声学模型论文笔记
[FSMN] ==Shiliang Zhang et al. “Feedforward Sequential Memory Networks: A New Structure to Learn Long-term Dependency” arXiv: Neural and Evolutionary Computing (2015): n. pag.== citations:62
思路
提出前馈序列记忆网络 FSMN(Feedforward Sequential Memory Networks)
将上下文编码成一个向量(与隐层输出结点维度相同),其实就是不同时间帧特征加权求和 $\large{\tilde{h}t^l=\sum\limits{i=0}^{N_1}a_i^l\cdot{h_{t-i}^l}+\sum\limits_{j=1}^{N_2}c_j^l\cdot{h_{t+j}^l}}$
其中,$a_i$和$c_i$是常数系数或常数向量,在任意t时刻,都是不变的(时不变系数)(可通过梯度更新来更新该值)
这和只用h,只梯度更新h就够了不一样(一开始想的是这个a都不需要,h能自动更新到那个值,其实不是的),可以认为是一个scale因子
这个结构叫 tapped-delay structure(抽头延时)
在下标索引超出范围时使用零填充向量
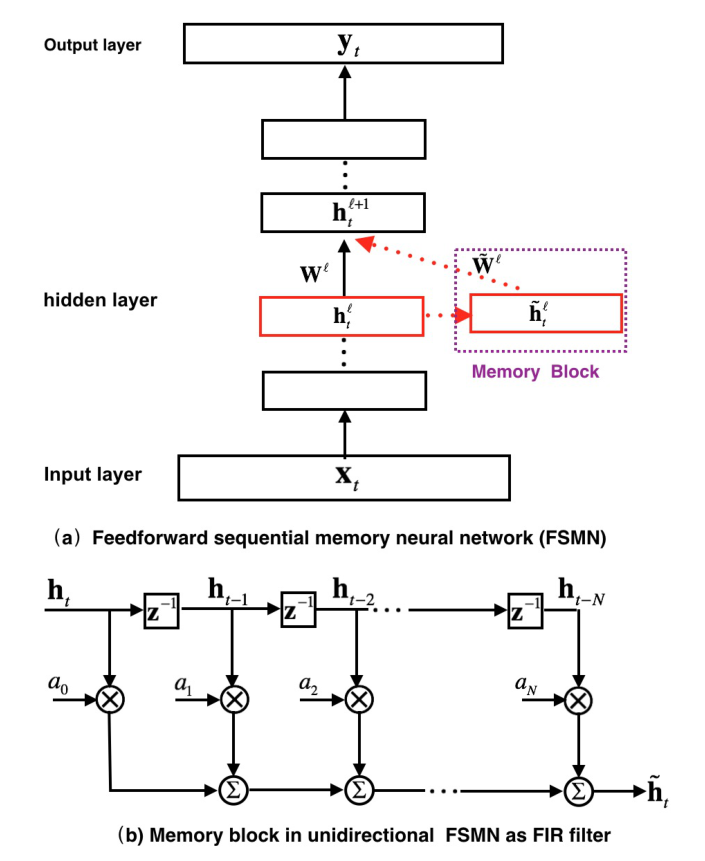
前向传播:$\large{h_t^{l+1}=f(W^lh_t^l+\tilde{W}\tilde{h}_t^l+b^l)}$
FSMN与RNN比较,RNN:$\large{h_t=f(Wx_t+\tilde{W}h_{t-1}+b)}$
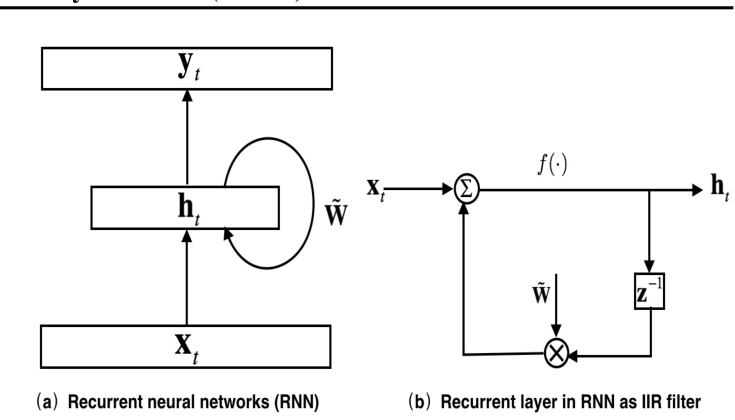
同一层下,当前时刻h来自前一时刻h和x。这和FSMN不同,FSMN当前时刻h不会来自同一层的不同时刻h。
RNN类似无限脉冲响应IIR;FSMN类似高阶有限脉冲响应;
- 时不变系数a可以换成attention系数(时变了)(context-dependent系数)