声学模型
==Vaswani, Ashish, et al. “Attention is all you need.” Advances in neural information processing systems 30 (2017).==citations:42175
官方 github tensorflow:https://github.com/tensorflow/tensor2tensor
gihub Chainer:https://github.com/soskek/attention_is_all_you_need
github pytorch:https://github.com/jadore801120/attention-is-all-you-need-pytorch
github tensorflow:https://github.com/Kyubyong/transformer
github:https://github.com/huggingface/transformers
公众号:位置编码在注意机制中的作用
知乎:如何理解Transformer论文中的positional encoding,和三角函数有什么关系?
https://kazemnejad.com/blog/transformer_architecture_positional_encoding/#the-intuition
https://nlp.seas.harvard.edu/2018/04/03/attention.html [待看,据说很好]
解决什么问题
- 提出一种新的序列模型,效果好,简单,没用到RNN/CNN;
- 之前的序列模型想要建模 序列内不同位置的特征之间关系 是 随着特征之间距离远近而计算量大或小的;
用了什么方法
- 改变了以往的序列模型结构,采用了self-attention机制,encoder-decoder,point-wise feedward;
效果如何
- 机器翻译任务 28.4 BLEU on the WMT 2014 Englishto-German translation task;
还存在什么问题
- 由于encoder的attention是注意整个输入,因此非流式
思路
- 提出一种新的简单的序列转换模型(sequence transduction models),Transformer,完全基于注意力机制,没使用递归和卷积;使用stacked self-attention,encoder和decoder只使用position-wise(point-wise)的全连接层;
- Self-attention :是一种将单个序列的不同位置联系起来的注意力机制;
- Transformer结构图:
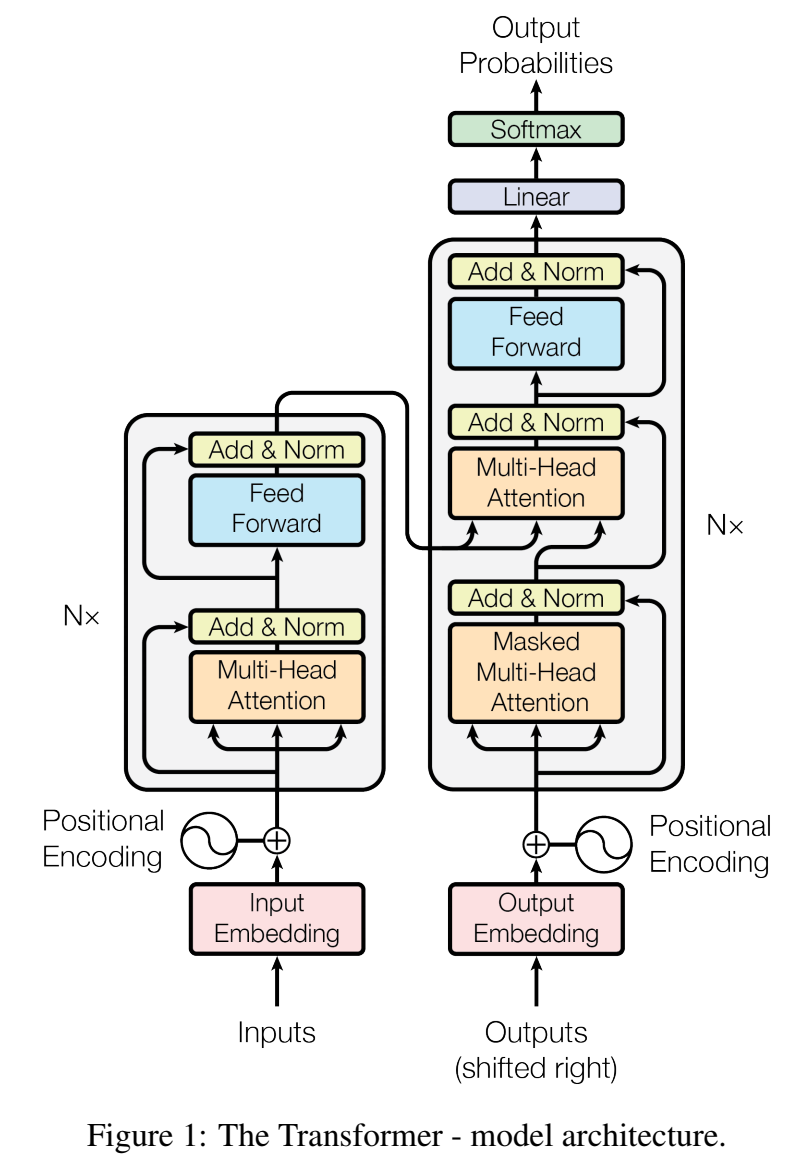
Encoder:input sequence of symbol representations X 到sequence of continuous representations Z 的映射;
- stack堆叠了6层相同的层,每层有两个子层,第一层是多头注意力机制multi-head self-attention mechanism ,第二层是按位置的全连接前馈层 position-wise fully connected feed-forward network ,子层都用了残差结构,残差相加再layernorm层归一化,$LayerNorm(x + Sublayer(x)) $,再embedding,$\large d_{model}=512$,因此encoder输出512维embedding;
Decoder:给定整条Z序列,生成输出序列,一次一个输出,auto-regressive 自回归的;在生成下一个符号时,使用先前生成的符号作为额外的输入
- stack堆叠了6层相同的层,每层有三个子层:
- 第一层是多头注意力机制multi-head self-attention mechanism ,masking:decoder里的attention只关注前面的position信息;
- 第二层对encoder的embedding做多头注意力机制,叫”encoder-decoder attention” layers ,query序列来自上一层的deocder层,key和value来自encoder输出的embedding序列;
- 第三层也是position-wise fully connected feed-forward network,子层都用了残差结构,残差相加再layernorm层归一化;
Attention函数:对于一个输出,是一个query和一组key,value对的映射关系,获得映射关系叫做attention;
- output:value向量的加权和,其中“权重”表示query和key的相关程度;
Scaled Dot-Product Attention :transformer里使用的attention叫按比例点乘(Scaled Dot-Product)的attention;query向量维度 $d_k$ ,key向量维度 $d_k$ , value向量维度 $d_v$ ,
除以$\sqrt{d_k}$ (scaled),对weight用softmax进行标准化;
$\large Attention(Q,K,V)=softmax(\frac{QK^T}{\sqrt{d_k}})V$
其中,$\large Q \in \mathbb{R}^{L_q \times d_k}$ , $\large K \in \mathbb{R}^{L\times d_k}$, $\large V \in \mathbb{R}^{L \times d_v}$
这里Q,K,V对应下面multi-head的Q=qW,下面虽然写的QW,但其实是Q=qW,或者说Q=EW,E是输入,维度是L*d_k
点乘:对应位置相乘,求和 :$\large q\cdot k=\sum_{i=1}^{d_k}q_ik_i$
不加scaled的话,点乘结果会很大,softmax之后,反向传播梯度很小;
输出序列z,其中元素 $z_i \in \mathbb{R}^d$ , 输入序列x,其中元素 $x_i\in \mathbb{R}^d$
对每个元素z_i,是由输入通过线性变换的加权求和得到的:$\large z_i=\sum\limits_{j=1}^n\alpha_{ij}(x_jW^V)$
对每个权重系数,是通过softmax函数计算得到:$\large \alpha_{ij}=\frac{\exp e_{ij}}{\sum_{k=1}^n\exp e_{ik}}$
对每个$e_{ij}$,是通过compatibility function来比较两个输入元素:$\large e_{ij}=\frac{(x_iW^Q)(x_jW^K)^T}{\sqrt{d_z}}$ ,这里的compatibility function用的是Scaled dot product 缩放点乘
$\large W^Q, W^K, W^V \in \mathbb{R}^{d_x\times d_z}$
self-attention:把input 经过三个不同的transform W,得到Q,K,V矩阵,然后Q和K点乘(matmul),softmax得到A’,A’与V矩阵想乘(乘完加)得到输出编码向量O
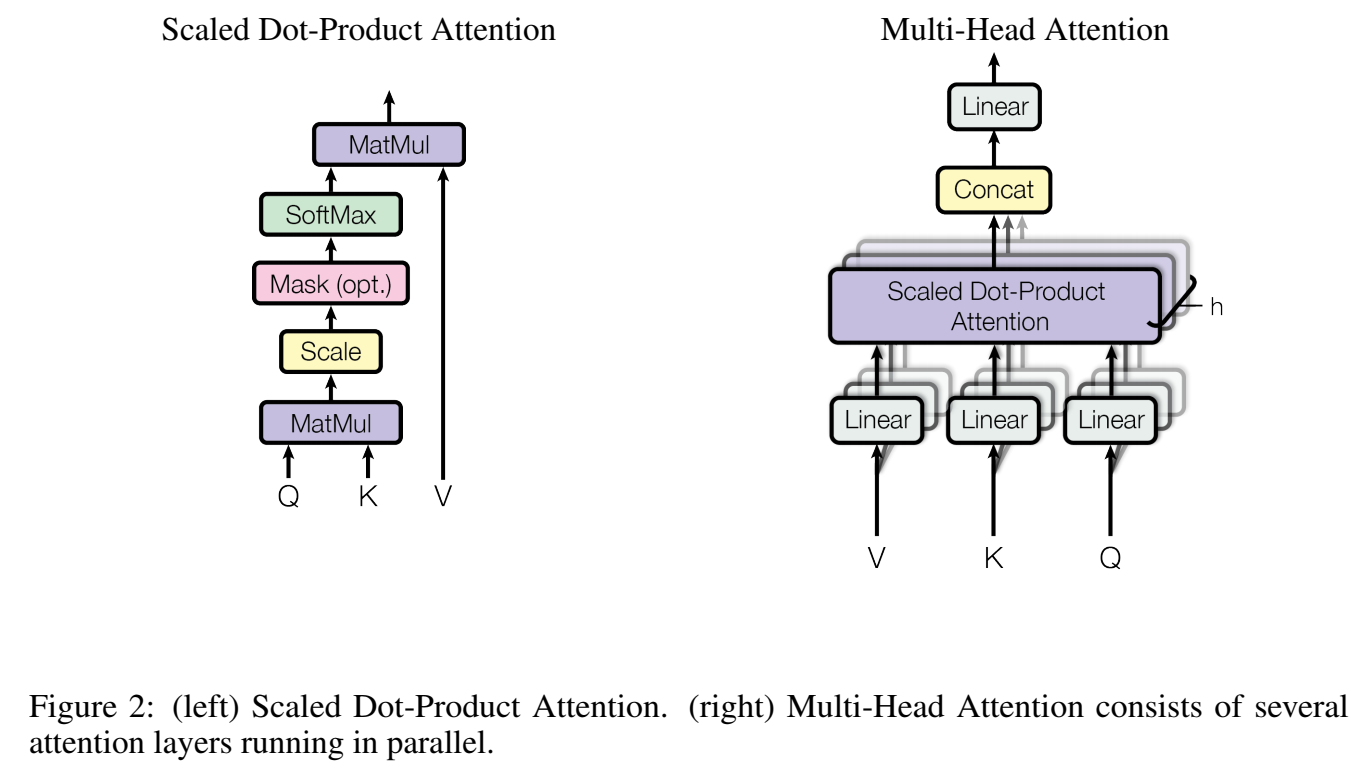
- Multi-Head Attention :

举例,multi分开,和只用一个大矩阵确实是不同的:
1 | import torch |
Position-wise Feed-Forward Networks :由两个线性层组成,中间的激活函数用relu,不同位置的输入作用都是一样的(就是位置无关),逐位置,
- $\large FFN(x) = \max(0; xW_1 + b_1)W_2 + b_2 $
- 输入输出维度都是512,神经元结点2048;

- Feed Forward Module作用:
- 非线性变换,强化模型的表达能力
- 输入映射到高维再映射到低维,模型学习到更加抽象的特征
Embeddings and Softmax :在embedding层,权重乘以$\sqrt {d_{model}}$
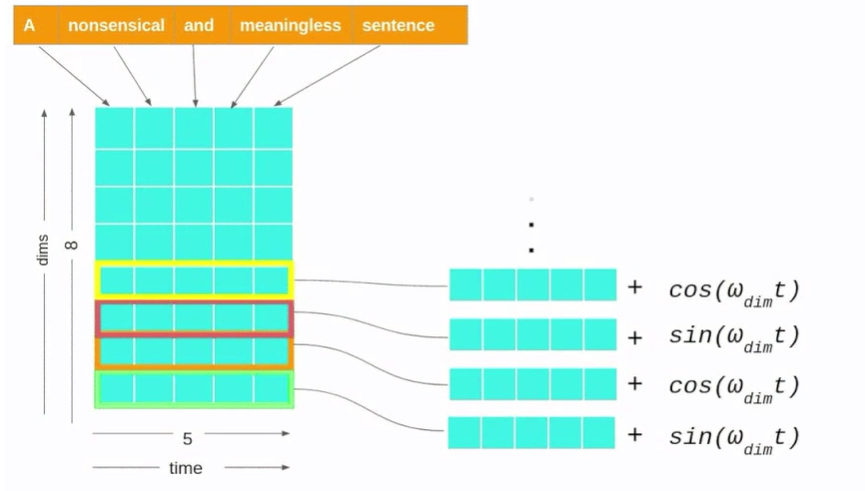
Positional Encoding :序列模型要有序列性(就是要有个顺序),而attention是当前帧和其他所有帧点乘,因此其它帧的相对位置信息,attention是考虑不到的,因此要加上位置编码来表示位置信息;
Positional Encoding和token embedding相加,作为encoder和decoder的底部输入。Positional Encoding和embedding具有同样的维度$d_{model}$,因此这两者可以直接相加。
$\large PE_{(pos,2i)}=sin(pos/10000^{2i/d_{model}})$
$\large PE_{(pos,2i+1)}=cos(pos/10000^{2i/d_{model}})$
其中,i是第i维 $i\in[0,d_{model}/2)$;pos表示token在序列中的位置,比如第一个token就是0;
每一维做的操作不一样(sin或cos)
比如:第二个token,即PE(1),有$d_{model}$维,比如是512维,表示为:$PE(1)=[sin(1/10000^0),cos(1/10000^0),sin(1/10000^{2/512}),cos(1/10000^{2/512}),…]$
出发点是三角函数 $sin(a+b) = sin(a)cos(b) + cos(b)sin(a)$, b 是一个固定的 offset 也就是常数了,所以 pos+k 的编码就可以通过 pos 的编码来线性表示了。不同位置就是同一个频率的不同相位。

每一组单位向量会随着 pos 的增大而旋转,但是旋转周期不同,按照论文里面的设置,最小的旋转周期是 2pi,最大的旋转周期是 10000 x 2pi。把 position 表示成多组不同旋转周期的单位向量,能有助于泛化到训练时没有见过的长度;
训练的loss:输出符号与真实标签的cross entropy;训练时decoder输入:真实标签groundtruth;输出是词表vocabulary的大小
测试时decoder输入:一开始BEIGIN符号,然后一个输出;
把第一个输出作为第二个输入,得到第二个输出;
把第二个输出作为第三个输入,得到第三个输出……绝对位置编码中,Q、K、V都要加位置编码
复杂度比较:

抽象
self attention:相比 recurrent 不存在梯度消失问题,这点显然。对比 CNN 更加适合文本,因为能够看到更远距离的信息,这点展开说明——因为文本语义的抽象不同于图像语义的抽象,后者看下一层的局部就行,前者经常需要看很远的地方。比如现在 “苹果” 这个词我要对它做一个抽象,按 “苹果公司” 抽象还是按 “水果” 抽象呢?这个选择可能依赖于几十个 step 之外的词。诚然,CNN 叠高了之后可以看到很远的地方,但是 CNN 本来需要等到很高层的时候才能完成的抽象,self attention 在很底层的时候就可以做到,这无疑是非常巨大的优势。
RNN是指不同 step 之间要顺序执行从影响速度的 recurrence。而这个 decoder 每一层对不同位置的计算是并行的。当前位置的计算不依赖前面位置的计算结果。 当然这也是因为他使用的是 ground truth 做输入,砍掉相邻两步之间 hidden state 这条连接了。 为了并行, 模型的灵活性受到了限制。不过,在测试阶段 decode 下一个词依赖于上一个输出,所以仍然是 recurrence 的。
==Chorowski, Jan K., et al. “Attention-based models for speech recognition.” Advances in neural information processing systems 28 (2015).==citations:2267
解决什么问题
- attention用在语音识别任务里效果不好的问题;机器翻译的注意力机制模型 直接用来做语音识别任务时,会出现只对训练集类似的话才识别得好 的问题、它只适用于track跟踪它所识别的内容在输入序列中的绝对位置absolute localtion;
用了什么方法
- 在注意力机制中引入location-awareness;2. 改变注意力机制,防止它过多地注意在单个帧上;
效果如何
- 引入location-awareness,PER从18.7%下降到18%;防止只注意单帧,PER下降到17.6%
还存在什么问题
-
论文思路
为什么机器翻译和手写识别的attention不能直接用与语音识别任务:
- 机器翻译和语音识别任务的区别:机器翻译的输入长度短(只有几十个词),识别是几千帧,因此很多语音片段是相似的,区分它们是一个挑战;
- 手写识别和语音识别任务的区别:笔迹和背景区分明显,“噪声小”,语音识别的背景噪声可能很大,信噪比低,没有清晰的结构;
- 因此对识别任务的attention model的要求是:能够处理长输入和带噪输入;
机器翻译模型直接用于语音识别任务会带来的问题:
- 长句子错误率高;
- 只适用于跟踪它所识别的内容在输入序列中的绝对位置;因此短句尚可,对于长句不可行;
修改注意力机制:
- 目的:使之能够注意到:1)前一个step的焦点位置(the location of the focus from the previous step )、2)输入序列的特征(the features of the input sequence)
- 如何实现:在注意力机制的输入中,添加辅助卷积特征;该卷积特征是从对前一个step的attention权重进行卷积而来的;(location awareness)
早期的注意力机制公式:
- content-based 注意力机制:$\large \alpha_i=Attend(s_{i-1},h)$
**Attend **操作:对h中的每个元素分别打分并将分数标准化:$\large e_{i,j}=Score(s_{i-1},h_j)$、 $\large \alpha_{i,j}=exp(e_{i,j})/\sum\limits_{j=1}^Lexp(e_{i,j})$
可以看出,在不同位置处的$h_j$如果元素值很相似,score分数会很接近,这就是相似语音片段“similar speech fragments” 问题,该问题可通过encoder用 BiRNN,或编码了h的上下文信息的CNN来缓解;但是h能力有限,因此通过上下文进行消歧的可能性是有限的;
因此,提出 location-based 注意力机制来缓解没考虑h位置的问题:
- location-based 注意力机制:$\large \alpha_i=Attend(s_{i-1},\alpha_{i-1})$
但是,这样也有问题,没依赖输入h,只依赖s,这样得到的距离信息方差很大;
因此,提出混合location和content的注意力机制:
- hybrid 注意力机制:$\large \alpha_i=Attend(s_{i-1},\alpha_{i-1},h)$
使用前一个的对齐$\alpha_{i−1}$从h中选择一个短的元素列表(content-based attention );
获得注意力机制权重后,神经网络的走向:
$\large g_i=\sum\limits_{j=1}^L\alpha_{i,j}h_j$
$\large y_i \sim Generate(s_{i-1},g_i)$
$\large s_i=Recurrency(s_{i-1},g_i,y_i)$
其中,$\alpha_i \in R^L$ 是attention权重,称为alignment;$g_i$ :glimpse;Recurrency 为GRU或LSTM;
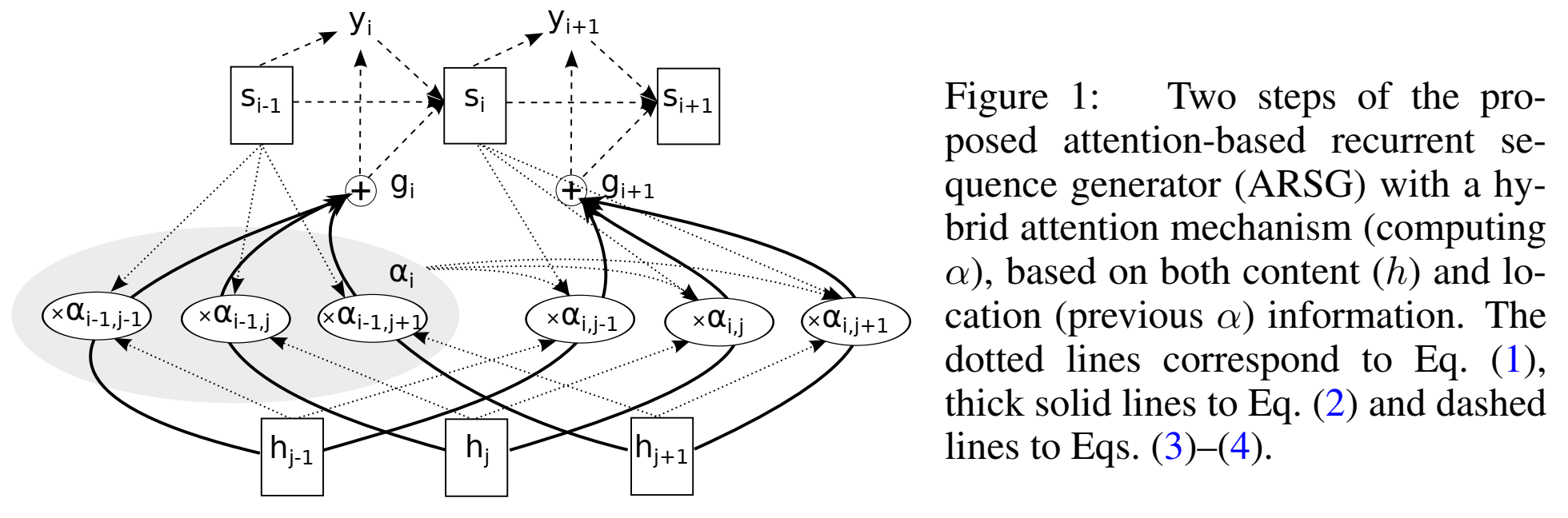
attention-based recurrent sequence generator (ARSG)with Convolutional Features :
content-based注意力机制的 score 操作:$\large e_{i,j}=Score(s_{i-1},h_j)=w^Ttanh(Ws_{i-1}+Vh_j)+b$
将content-based扩展为location-aware:通过考虑前一个step的alignment $\alpha_{i-1}$:对previous alignment $\alpha_{i-1}$的每个位置 $j$ ,通过与矩阵$F$卷积($F\in R^{k \times r}$),来提取 $k$ 向量($\large f_{i,j}\in R^k$):
$\large f_i=F*\alpha_{i-1}$
因此hybrid的 score 操作为:$\large e_{i,j}=Score(s_{i-1},\alpha_{i-1},h)=w^Ttanh(Ws_{i-1}+Vh_j+Uf_{i,j})+b$
Score Normalization: Sharpening and Smoothing
score操作完,标准化后得到权重α,但是这个标准化 $\large \alpha_{i,j}=exp(e_{i,j})/\sum\limits_{j=1}^Lexp(e_{i,j})$ 有几个问题:
- $h$ 序列很长时,$g_i$会更容易从无关 $h_j$ 获得信息,就是噪声信息了,(因为score $\alpha_{i,j}$总为正数且和为1),这样对于每一帧 $i$ ,都会更不容易关注到与 $i$ 真正相关的帧信息;
- $h$ 序列很长时,计算复杂度会显得很大,注意力机制每帧都要考虑所有帧,$O(LT)$;
但是用softmax标准化的好处是会只关注于单个特征向量$h_j$,而不是多个不同 j 的h;
解决noisy glimpse方法:通过 Sharpening 化,锐化,具体实现的方法有:
- 方法1:让$\alpha$分布更极端,区分更大;通过引入inverse temperature β > 1
$\large \alpha_{i,j}=exp(\beta e_{i,j})/\sum\limits_{j=1}^Lexp(\beta e_{i,j})$
或者keep only the top-k frames according to the scores and re-normalize them ,但是复杂度没下降,还可能会更关注更窄的帧;
- 方法2:windows attention机制:只看窗口长度的h:$\large \tilde h=(h_{p_i-w,…h_{p_i+w-1}})$ ,复杂度$O(L+T)$;训练和推理阶段都能用;
Sharpening对长句子有效,但是也会降低短句子性能,这个现象,论文作者认为,假设Sharpening的作用是有助于模型从多个得分最高的帧中进行选择。。。。
把无界的exp函数换成有界的sigmoid函数:称为 smoothing 化:
- Smoothing : $\large \alpha_{i,j}=\sigma(e_{i,j}/\sum\limits_{j=1}^L\sigma(e_{i,j}))$
实验
- 建模单元phoneme,61个phone,一个eos token,39?
- Timit数据集,这个数据集都是很短的小于5s,测试时会特地把音频拼接构造长句子,输入特征40维,一阶二阶差分120维,3维能量,共123维;
- 不同的参数子集被重复使用的次数不同; 编码器的为T次,注意权重为LT, ARSG的所有其他参数为L次。 这使得导数的尺度变化很大,因此用自适应学习率算法AdaDelta优化器(两个超参$\epsilon$和$\rho$)
- 初始化为标准差0.01的高斯分布,RNN进一步正交初始化;
- batchsize=1!由于TIMIT数据集很小,一开始加正则,后面没加正则;100K参数量;
- encoder:3层 Bi GRU,256结点;encoder输出 h:512维;generator :单层 GRU,256结点,输出64维?;
结果
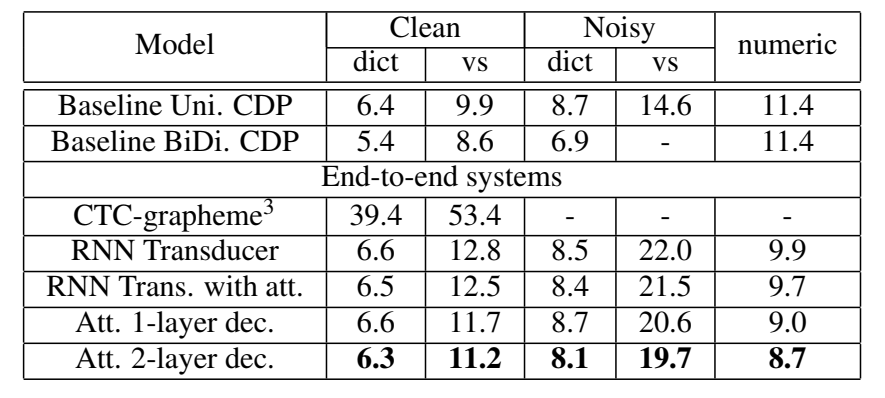
不同模型结果:
baseline其实并不差,并且也能学到对齐信息,

锐化里windows方法对齐效果最好:
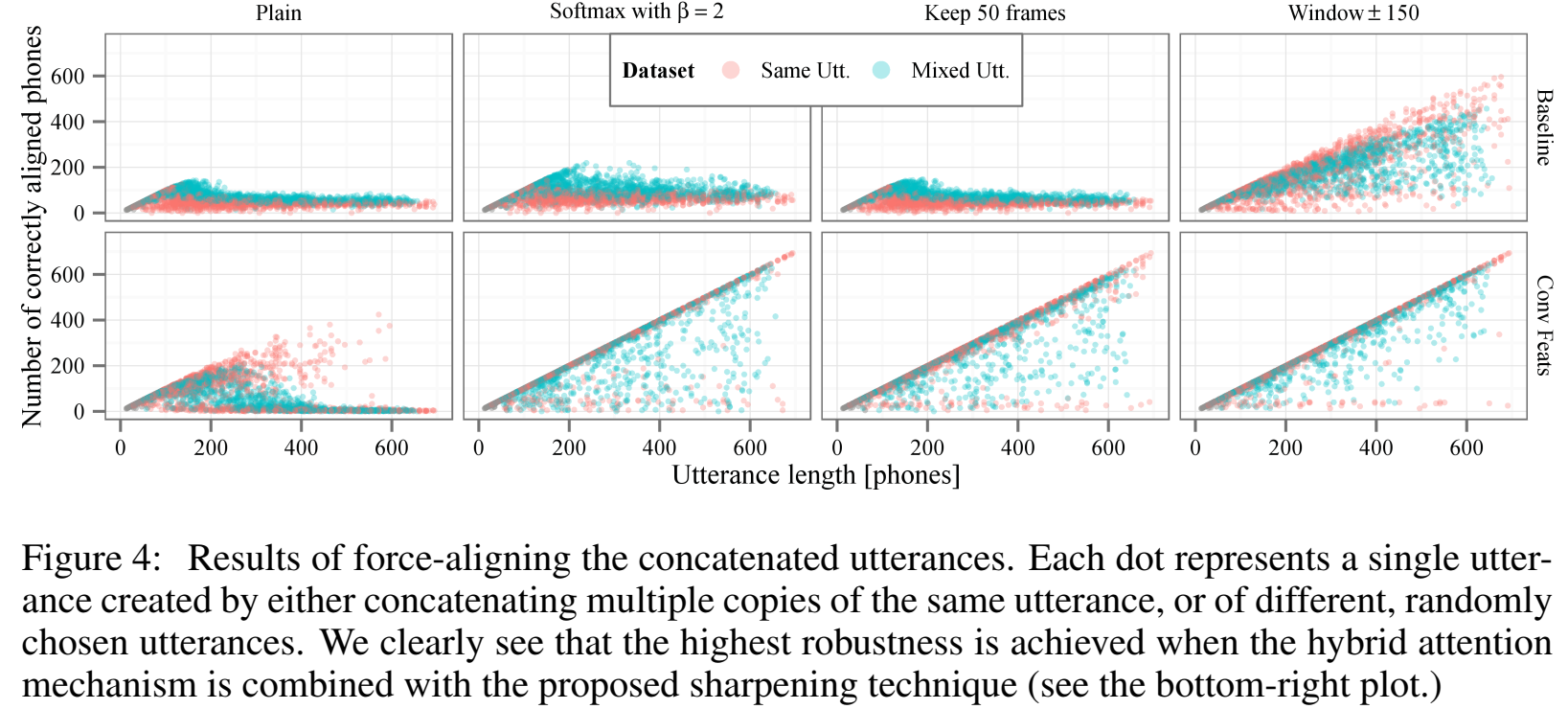
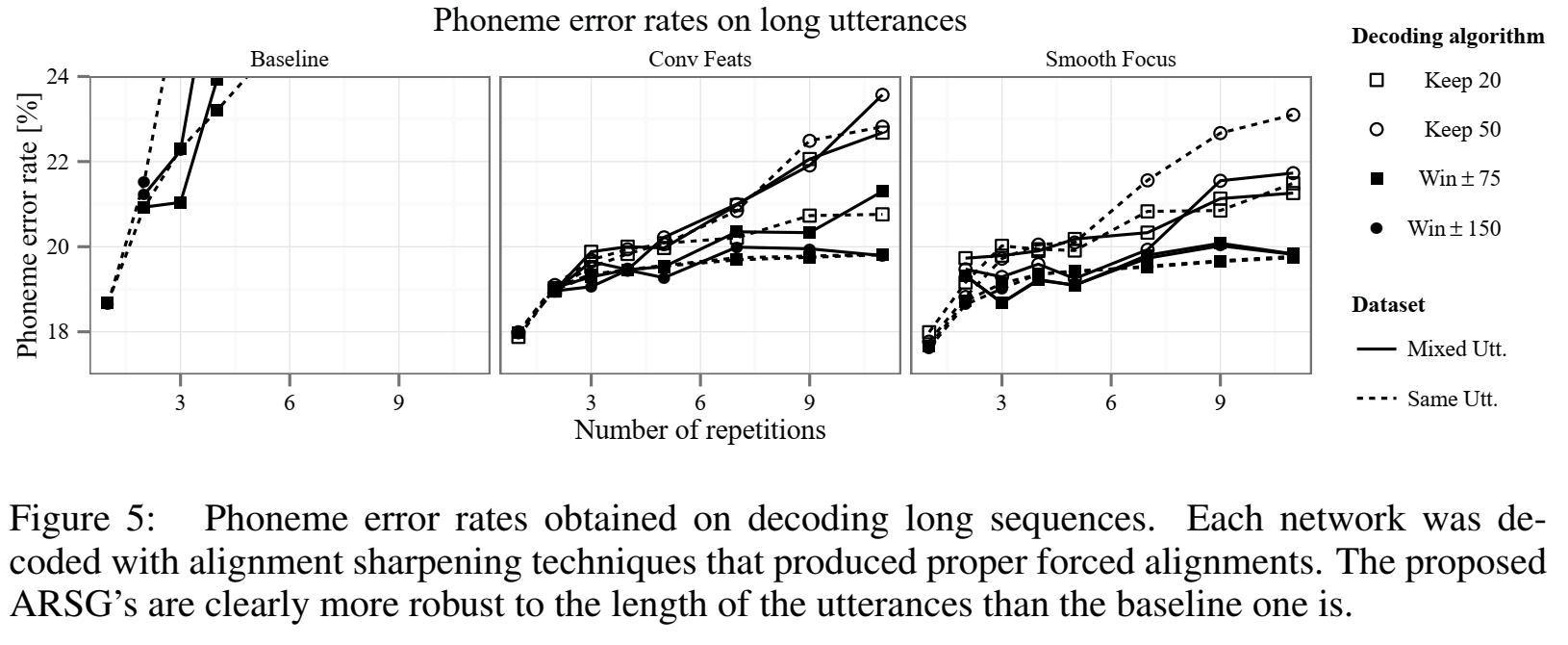
对于repeat phone:
==Prabhavalkar, Rohit, et al. “A Comparison of Sequence-to-Sequence Models for Speech Recognition.” Interspeech. 2017.== google citations:268
解决什么问题
- 比较了识别模型的性能,对比了多个端到端模型在识别任务的性能;
用了什么方法
- 不同模型都以字母建模,CTC、RNN-T、attention based、RNNT with attention的端到端识别模型,不加LM;
效果如何
- 在口述测试集、数值测试集优于baseline,但在有较多专有名词的问答搜索测试集,会比basline差;
- 总的来说只用字母建模,没有用语言模型,这个声学模型的建模能力还是非常牛逼的;
还存在什么问题
- 端到端模型与LM的结合实验;
论文思路
比较CTC、RNN-T、attention based、RNNT with attention的端到端识别模型,(比较时它们都是用grapheme字母建模,没有词典、lm)
attention based依赖LM,否则在不同数据集上表现差异很大
发现端到端模型可以隐式学习从口语到书面形式的映射(比如说”one hundred dollars” 能输出 “$100”)(以前这种问题更多是用正则做的)
端到端模型结构:
- RNNT:可流式识别,但用双向encoder,就不流式了;
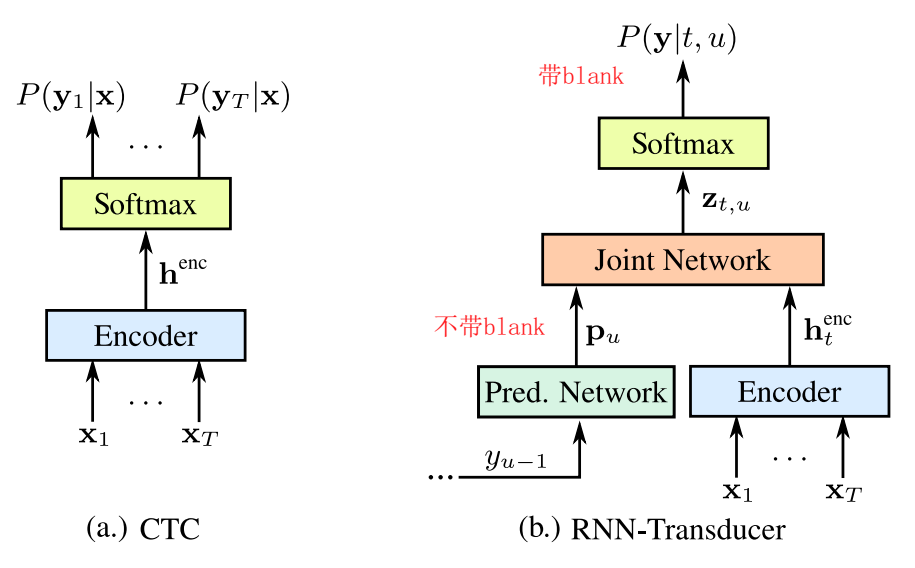
- attention-based:比如las、
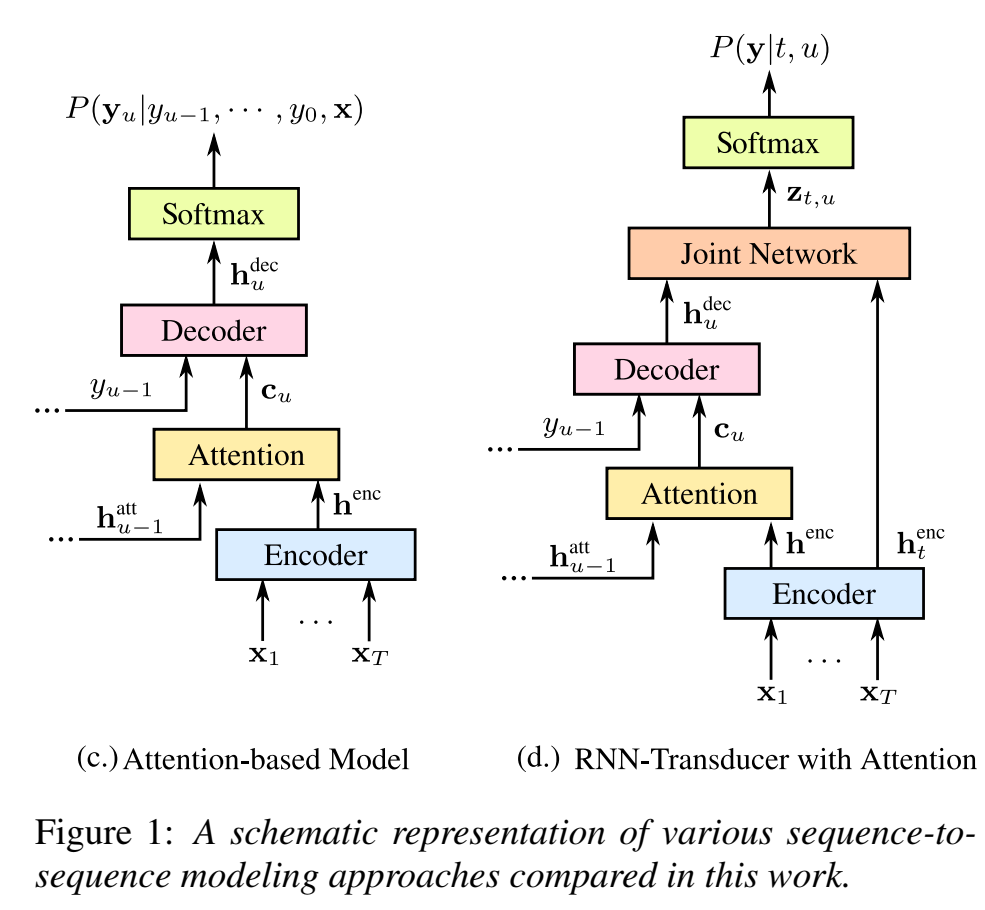
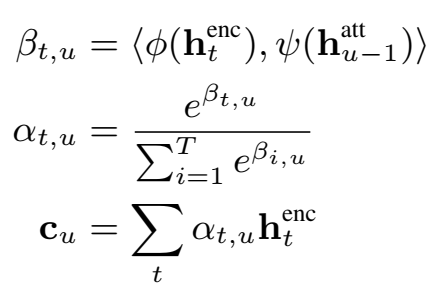 - RNN Transducer with Attention :把RNN-T里的prediction network换成las里的attention decoder;和las相同,要添加sos和eos label,
- RNN Transducer with Attention :把RNN-T里的prediction network换成las里的attention decoder;和las相同,要添加sos和eos label,
实验
- 数据集:12500 h
- 数据扩展(即使1w小时了也还要数据扩展)目的是对噪声和混响更robust:生成multicondition training (MTR) data:distorted using a room simulator 、by adding in noise samples extracted from YouTube videos and environmental recordings of daily events 、
- the overall SNR is between 0dB and 30dB, with an average of 12dB ,信噪比不低于0dB,不高于30dB,平均12dB
- log-mel 特征80维,25ms帧长,10ms帧移,送给模型时下采样3倍,
- 标签:26个字母a-z,10个数字0-9,空格,标签符号
- ctc:encoder:5层 blstm,350结点(700结点),用这个训好(收敛了)的encoder权重,作为其他端到端模型的初始权重,这可以加速其他模型的收敛;
- rnnt:encoder和上同,prediction network 单层gru,700结点;joint network 单层前馈网络,700结点,tanh激活函数;解码 beam search 的beam=15
- attention-based :decoder:一或两层gru,700结点;
- baseline:ctc模型,训好用smbr再训,8192 CD phonemes,解码:pruned, first-pass, 5-gram language model ,再用更大的5-gramLM进行rescore ;词典 包含百万个词
- RNN-T剪枝是走了t步剪枝(frame-synchronous decoding);attention剪枝是输出u个符号剪枝(label-synchronous decoding)
- 为了防止attention-based模型输出非常短的话语,只有当模型输出一个概率大于阈值的
标签时,才允许终止下一个标签预测过程;
结果
- CTC直接解码字母时,不接语言模型会非常差
- 这样看来attention-based model效果比RNNT好
- 在numeric 测试集(从口语映射到书面领域),attention和rnnt相比于baseline有明显改善,认为 the ability to examine the input acoustics in addition to the previous sequence of predicted tokens is particularly helpful
- 在voice-search 测试集,比baseline差,分析是因为没加LM;
- 发现端到端模型很难识别专有名词proper nouns (比如地名、实体名)