端到端识别方案
==Yao, Zhuoyuan, et al. “Wenet: Production oriented streaming and non-streaming end-to-end speech recognition toolkit.” arXiv preprint arXiv:2102.01547 (2021).==
github:https://github.com/mobvoi/wenet
chao yang :Wenet网络设计与实现
思路
提出识别框架Wenet
解决流式非流式问题方法:用dynamic chunk-based attention策略,提出two-pass方法框架(U2,a unified two-pass joint CTC/AED model )解决流式非流式的统一 (unifying streaming and non-streaming modes)
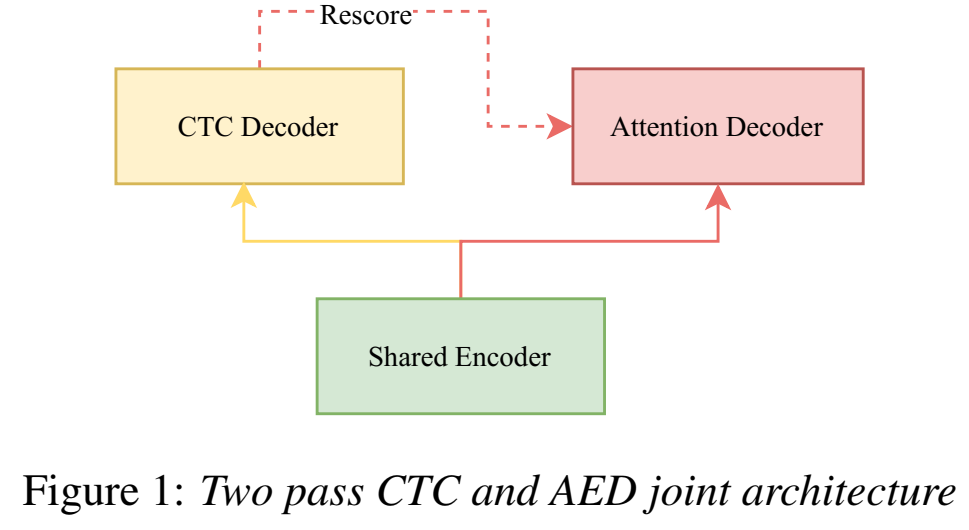
U2:
- Shared Encoder :多个Transformer和Conformer(只看右context),只看部分输入音频特征长度,因此可以流式;
- CTC Decoder:线性层,CTC loss;
- Attention Decoder:多个Transformer decoder层;
- rescore解码过程:CTC Decoder流式进行一遍解码,Attention Decoder进行第二遍解码;attention rescoring :CTC prefix beam search输出n-best候选路径,n-best和encoder通过AED decoder得到output,这里n-best(没有blank了)是作为decoder的输入序列(类似于训练时的label序列,可以并行,一次到位,不需要输出作用到下一个输入);
- rescore:
- aed的输出并没有用什么beam search,而是直接取和ctc n-best对应位置相同的路径分数
- aed输出的第n条序列分数为:==对应ctc 第n条路径分数 * ctc_weight + 在ctc第n条作为输入的前提下 aed的输出的路径分数==(recore 分数)
- 可能aed rescore的作用是用来校正ctc的n-best的,既然前提是在ctc n-best空间范围内重新选一条,所以ctc n-best一定是很有说服力的;
训练
Joint CTC/AED training:
- Loss function:$\large L_{combined}(x,y) = \lambda L_ {CTC}(x,y) + (1-\lambda) L_{AED} (x,y)$
- 优势:加快收敛,提高训练稳定性,得到更好识别结果
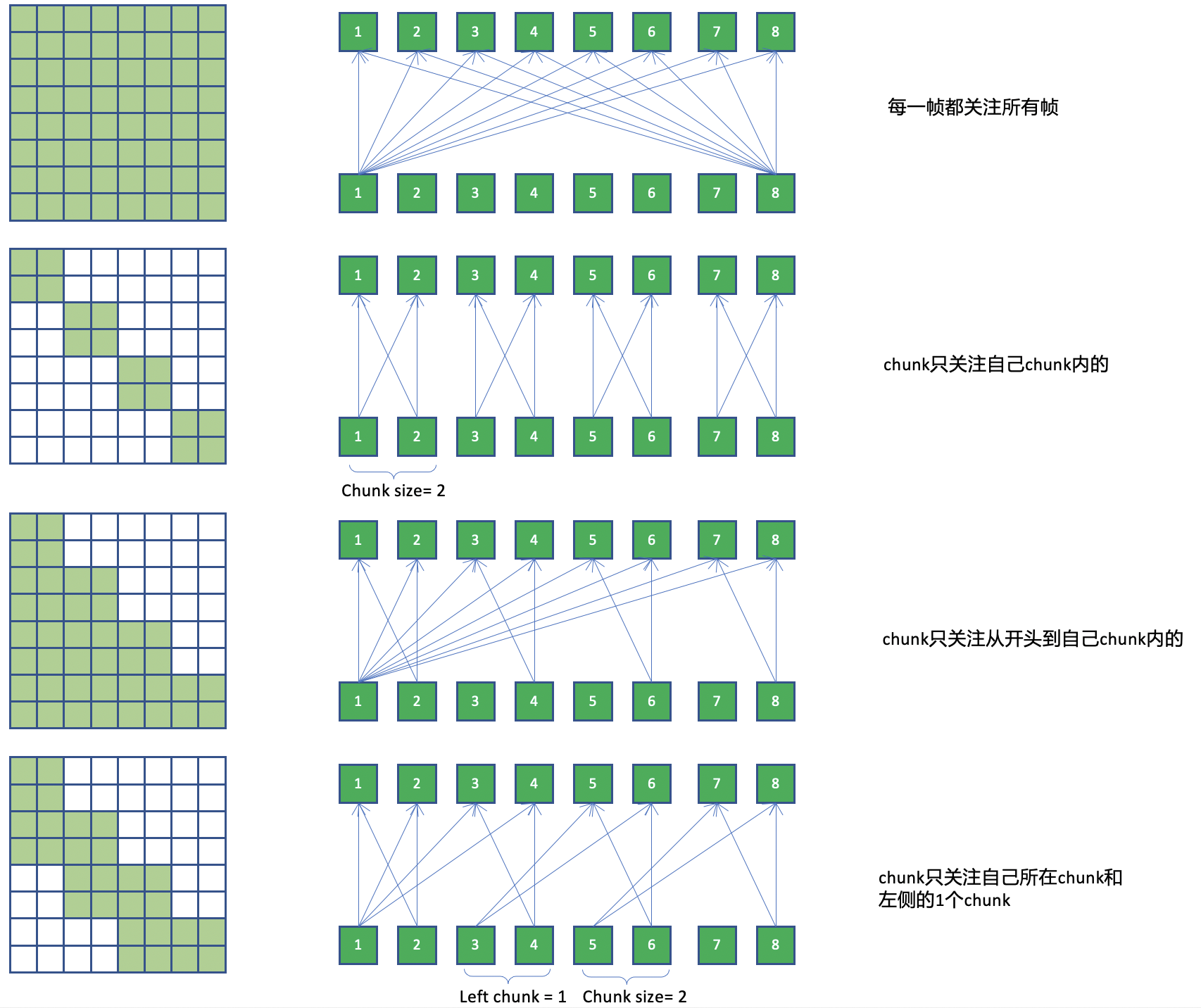
dynamic chunk training :
- 训练时每个chunk里,只能看见从音频开头到当前chunk尾的长度信息;chunk大小是随机数,让模型学会预测任意长度chunk输出
- chunk是帧数(这里的帧按下采样后的帧),基于chunk的attention,本质上是去限制attention的作用范围,可以通过attention mask来实现。(QK后接mask后得score,再softmax)
- 优势:实现了流式
系统设计
- 训练:
- TorchScript 用来开发models;
- Torchaudio 用来即时on-the-fly特征抽取;
- Distributed Data Parallel (DDP)用来分布式训练;
- 部署:
- torch Just In Time (JIT) 用来导出模型;
- PyTorch quantization 用来量化模型;
- LibTorch 用来上线使用 production runtime;
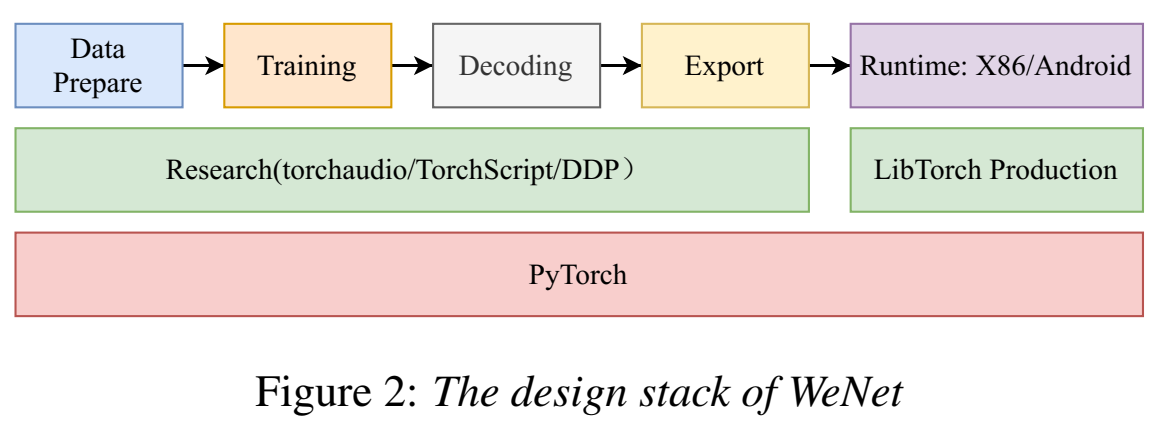
- Runtime
- x86 as server runtime
- Android as on-device runtime
实验
- 数据集:aishell-1,150h train,10h dev,5h test;
- 特征:80维mfcc,25ms帧长,10ms帧移,specaugment(numf=2,F=10,numt=2,F=50)用来防止过拟合;
- 特征先经过两层3* 3 kernel,stride=2的卷积,进行下采样,再送入encoder;
- encoder:12个transformer层;decoder:6个transformer层;
- 25000步warm-up,adam优化器;
- average top-K 最低cv_loss作为最终模型;
- 可以用简单的2gram phone lm代替ctc n-best给attention用吗?????
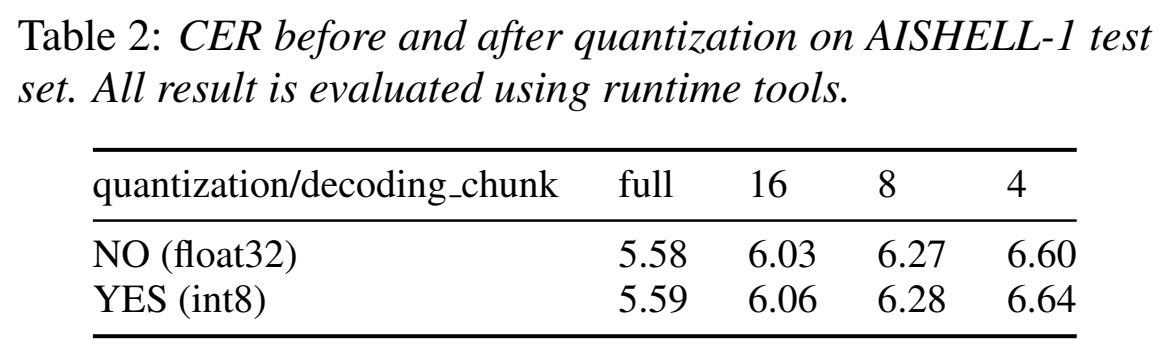
- CER结果:
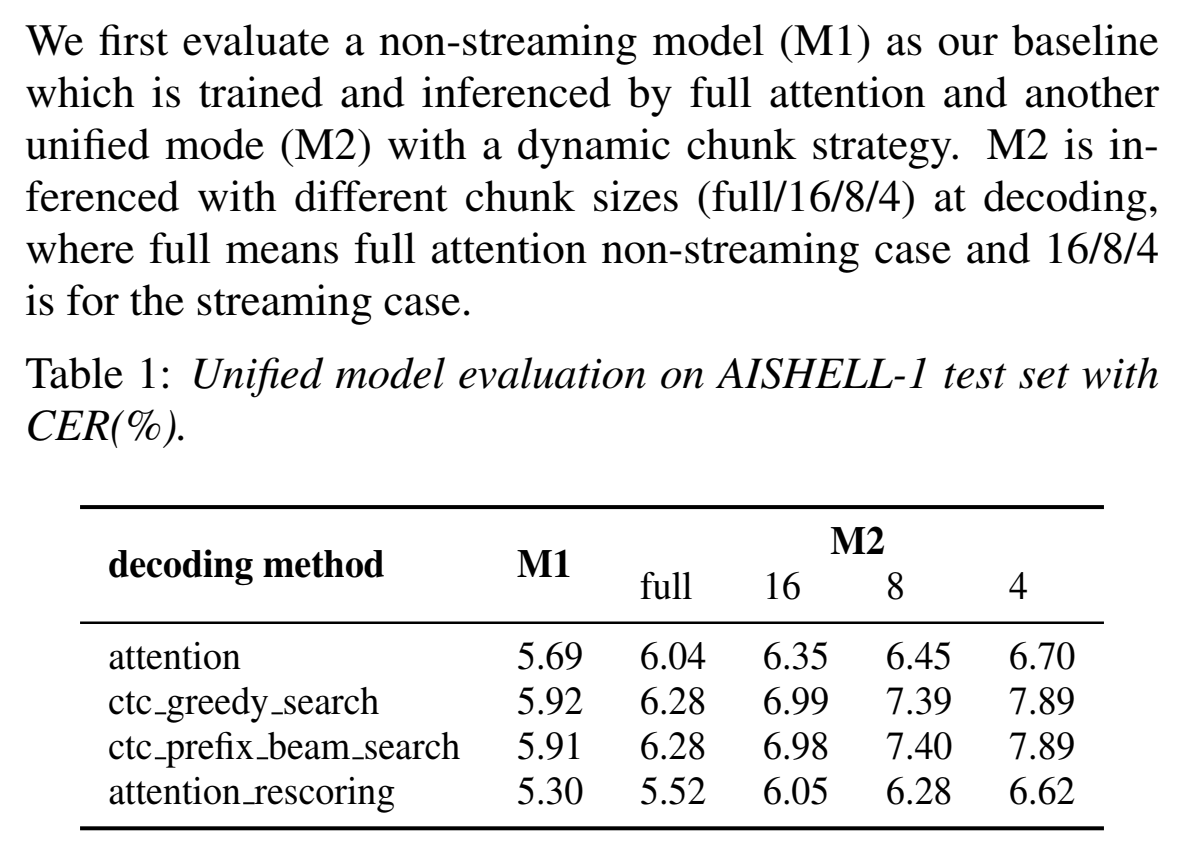
- 量化CER对比:可以看出错误率很差得很小
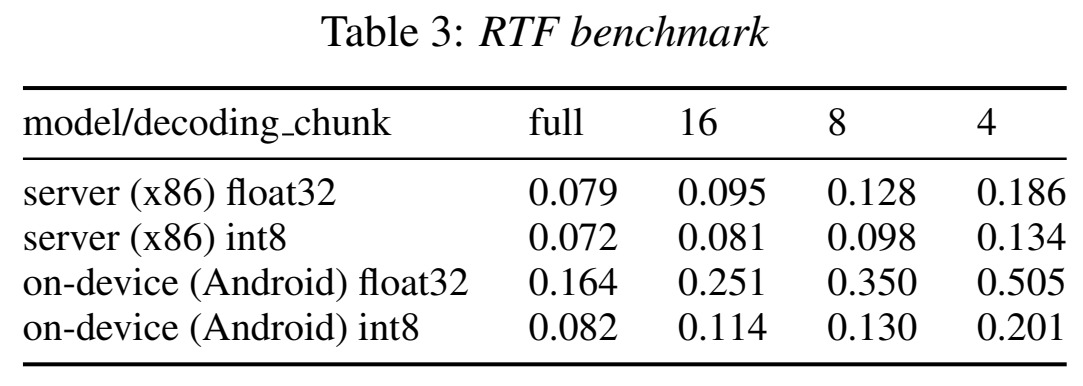
- RTF:可以看出实时率很不错
- 更小的chunk反而有更高的RTF,因为一条音频分的chunk数变多了,前向计算的次数变多了(chunk越小的好处是时延小);
- 在安卓端上,量化会带来速度的两倍提升;但在x86服务端上提升不大;
- Latency
- 通过构造WebSocket server/client 来仿真测试真实流式应用,来评估时延;
- model latency:由于等待模型计算而引入的延迟,计算为 $(chunk/2 * 4 + 6)*10(ms)$,4是下采样率,6是一开始两层cnn要lookahead一些帧(6帧),10是帧移;
- rescoring cost,二遍解码的延迟;
- final latency,用户感受到的时延,是从用户停止说话 到 得到识别结果 之间的时长
- 接收到用户停止发语音后,发送到ctc decoder拿到ctc的n-best,给attention decoder;
- 网络延迟未考虑(因为测试时server/client在同一台机子)

实验2
- 数据集15,000-hour (1.5w小时)普通话数据
- 累计4个步长的梯度,才更新,能更稳定地训练
- 分析attention rescore对于长音频会有优势(大于5s)
==Zhang, Binbin, et al. “WeNet 2.0: More Productive End-to-End Speech Recognition Toolkit.” arXiv preprint arXiv:2203.15455 (2022).==
思路
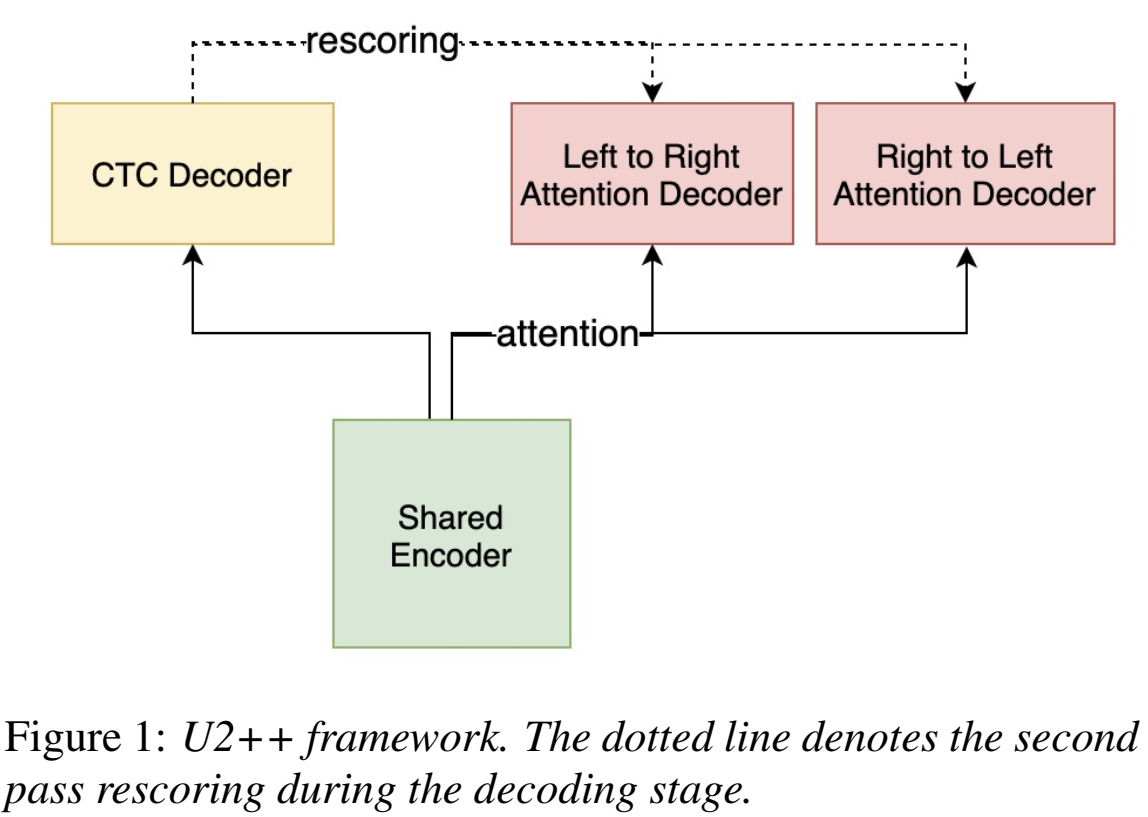
- 为了提高ASR识别率,提出U2++(通过双向attention decoder来统一two-pass的框架),
- 训练阶段:双向 从后往前的attention decoder使得获得未来一段时间的信息,
- 解码阶段:结合从前和从后的预测结果
- 改善了shared encoder,并提高rescore的识别率(比单向提高10%);
- U2++框架:a unified two-pass joint CTC/AED framework
- Shared Encoder:给声学特征建模,由多个transformer或conformer组成,only takes limited right contexts into account to keep a balanced latency
- CTC Decoder:建模声学特征和token单元的帧级别对齐,由一个线性层组成,which transforms the Shared Encoder output to the CTC activation
- Attention Decoder:
- Left-to-Right Attention Decoder (L2R) :models the ordered token sequence from left to right to represent the past contextual information.
- A Right-to-Left Attention Decoder (R2L) :models the reversed token sequence from right to left to represent the future contextual information.
- The L2R and R2L Attention Decoders consist of multiple Transformer decoder layers.
- 用一个超参数调节二者的loss比例:$L_{AED}(x,y)=(1-\alpha)L_{L2R}(x,y)+\alpha L_{R2L}(x,y)$
- 在dynamic chunk训练里,chunk给特征都是从前往后给的,然后L2R对现有的chunk从前往后做,R2L是从后往前做;
- two pass:During the decoding stage, the CTC Decoder runs in the streaming mode in the first pass and the L2R and R2L Attention Decoders do rescore in the non-streaming mode to improve the performance in the second pass.
- N-gram Language Model :在Wenet2.0中引入了基于wfst的n-gram语言模型;在CTC解码中加入,提高8%
- (雷博说)对于垂直领域,训练lm用的通用文本 + 一些垂直领域文本
- TLG:compiles the n-gram LM (G), lexicon (L), and end-to-end modeling CTC topology (T) into a WFST-based decoding graph (TLG) $TLG=T\circ min(det(L\circ G))$
- denoted as CTC WFST beam search in the WeNet 2.0
- To speedup decoding, blank frame skipping technique is adopted (参考”Phone synchronous decoding with ctc lattice”)
- 用n-gram进行语言模型训练,这是因为更符合工业使用
- 解码时为了加速解码,blank符号概率大于0.98的,跳过该帧,就是说 不考虑很可能是blank的帧的概率,可以加速解码,因为blank其实没啥用;

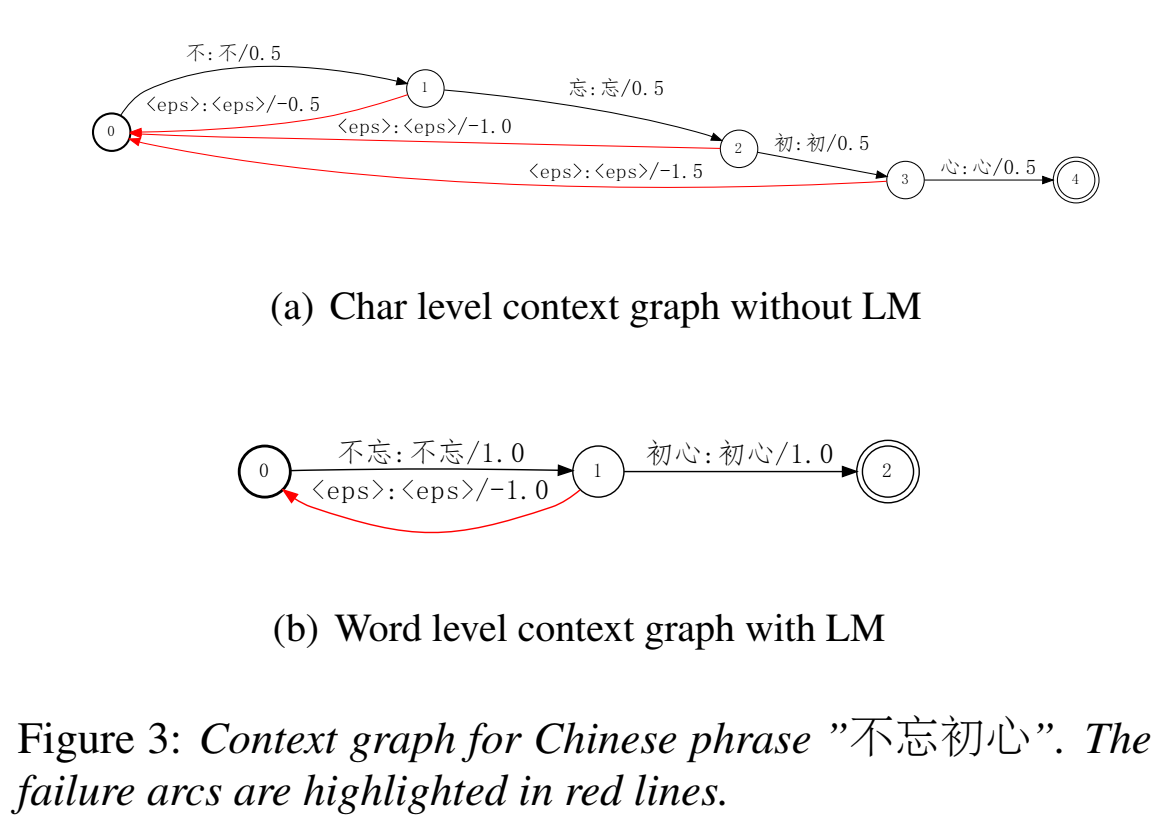
Contextual Biasing :设计了一种联合contextual biasing框架,更适配特定语境,比如通讯录;【TODO 看三篇论文】
(雷博说)contextual bias是为了解决 ==热词== 问题,用来生成一些热词,但是权重需要经验构造,不是一个非常靠谱的方案;
在解码中用,有LM和没有LM的解码过程都可以引入,从而适配语境
已知biasing phrases短语,实时构建contextual wfst图;首先,biasing phrases通过词典或模型拆分成biasing unit,把biasing unit的arc权重提高
a special failure arc with a negative accumulated boosted score is added ,当只匹配部分bias unit而不是整个bias phrase时,失败弧用于move提高的权重
(也就是加一条空边(有权重)的弧回去,平衡这个提高的权重)
$\large y^*=arg\max\limits_y logP(y|x) + \lambda logP_C(y)$,其中$P_C(y)$ 是bias score
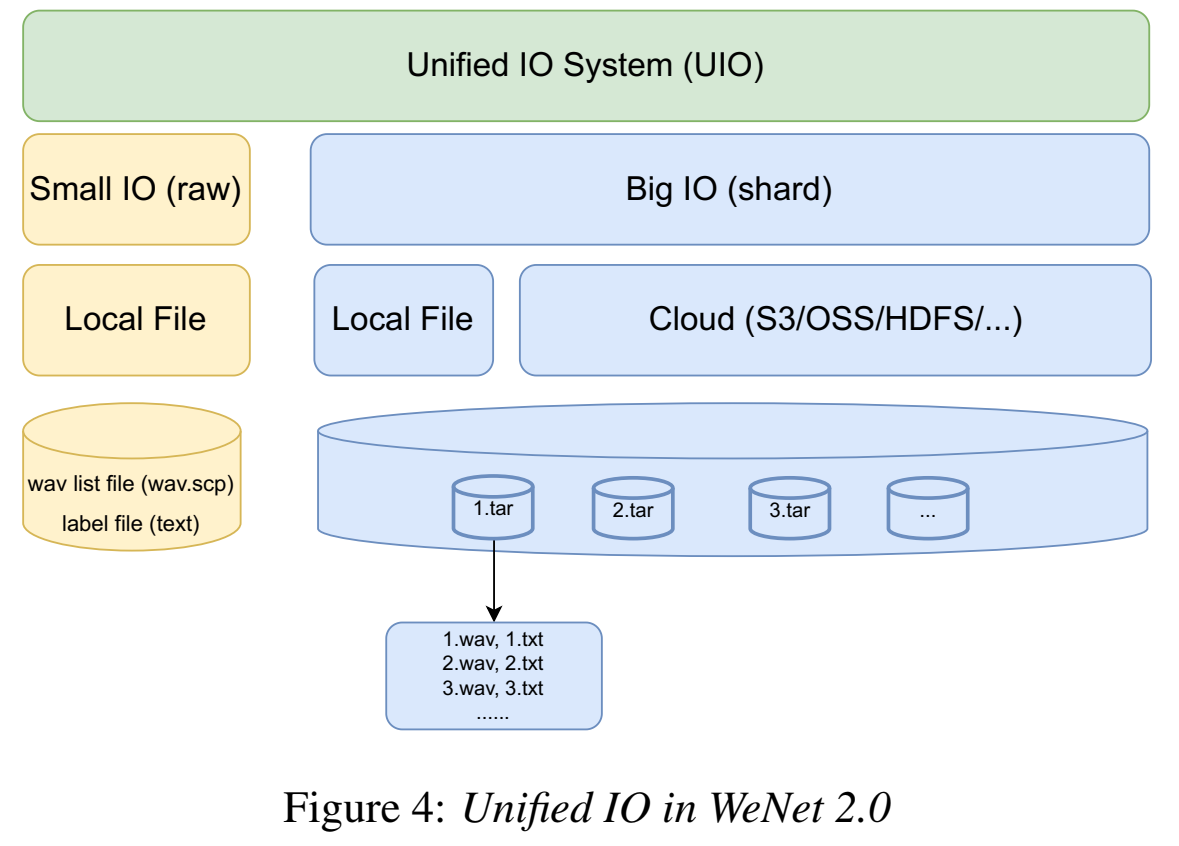
- 设计了一种联合Unified IO(UIO)来支持大规模数据训练
- 对于小数据集,UIO随机访问样本;
- 对于大数据集,UIO先把样本聚集在一个块里(类似kaldi的egs)(tar压缩,压缩是为了防止OOM),之后训练、随机访问的就是这个块shard(解压来训练)
- inspired by TFReord (Tensorflow) and AIStore
- https://wenet.org.cn/wenet/UIO.html
- Chain IO [TODO]
训练
- dynamic chunk值选取:在均匀分布$C \sim U(1,maxbatchlengthT)$中随机选取,
实验
- 数据集aishell-1、wenetspeech
$\large x\in f\times T$
$\large z\in f’\times T$
$\large y\in e\times L$
大规模训练
==Kim, Chanwoo, et al. “End-to-end training of a large vocabulary end-to-end speech recognition system.” 2019 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU). IEEE, 2019.==
解决什么问题
-
用了什么方法
-
效果如何
-
还存在什么问题
-
论文思路
- 提出了一个端到端语音识别系统的训练框架,数据读取、数据增广、参数更新都能是on-the-fly(即时)的;
- 训练用了Horovod allreduce approach
- 训练CPU部分用的Example Servers (ES) and workers
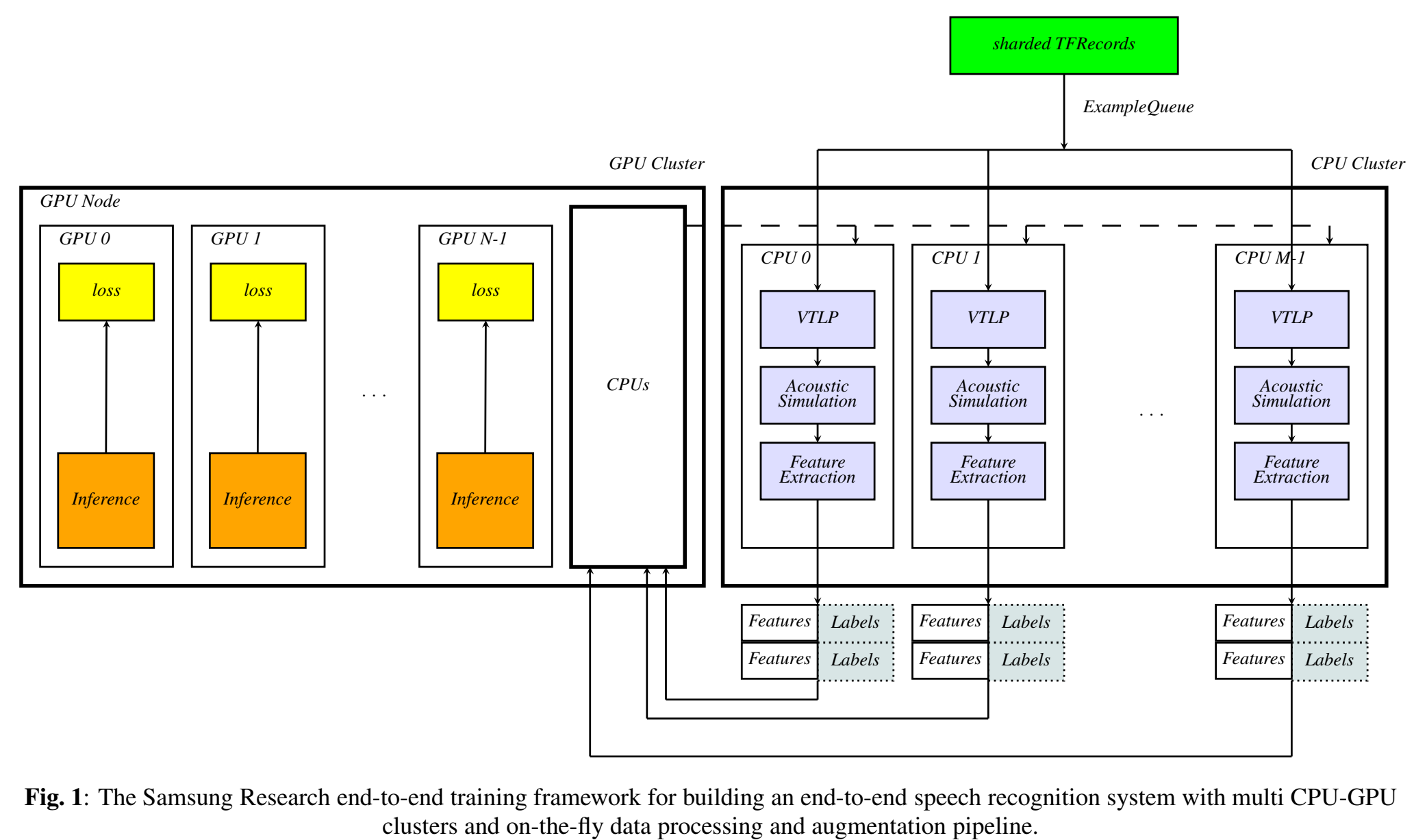
- 数据加载,用的tf.data的data queue(没用QueueRunner )
- 训练在Horovod用的allreduce 方法(没用server-worker structure )
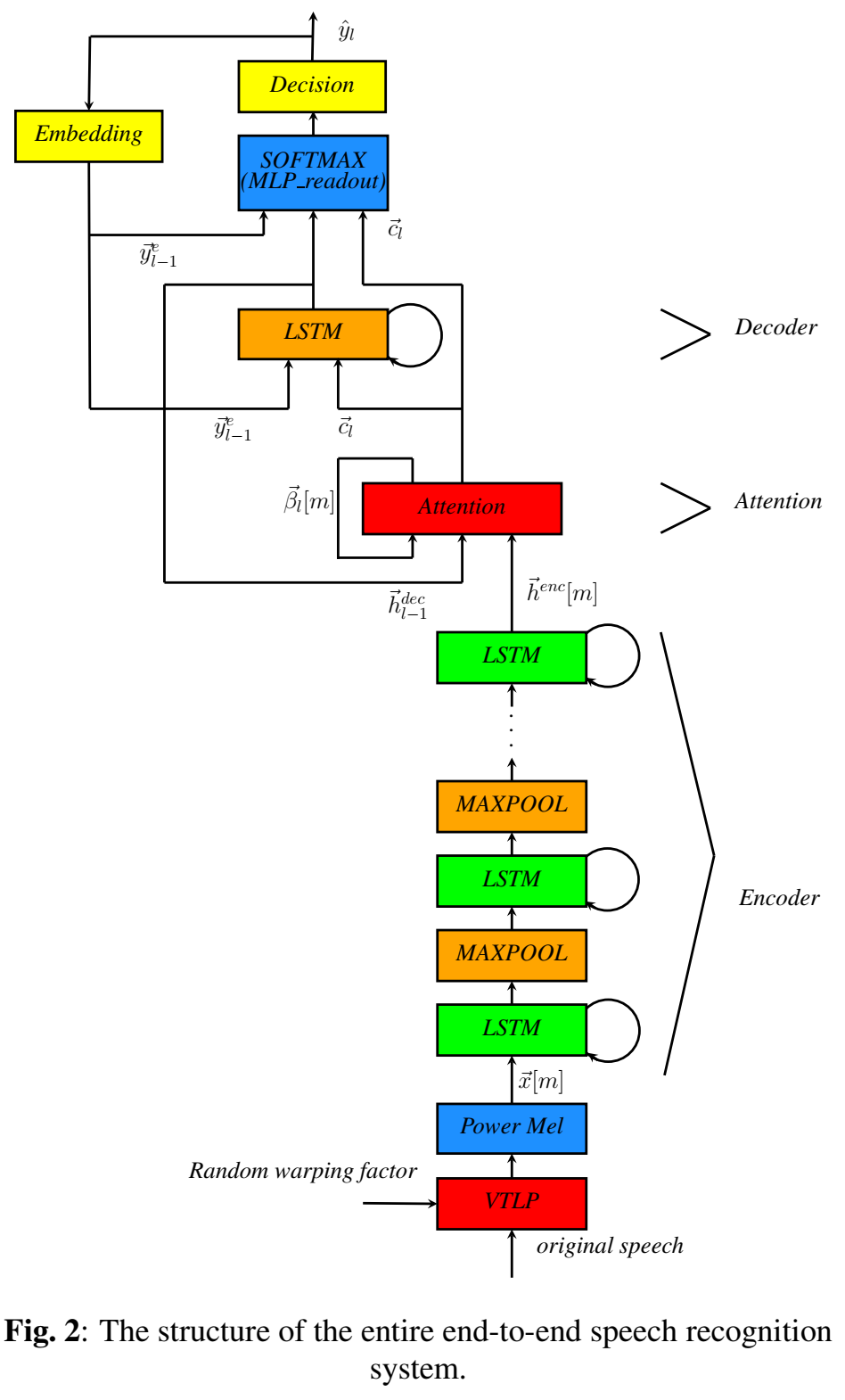
- 模型:
实验
- 数据集:librispeech、10,000-hr anonymized Bixby English dataset (三星的智能助手)
- 机器:Each GPU node of the GPU cluster has eight Nvidia™P-40, P-100 or V-100 GPUs and two Intel E5-2690 v4 CPUs, Each of these CPUs has 14 cores.
结果
- AM与transformer LM进行shallow fusion,WER:2.44 % (librispeech test-clean)
TODO 没看完