基于分类的命令词识别
三种情况:
- 输入T帧,输出1个类别向量(每个类是一个关键词)
- 输入T帧,输出T帧类别向量(每个类是一个关键词);测试时,每输入N帧,计算关键词类别的平滑后验概率,超过阈值则唤醒
- 输入T帧,输出T帧类别向量(每个类是一个关键词),只要有其中一帧keyword类别超过阈值,则唤醒;
另外一种情况:输入T帧,输出N个字符类别向量(比如transformer模型),输出字符串有beam search过程
查阅的文献里只针对一两个关键词的情况(google speech commands没考虑)
情况1:
- 数据集mobvoi,包含两个关键词:
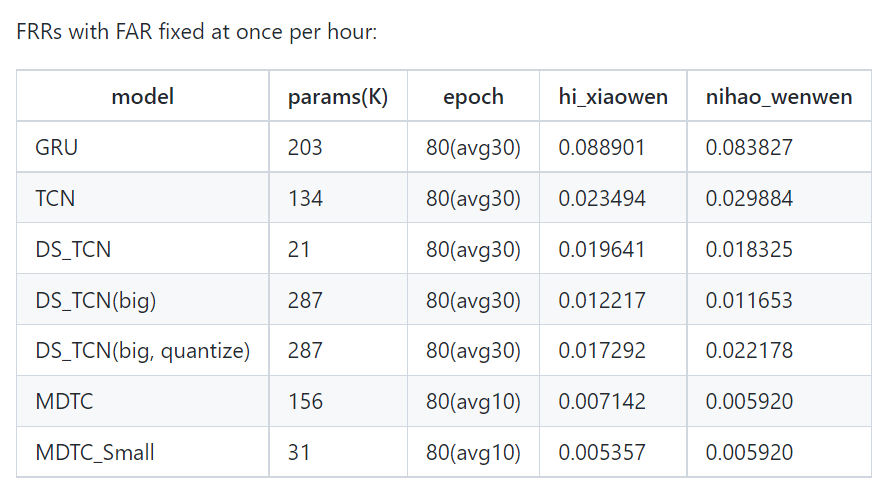
最佳情况(对应模型MDTC_Small):每小时虚警1次情况下,关键词“hi_xiaowen”的误拒率为0.53%,关键词“nihao_wenwen”的误拒率为0.59%;
数据集snips,包含一个关键词:
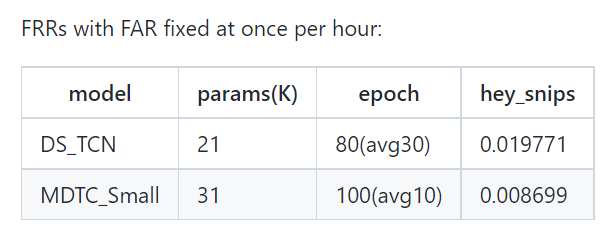
- 最佳情况(对应模型MDTC_Small):每小时虚警1次情况下,关键词“hey_snips”的误拒率为0.87%;
情况2:
Sun, Ming et al. “Max-pooling loss training of long short-term memory networks for small-footprint keyword spotting.” 2016 IEEE Spoken Language Technology Workshop (SLT) (2016): 474-480.
数据集(非开源)alexa,包含一个关键词
提出max-pooling loss,是在keyword区域内模型输出的最大后验概率,加入loss function(目标之一是最大化keyword输出的某帧后验概率)
后处理:每30帧计算一次是否触发,30帧的滑动窗口,平滑窗口内的后验概率,若大于阈值,视为触发,触发后的40帧不再计算(lock out period),以免重复触发;有触发的音频发送完后,会多送入20帧(latency windows),以防没送完。
[TODO] 情况2 开源数据集的结果
参考情况:
Alignment-Free LF-MMI
- 数据集mobvoi,包含两个关键词;数据集snips,包含一个关键词::
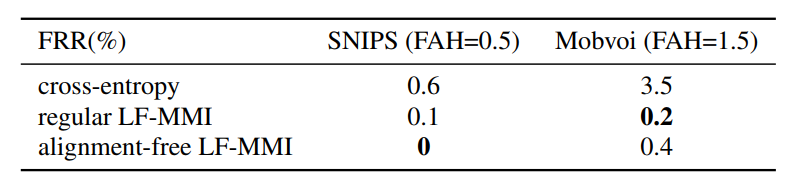
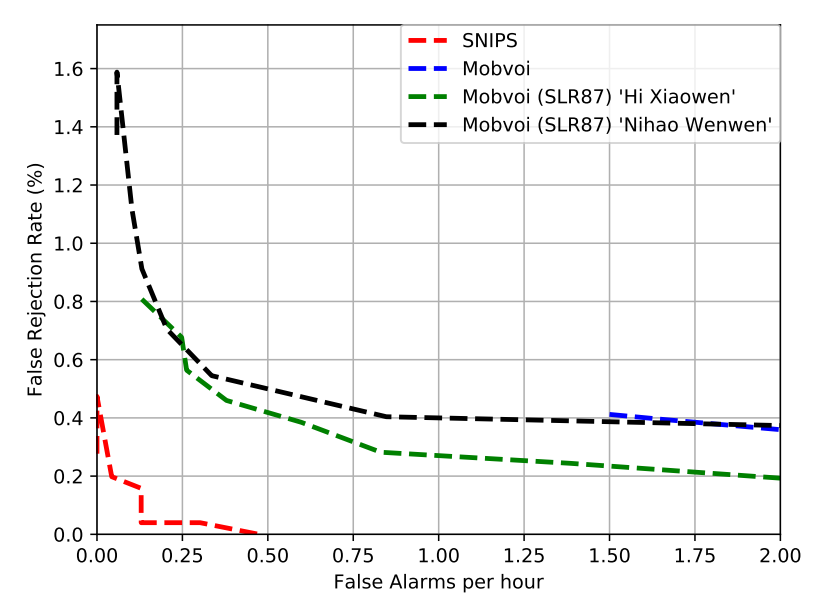
- 每小时虚警1次情况下,关键词“hey_snips”的误拒率为0%;关键词“hi_xiaowen”的误拒率为0.25%,关键词“nihao_wenwen”的误拒率为0.4%;
- 效果优于情况1
Yiming Wang et al. “Wake Word Detection with Streaming Transformers” International Conference on Acoustics, Speech, and Signal Processing (2021)
- 数据集mobvoi,包含两个关键词;数据集snips,包含一个关键词::
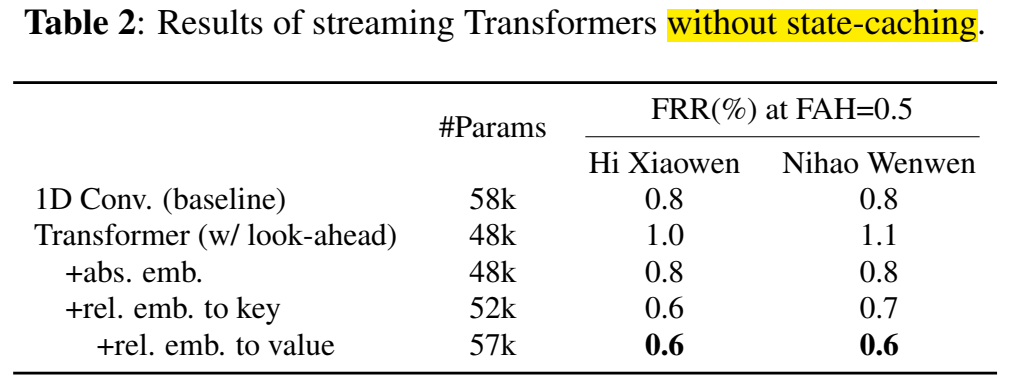
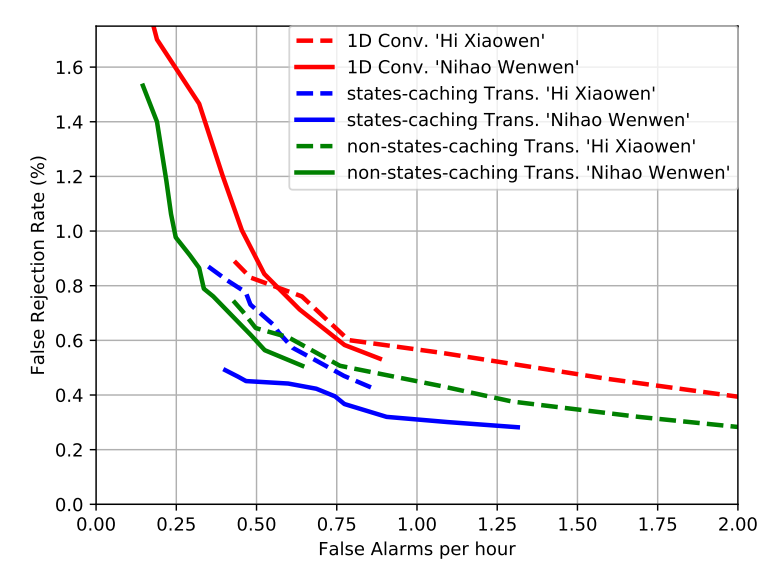
- 每小时虚警1次情况下,关键词“hi_xiaowen”的误拒率为0.45%,关键词“nihao_wenwen”的误拒率<0.5%;
- 效果优于情况1