tdnn、tdnnf计算量分析
计算量,一般是指的1s内乘法的次数
一帧的计算量,一般就是参数量?
TDNN
- tdnn结构:
1 | fixed-affine-layer name=lda input=Append(-6,-3,0,3,6) affine-transform-file=$dir/configs/lda.mat |
- tdnn一帧计算量:

- tdnn网络图:
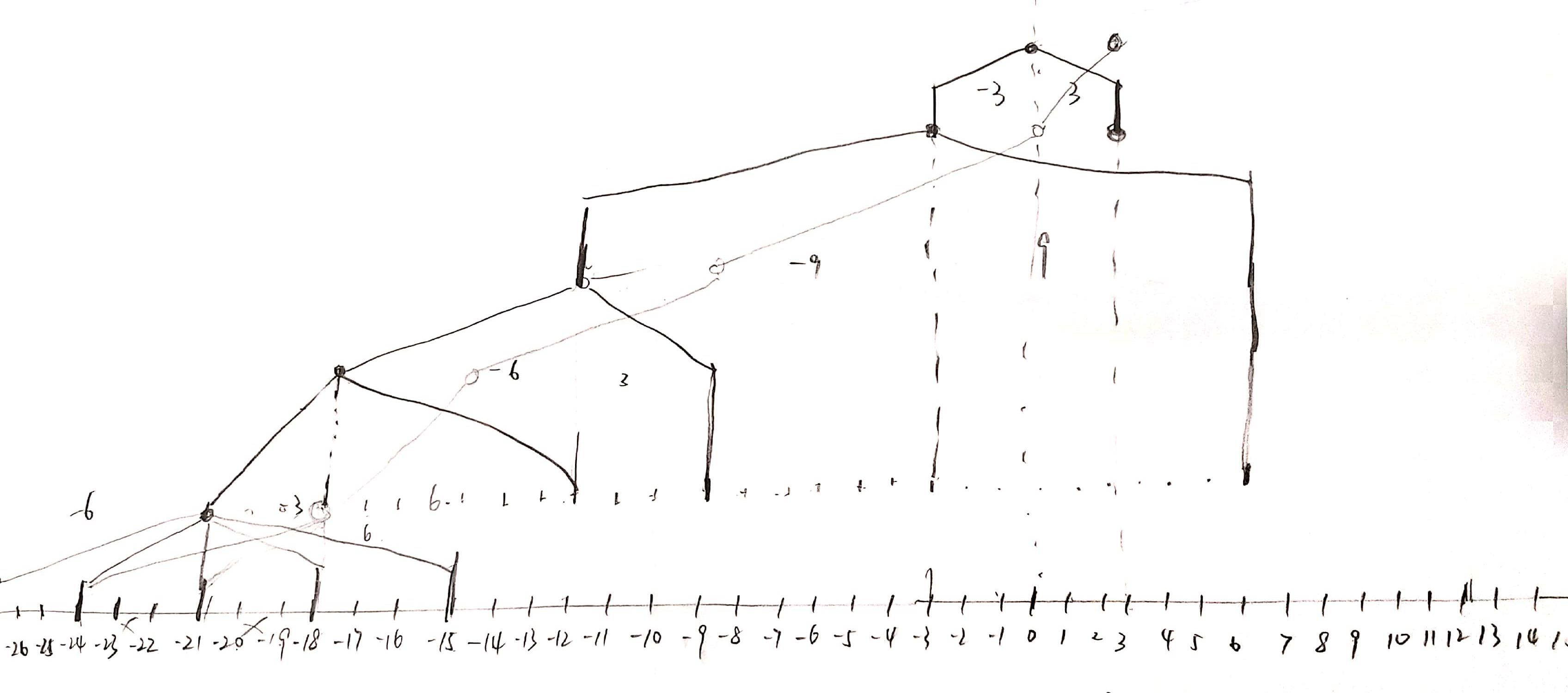
可以看出,chain的跳帧,作用到最底层的输入,输入也是跳3帧的,相当于虽然左右跨帧27,27,但实际输入,参与计算的只有1/3的帧数,相当于速度3倍。
TDNNF
- tdnnf结构
1 | dim=320 |
- tdnnf一帧计算量:

- tdnnf网络图
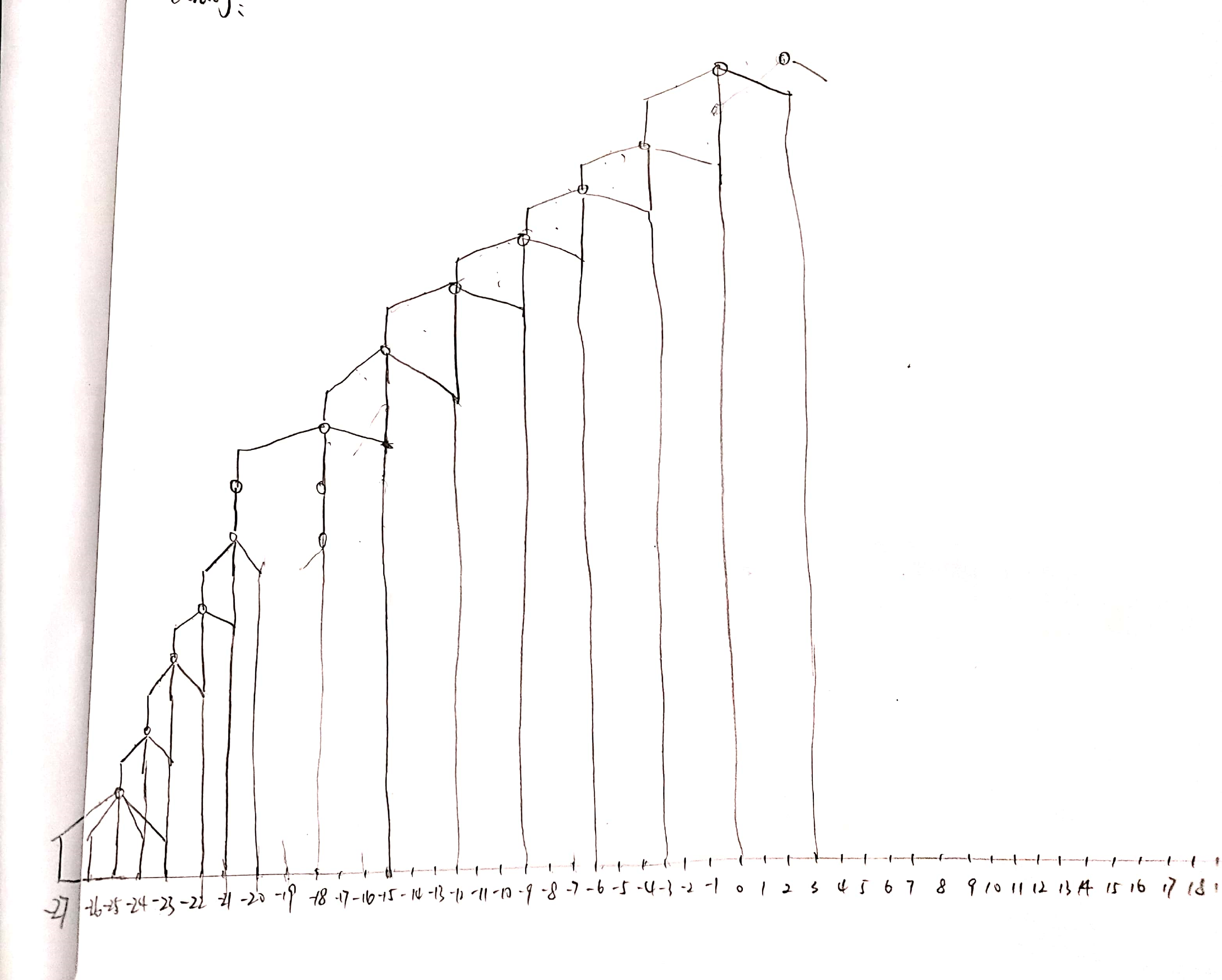
可以看出,前几层很多1的拼帧,所以虽然最上层输入给decoder的进行了下采样,到了底层,也还是要利用那么多帧,没有起到加速的效果。
- 改进:不用1的拼帧,只用3的拼帧