kaldi chain
生成phone的语言模型lm,为了分母hclg lattice服务:
chain_lib.create_phone_lm(args.dir, args.tree_dir, run_opts, lm_opts=args.lm_opts)
exp7/chain/tdnn/log/make_phone_lm.log:
gunzip -c exp7/chain/tri5_tree/ali.1.gz exp7/chain/tri5_tree/ali.2.gz exp7/chain/tri5_tree/ali.3.gz exp7/chain/tri5_tree/ali.4.gz exp7/chain/tri5_tree/ali.5.gz exp7/chain/tri5_tree/ali.6.gz exp7/chain/tri5_tree/ali.7.gz exp7/chain/tri5_tree/ali.8.gz exp7/chain/tri5_tree/ali.9.gz exp7/chain/tri5_tree/ali.10.gz exp7/chain/tri5_tree/ali.11.gz exp7/chain/tri5_tree/ali.12.gz exp7/chain/tri5_tree/ali.13.gz exp7/chain/tri5_tree/ali.14.gz exp7/chain/tri5_tree/ali.15.gz exp7/chain/tri5_tree/ali.16.gz exp7/chain/tri5_tree/ali.17.gz exp7/chain/tri5_tree/ali.18.gz exp7/chain/tri5_tree/ali.19.gz exp7/chain/tri5_tree/ali.20.gz exp7/chain/tri5_tree/ali.21.gz exp7/chain/tri5_tree/ali.22.gz exp7/chain/tri5_tree/ali.23.gz exp7/chain/tri5_tree/ali.24.gz exp7/chain/tri5_tree/ali.25.gz exp7/chain/tri5_tree/ali.26.gz exp7/chain/tri5_tree/ali.27.gz exp7/chain/tri5_tree/ali.28.gz exp7/chain/tri5_tree/ali.29.gz exp7/chain/tri5_tree/ali.30.gz | ali-to-phones exp7/chain/tri5_tree/final.mdl ark:- ark:- | chain-est-phone-lm –num-extra-lm-states=2000 ark:- exp7/chain/tdnn/phone_lm.fst
生成分母lattice
exp7/chain/tdnn/log/make_den_fst.log:
chain-make-den-fst exp7/chain/tdnn/tree exp7/chain/tdnn/0.trans_mdl exp7/chain/tdnn/phone_lm.fst exp7/chain/tdnn/den.fst exp7/chain/tdnn/normalization.fst
den.fst :
- 第一列 :输入结点(结点,也叫fst的状态数),G 3gram phone 状态(0-3475,一共3476个);
- 第二列 :输出结点,G 3gram phone 状态(0-3474,一共3475个);(hmm_state????chain/chain-den-graph.cc)
- 第三列:in label:H pdf 状态(1-2392,一共2392个,原本pdf是0-2391的(pdf包含forward-pdf 和self-loop-pdf))(下面的例子用的tdnn_3、tdnn_4的模型,pdf 1976个)
- 第四列:out label:H pdf 状态
- in label和out label相同
- den.fst的结点是G空间,上面的分数是声学分数?语言分数?
1 | 3475 1516 1 1 8.70407677 |
计算loss脚本:
exp7/chain/tdnn/log/compute_prob_valid.1.log:
nnet3-chain-compute-prob –l2-regularize=0.0 –leaky-hmm-coefficient=0.1 –xent-regularize=0.1 exp7/chain/tdnn_3/final.mdl exp7/chain/tdnn_3/den.fst ‘ark,bg:nnet3-chain-copy-egs ark:exp7/chain/tdnn_4/egs/train_diagnostic.cegs ark:- | nnet3-chain-merge-egs –minibatch-size=1:64 ark:- ark:- |’
1 | nnet3-chain-merge-egs --minibatch-size=1:64 ark:- ark:- |
normalization.fst在分母有限状态机den.fst的基础上,修改了初始概率和终止概率得到的。
查看 cegs内容:
nnet3-chain-copy-egs ark:exp7/chain/tdnn_4/egs/train_diagnostic.cegs ark,t:1
- 由于chain模型采用跳帧策略,所以egs中存储的是三倍下采样后输出索引
- 分子lattice。WFSA结构。用于计算MMI,第三列、第四列是pdf的id(1-1975)
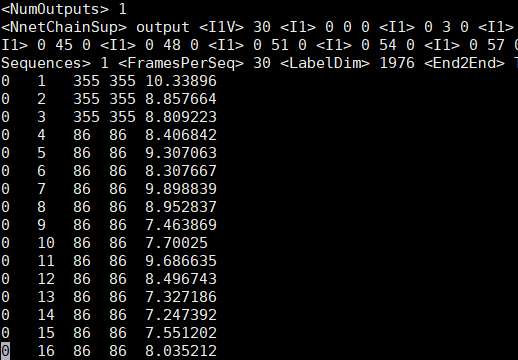
- 强制对齐结果,用于计算交叉熵??实际用上了吗?代码中交叉熵也是用的前后向计算的,没有用这个

计算loss代码:
nnet3-chain-compute-prob --l2-regularize=0.0 --leaky-hmm-coefficient=0.1 --xent-regularize=0.1 exp7/chain/tdnn_3/final.mdl exp7/chain/tdnn_3/den.fst ark:1
kaldi chain模型的序列鉴别性训练代码分析 jarvanWang博客园
Chain训练准则的计算 jarvanWang博客园
跳转路线:
1 | chainbin/nnet3-chain-compute-prob.cc 的 chain_prob_computer.Compute(example_reader.Value()); |
nnet_output:dnn输出
chain/chain-training.cc
1 | Supervision &supervision |
初始化:
NnetChainComputeProb chain_prob_computer(nnet_opts, chain_opts, den_fst,nnet);
chain/chain-supervision.h:可以看见类Supervision的详细定义与Supervision的成员解释
- Supervision类:
- label_dim:pdf数量
- fst:按帧index排序
chain/chain-den-graph.h:可以看见类DenominatorGraph的成员定义
- DenominatorGraph类:
- ForwardTransitions
- BackwardTransitions
- Transitions
chain/chain-den-graph.cc:
1 | void DenominatorGraph::SetTransitions(const fst::StdVectorFst &fst, |
- den.fst:(这里把fst权重转换为exp-)
fstprint den.fst | awk -F'\t' '{$NF=exp(-$NF);print$0}' | tr ' ' '\t'
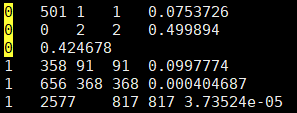
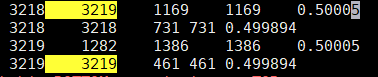
- transitions_out :transitions_out索引是den.fst的第一列,因此表示这个结点状态辐射出多少条路径的意思

- transitions_in :transitions_in索引是den.fst的第二列,因此表示多少条路径到这个结点状态的意思

- transitions :按顺序把transitions_out内容和transitions_in 全放到transitions里
- forward_transitions :transitions_out每个结点状态的初始数量和辐射出边的数量

- backward_transitions 内容:接完transitions_out全部后,transitions_in每个结点状态的初始数量和到这个结点边的数量

只求loss时,也会用到前后向算法(chain/chain-training.cc:denominator.Forward())
$\alpha$ 的概率,依赖声学分数(nnet_output(pdf数*帧数))和语言分数,因为里面的状态是G空间的状态
chain/chain-denominator.cc:赋予$\alpha$ 值
1 | BaseFloat DenominatorComputation::Forward() { |
1 | frames_per_sequence_ = 30 |
alpha(t, i)对应前后向算法中的$\alpha$($\alpha_t(i)$定义:到时刻t,部分观测序列为$o_1,o_2….,o_t$且状态为i的概率为前向概率)
beta(t, i)对应前后向算法中的$\beta$($\beta_t(i)$定义:到时刻t,状态i,部分观测序列为$o_{t+1},o_{t+2},…,o_T$的概率为后向概率)
gamma(t, n) ($\gamma_t(i)$定义:给定模型和观测序列,在时刻t处于状态i的概率$\large{\gamma_t(i)=\frac{\alpha_t(i)\beta_t(i)}{\sum\limits_{j=1}^N\alpha_t(j)\beta_t(j)}}$)
chain/chain-datastruct.h:
后面计算alpha就是用到这个三元组,hmm_state知道哪个状态结点(要遍历的),pdf就知道对应哪个发射概率,transition_prob对应语言模型概率
1 | struct DenominatorGraphTransition { |
前后向算法里面的转移概率是语言模型概率
- loss,用前后向算法得到loss值
分母前向alpha计算:chain/chain-denominator.cc
1 | int32 prob_stride = probs.Stride(); //yl:probs.Stride()是帧数 |
分子
分子loss计算:chain/chain-generic-numerator.cc
知道了确定的pdf,三元组的时候就不用遍历所有pdf了,但也要遍历所有G空间状态。
1 | //chain/chain-training.cc: |
chain/chain-generic-numerator.cc:
- out_transitions_:GenericNumeratorComputation的类成员,transition_prob是当前lattice里的权重减去该句子权重最大值,再取负号
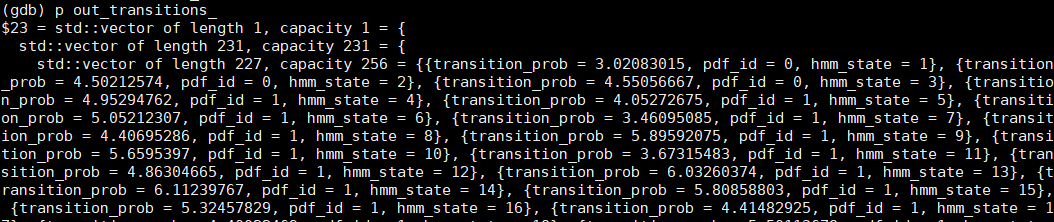
- in_transitions_:GenericNumeratorComputation的类成员
- 计算$\alpha$,所有lattice上这个状态结点的概率 累加 (概率还包含状态转移和pdf发射)
1 | for (int t = 1; t <= num_frames; ++t) |