语言模型融合
==Cabrera, Rodrigo, et al. “Language model fusion for streaming end to end speech recognition.” arXiv preprint arXiv:2104.04487 (2021).==
解决什么问题
- 通过使用在和训练不匹配的文本数据上训练的语言模型(LM)来解决流式和尾部识别的挑战,以增强端到端模型;
- 解决tail phenomena 的问题,比如专有名词,数值,口音 ?
用了什么方法
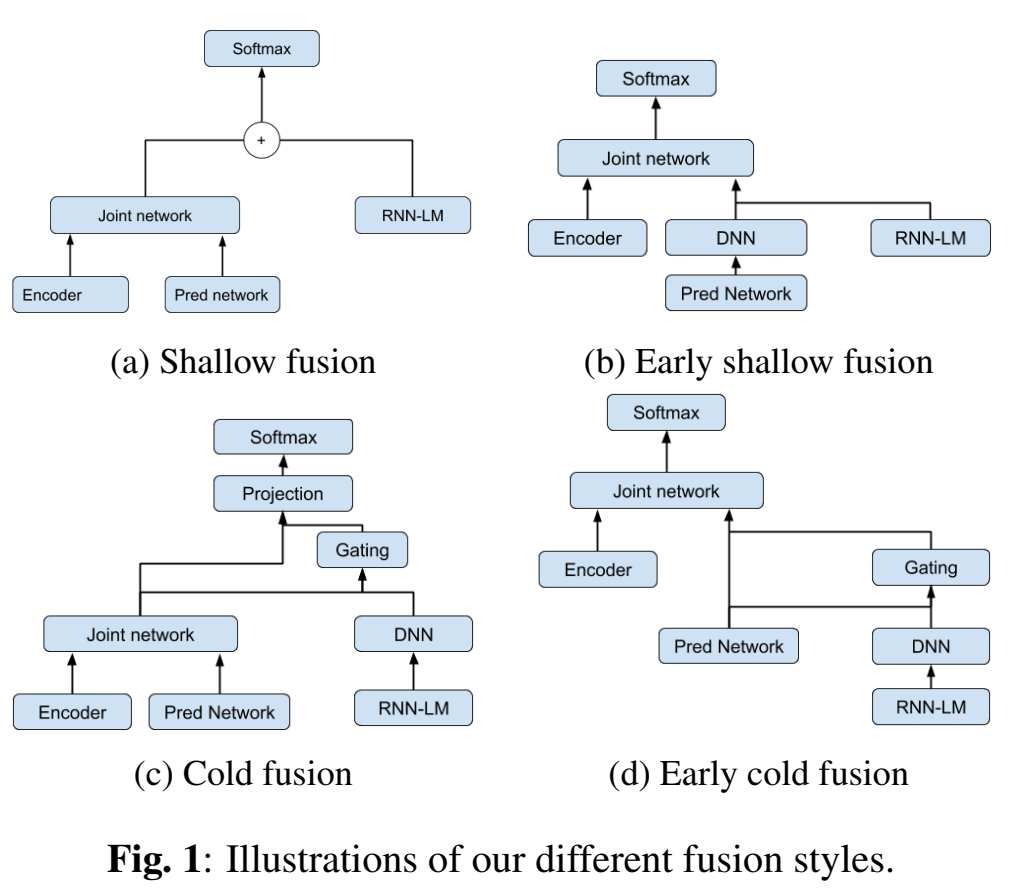
- 扩展了流式RNNT中声学模型和语言模型融合shallow fusion 和 cold fusion方法,提出两种新的competitive fusion方法
效果如何
- 8%改善识别率
还存在什么问题
tail phenomena ?
加了lm对rtf、内存、延时有影响吗?多大影响?
好的多语种识别模型一般是怎么样的?是按论文所说的各自训练一个语种的am/lm模型,再多个模型融合吗?
论文思路
通过使用在和训练不匹配的文本数据上训练的语言模型(LM)来解决流式和尾部识别的挑战,以增强端到端模型;
扩展了流式RNNT中shallow fusion 和 cold fusion方法,提出两种新的competitive fusion方法
端到端模型中,可以用纯文本训练LM,来进行模型融合,常用的有shallow fusion,deep fusion,cold fusion,component fusion,他们大多用神经网络LM,少部分用n-gram fst LM;
但是这些融合模型是非流式的,流式的融合模型还没怎么有论文
RNN-LM:对于一个wordpiece序列,语言模型概率为 $\large P(w_1^T)=\prod\limits_{i=1}^TP(w_i|w_1,w_2,…,w_{i-1})$
训练LM时没有blank,但是RNNT里有,因此推理时要给RNN-LM一个blank概率,文中定义blank概率等于RNNT里blank的输出概率,即 $\large logP_{lm}(
)=logP_{rnnt}( )$ 这意味着当RNNT模型输出blank时,RNN-LM不更新,融合后blank的概率保持不变。。?
shallow fusion:把RNNT的概率和RNN-LM的概率log线性相加,再送入softmax层: $\large logP(y_t)=logP_{rnnt}(y_t)+\beta logP_{lm}(y_t)$ ,其中$y_t$是t帧时的输出符号
- RNNT和LM分开训练(不同数据)各训各的,
- 注意,这里应该就不是联合训练,没有训练过程,而是各自训练好了,融合到一块,得到每帧下每个符号的概率
- 因此,$\beta$ 和 blank惩罚这两个超参数就要精细调节,才能有好的识别率
Early Shallow Fusion
- 因为RNNT里的预测网络prediction network被比作LM,受此启发,将该LM和预训练LM进行log线性插值融合,再送入RNNT里的joint network;
- $l_t^{Pred}=DNN(h_t^{Pred})$ , $h_t=l_t^{Pred}+\beta l_t^{LM}$
- 只在推理阶段用
Cold Fusion
预训练LM参与rnnt训练,但是rnnt参数更新,lm参数不更新
用fine-grained gating方法,这样对于非训练集之外的场景效果会更好[TODO]?
$\large h_t^{LM} = DNN (l_t^{LM})$
$\large g_t=\sigma(W[s_t^{jn};\dot h_t^{LM}]+b)$
$\large s_t=[s_t^{jn};g_t h_t^{LM}]$
$\large r_t=DNN(s_t)$
$\large \hat P(y_t|x,y<t)=softmax(r_t)$
? 公式有写错吗
推理时还需要用LM吗?
Early Cold Fusion
训练推理阶段都用
$\large h_t^{LM}=DNN(l_t^{LM})$
$\large g_t=\sigma(W[h_t^{Pred};h_t^{LM}]+b)$
$\large h_t=[h_t^{Pred};g_t \dot h_t^{LM}]$
实验
模型:RNNT:
- encoder network :8层单向LSTM,2048结点,640维projection层;
- prediction network :2层单向LSTM,2048结点,640维projection层;
- joint network:前馈层,640结点;
- 参数量:120M
- 建模单元:wordpieces(WPE),vocabulary=4096
- A stacking layer is inserted after the second layer, which stacks the outputs of two neighboring frames with a stride of 2 for speed improvement.
模型:RNN-LM:
- 2层单向LSTM,2048结点,128维embedding层;60M参数量;
- 建模单元:wordpieces(WPE),vocabulary=4096
RNNT数据集:不同数据量的的多语种实验(三种语言),
- Greek :6700h
- Norwegian :3500h
- Sinhala :160h
- 数据扩展:room simulator ,加噪,混响,平均信噪比12dB
RNN-LM训练数据:60%来自RNNT训练文本,40%来自其他;
- Greek :10亿条文本
- Norwegian :10亿条文本
- Sinhala :2亿条文本
RNN-LM训练准则:最小化log困惑度
最终用的模型:不同语种模型进行模型融合得到的一个模型;
结果
- 对于attention base 模型,shallow fusion 优于 cold fusion;(文中没做该实验,该结论来自las论文)
- 对于RNNT models 模型,cold fusion 优于 shallow fusion;
收获
- 预训练的RNN-LM和声学模型联合训练(只训练声学模型参数)会提高识别率
==Liu, Yufei, et al. “Internal language model estimation through explicit context vector learning for attention-based encoder-decoder ASR.” arXiv preprint arXiv:2201.11627 (2022).==
解决什么问题
E2E模型已经学了一些语言模型信息(称为biased internal language model(ILM)),这时候如果想用外部语言模型的分数,内部lm的分数要先减掉,然后才能加外部lm分数,不然就加太多;因此需要知道怎么评估ILM的分数,才能获取该分数。
也可以不减掉这个内部lm分数,但是要尽量让内部lm的bias作用不明显,就是可以用外部lm的训练数据去训练这个内部lm,到时候不需要外部lm,直接用内部lm,也是起到了外部lm参与的效果;
本文的E2E模型是LAS模型;
用了什么方法
两种方法来评估ILM:
- 把LAS decoder里的context vector(AttentionContext )换成参数可学习可更新的vector;
- query vector通过前馈网络映射到context vector,使得context vector不依赖encoder信息(声学信息);
只更新上述两种方法里的参数,LAS其他参数固定不更新,用纯文本训练他们,就相当于训练一个外部LM了,目标函数是最小化perplexity;
[TODO] 方法2. c只来源于文本不需要声学信息,那声学信息在哪里作用??encoder信息不需要了吗。。。
效果如何
在多个数据集上,优于shallow fusion的方法,优于前人的两种Internal Language Model Estimation (ILME) 方法;
没有额外LM参与,没有额外的耗时,保证了RTF不会很大;
应用到我的任务
用conformer encoder+ctc decoder和attention decoder,这里可以把attention decoder全替换成外部lm训练数据训练的lm,
- 用ctc出来n best做rescore(和wenet的attention rescore方法相同,只是attention decoder换了,不需要encoder信息),该方法叫rescore
- shallow fusion,
attention decoder输入的embedding层就用ctc decoder出来的,当blank概率不要很大的帧送进去解码(作为attention decoder的输入embedding层),非自回归(不使用attentiondecoder的输出信息作为下一个符号的输入),然后把ctcdecoder给的全送进去,得到N个V向量,做beam search;