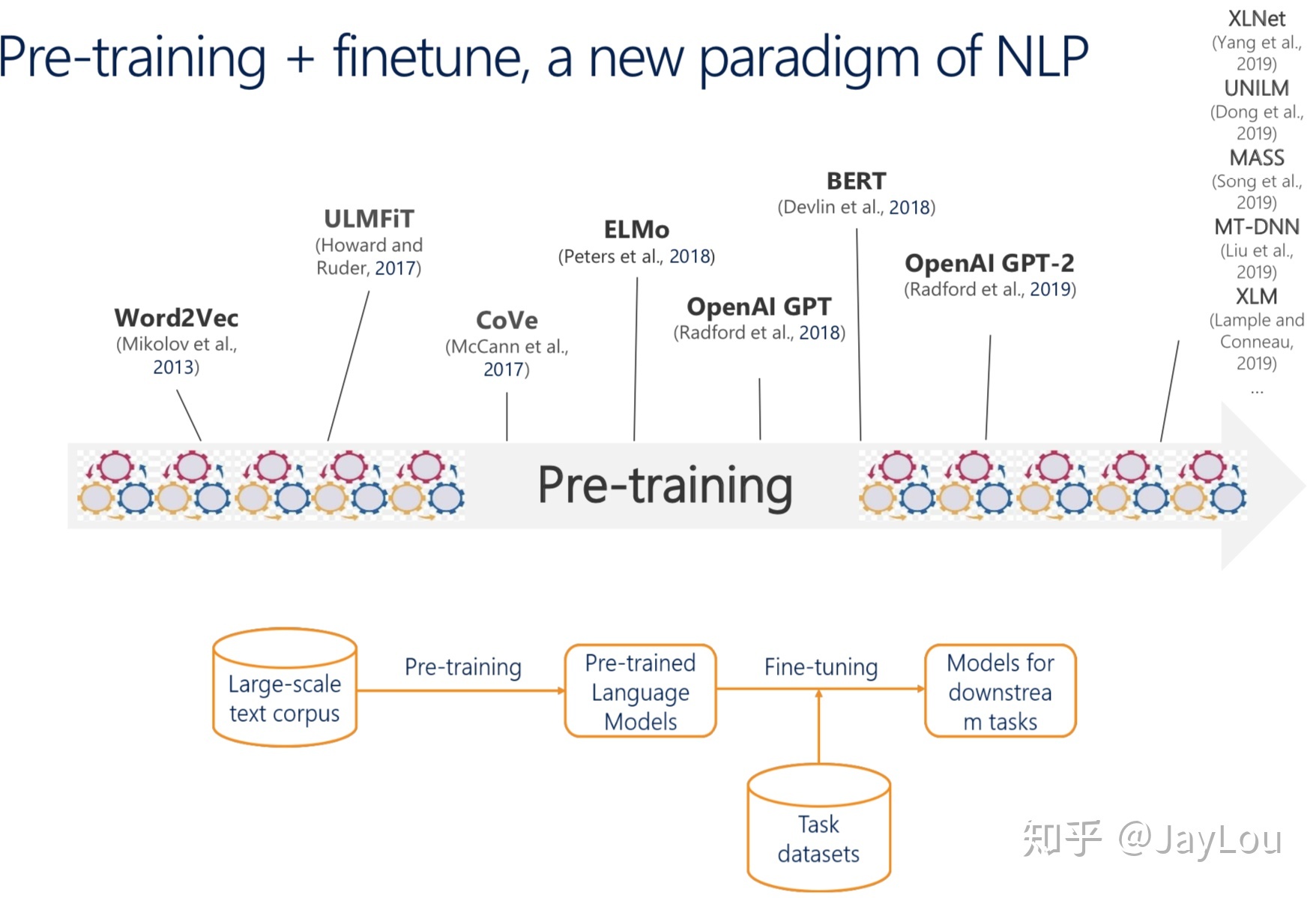
预训练思想的本质是模型参数不再是随机初始化,而是通过一些任务(如语言模型)进行预训练;预训练属于迁移学习的范畴,本文的【预训练语言模型】主要指无监督预训练任务(有时也称自学习或自监督),迁移的范式主要为特征集成和模型精调(finetune)。
语言模型表示序列文本的联合概率分布,为降低对长文本的概率估算难度,通常使用一个简化的n-gram模型。为缓解n元语言模型概率估计时遇到的数据稀疏问题,提出了神经网络语言模型NNLM,第一层参数可用作词向量表示。词向量可看作是NNLM的一个副产品,而word2vec通过一些优化技巧专注于词向量的产生,后来的glove词向量是通过共现语料矩阵进行高效分解产生的,glove也可看作是更换了目标函数和权重函数的全局word2vec。由于word2vec、glove等静态词向量未考虑一词多义、无法理解复杂语境,可通过预训练语言模型产生上下文相关的特征表示(动态词向量)。
(注:本文没有把word2vec纳入预训练语言模型的范畴,虽然word2vec可看作语言模型,但其更专注于词向量的产生。本文的预训练语言模型主要指能够产生上下文相关的特征表示)
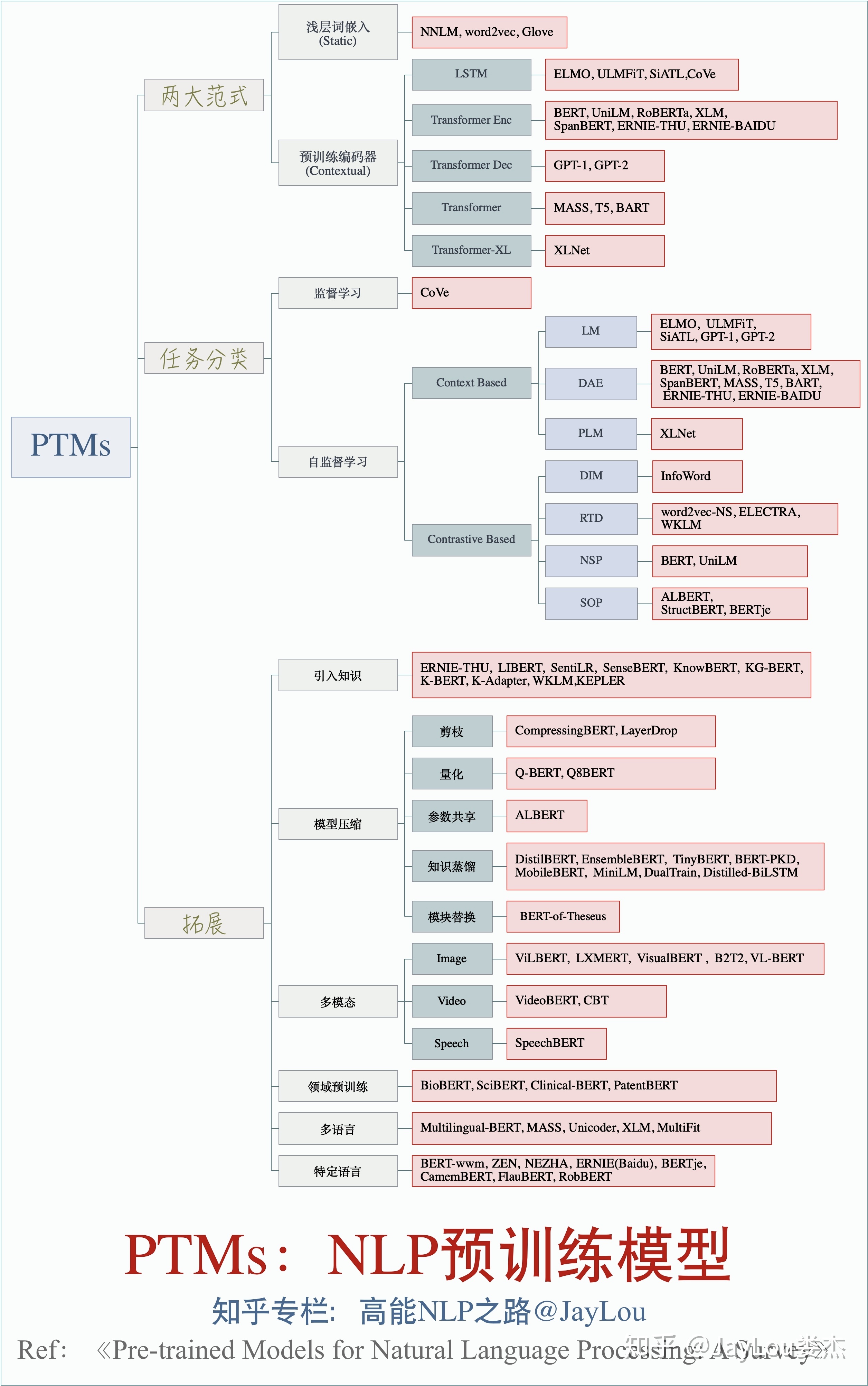
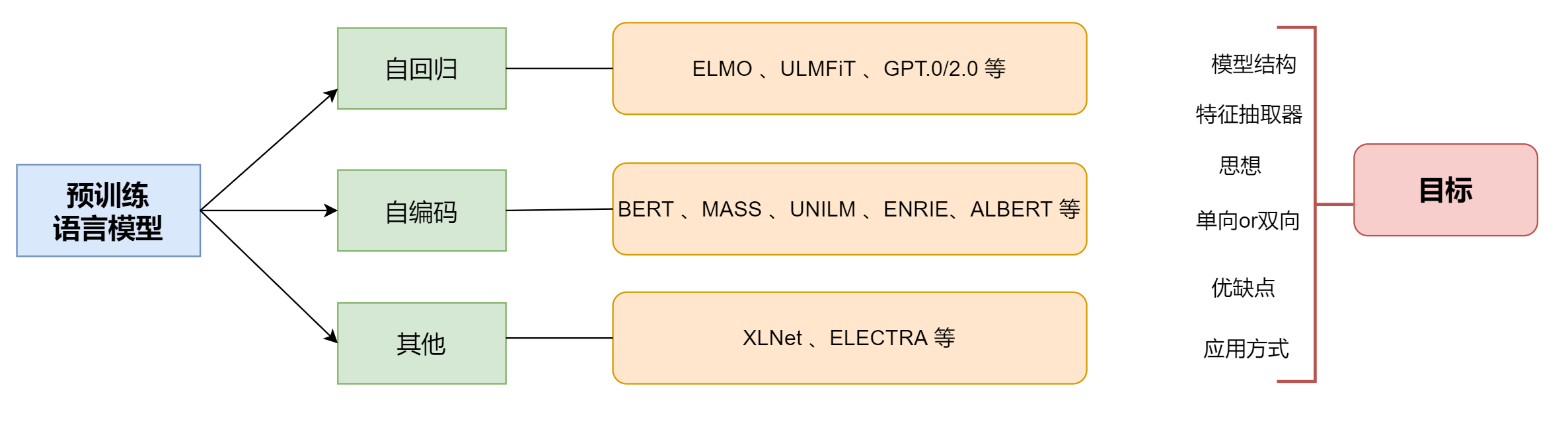
预训练模型分类
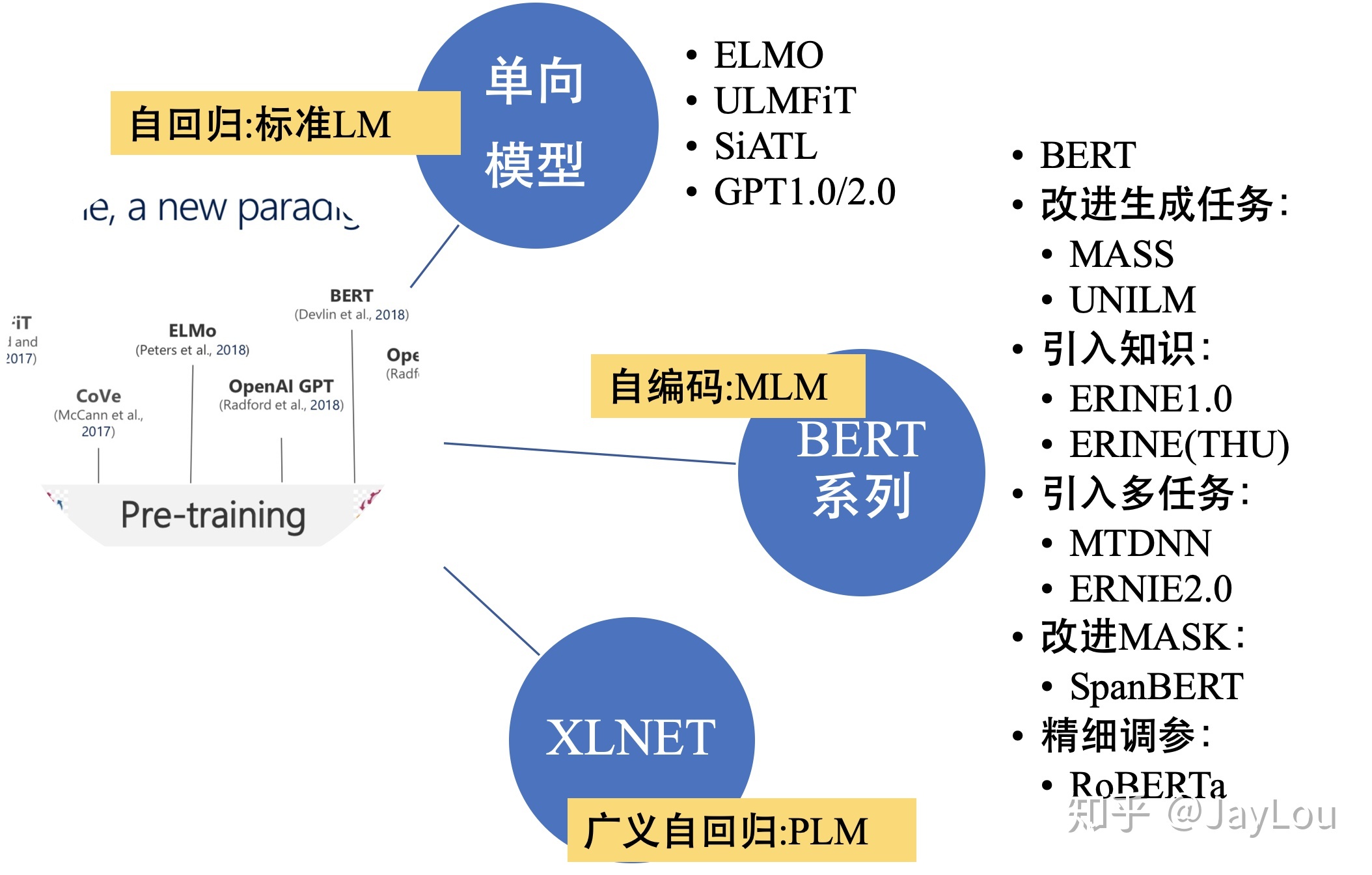
单向特征表示的自回归预训练语言模型,统称为单向模型:
- ELMO/ULMFiT/SiATL/GPT1.0/GPT2.0;
双向特征表示的自编码预训练语言模型,统称为BERT系列模型:
- (BERT/MASS/UNILM/ERNIE1.0/ERNIE(THU)/MTDNN/ERNIE2.0/SpanBERT/RoBERTa)
双向特征表示的自回归预训练语言模型:XLNet;
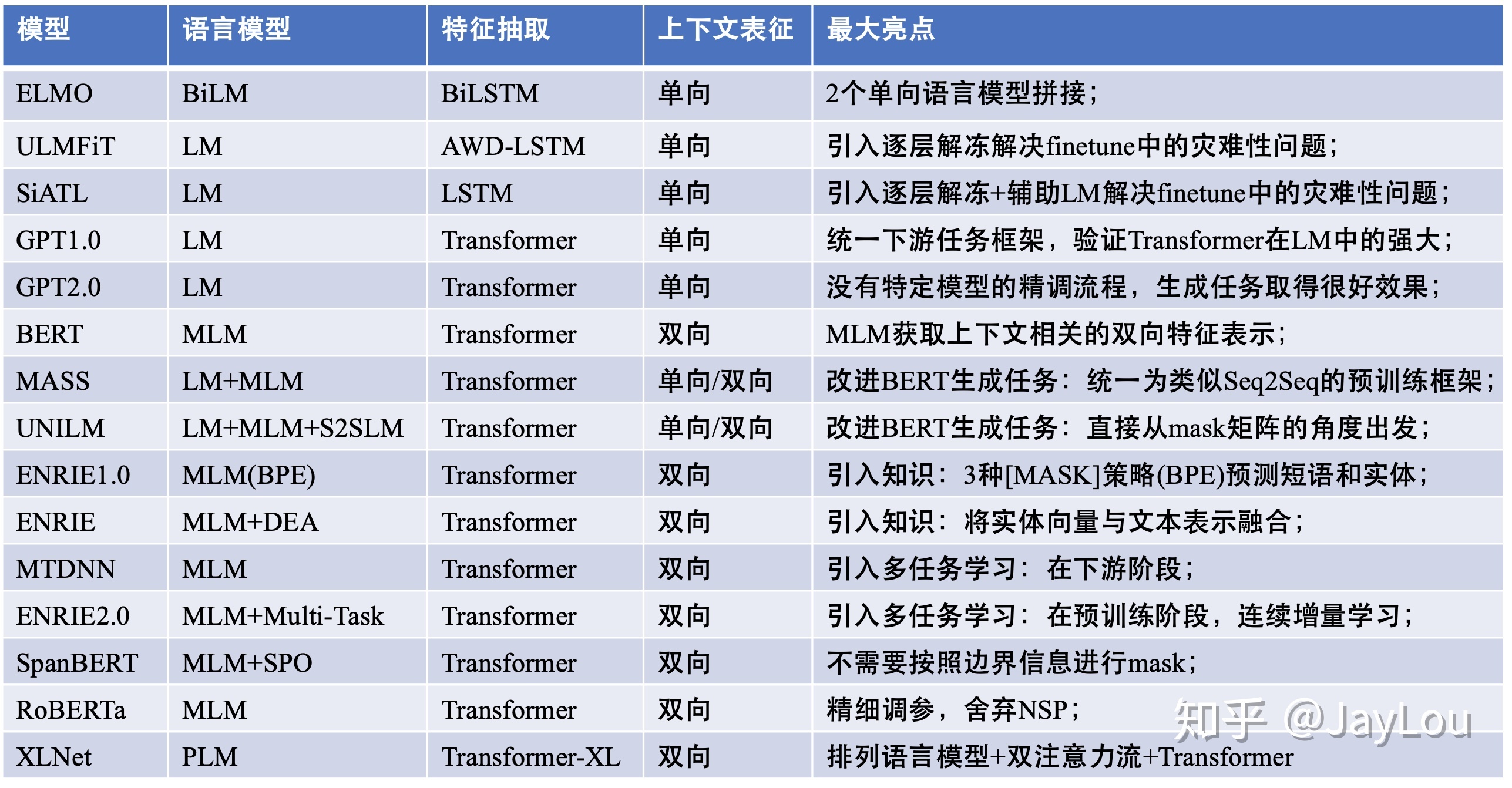
不同的特征抽取机制
- RNNs:ELMO/ULMFiT/SiATL;
- Transformer:GPT1.0/GPT2.0/BERT系列模型;
- Transformer-XL:XLNet;
不同的预训练语言目标
- 自编码(AutoEncode):BERT系列模型;
- 自回归(AutoRegression):单向模型(ELMO/ULMFiT/SiATL/GPT1.0/GPT2.0)和XLNet;
BERT系列模型的改进
- 引入常识:ERNIE1.0/ERNIE(THU)/ERNIE2.0(简称为“ERNIE系列”);
- 引入多任务学习:MTDNN/ERNIE2.0;
- 基于生成任务的改进:MASS/UNILM;
- 不同的mask策略:WWM/ERNIE系列/SpanBERT;
- 精细调参:RoBERTa;
特征表示(是否能表示上下文):
- 单向特征表示:单向模型(ELMO/ULMFiT/SiATL/GPT1.0/GPT2.0);
- 双向特征表示:BERT系列模型+XLNet;
二、预训练语言模型的基础:特征抽取机制+语言模型的分类
Q2:基于深度学习的NLP特征抽取机制有哪些?各有哪些优缺点?
1)能否处理长距离依赖问题
长距离依赖建模能力: Transformer-XL > Transformer > RNNs > CNNs
- MLP:不考虑序列(位置)信息,不能处理变长序列,如NNLM和word2vec;
- CNNs:考虑序列(位置)信息,不能处理长距离依赖,聚焦于n-gram提取,pooling操作会导致序列(位置)信息丢失;
- RNNs:天然适合处理序列(位置)信息,但仍不能处理长距离依赖(由于BPTT导致的梯度消失等问题),故又称之为“较长的短期记忆单元(LSTM)”;
- Transformer/Transformer-XL:self-attention解决长距离依赖,无位置偏差;
2)前馈/循环网络 or 串行/并行计算
- MLP/CNNs/Transformer:前馈/并行
- RNNs/ Transformer-XL:循环/串行:
3)计算时间复杂度(序列长度n,embedding size为d,filter大小k)
- CNNs:$O(k\cdot n\cdot d^2)$
- RNNs:$O(n\cdot d^2)$
- Self Attention:$O(n^2\cdot d)$
Q3:自回归和自编码语言模型各有什么优缺点?
1.自回归语言模型
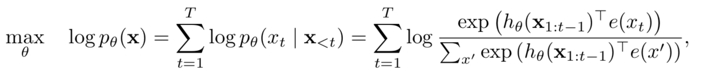
优点:
- 文本序列联合概率的密度估计,即为传统的语言模型,天然适合处理自然生成任务;
缺点:
- 联合概率按照文本序列从左至右分解(顺序拆解),无法通过上下文信息进行双向特征表征;
代表模型:ELMO/GPT1.0/GPT2.0;
改进:XLNet将传统的自回归语言模型进行推广,将顺序拆解变为随机拆解(排列语言模型),产生上下文相关的双向特征表示;
2.自编码语言模型
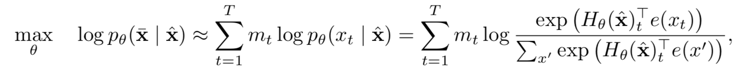
优点:本质为降噪自编码特征表示,通过引入噪声[MASK]构建MLM,获取上下文相关的双向特征表示;
引入独立性假设,为联合概率的有偏估计,没有考虑预测[MASK]之间的相关性
- 不适合直接处理生成任务,MLM预训练目标的设置造成预训练过程和生成过程不一致;
- 预训练时的[MASK]噪声在finetune阶段不会出现,造成两阶段不匹配问题;
代表模型:BERT系列模型;