语言模型 自回归
==Sarzynska-Wawer, Justyna, et al. “Detecting formal thought disorder by deep contextualized word representations.” Psychiatry Research 304 (2021): 114135.== citations:10182
知乎:Deep contextualized word representations [文献阅读笔记]
https://sh-tsang.medium.com/review-elmo-deep-contextualized-word-representations-8eb1e58cd25c
思路
提出一种新的深度上下文词表示(word embedding),能够建模
- 复杂的语意和语法信息。(比如 句法和语义) ;
- 同样的词在不同的语境中含义差距比较大, 所谓一词多义的情况。
提出 ELMo (Embeddings from Language Models) 表示,它并不是学习上下文词向量的方法,而是学习一个网络(biLM)函数,使用bidirectional LSTM 使用包含上下文的整个句子作为语句进行训练和建模;
其高level隐层节点捕捉上下文相关的词义(可以用在语义消歧任务,直接用这部分特征),低level隐层节点捕捉语法的各个方面进行建模(可以用在词性标记);
我的理解是低level特征更容易捕捉输入的很小范围之间的不同之处,高level特征更容易捕捉上下文,较大范围之间的不同之处(小范围内的不敏感了)
模型特点:(1)深度很深(2)每一层学到的信息可以进行线性组合来适用于不同的下游任务。
效果:下游任务为nlp的六个任务,都是SOTA;
ELMo 中 biLM 不同层输出可根据不同的下游任务进行组合。 比如说对于输入序列中的一个词,使用L层的biLM模型映射后就得到一组2L+1种的映射组合:
$\begin{aligned} R_k &=\left{\mathbf{x}k^{L M}, \overrightarrow{\mathbf{h}}{k, j}^{L M}, \overleftarrow{\mathbf{h}} \frac{L M}{k, j} \mid j=1, \ldots, L\right} \ &=\left{\mathbf{h}_{k, j}^{L M} \mid j=0, \ldots, L\right} \end{aligned}$
表达式为:其中j是不同layer,k是不同token position,s是softmax-normalized weights ,$\gamma$是缩放参数;每层后接layer norm;
$\mathbf{E} \mathbf{L M} \mathbf{o}k^{\text {task }}=E\left(R_k ; \Theta^{\text {task }}\right)=\gamma^{\text {task }} \sum{j=0}^L s_j^{\text {task }} \mathbf{h}_{k, j}^{L M}$
ELMo 的预训练模型结构基本就是一个两层的biLSTM, 每一层包含4096个unit, 每个词会被映射为512维的向量。 特殊的点是在一层和二层之间增加了残差连接。 一旦预训练模型训练好后就可以直接计算词向量用于下游任务,或者进行 fine-tuned用于下游任务。
训练ELMo就也可以当语言模型来训练,拿它的输出来用做语言模型也是可以的;
模型结构
- 双向biLSTM,使用独立训练的从左到右和从右到左lm的浅级联
- 目标函数:分别以$\large P(w_i|w_1,…,w_{i-1})$ 和 $\large P(w_i|w_{i+1},…,w_n)$ 作为目标函数,独立训练两个representation然后拼接
==Howard, Jeremy, and Sebastian Ruder. “Universal language model fine-tuning for text classification.” arXiv preprint arXiv:1801.06146 (2018).== citations:2702
开源预训练模型和代码:http://nlp.fast.ai/ulmfit
思路
提出一种通用的语言模型,微调语言模型来适应下游任务,称为 Universal Language Model Fine-tuning (ULMFiT) ,一种有效的迁移学习方法;
提出保留以前的知识,避免在微调时遗忘原本知识的方法:称为 区分式微调、斜的三角学习率、逐渐冻结。。?discriminative fine-tuning,slanted triangular learning rates, and gradual unfreezing
相关工作:
- CV领域里的迁移学习:近几年finetune的一种方法是微调预训练模型的最后一/几层,前面层参数不变,来达到下游任务目的;
- NLP领域里的迁移学习:预训练模型通过其他任务捕获额外上下文的embedding。然后,不同层次的embedding被用作特征,与单词embedding或中间层的输入连接,来达到下游任务目的;该方法称为 hypercolumns
- Multi-task learning :语言模型作为目标函数之一,和主任务一起联合训练,多任务学习 ;但是MTL每次都要求从头开始训练任务,这使得它效率低下,并且经常需要仔细权衡任务特定的目标函数;
- Fine-tuning :在语言模型上进行微调,但是如果微调训练数据少,容易过拟合,数据量大,又不容易有那么多数据;
ULMFiT:分为三个步骤:
- 预训练通用领域的LM;
- target task LM fine-tuning;(该步骤运用的trick:Discriminative fine-tuning、Slanted triangular learning rates)
- target task下游任务fine-tuning;只更新后接层的参数,前面层参数冻结;(该步骤运用的trick:Discriminative fine-tuning、Slanted triangular learning rates、gradual unfreezing)
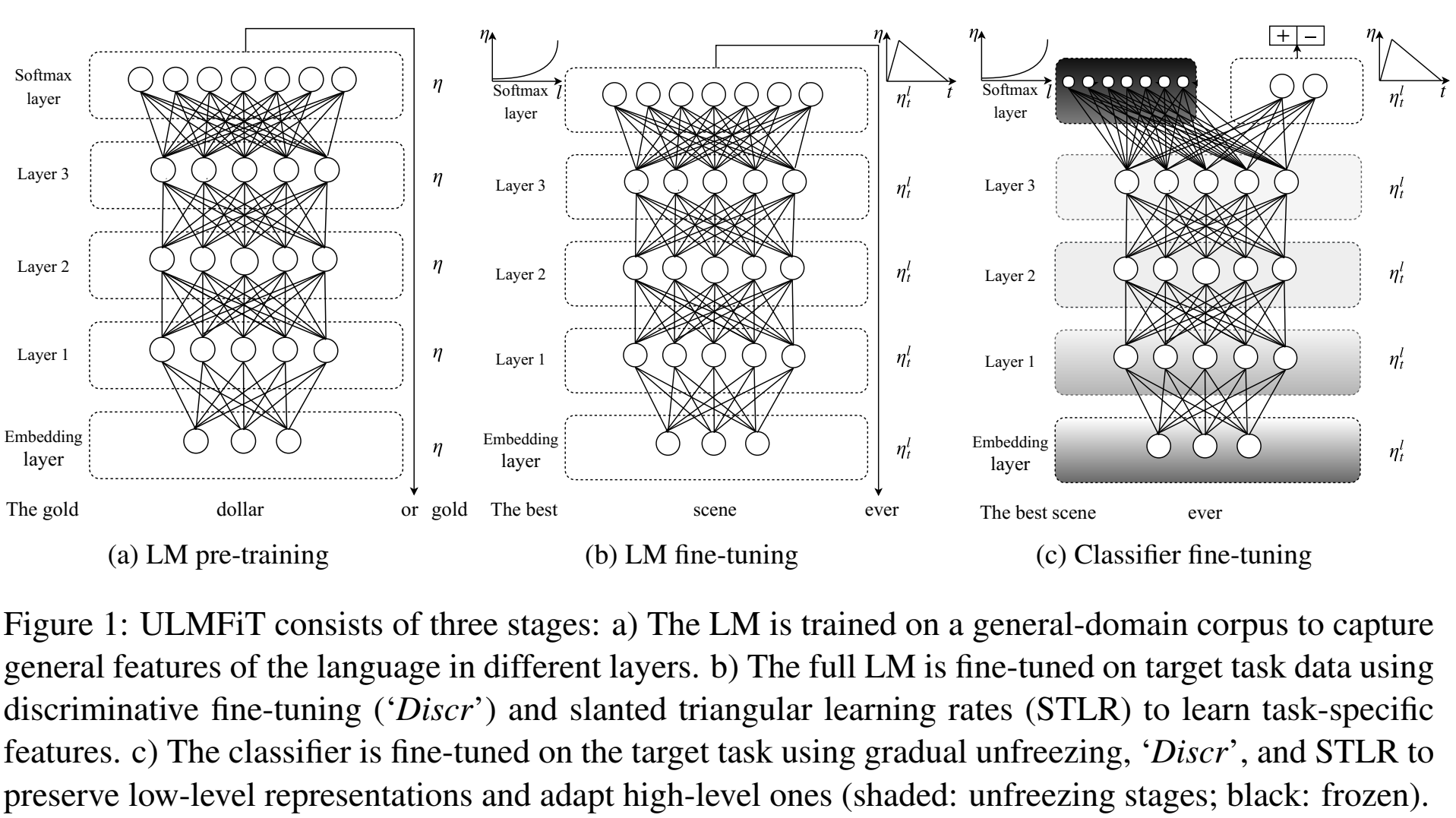
文章提出了一些finetune种的训练方法(trick):
Discriminative fine-tuning:(不是鉴别性训练),因为不同层提取的特征不同,所以给不同层不同的学习率是比较合适的;经验:finetune时最后一层学习率$\gamma$,其他层学习率$\gamma/2.6$,(其他层学习率小一点,最后一层学习率大一点);
Slanted triangular learning rates :因为希望模型尽快收敛,所以修改不同迭代数时的学习率,先增后减;(这个和我之前的想法一样啊,我也觉得finetune需要先增加学习率,训练得比较好,再减小学习率)
学习率的表示为:T为迭代数,经验:cut_frac = 0.1, ratio = 32 ,ηmax = 0.01;
和 aggressive cosine annealing 的学习率策略 有点像
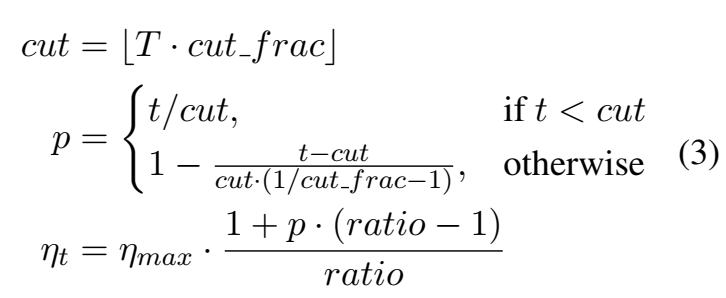
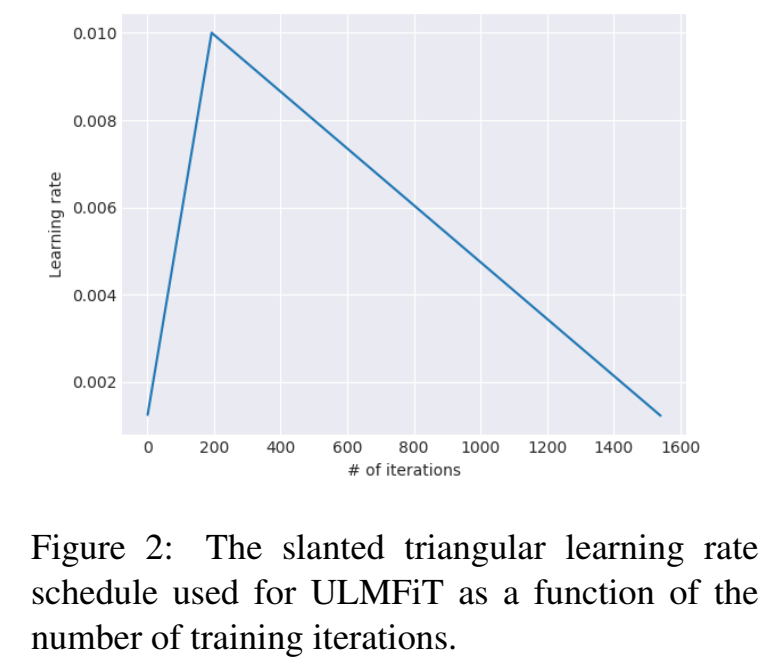
Gradual unfreezing :应用于下游任务,因为怕遗忘之前LM的能力,因此从最后一层开始更新模型参数,逐渐往前面层更新,这是基于最后一层学到的知识最少的假设;逐渐解冻;这类似于chain-thaw (Felbo et al., 2017)
BPTT for Text Classification (BPT3C) :为了在large documents上进行模型精调,作者将文档分为固定长度为b的batches,并在每个batch训练时记录mean和max池化,梯度会被反向传播到对最终预测有贡献的batches。(Merity et al., 2017a);【??】
本文的下游任务是文本分类任务,因此第三步是在第二步的LM后接一个分类linear层,因为输入给线性层是多个词,因此取最后一个输出特征,和maxpooling和meanpooling的输出特征,concat作为总的特征,再接一个linear输出:
$\mathbf{h}_c=\left[\mathbf{h}_T, \operatorname{maxpool}(\mathbf{H})\right., \operatorname{meanpool} \left.(\mathbf{H})\right]$
实验
- 用预训练语言模型AWD-LSTM (Merity et al.,2017a)
优缺点
优点:
对比其他迁移学习方法(ELMo)更适合以下任务:
非英语语言,有标签训练数据很少
没有state-of-the-art模型的新NLP任务
只有部分有标签数据的任务
缺点:
- 对于分类和序列标注任务比较容易迁移,对于复杂任务(问答等)需要新的精调方法。
- 模型用的LSTM,对于长距离的输入捕捉不好;
==Radford, Alec, et al. “Improving language understanding by generative pre-training.” (2018).==citations:3533 OpenAI
背景
- 无标注数据多,过去研究发现即使在有相当多的监督可用的情况下,以无监督的方式学习良好的表示也可以提供显著的性能提升(代表研究:词向量)。
- 利用无标注文本有两个挑战:
- 目前还不清楚哪种优化目标,在学习对迁移有用的文本表示时,最有效;可能是语言模型,也可能是机器翻译等等(来自https://gluebenchmark.com/leaderboard )
- 对于如何最有效地将这些学习到的表征迁移到目标任务上,目前还没有达成共识。(现有的方案有:对模型进行target任务的更改;使用复杂的学习方案;添加辅助学习目标)
思路
- 提出Generative Pre-Training (GPT),通过对不同corpus上的无标注文本训练生成式预训练语言模型,该语言模型能提高下游任务模型能力;
- 微调中使用task-aware input transformations ,实现对模型最小的改动下,得到最佳的迁移效果;
- 探索了一种半监督语言理解任务的方法,使用无监督的预训练和有监督的微调相结合。
- 目标是学习一种通用的表示法,这种表示法几乎不需要适应广泛的任务,就能迁移?
- target task的corpus和预训练的unlabeled的corpus不在一个领域,也可以,比如英文的预训练模型,中文的LM任务;
- Semi-supervised learning for NLP NLP中的半监督学习 :一般是用无标注文本学习word embedding;词级别
- Unsupervised pre-training :其目标是找到一个好的初始化点,而不是修改监督学习目标,作为后续任务的初始模型;预训练作用类似正则化,使模型有更好的泛化性;
- Auxiliary training objectives :添加辅助无监督训练目标是半监督学习的另一种形式;
框架方法
- 采用了两个步骤:1. 用无标注文本训练一个预训练LM(Unsupervised pre-training );2. 用有监督数据将预训练模型迁移到下游任务中(Supervised fine-tuning);
- 迁移过程,用task-specific input adaptations derived from traversal-style approaches ??
- Unsupervised pre-training :语言模型loss function为路径概率,为在前k个token发生时当前token发生的概率的乘积;

- Supervised fine-tuning :

将语言建模作为微调的辅助目标有助于(a)改进监督模型的泛化,(b)加快收敛速度。
模型结构
- transformer
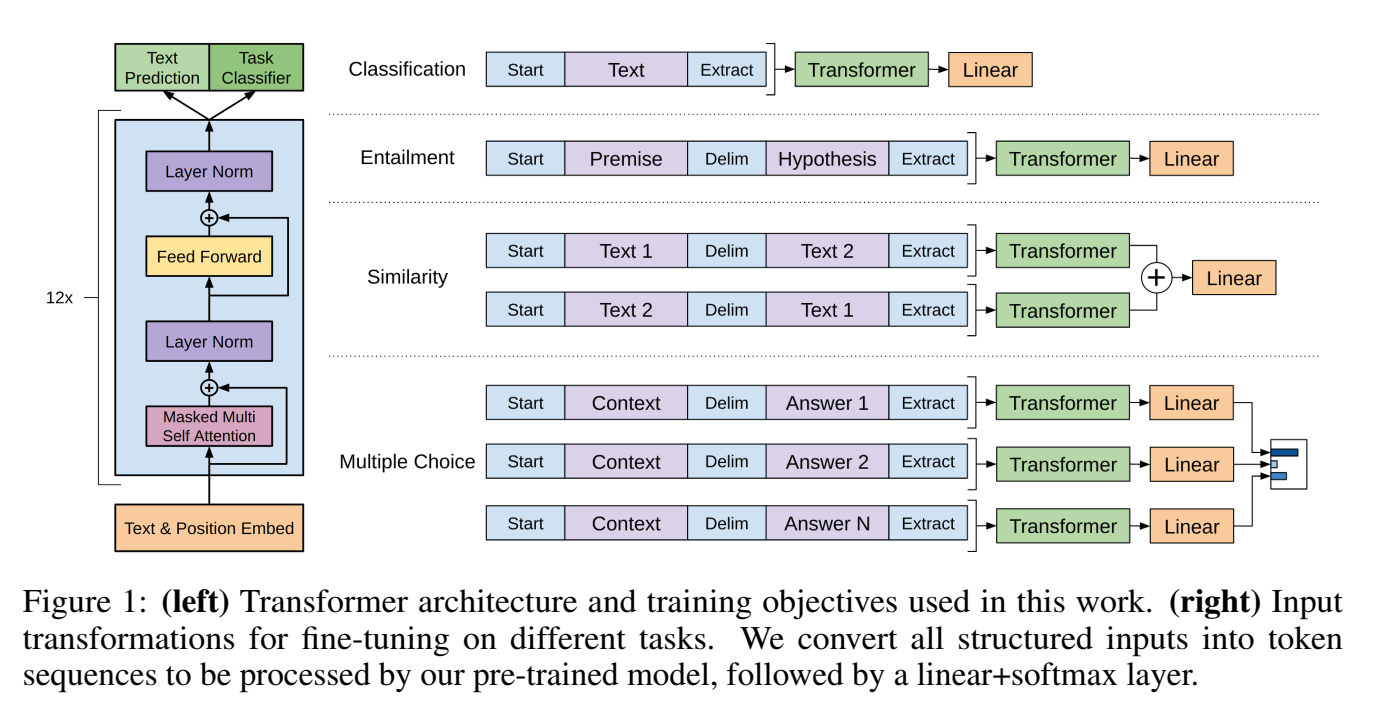
优缺点
优点:
- 循环神经网络所捕捉到的信息较少,而Transformer可以捕捉到更长范围的信息。
- 计算速度比循环神经网络更快,易于并行化
- 实验结果显示Transformer的效果比ELMo和LSTM网络更好
缺点:
对于某些类型的任务需要对输入数据的结构作调整
适用任务
- Natural Language Inference
- Question Answering and commonsense reasoning
- Classification
- Semantic Similarity
==Radford, Alec, et al. “Language models are unsupervised multitask learners.” OpenAI blog 1.8 (2019): 9.==citations:3193
https://zhpmatrix.github.io/2019/02/16/transformer-multi-task/
思路
- 提出GPT2.0
==Chronopoulou, Alexandra, Christos Baziotis, and Alexandros Potamianos. “An embarrassingly simple approach for transfer learning from pretrained language models.” arXiv preprint arXiv:1902.10547 (2019).==citations:88
Larger-Scale Transformers for Multilingual Masked Language Modeling