语言模型
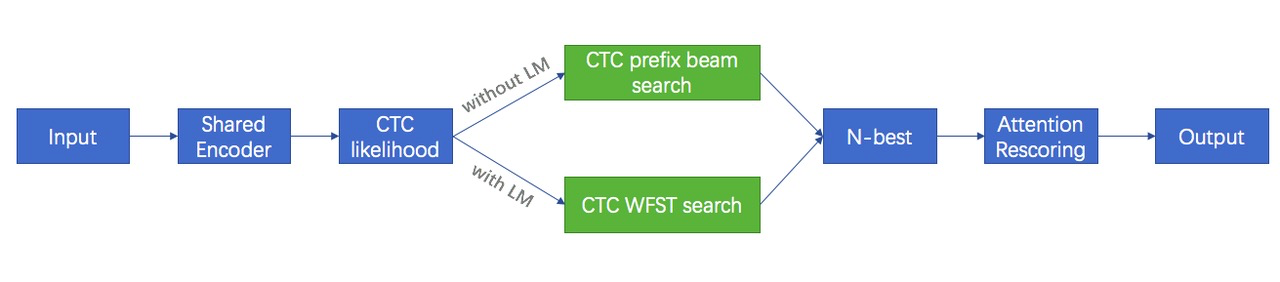
- 没有LM,用CTC prefix beam search来产生N-best
- 有LM,用CTC WFST search来产生N-best,其中CTC WFST search是传统的基于WFST的decoder
第一步是构建解码图,用建模单元T,词典L,语言模型G组合compose到统一一个解码图TLG里,其中T是端到端训练的建模单元,中文里是char,英文是char或BPE;L是词典,就是把词组分开成建模单元,比如把word“我们”分开成两个chars“我 们”,word“APPLE”分开成五个字母letters“A P P L E”,没有音素,词典不用特殊设计;G是语言模型,就是将n-gram编译成标准的WFST表示;
第二步是解码,和传统方法一样,用Viterbi搜索算法;
WeNet利用Kaldi中的解码器和相关工具来支持基于LM和WFST的解码。为了便于使用和保持独立性,我们在WeNet运行时直接将Kaldi中与解码相关的代码迁移到此目录。并按以下原则进行修改和组织:
- 为了最小化更改,迁移后的代码保持与原始代码相同的目录结构。
- 我们使用GLOG代替Kaldi的日志系统。
1 |
- 我们修改了代码格式,以满足WeNet代码风格的lint要求。
核心代码是 https://github.com/wenet-e2e/wenet/blob/main/runtime/core/decoder/ctc_wfst_beam_search.cc , 它在Kaldi中包装wrap了LatticeFasterDecoder。我们使用空白帧跳转来加速解码。
此外,WeNet还迁移了构建解码图的相关工具,如arpa2fst、fstdeterminizestar、fsttablecompose、fstminimizeencoded等工具。因此,所有与LM相关的工具都是内置工具,可以开箱即用。
我们在不同的数据集上获得了一致的增益(3%~10%),包括aishell、aishell2和librispeech
词典的构造:
tools/fst/prepare_dict.py
之前训练时,按字建模,没有词组,因此字一共有4232个字(训练集)(data/dict/lexicon.txt),加eos/sos是4233个
现在:把aishell里的一个自带的词典corpus/aishell/resource_aishell/lexicon.txt(13万个词组),通过data/dict/lexicon.txt进行过滤,只保留训练集有的字的词组,
得到的词典用字建模,组成词组,12万词的词典(data/local/dict/lexicon.txt);
训练LM:
local/aishell_train_lms.sh
用训练集训练LM:
从corpus/data_aishell/transcript/aishell_transcript_v0.8.txt(所有train/dev/test音频对应的文本,进行了分词)过滤出训练集对应的12万条分词文本(data/local/lm/text)
用分词过的12万条训练集文本、12万词的词典 训练语言模型,得到 16M的 3-gram的lm.arpa
file data/local/lm/heldout: 10000 sentences, 89496 words, 0 OOVs
0 zeroprobs, logprob= -272791.2 ppl= 551.7352 ppl1= 1117.077
可以看出,ppl=500多,还不是特别好(300以内才好)
构建解码中使用的TLG
tools/fst/compile_lexicon_token_fst.sh
tools/fst/make_tlg.sh
TLG.fst = T compose(determini(L compose G))
TLG参与推理解码
./tools/decode.sh
1 | ./tools/decode.sh --nj 16 \ |
./tools/decode.sh 具体为:
1 | decoder_main \ |
要到runtime/server/x86 进行编译:mkdir build && cd build && cmake .. && cmake --build . [用docker的话,这步就不需要]
cmake版本要3.14 ,我没有编译成功(3.12),错误报告见:/home/data/yelong/newest_wenet/wenet/runtime/server/x86/build/CMakeFiles/CMakeOutput.log
因此决定直接用 docker
进入到container中:docker exec -it 5627fbb7b503 bash
进入到/home/wenet/runtime/server/x86
用c进行解码
使用docker启动语音识别服务
先要拉去最新的image
1 | cd docker |
最简单的使用 Wenet 的方式是通过官方提供的 docker 镜像 wenetorg/wenet:mini 来启动服务。
(镜像默认都是放在https://hub.docker.com/里,然后虽然没有这个前缀,但是会去这上面找镜像,镜像名叫wenetorg/wenet-mini)
下面的命令先下载官方提供的预训练模型,并启动 docker 服务,加载模型,提供 websocket 协议的语音识别服务。
1 | cd wenet/runtime/server/x86 |
$model_dir 是模型在本机的目录,将被映射到容器的 /home/wenet/model 目录,然后启动 web 服务。
用网页的实时识别
上面的docker容器中运行 bash /home/run.sh
/home/run.sh内容:
1 |
|
然后下载github的wenet整个项目到windows本地,使用浏览器打开文件runtime/server/x86/web/templates/index.html,在 WebSocket URL:填入 服务器的地址,端口号,比如ws://10.22.23.14:10086
就可以了!
经我测试,识别非常慢,识别不准确。。??
在 Docker 环境中使用
如果遇到问题比如无法编译,我们提供了 docker 镜像用于直接执行示例。需要先安装好 docker,运行如下命令,进入 docker 容器环境。
1 | docker run -it mobvoiwenet/wenet:latest bash |
该镜像包含了编译过程中所依赖的所有第三方库、编译好的文件和预训练模型。
预训练模型在 /home/model 目录, 可执行程序在 /home/wenet/runtime/server/x86/build 目录。
有了这个镜像后,平时需要的话,可以新建容器:
1 | docker run -it mobvoiwenet/wenet:latest bash |
如果修改了cc文件,要执行 mkdir build && cd build && cmake .. && cmake --build .进行编译
自行编译运行时程序
==该方式不推荐,因为本地编译麻烦,cmake升级版本还和gcc版本有关==
如果想使用非 docker 方式,需要自行编译。Wenet 支持 linux/macos/windows 三种平台上的编译。需要安装 cmake 3.14 或者更高版本。
运行如下命令,完成编译。
1 | # 当前目录为 wenet/runtime/server/x86 |
或者使用命令编译以支持 gRPC。
1 | mkdir build && cd build && cmake -DGRPC=ON .. && cmake --build . |
编译好的可执行程序在 wenet/runtime/server/x86/build/ 下:
- decoder_main 本地文件识别工具
- websocket_server_main 基于websocket协议的识别服务端
- websocket_client_main 基于websocket协议的识别客户端
下载预训练模型
1 | # 当前目录为 wenet/runtime/server/x86 |
以上不推荐,因为本地编译麻烦,cmake升级版本还和gcc版本有关
本地wav文件识别
本地文件识别,即程序每次运行时,给定一个语音文件或者一组语音文件列表,输出识别结果,然后结束程序。
下载好模型后,执行如下的命令进行本地wav文件识别,将 wav_path 设为你想测试的 wav 文件地址,将 model_dir 设为你的模型目录地址。
进入到镜像为mobvoiwenet/wenet:latest的容器里
cd /home/wenet/runtime/server/x86
1 | # 当前目录为 wenet/runtime/server/x86 |
decoder_main工具支持两种wav文件模式:
- 使用
--wav_path指定单个文件,一次识别单个wav文件。 - 使用
--wav_scp指定一个.scp格式的wav列表,一次识别多个wav文件。
执行 ./build/decoder_main --help 可以了解更多的参数意义。
1 | docker run -d -v /home/data/yelong/newest_wenet/wenet/runtime/server/x86/docker/docker_resource:/home/data/yelong/newest_wenet/wenet/runtime/server/x86/docker_resource -it wenet bash |
测试不同解码方法的rtf
测试集、模型在:10.22.24.3:/home/data/to_yelong/rtf-test
在空机器10.22.23.14,cpu,单线程测试
1 | grep Decoded exp/hua/xueyuan_0.0_1.0/split1/1.log | awk '{print$6}' | sed s'/ms//g' | awk '{sum+=$1} END {print sum}' |
decoder_main 单线程测试,n-best=10,无LM,解码方式CTC prefix beam search (+rescore):
37.pt(195M模型,大概50M参数):rtf=0.08475(有rescore)
4.pt(500M模型,140M参数):rtf=0.2759(有rescore);rtf=0.1377(无rescore)