WeKws
https://github.com/wenet-e2e/wekws
Mining Effective Negative Training Samples for Keyword Spotting (github, paper)
Max-pooling Loss Training of Long Short-term Memory Networks for Small-footprint Keyword Spotting (paper)
A depthwise separable convolutional neural network for keyword spotting on an embedded system (github, paper)
Hello Edge: Keyword Spotting on Microcontrollers (github, paper)
An Empirical Evaluation of Generic Convolutional and Recurrent Networks for Sequence Modeling (github, paper)
代码结构梳理
1 | train_dataset = Dataset(args.train_data, train_conf) |
其中,kws/dataset/dataset.py里的Dataset函数:
1 | def Dataset(data_list_file, conf, partition=True): |
给dataset按if添加了很多项,写法比较规范
examples/hi_xiaowen/s0/kws/dataset/processor.py,有点看不懂这里是怎么jump的
1 |
|
max pooling loss
max_pooling loss是取正样本某帧的最大正类概率值,让这帧概率越大越好,取负样本某帧的最小负类概率值,让这帧的概率越大越好
二分类时:
target = filler时:$loss=\min\limits_T(1-P_{keyword})$ (min pooling)
target = keyword时:$loss=\max\limits_TP_{keyword}$ (max pooling)
三分类时(两个keyword)
target = filler时:$loss=\min\limits_T(1-P_{keyword1})+\min\limits_T(1-P_{keyword2})$ (min pooling)
target = keyword1时:$loss=\max\limits_TP_{keyword1}+\min\limits_T(1-P_{keyword2})$ (max pooling)
target = keyword2时:$loss=\max\limits_TP_{keyword2}+\min\limits_T(1-P_{keyword1})$ (max pooling)
目标:$\max_Wloss$
这里我一开始有个误区,$\min\limits_T(1-P_{keyword})$其实不等价为$\max\limits_T(P_{keyword}-1)$!!!而是$\min\limits_T(1-P_{keyword})=-\max\limits_T(P_{keyword}-1)$
最小化loss(代码里取负号后是最小化loss,不取负号是最大化loss,我这里先不取负号进行解释),因此要最大化target=keyword时 $P_{keyword}$的概率,因为只要有一帧大于阈值就算唤醒,所以取max-pooling对应最大keyword概率帧的概率,同时也要最小化nonkeyword的概率,这里希望最难训练的一帧nonkeyword也要尽可能小,最难训练一帧对应的min-pooling的$1-P_{nonkeyword}$,使得$\min\limits_T(1-P_{nonkeyword})$尽可能大作为loss function,随着迭代该值能够越来越大,意味着最难训练的nonkeyword的概率越来越小
[==TODO==]稳定之后,尝试focal loss?尽可能让所有的keyword的概率都要大,试试$\min\limits_TP_{keyword}$使之尽可能大
推理时只考虑keyword帧是否大于阈值(只要有一帧大于阈值就算唤醒)
1 | def max_pooling_loss(logits: torch.Tensor, |
- kws/bin/average_model.py:把最后保存的N个模型里面的参数求和取平均
- kws/bin/score.py:计算声学模型输出,保存到文件中
- kws/bin/compute_det.py:计算FRR/FAR:对于某个分类,看它的分数是否大于阈值,大于就唤醒,小于没唤醒;(而不是在不同分类之间比较大小,从而确定是哪个分类唤醒,这是因为这里的输出没有filler分类,只有keyword分类)
hi_xiaowen数据集替换为自己的数据集
。。。
生成data.list:
用shell直接从现有文件中生成了
1 | awk '{print"{\"key\": \""$1"\","}' feats.scp > 1 |
1 | awk '{print"{\"key\": \""$1"\","}' feats_offline_cmvn.scp > 1 |
不用代码统计global cmvn,用kaldi的
1 | matrix-sum --binary=false scp:data/train_p400h_n4000h/cmvn.scp - > data/train_p400h_n4000h/global_cmvn.stats |
训练
num_worker=1
输出模型步长
之前是一个epoch输出一个模型,现在改成1000次迭代输出一个模型
mdtc_small:
dilation:低层到高层的值逐渐增长 1,2,4,8
self.receptive_fields感受野(非kernel size)大小与dilation有关,这个变量是为了给卷积补零用的,统计一共需要多少补零的长度
如果causal=True,就不能卷(计算)当前时间帧后面帧的信息,只能给过去帧补零,以达到能够计算的长度
如果causal=False,前后帧补零(除以2)$\left\lfloor\frac{\text{len(pad)}}{2}\right\rfloor$
1 | self.receptive_fields = dilation * (kernel_size - 1) |
补零的不计算?:
1 | if self.causal: |
[TODO] 补零,可以用复制代替??
preprocessor预测里后的特征分别经过stack_num个TCN Stack,得到stack_num个输出
结构:
1 | the number of model params: 33201 |
参数图:
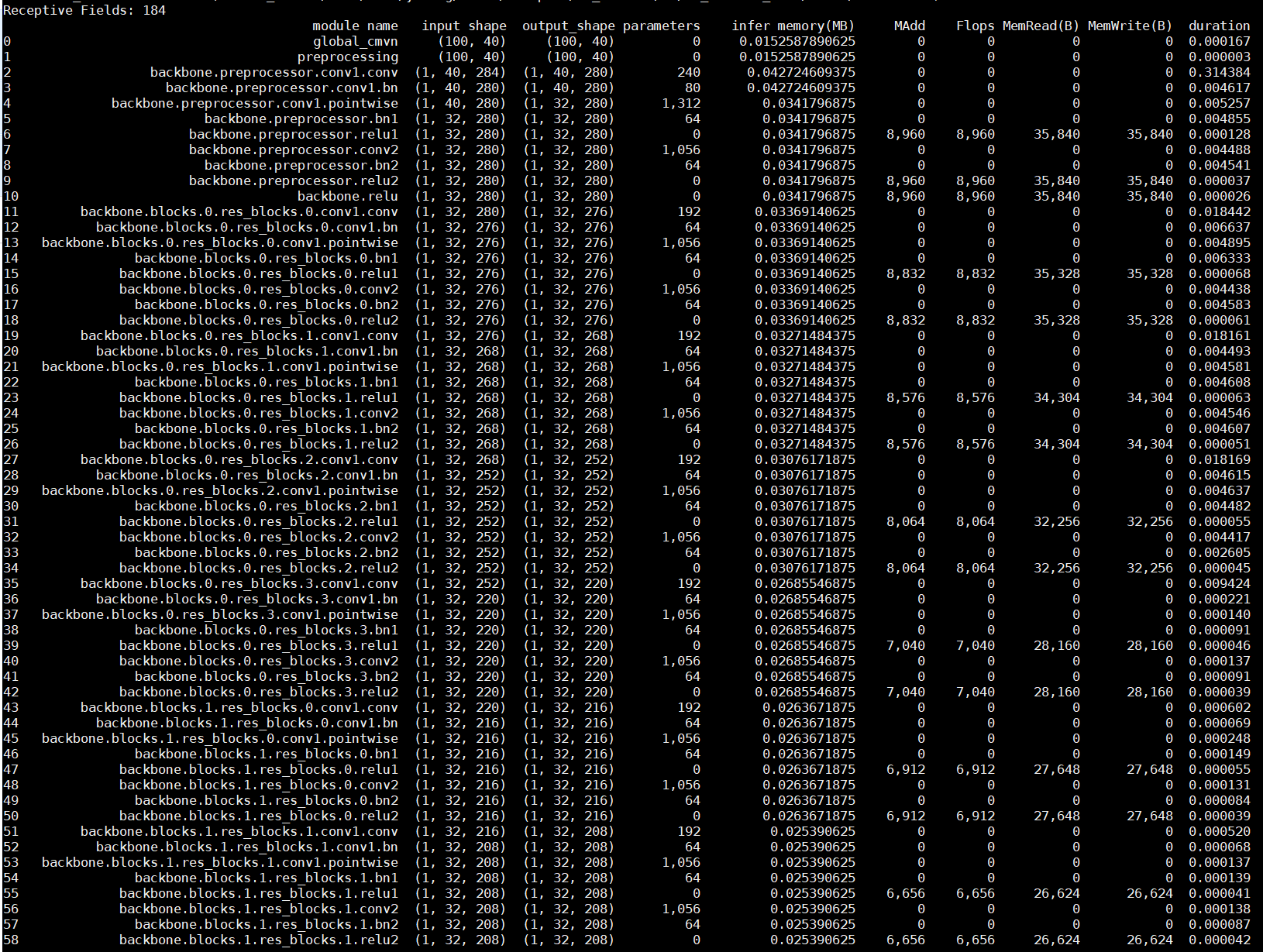
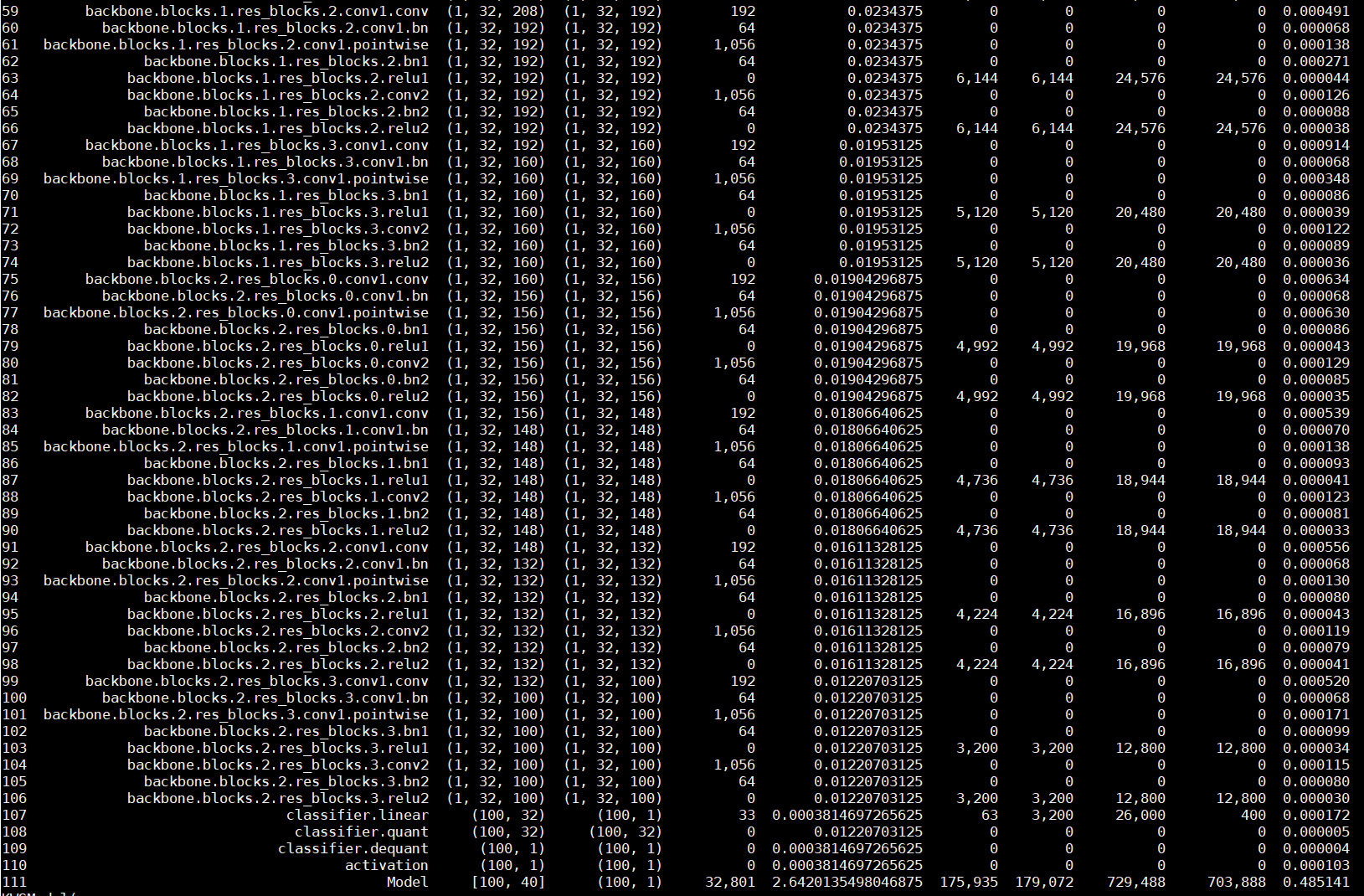
修改代码
在log中把train的learning rate也打印出来
在kws/utils/executor.py中,修改logging代码为:
1 | logging.debug( |
打印model结构图/可视化
法一:tensorboard[可视化不太明显]
在kws/model/kws_model.py中,添加代码
1 | kws_model = KWSModel(input_dim, output_dim, hidden_dim, global_cmvn, |
在路径runs/下,tensorboard打开
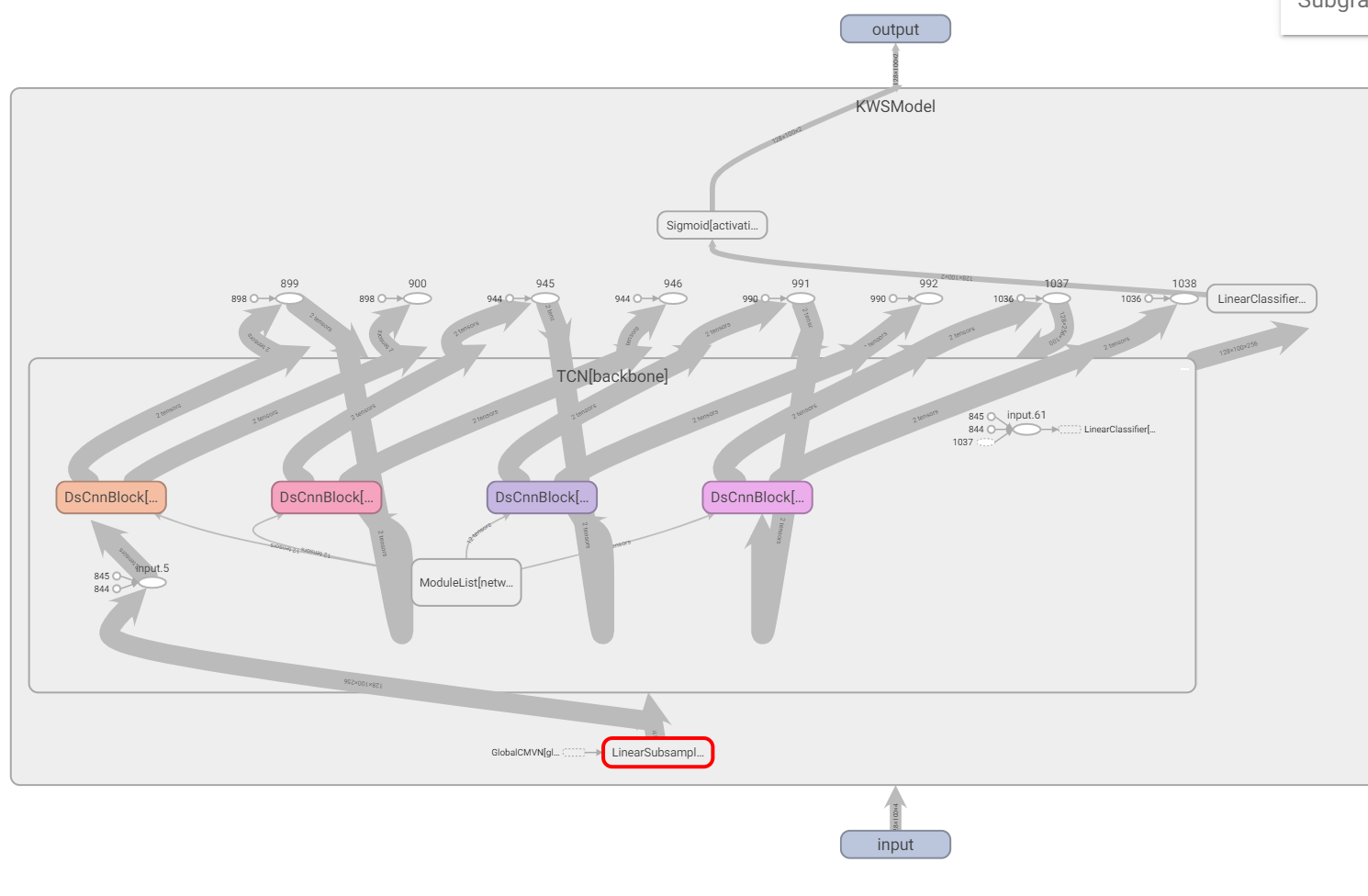
可以展开看细节。但是这样可视化程度不是很强。[tensorboard可视化模型结构并不友好]
法二:torchviz
在kws/model/kws_model.py中,添加代码
1 | from torchviz import make_dot |
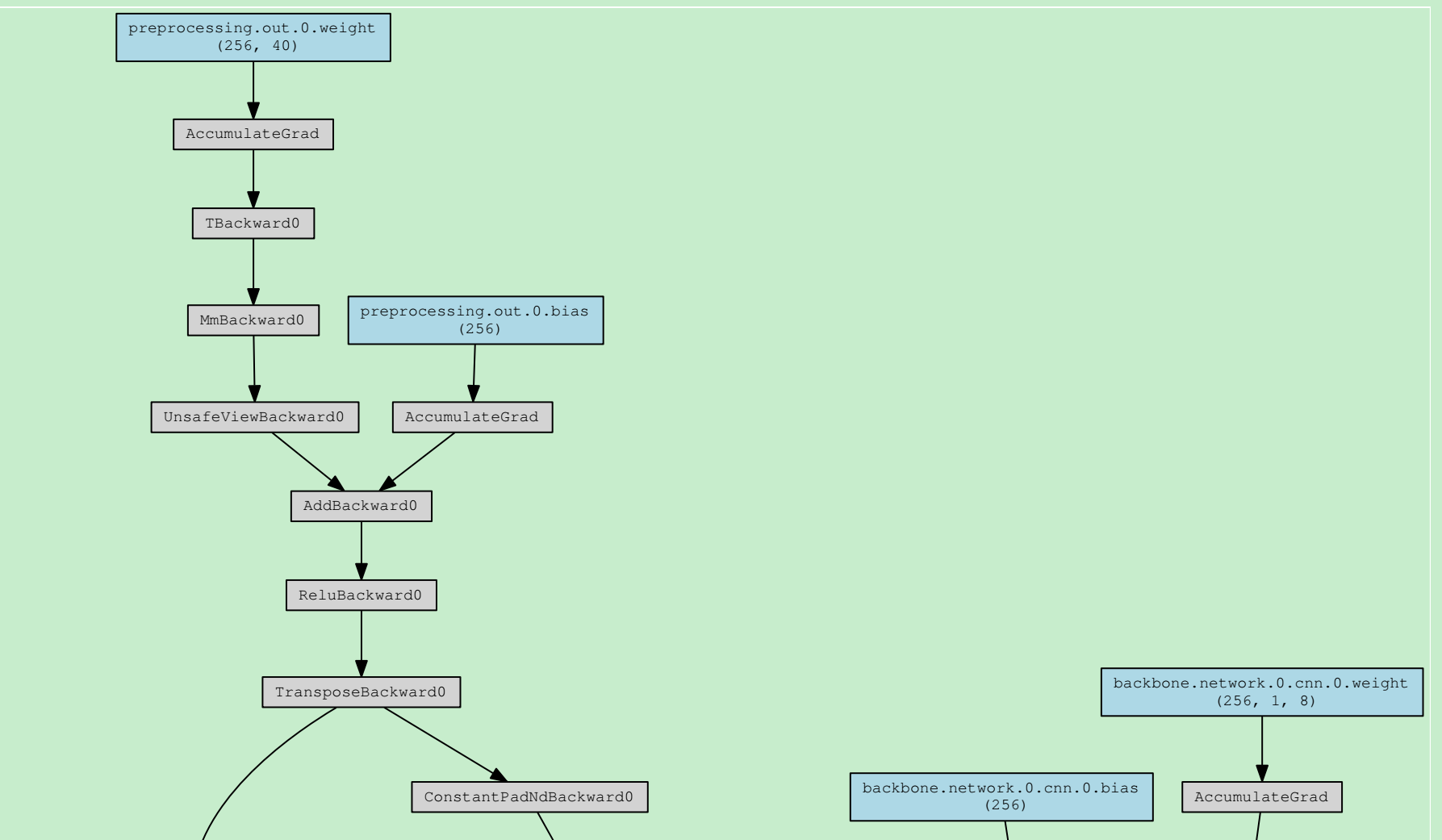
法三:tensorwatch
支持的网络不够多
在kws/model/kws_model.py中,添加代码
1 | import tensorwatch as tw |
- ds_tcn:以batch size=1,time=1s,40维特征为例的tensorwatch.model_stats
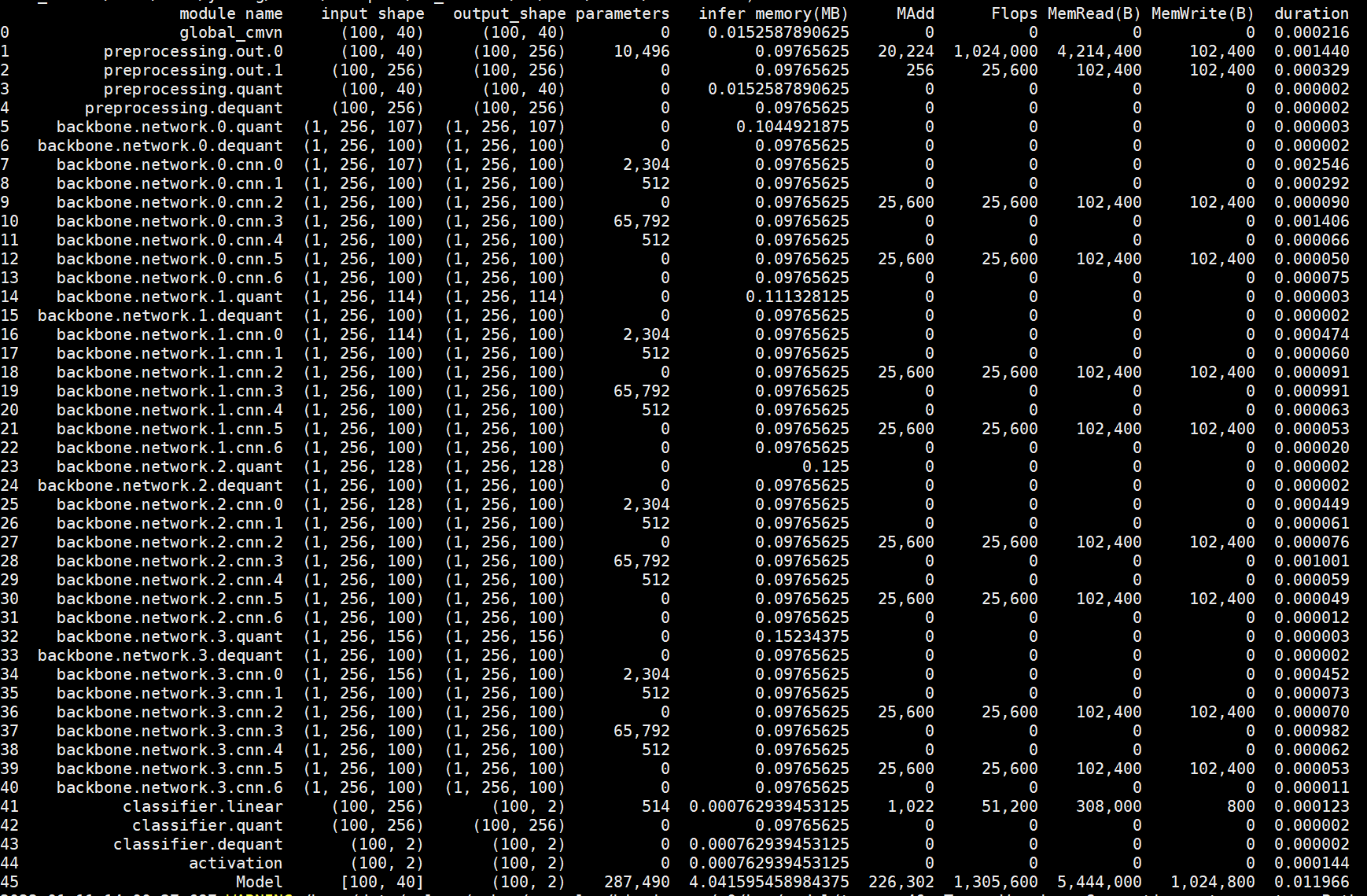
法四:fvcore
1 | from fvcore.nn import FlopCountAnalysis |