Code-Switching中文论文
==端到端的中英文混合语音识别声学建模算法研究_周心远.caj== 2021 硕士论文 上海师范大学
Xinyuan Zhou, Grandee Lee, Emre Yilmaz, Yanhua Long, Jiaen Liang and Haizhou Li. “Self-and-Mixed Attention Decoder with Deep Acoustic Structure for Transformer-based LVCSR.” in Proc. of the 21st Annual Conference of the International Speech Communication Association (INTERSPEECH). ISCA, 2020
Xinyuan Zhou, Emre Yilmaz, Yanhua Long, Yijie Li and Haizhou Li. “Multi- Encoder-Decoder Transformer for Codeswitching Speech Recognition.” in Proc. of the 21st Annual Conference of the International Speech Communication Association (INTERSPEECH). ISCA, 2020.
背景
- DNN-HMM框架的局限:
- 常规 DNN-HMM语音识别系统是基于拼音、音标等一些声学单元建模,在不同语言之间的声学单元相互独立,且声学属性不同。通过多种不同语言的独立发音字典无法很好地建
模不同语言声学属性之间的联系。 - 其次由于混合语言语音的特殊性,语言转换处训练数据稀疏,DNN-HMM 系统无法有效建模两种语言相接处的声学属性。
- 常规 DNN-HMM语音识别系统是基于拼音、音标等一些声学单元建模,在不同语言之间的声学单元相互独立,且声学属性不同。通过多种不同语言的独立发音字典无法很好地建
思路
提出基于 Transformer 框架和联合 CTC 训练的端到端中英文混合语音识别系统,基于字符建模;
基于 Transformer 框架提出基于自注意力与混合注意力机制的声学建模方法;
为了更好挖掘中英文两种语言之间声学上的共性和区分性,本文提出“多编码器-解码器 Transformer”结构。
端到端模型通常基于字符建模,建模单元不再完全与声学单元一一对应,能够模糊建模单元与声学属性之间的关联,使得网络能够自动平衡不同语言语音之间的相似性与区分性;同时由于端到端模型摆脱了独立性假设,能够学习到语言切换处的声学属性。
基于 Transformer 结构,文章[70]对如何更高效地建模输入与输出关系展开 了进一步的研究。其对在 Transformer 中使用解码器在每一层都将目标序列与同 一编码器输出计算依赖这一做法提出质疑,并提出 layer-wise coordination 的思 想:即编码器与解码器之间,每层相互计算依赖,并共享编码器与解码器的参数。 通过 layer-wise coordination,网络能够学习源序列与目标序列将在底层表征时的 对齐信息;并且通过参数共享,能够确保编码器与解码器的隐状态处在同一语义 级别,还能减小模型参数量。
受到 Transformer 以及 layer-wise coordination 的启发,提出下图模型结构:
使用基于自注意力与混合注意力机制的解码器(Self-and-Mixed Attention Decoder, SMAD) 以 及 深层声学结构 (Deep Acoustic Structure, DAS),以改进基于 Transformer 语音识别模型的声学表征提取。
在原始 Speech-Transformer 的解码器中,首先使用自注意力子层提取语言学的表 征。然后传至另一个 source-target 注意力子层中,与编码器输出一同计算。在每 一层解码器中,使用的是同一个编码器的输出,来学习声学表征与目标间的关系。 本章提出一种统一上述两个注意力机制的模块:自注意力与混合注意力机制 (Self-and-Mixed Attention, SMA),作为解码器中唯一的注意力子层。与标准 Transformer 不同,在 SMAD 的输入端,==将编码器的声学表征与词向量拼接作为 输入==。通过这种方式,SMA ==可以将输入音频的声学与语言学表征投影至同一子空间,强化声学与语言学之间的关系学习==。 (原始论文里,先做了self attention才又做了mix attention,这里其实就是把attention的输入,变为encoder输出和词向量输入拼接起来,只是把输入拼接而已,然后做attention)
基于自注意力与混合注意力机制的 Transformer结构:
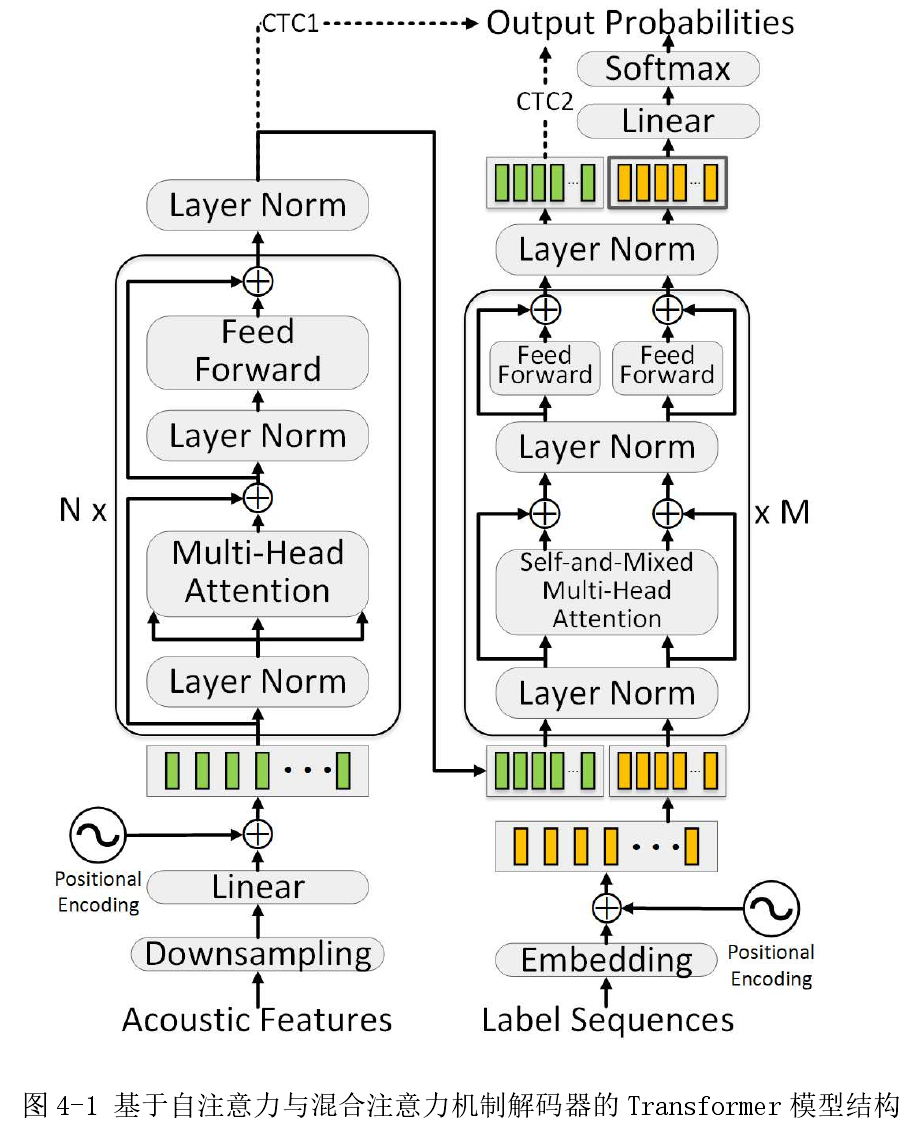
query用的词向量(target),key和value是concat了词向量和encoder输出的,然后key和value乘的W矩阵是一样的,文章说是为了将声学与语言
学表征向量投影至同一子空间,拼接后使用同一投影矩阵𝑊;
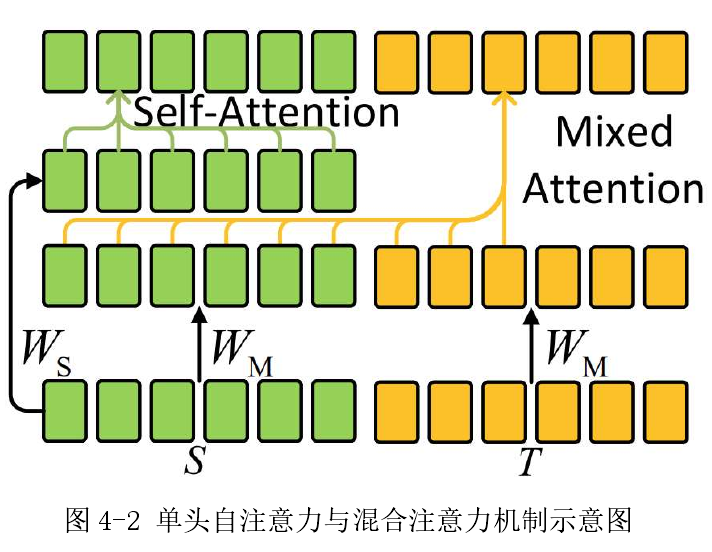
提出深 层 声 学 结 构 (Deep Acoustic Structure, DAS),相比于标准 Transformer 中,每层解码器使用相同的编码器输出。
本章提出的==解码器通过DAS,声学表征在编码器中逐层与语言学表征一同更新==。(就是decoder输出了一部分是来自encoder的信息,把这部分输出作为下一个decoder中的transformer的encoder信息,这和原始transformer不同)
该做法的目的如下:- 声学表征在解码器中再编码,利于进一步提取有效信息。
- 将声学与语言学表征投影至同一子空间,利于计算其相互关系与对齐。
第二个创新点:
多编码器-解码器 Transformer 的预训练机制
背景:由于包含中英文混合的语音及文本数据稀缺,中英文混合语音识别被视为典型的低资源任务。在多语言语音识别任务中,为解决声学建模过程中的数据稀缺 问题,可以使用==迁移学习 (Transfer Learning) 将预训练的高资源语言声学模 型迁移至目标低资源任务==。类似地,在中英混合 ASR 中,也可以使两个预 训练的声学模型适应至资源较少的混合语言条件中。另一种策略是应用==多任务学习技术==,通过联合训练 ASR 声学模型和语言识别分类器,来发掘混合语言 ASR 中的语言特定属性并减轻数据稀疏性。 但在这些工作中,==仅在解码器或模型的输出层中捕获了特定于语言的信息==。
入下图所示,结合了两个特定于语言的encoder(在图中分别用蓝色标记为英文相关,和橙 色标记为中文相关),以学习各个语言的属性。目的是通过为每种混合语言使用单独的模块来增强在每个encoder的输出处给出的声学表征向量之间的差异性。
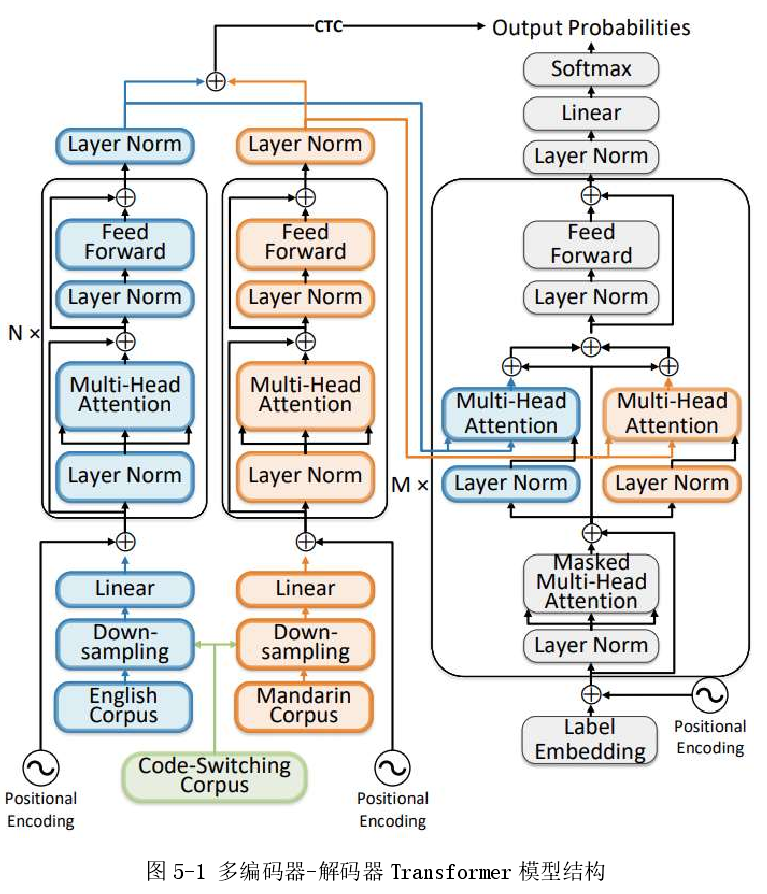
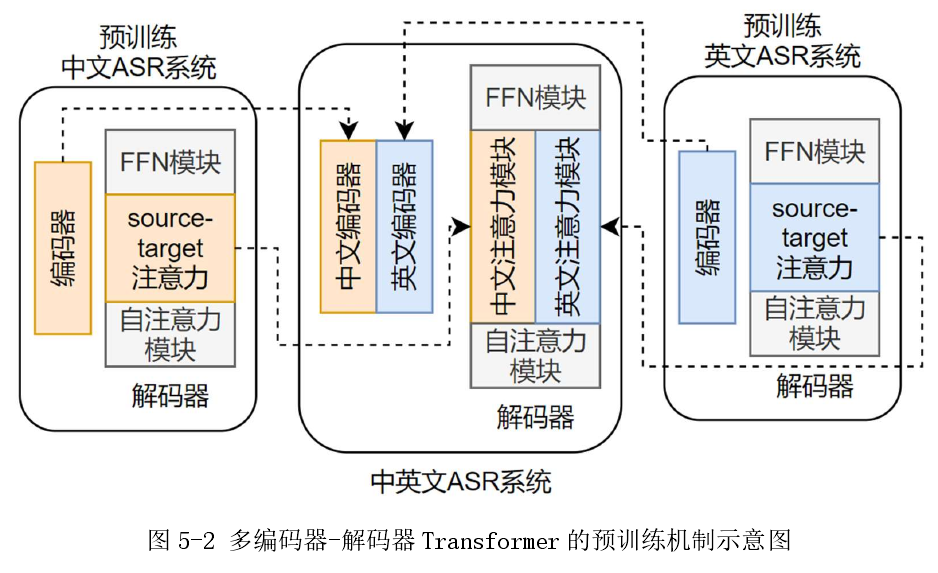
分别使用大型单语英文和中文语料库对特定语言的编码器和相应的注意力模块进行预训练
预训练:
其实就是中英文分别训练,然后拼起来,就是中英文asr系统,分别训好的模型作为初始化模型
实验
- 数据集:国际公开的中英文混合语音识别数据集 SEAME,该数据集和中国人说英文(夹杂英语)不同,是新加坡人说中文夹杂英文,很多都是英语长句,比起我们说的只有夹杂一两个英语单词还不太一样;
==基于LAS模型的中英文混杂语音识别研究_马夺.caj== 西北民族大学 2020 硕士论文
Ma, Duo, Guanyu Li, Haihua Xu, and Eng Siong Chng. “Improving code-switching speech recognition with data augmentation and system combination.” In 2019 Asia-Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA ASC), pp. 1308-1312. IEEE, 2019.
思路
训练过程用了计划抽样(schedule sample)[61]:这是由于训练attention过程用的标签训练的(teacher forcing),没有用任何输出概率的预测来影响网络,但是推理时无标签,用的是预测值来作为下一个符号的输入,因此模型泛化性不好;因此用了计划抽样,前期训练用标签,后期训练抽一些预测值作为输入;
Samy Bengio, Oriol Vinyals, Navdeep Jaitly, and Noam Shazeer. Scheduled Sampling for Sequence Prediction with Recurrent Neural Networks. In http://arxiv.org/abs/1506.03099, 2015
计划抽样:具体做法是在网络训练时以一定的概率选取网络预测输出标签作为预测下一个标签的条件;
Attention:基于注意力机制的 软对齐方式实现文本层次信息和音频层次信息的对齐。
CTC:基于帧级别的严格单调对齐的连接时序分布网络,直接从语音特征转换到帧级别的标签序列,然后对帧级别的标签序列进行后处理得到文本序列。
▁表示一个空格,中文英文都用bpe建模,
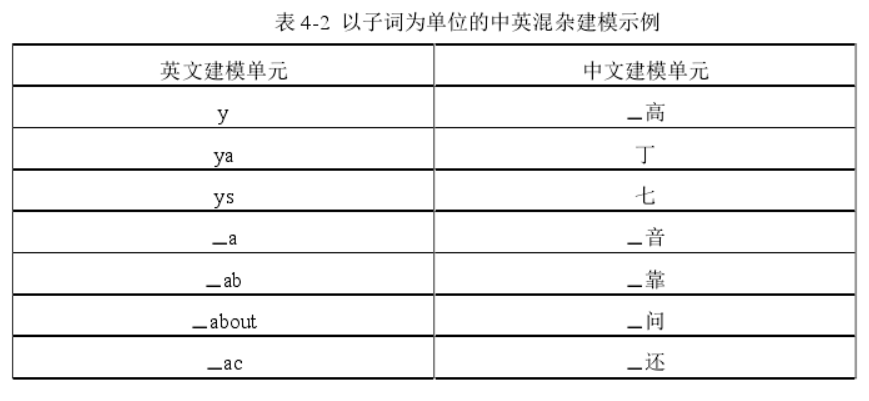
- 要查看用子词建模的语言模型的困惑度

- 介绍了多种注意力机制:
- 点乘注意力机制
- 加性注意力机制
- 位置感知注意力机制[比较好]
- 收敛的注意力机制
- 基于LSTM的位置感知注意力机制
- 基于位置感知的收敛的注意力机制
- 加性的多头注意力机制
实验
- 数据集:国际公开的中英文混合语音识别数据集 SEAME;
- 模型变大时,梯度累加策略也要加大,多累计几步再更新!这个比较重要,不然可能负优化;
结果
- 调参:
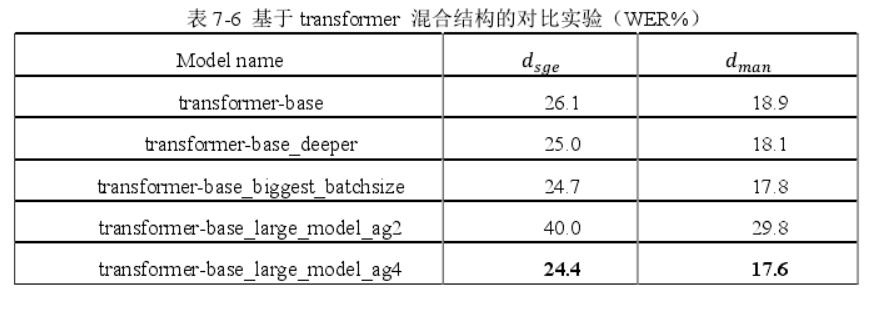
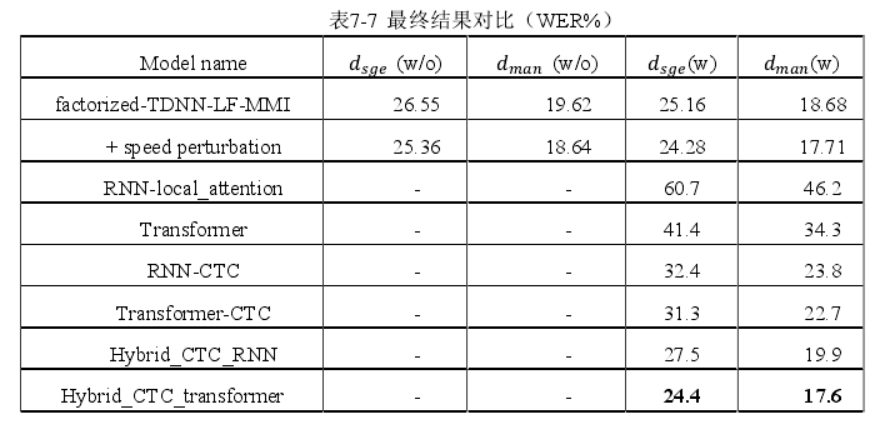
- SEAME 的两个测试集上,词错误率(WER)分别为 24.4%和 17.6%;
==中英文混合语音识别数据选择与数据增广方法研究_张皓博.caj== 新疆大学 硕士论文 2021
Monolingual Data Selection Analysis for English-Mandarin Hybrid Code-Switching Speech Recognition
思想
声学模型:
数据增广可以增加语音识别模型的鲁棒性,但是语料的内容并没有进行相应的扩充,因此在准确度上的收益并不明显。
最近几年,出现了使用语音合成作为语音识别的一种数据增广方式[49] [50] [51] [52];其中包含了将合成的语音加入训练集的方式,还有使用语音识别、语音合成模型联合训练。
用中英文混合的语音合成系统为中英混合语音识别做数据增广;阿里巴巴使用跨语种语音转换(Cross-lingual Voice Conversion)的方式构建了中英文混杂语音识别系统[96];
(之前雷博说不可行,因为合成的音是确定的,没有上下文信息,那么现在用一个声学模型部分已经挺好的识别模型,再用合成数据,能否改善语言模型那部分(decoder)),感觉是可能可行的,虽然没有改善声学模型,但是改善了语言模型decoder部分?。
使用中文、英文数据训练一个预训练模型, 利用迁移学习的方式[ 55],构建中英文混杂语音识别系统。当任务中成对的有标签 数据较少,而无标签数据较多时,还可以使用半监督学习构建中英文混杂语音识别 系统[56]。
语言模型:
- 在构建语言模型时,我们可以通过互联网获取任务相关的文本。语言模型的构建也可以使用数据增广的方式[ 57] [58],还可以通过一定的策略生成更多中英文混合的文本,为大词汇量中英文混杂语音识别构建词汇量充足的中英文混杂的语言模型。例如可以利用 BERT 模型、或是生成对抗神经网络(GAN)进行文本生成[ 59] [60],生成的文本可以构建更大的语言模型,也可以指定领域高频话题语料,来生成特定任务上的语言模型。
- 一般使用神经网络语言模型来提升语音识别的准确率还需要第二步重打分(Rescore)操作,即在解码器解码出的最有可能的一组结果中,利用神经网络语言模型,对每个结果重打分,选取最优可能的结果;通常重打分的操作可以在 Lattice 上进行,也可以在 N-best 的结果上进行,但是在 Lattice 上解码的结果通常要好于 N-best,因为 Lattice 可以表示更大的假设空间。
- 也有人尝试不使用重打分的方式让识别过程分两个阶段,他们提出更高效的方式尝试在解码时就使用神经网络语言模型[84] [85] [86] [87] [88]。
解码器:
- 为中英文混杂模型构建解码器时,可以将原来单语的解码器中,为那些常发生 翻译替换的中文词添加英文标签,从而来构建混合语音识别的解码器[ 61]。另外,基 于 n-gram 的语言模型,相较于神经网络的语言模型来说,建模能力相对较弱。使 用 RNNLM(Recurrent Neural Network Language Model)构建语音识别的语言模型, 对混合语音识别系统的 n-best 识别结果进行重打分,性能有明显提升[62];
词典
- 英文:2019 年 Facebook 提出有效的方案,可以让英文词典可直接通过上下文相关的英文字母加边界标记来表示每个词的发音,以此作为声学模型的建模单元[92];每个字母的开头和结尾使用词边界标志 WB(Word Boundary)标记,大写保持,单词中的部分符号保持。
- 但英文数据很少时(在中英混里占的比例很少),该方法还不如只用音素建模的识别系统!![该方法会略微变差]

端到端混合语音识别系统:TODO(感觉不错,可以好好看看)
- 中英文混杂的端到端语音识别系统也不断被提出[63] [64] [65] [66]。
- (1)数据增广:由于混杂数据相较于纯中文、纯英文 数据较少,训练过程中非常容易过拟合,需要进行数据增广、数据生成的方式防止 模型过拟合,同时提升模型的鲁棒性。因此,数据增广对于中英文混合的端到端语 音识别也是至关重要的[ 67][68]。
- (2)语言模型:端到端模型需要大量有标签数据,可 以训练独立的语言模型,然后对端到端模型进行融合,以达到学习足够的文本规则。 但是语言模型的融合、重打分对模型性能地提升还不算高效。
- (3)基于深度学习的 端到端模型灵活复杂,相较于传统语音识别,融合多任务学习也能够提升模型性能。例如中英文混杂识别联合语种识别[69] [70] [71]、口音识别 [72] [70] [73]、说话人识别 [74]等都 提出了不同的多任务 ASR 模型。
模型
- HMM-TDNN-F ,chain model
实验
- 数据:数据堂ASRU 2019比赛,200小时中英混+500小时中文;
- 发音词典: 210 个普通话音素,以及 42 个英文音素,两个音素集不存在共用音素;
- 改进:发现数据堂的发音词典里面中文部分有很多标注错误的?因此从网上爬取发音,重新做了词典;
- 改进:中文重新从网上爬;英文用facebook的上下文相关的音素建模,不是用的上下文无关的音素;【但是效果会变差!】
- 改进:由于比赛给定了语言模型,因此按语言模型的词语,重新对文本进行分词(之前是jieba分词),这个效果挺显著;【发音词典和语言模型若更加匹配,就能构建更优的图网络】
- 添加中文数据对系统的影响:
- 使用更多的普通话数据,识别结果的中文部分有明显的改善;识别性能的提升主要来自单个英语单词的语句,从这个角度看来,是符合数据匹配猜测的;(数据中只有一个/两个英文的文本居多)
- 更多的普通话数据不会明显影响英语部分的识别;对于那些包含更多英文单词的语句,添加中文单语数据对性能的提升作用有限,甚至是负面影响
- 当添加中文数据超过某个点时,可能会伤害整体的性能,测试集上使用大约 400 小时的普通话数据时,可以获得最佳性能
- 结果的改善归因于 Man500 数据集合 CS200 数据集在中文方面的紧密的相似性;
- 数据匹配很关键;
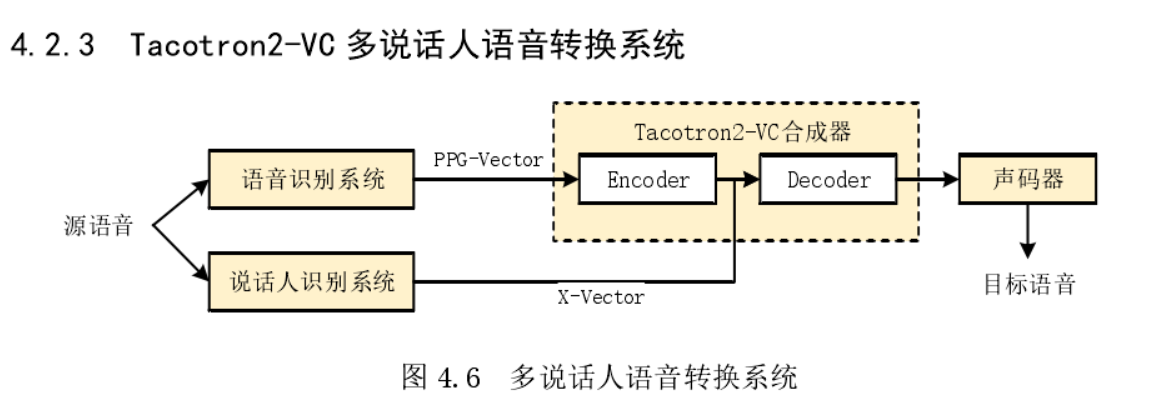
基于语音转换(VC)的方法进行数据增广:
- 合成只有单个音色,单个说话人,用语音转换的方法扩充不同说话人,就相当于给识别做数据增广;

- Tacotron2-VC 多说话人语音转换系统
==基于中英文混合模型的语音识别研究== 李伟 语音技术 中国电子科技集团公司 第四十三研究所 2011
太早的论文了,没什么参考价值;
思想
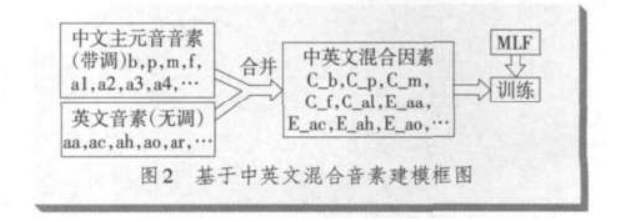
根据发音学的一些先验知识,提出一种基于主元音及英文音素序列混合的声学模型
就是把中文和英文的音素混在一起,并且做了一些合并的操作;
中文的主元音大概有 40 多个,加上英文的 40多个音素,一共 80 多个音素;
考虑到汉语的声调问题,主元音的音素扩展到 98 个,例如 a 的发音,扩展成a1,a2,a3,a4;
辅音(21 个)都是无调的,不做扩展。
考虑到中文和英文的音素有些发音相同,就把这些音素合并到一起,例如 b,p 等。最终得到的音素个数为126 个;
结果
- 比起纯中文和纯英文模型,准确度下降各自从80%下降到70%,但是中英混合从40%上升到70%
==论网络流行语中中英文混合语的语码转换现象== 程迎新 渤海大学 2015 六盘水师范学院学报