基于chain多唤醒词识别模型
参考袁有根NCMMSC会议分享
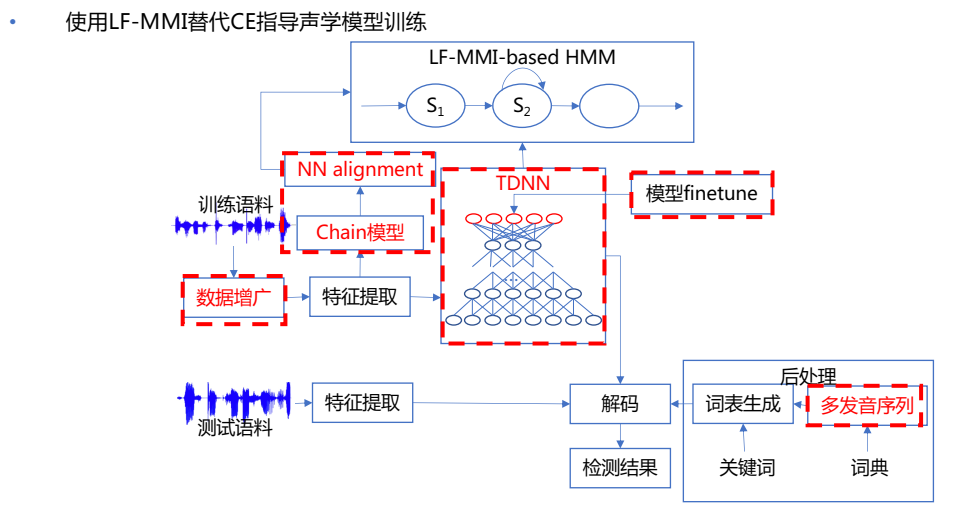
目标:训练更好的AM;如何将测试时的解码网络内的参数自动调整;
思路:一开始想要防止语言模型过拟合!!!其实根本没必要!!!,因为端到端模型中有语言模型部分,该部分参数会更新,因此越训练会越适配训练集,因此语言模型容易过拟合(而一般外部语言模型用的可不止训练数据,用的是很大文本统计得到的,可以做shallow fusion),而chain model里面参与计算loss的语言模型部分根本不会跟新,不用考虑过拟合问题!!!
如果是只考虑有无必要把语言模型融入,按照人家拼命把语言模型拿掉的思路,是没有必要再引入语言模型的。
但是希望测试时的解码网络的参数能调整,因此借鉴模型fusion的思路,1.shallow fusion cold fusion 外部语言模型参与,可使得模型倾向于
用无调音节建模
step1. 训练一个初始大一点的chain模型,分母网用训练数据得到的3gram phone ,记作chain model1,目的是后续的对齐;
用tri3对齐lattice,训练大chain model
用tri3对齐,训练tdnn,用tdnn进行后续对齐:local/nnet3/run_tdnn_bigmodel_for_align.sh
step2. 对齐生成lattice,重新训练,注意,此时构建egs时不再下采样(frame-subsampling-factor=1),分母网用训练数据得到的3gram phone loop,记作chain model2,目的是做finetune的初始模型
step3. finetune:
- 语言模型P(W)都是1,进行finetune,得到chain model2,这个想法是为了训练更好的声学模型,让声学模型受语言模型的帮助更小,更独立。花哥说,这有点类似em思路,固定语言模型,更新声学模型,再放开语言模型,更新声学模型,最后的结果可能和一开始就引入语言模型的结果差不多;
- 用测试解码网络作为P(W)进行finetune,得到唤醒任务的chain model3,雷博尝试了该方法,并且把学习率调小,结果far会很高,可能由于解码网络的竞争路径太少,竞争路径的分数也很高?
- loss分母竞争路径分数-唤醒路径分数(如何挑选出唤醒路径?),参考专利《[重要]CN201710343427-基于鉴别性训练的定制语音唤醒优化方法及系统-审定授权.pdf》
- 训练LM网络,LM网络的输入是测试解码网络概率,输出是新G概率,再用该概率去做分母,这个如何实现??
step4. 用step1的模型,用上下文无关音节建模,减少分类数,重新对齐生成lattice,再训练一个chain model
先看一下language model fusion的论文《LANGUAGE MODEL FUSION FOR STREAMING END TO END SPEECH RECOGNITION 》,看一下如何容融合外部语言模型
赋予loss不同权重
思路:
参考多任务学习的赋予权重思路:kaldi/egs/babel_multilang/s5/local/nnet3/run_tdnn_multilingual.sh
修改多任务学习的脚本,使得loss不同权重,但是又只训练一个任务
kaldi判断多任务的脚本:steps/nnet3/train_raw_dnn.py
通过有没有valid_diagnostic.scp或valid_diagnostic.ark来判断use_multitask_egs=True还是False,这个只在raw里有,因此要把mdl中的也增加多任务学习,然后作用到train_lib.common.train_one_iteration训练。
train_one_iteration里决定存储的是mdl还是raw的符号:get_raw_nnet_from_am。
实验汇总
topo区别实验
比较四/三/二个字用四/三/二状态建模,与不管几个字都用四状态建模的区别。
比较单音素(现在里面是单音素)与三音素的区别?需要比较吗
DNN对齐模型区别实验
- 用tdnn大模型(69M)作为后续对齐模型:
- 路径:25.3:/home/data/yelong/kaldi/egs/hi_mia/w1/exp_syll/nnet3/tdnn
- 脚本:local/nnet3/run_tdnn_bigmodel_for_align.sh
- 学习率:initial_effective_lrate=0.008,final_effective_lrate=0.00008,num_epochs=6(这样学习率太大了会报LOG Per-component max-change active)
- 训练集特征:train_set=data/plp/train_12000
- 对齐:ali_dir=exp_syll/tri3_ali
- 模型:tdnn,6层,1024结点,左拼13右拼9
- 分类数:8000类
- 结果:loss=-2,acc=46%(可能因为分类数太多,调小学习率继续训练无改善)
- 用conv tdnnf的chain大模型(67M)作为后续对齐模型
- 路径24.4:/home/data/yelong/kaldi/egs/hi_mia/w1/exp_syll/chain/tdnn_cnn_tdnnf
- 脚本:run_2_chain_ddt1500h.sh
- lattice:/home/storage/yelong/lattice/exp_syll/tri3_lats
- tree:exp_syll/chain/tri4_cd_tree
- feat:data/plp/train_12000
- 模型:cnn-tdnnf
对齐大模型生成lattice
- tdnn大模型生成lattice:
- 训练集:负样本12000小时(1111万条),正样本2000小时(380万条),data_multi/merge_all_sub4_12000/,正负样本1:6
- tdnn大模型路径:25.3:/home/data/yelong/kaldi/egs/hi_mia/w1/exp_syll/nnet3/tdnn
- 对齐lattice路径:exp_syll/nnet3/tdnn_12000n_2000p_lats/(集群跑的)
- chain大模型生成lattice
- 训练集:负样本12000小时(1111万条),正样本2000小时(380万条),data_multi/merge_all_sub4_12000/,正负样本1:6
- 对齐lattice路径:exp_syll/chain/tdnn_cnn_tdnnf_12000n_2000p_lats/(集群跑的)[没跑完]
- 这次把命令词都放在词典中,作为整词,不分词【没必要,因为chain用1状态建模(2个pdf),不是三音素是单音素,和前后文无关】
- 料想和tdnn对齐模型效果差不多,实验暂停。
构建单音素(每个音素两个pdf)
脚本:25.3:/home/data/yelong/kaldi/egs/hi_mia/w1/run_2_chain_ddt1500h.sh
构建单音素build-tree时:–context-width=1 –central-position=0
得到pdf=808(不是810,这是因为音节den和dia的forward-pdf和self-loop=pdf相同,应该是因为训练样本里没有?)
训练chain model
Finetune
根据chain_tdnn5_256_l39r27_id_merge_all_sub4_12000_basedTDNN_smaller_phone_lm,解码训练集data_multi/merge_all_sub4_12000,得到data_multi/merge_all_sub4_12000_filter_false_rejection_alarm,其中,
- false alarm数量6k
- false rejection数量50w,其中,7w条是识别成其他唤醒词(也就是其他唤醒词的误唤醒),7w条中有6w条是上/下一曲/集的误唤醒,小源小源4w
- 方法2重训后,再次解码false alarm和false rejection样本
- false alarm:6k -> 5k(下降19%)
- false rejection:50w -> 48w(下降4.7%)
根据chain_tdnnf8_432_48_l27r27_id_merge_all_sub4_12000_basedTDNN_smaller_phone_lm_more_epoch,解码训练集data_multi/merge_all_sub4_12000,得到data_multi/merge_all_sub4_12000_filter_false_rejection_alarm_tdnnf8,其中,
- false alarm数量1.8w
- false rejection数量66w,其中,小源小源4.8w
- 测试集far会更低的,但是解码训练集,居然比chain_tdnn5_256_l39r27_id_merge_all_sub4_12000_basedTDNN_smaller_phone_lm的更多!!!
- 方法2重训后,再次解码false alarm和false rejection样本,和想象的不同的是,误唤醒和误拒绝并没有少很多,感觉还是没训练好
- false alarm:1.8w -> 1.5w (下降17.2%)
- false rejection:66w -> 62w(下降5.6%)
方法1:
- 只对这些样本重新训练一轮(也要保证正负样本比例,小源正样本还不能少,否则唤醒率会略有下降)
- 随机shuf取出300w的负样本,与false alarm构成300w的负样本,正样本50w
- 在exp_syll/nnet3/tdnn_12000n_2000p_lats/中用
- 脚本:25.3:/home/data/yelong/kaldi/egs/hi_mia/w1/run_2_chain_ddt1500h.filter_far_frejection.sh
- 模型:exp_syll/chain/chain_tdnn5_256_l39r27_id_merge_all_sub4_12000_basedTDNN_smaller_phone_lm_filter_false_reje_ala_small_learningrate
- input_model:chain_tdnn5_256_l39r27_id_merge_all_sub4_12000_basedTDNN_smaller_phone_lm/final.mdl
- 初始和结束的学习率都为==0.000001==
1 | lattice-copy "--include=cat data_multi/merge_all_sub4_12000_filter_false_rejection_alarm/uttlist |" --ignore-missing "ark:gunzip -c exp_syll/nnet3/tdnn_12000n_2000p_lats/lat.1.gz |" "ark:| gzip -c > exp_syll/nnet3/tdnn_12000n_2000p_filter_false_rejection_alarm_lats/lat.1.gz" |
- 将筛选出的lattice放在exp_syll/nnet3/tdnn_12000n_2000p_filter_false_rejection_alarm_lats中
- 结果:如果学习率是0.00015开始训练的,学习率一开始设置得较大,效果不好,没有改善,误唤醒还增加了,但是==调小学习率后,效果变好了==
- 用同一批数据finetune tdnnf8试一试
方法2:
- 对这些样本赋予高一点的权重,其他样本赋予低一点的权重,对所有样本finetune训练一轮
- 脚本:25.3:/home/data/yelong/kaldi/egs/hi_mia/w1/run_tdnn_multilingual.sh
- 模型:exp_syll/chain/chain_tdnnf8_432_48_l27r27_id_merge_all_sub4_12000_basedTDNN_smaller_phone_lm_more_epoch_multitask_test_input_model/
awk -F'-' '{$NF=null;print$0}' 1| sed 's/ *$//' | tr ' ' '-' | paste -d ' ' - 1
1 | for n in $(seq 1 3430);do |
1 | src=exp_syll/chain/chain_tdnnf13_320_32_l27r27_id_merge_all_sub4_12000_basedTDNN_multi_2/egs |
- 初始学习率设置为1.2e-04(8卡,脚本里对应0.000015)或者1e6,结果差不多
- input_model:chain_tdnnf8_432_48_l27r27_id_merge_all_sub4_12000_basedTDNN_smaller_phone_lm_more_epoch/final_add_output01.mdl
- 似乎是因为这是tdnn5的false alarm和false rejection样本,似乎对于tdnnf8无效,因此没有改善,应该用tdnnf8的解码训练集训一轮,会好一点
把以上对于tdnn5不同权重finetune一轮:
脚本:25.3:/home/data/yelong/kaldi/egs/hi_mia/w1/run_tdnn_multilingual_tdnn5.sh
模型:exp_syll/chain/chain_tdnn5_256_l39r27_id_merge_all_sub4_12000_basedTDNN_smaller_phone_lm_multitask
input_model:exp_syll/chain/chain_tdnn5_256_l39r27_id_merge_all_sub4_12000_basedTDNN_smaller_phone_lm/final_add_output01.mdl
初始和结束的学习率都为==0.000001==(8卡,脚本里对应0.000000125)(是否有点小了?)
有改善,改善比方法1多,不知道这个改善是否来源于多训练一轮epoch?
重新解码tdnnf8训练集,用tdnnf8解码的false alarm和false rejection样本finetune一轮
- weight比例2.5:1,无论学习率是1e-6(8卡后)或者1.5e-5(8卡后),效果都没有改善
- 查看有没有==过拟合==:
grep output-0-xent compute_prob_valid.* | sed 's/valid./ /g' | sed 's/.log/ /g' | sort -k 2 -n grep "average objective function for 'output-0'" train.*.1.log | sed 's/train./ /g' | sed 's/.1.log/ /g' | sort -k 1 -n- 少数测试集有改善
学习率设置
| 脚本里initial_lr(实际lr (乘以gpu数) | 脚本里final_lr(实际lr (乘以gpu数) | |
|---|---|---|
| 普通 | 0.00015 | 0.000015 |
| more_epoch | 0.000015 | 0.0000015 |
| false_reje_ala:训练的是tdnn5(结果不好) | 0.00015 | 0.000015 |
| false_reje_ala调小学习率:训练的是tdnn5(有改善) | 1.25e-7(1e-06) | 1.25e-7(1e-06) |
| multitask_test_input_model:训练的是tdnnf8(没有改善) | 0.000015(0.00012) | 0.0000015(1.2e-05) |
| multitask_test_input_model_small_learningrate:训练的是tdnnf8(没有改善) | 1.25e-7(1e-06) | 1.25e-7(1e-06) |
测试解码
- chain_tdnn5_256_l39r27_id_merge_all_sub4_12000_basedTDNN_smaller_phone_lm
实验测试结果
10000条命令词,测唤醒率
tdnn[1]:chain_tdnn5_256_l27r27_id_merge_all_sub4_12000_basedTDNN_smaller_phone_lm/graph_add_two
tdnn[2]:chain_tdnn5_256_l39r27_id_merge_all_sub4_12000_basedTDNN_smaller_phone_lm_filter_false_reje_ala_small_learningrate/graph
tdnn[3]:chain_tdnn5_256_l39r27_id_merge_all_sub4_12000_basedTDNN_smaller_phone_lm_multitask/graph
tdnn[4]:chain_tdnn5_256_l39r27_id_merge_all_sub4_12000_basedTDNN_smaller_phone_lm_more_epoch/graph
tdnnf[1]:chain_tdnnf13_320_32_l27r27_id_merge_all_sub4_12000_basedTDNN_smaller_phone_lm
tdnnf[2]:chain_tdnnf8_432_48_l27r27_id_merge_all_sub4_12000_basedTDNN_smaller_phone_lm_more_epoch/graph_add_two2/
tdnnf[3]:chain_tdnnf8_432_48_l27r27_id_merge_all_sub4_12000_basedTDNN_smaller_phone_lm_more_epoch_multitask_tdnnf8decode/graph_10_1
tdnnf[4]:chain_tdnnf8_432_48_l27r27_id_merge_all_sub4_12000_basedTDNN_smaller_phone_lm_more_epoch/graph1/ (2gram lm)[实际不可用]
47万条随机语音片段,测误唤醒(479984)
tdnn[1]:chain_tdnn5_256_l39r27_id_merge_all_sub4_12000_basedTDNN_smaller_phone_lm/graph_add_two
tdnn[2]:chain_tdnn5_256_l39r27_id_merge_all_sub4_12000_basedTDNN_smaller_phone_lm_filter_false_reje_ala_small_learningrate/graph
tdnn[3]:chain_tdnn5_256_l39r27_id_merge_all_sub4_12000_basedTDNN_smaller_phone_lm_multitask/graph
tdnn[4]:chain_tdnn5_256_l39r27_id_merge_all_sub4_12000_basedTDNN_smaller_phone_lm_more_epoch/graph
tdnnf[1]:chain_tdnnf13_320_32_l27r27_id_merge_all_sub4_12000_basedTDNN_smaller_phone_lm
tdnnf[2]:chain_tdnnf8_432_48_l27r27_id_merge_all_sub4_12000_basedTDNN_smaller_phone_lm_more_epoch/graph_add_two2/
tdnnf[3]:chain_tdnnf8_432_48_l27r27_id_merge_all_sub4_12000_basedTDNN_smaller_phone_lm_more_epoch_multitask_tdnnf8decode/graph_10_1
tdnnf[4]:chain_tdnnf8_432_48_l27r27_id_merge_all_sub4_12000_basedTDNN_smaller_phone_lm_more_epoch/graph1/ (2gram lm)[实际不可用]
小源小源一个唤醒词
lei:V1+SIL
tdnn[1]:chain_tdnn5_256_l39r27_id_merge_all_sub4_12000_basedTDNN_smaller_phone_lm/graph_add_two
tdnn[2]:chain_tdnn5_256_l39r27_id_merge_all_sub4_12000_basedTDNN_smaller_phone_lm_filter_false_reje_ala_small_learningrate/graph
tdnn[3]:chain_tdnn5_256_l39r27_id_merge_all_sub4_12000_basedTDNN_smaller_phone_lm_multitask/graph
tdnn[4]:chain_tdnn5_256_l39r27_id_merge_all_sub4_12000_basedTDNN_smaller_phone_lm_more_epoch/graph
tdnnf[1]:chain_tdnnf13_320_32_l27r27_id_merge_all_sub4_12000_basedTDNN_smaller_phone_lm/graph_add_two2 前向计算时间长,不考虑
tdnnf[2]:chain_tdnnf8_432_48_l27r27_id_merge_all_sub4_12000_basedTDNN_smaller_phone_lm_more_epoch/graph_add_two2
tdnnf[3]:chain_tdnnf8_432_48_l27r27_id_merge_all_sub4_12000_basedTDNN_smaller_phone_lm_more_epoch_multitask_tdnnf8decode/graph_10_1
tdnnf[4]:chain_tdnnf8_432_48_l27r27_id_merge_all_sub4_12000_basedTDNN_smaller_phone_lm_more_epoch/graph1/ (2gram lm)[实际不可用]
()内是所有命令词的误唤醒
实验小结
- 从声学模型输出观察:
pdf2phone exp_syll/chain/chain_tdnn5_256_l39r27_id_merge_all_sub4_12000_basedTDNN_smaller_phone_lm/final.mdl ark:feats.scp1.1.1 | utils/int2sym.pl -f 2- exp_syll/chain/chain_tdnn5_256_l39r27_id_merge_all_sub4_12000_basedTDNN_smaller_phone_lm/phones.txt -
发现确实是声学模型不够好造成的误触发。相似音(比如jing和ji)容易误触发
多训练epoch效果有改善(4epoch->5epoch)
学习率不能调高,否则易过拟合
训练分母的phone lm从4gram到2gram,效果会提升,训练中复杂的语言模型反而没有带来收益,推测原因:
- 1.简单的语言模型能让声学模型得到的信息更少,加重了声学模型的训练难度,使得声学模型训练得更不容易过拟合;
- 2.复杂的语言模型(适配训练集的语言模型)使得声学模型更容易过拟合;
- 3.训练中简单的语言模型与测试的1gram语言模型更接近;
解码训练集,用false alarm和false rejection的样本,增加高一点权重(调参10:1和2.5:1),不同学习率,重训练一轮。结果没有改善
结果分析
- 小源小源唤醒词的唤醒率、误唤醒基本可以达到要求,但是其他唤醒词的误唤醒还是比较高。
- 尝试从样本出发:解码训练集,用false alarm和false rejection的样本,增加高一点权重(调参10:1和2.5:1),重训练一轮。结果:没有改善
- 尝试从后处理出发:增加简单二级阈值判断(解码命令词起止时间长度,解码命令词cost值)。结果:没有改善,简单阈值判断不出。
- 尝试从训练目标函数出发:用最大化状态/音素正确率作为目标函数(sMBR、MPE),增加唤醒词的唤醒率;尝试center loss减少类内距离(从而增加类间距离)(未完成)
- 尝试从声学模型出发:tdnnf比tdnn好,在前向时间相同情况下尝试其他声学模型(未完成)
增加解码竞争路径
花哥说,用类似2gram语言模型思路,通过判断两个字前后的文本是怎样的,来抑制两个字的误触发。
具体做法思路:把1gram里的命令词去掉,放在2gram里
路径:25.3:/home/data/yelong/kaldi/egs/hi_mia/w1/data_syll/lang_context
HCLG:exp_syll/chain/chain_tdnnf8_432_48_l27r27_id_merge_all_sub4_12000_basedTDNN_smaller_phone_lm_more_epoch/graph1/
把四字放到2gram里,删掉1gram它的路径,效果没有提升反而下降,原因分析
该方法有效降低误触发,二、三字误触发能降低17%~30%
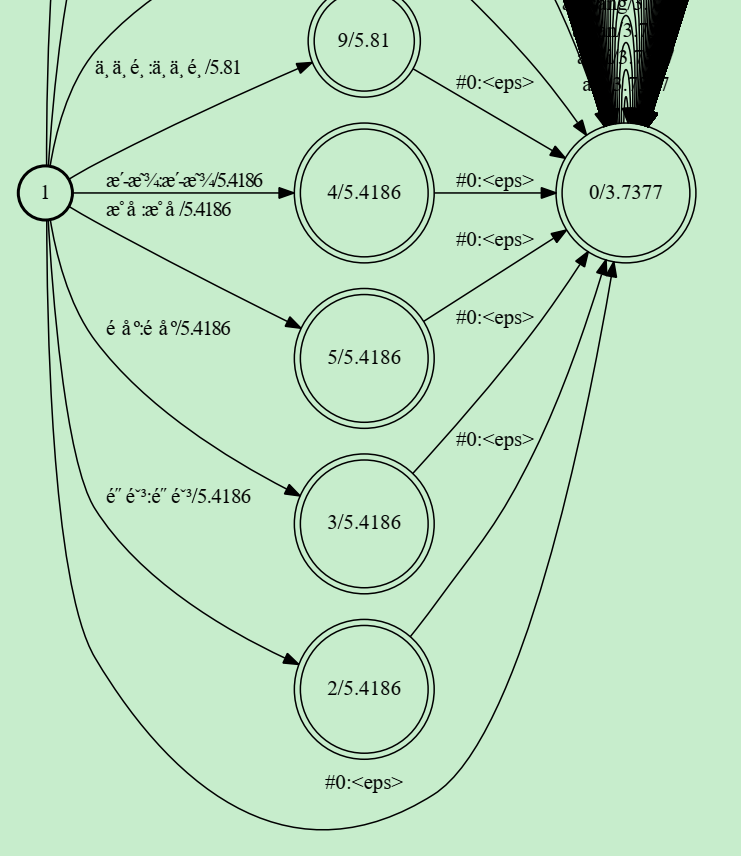
1是开始状态,两个圈是结束状态。
表示只能以 2gram里只能以 比如 静音 开头,可以 有“静音 其他音” 的路径,但没有“其他音 静音” 的路径
与原先区别:命令词前有其他声音会降低唤醒率(要很大声)(现实总是有其他声音的,不可行)
实验不可行:测试0807(实际录音),小源小源也采用上述方法放进2gram,发现唤醒率很低。
虽然在test_1w里,四字的唤醒率没有降低,但是在0807实测测试集里,唤醒率大幅度降低
2gram
用训练集ali训练的2gram LM,误识别率可以下降34%,但是时间多5倍
剪枝后:
ngram -lm srilm.o3g.kn.gz -order 2 -prune 0.00001 -write-lm newlm:误唤醒能下降28%,时间2倍之前(雷博说这个可能测不准,要用keyword_lib测才会准一点)
ngram -lm srilm.o3g.kn.gz -order 2 -prune 0.0001 -write-lm newlm:误唤醒只能下降4%,时间1.4倍之前
降低一点点识别率,同时也降低误识别率的方法:
把相似音(比如zan的相似音zai、zi、zhan…….)的权重提高一点
误触发常发生在有个xiao/yuan开头的音,即使音后面不同,也会触发
我的意思是修改FST,让小源小源在发音发完整个词后,output label才是小源小源。
雷博说,现在输出文本,都是发完小源小源,达到结束state了,才会回溯判断是否有小源小源,不存在发音一半就出来小源小源的情况;
唯一可能减少一点误触发的方法就是,小/源状态自己也有结束state,可能到达小/源就结束;
但其实这个在垃圾路径里已经添加了,没有走到还是路径权重的原因;
