语言模型 自编码
==Devlin, Jacob, et al. “Bert: Pre-training of deep bidirectional transformers for language understanding.” arXiv preprint arXiv:1810.04805 (2018).==citations:41870!
code、pre-trained model :github:https://github.com/google-research/bert
背景
- Unsupervised Feature-based Approaches :无标注文本训一个模型,用word embedding给下游任务
- Unsupervised Fine-tuning Approaches :无标注文本训一个模型,加下游任务层,或者只把下游任务的一部分用无标注文本训练
思路
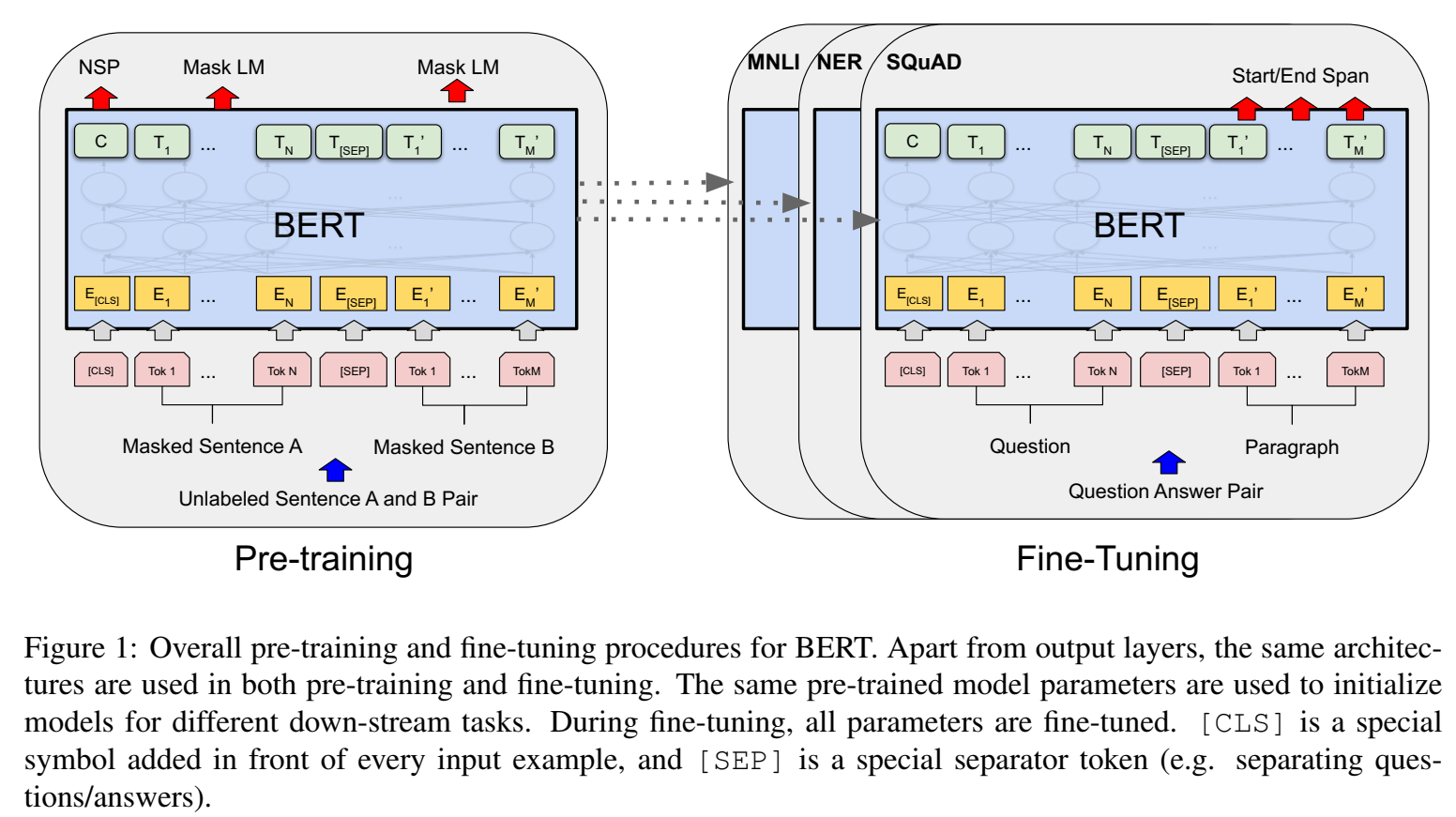
提出新的语言表示模型,称为Bidirectional Encoder Representations from Transformers (BERT),通过联合从左和从后的所有layer的上下文,预训练deep、双向的语言表示,训练文本来自未标注文本;得到预训练语言表示,后接输出层,就可以适合很多下游任务;
BERT是一种基于微调的表示模型,finetuning based representation model ,适合sentence-level 和token-level的下游任务;
ELMo、ULMFiT、GPT称为“单向的”语言模型,因为一般是从左往后单向的,不然就是双向biLSTM,使用独立训练的从左到右和从右到左lm的浅级联,deep bidirectional representations 其实学的并不好,因此叫单向;
BERT的“双向”,体现在用的attention结构,因此能看见上下文;
方法
- masked language model” (MLM) pre-training objective ,masked LM从输入中随机屏蔽一些token,目标是只基于上下文的词,预测屏蔽的原始词汇表id;这种和之前ELMo、ULMFiT、GPT就不太一样,能够很好的学习deep bidirectional representations;
- 目标函数:$\large P(w_i|w_1,…,w_{i-1},w_{i+1},…,w_n)$
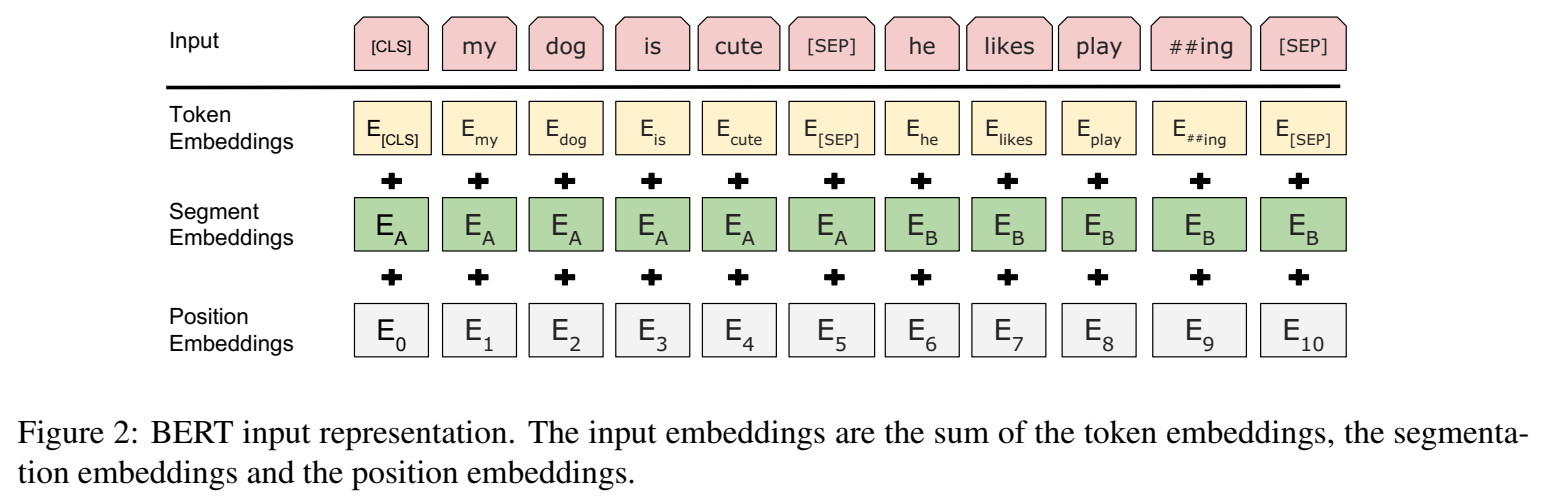
- input由三个特征embedding求和组成,分别是
- token embedding:第一个单词是CLS标志,可以用于之后的分类任务
- position embedding
- segment embedding:代表是不是属于同一段segment的信息特征,用来区别两种句子,因为预训练不光做LM还要做以两个句子为输入的分类任务
“masked LM” (MLM) :随机屏蔽输入token的一部分,然后只预测那些被屏蔽的token;经验:每句话15%masked;
一开始的masked做法:输入15%的单词变成[MASK]这个token,然后目标是**[MASK]token位置对应的输出概率为真实token要交叉熵最大** We only compute loss on masked tokens;
后来的masked做法:输出的15%的单词不是全变成[MASK]这个token,而是80%可能性变成[MASK],10%可能性变成随机token,10%可能性不变;
Next Sentence Prediction (NSP) :训练预训练模型中,给输出又引入说一个任务(多任务?),叫做是不是”下一句话“的判断,输出二分类,判断是不是下一句话?这对于微调任务比如QA和NLI很有用,如果不是这些微调任务,预训练模型训练不需要这个C向量;
Pre-training data :要用document-level corpus ,而不要用sentence-level的corpus,训练LM的文本一定要长,这样才能具备抽取长序列知识的能力;
Fine-tuning BERT :???【TODO】
模型
multi-layer bidirectional Transformer encoder ,transformer decoder (用tensor2tensor库)
词典:wordpiece后的30000个token
==Song, Kaitao, et al. “Mass: Masked sequence to sequence pre-training for language generation.” arXiv preprint arXiv:1905.02450 (2019).==citations:660
背景
- 和bert一样的预训练模型,Pre-training and fine-tuning 方式训练
思路
- 提出 MAsked Sequence to Sequence pre-training (MASS) ,用于基于encoder-decoder的language generation
方法
模型
==Lan, Zhenzhong, et al. “Albert: A lite bert for self-supervised learning of language representations.” arXiv preprint arXiv:1909.11942 (2019).==citations:3054 Google Research
背景
- 虽然预训练模型能改善下游任务性能,但是由于预训练模型较大,也会造成计算量、内存、延时增加,为了解决该预训练模型带来的问题,本文提出两种更小内存消耗的方法,并且能减小训练BERT的速度;
思路
- 提出 A lite bert 轻量级的BERT,自监督学习,语言表示
- 用关注于建模句间相关性的自监督loss,改善了下游任务的输入是多句输入的任务性能;
方法
- SCALING UP REPRESENTATION LEARNING FOR NATURAL LANGUAGE 对于自然语言的scaling up表示学习
- CROSS-LAYER PARAMETER SHARING
- SENTENCE ORDERING OBJECTIVES
DistilBERT
Smaller, faster, cheaper, lighter: Introducing DistilBERT, a distilled version of BERT