Alignment free LF-MMI
==Wang Y, Lv H, Povey D, et al. Wake Word Detection with Alignment-Free Lattice-Free MMI[J]. arXiv preprint arXiv:2005.08347, 2020.==
==Wang, Yiming. WAKE WORD DETECTION AND ITS APPLICATIONS. Diss. Johns Hopkins University, 2021.==王一鸣博士论文
==github开源代码==:The code and recipes are available in Kaldi [24]: https://github.com/kaldi-asr/kaldi/tree/master/egs/{snips,mobvoi,mobvoihotwords}.
==github代码==:https://github.com/YiwenShaoStephen/pychain
==csdn 博客==:Wake Word Detection with Alignment-Free Lattice-Free MMI
思想
- 提出alignment free LF-MMI,不需要对齐分子lattice
- 不把唤醒词里面每个音素建模,而是把整个唤醒词建模 model the whole wake phrase ,用一个固定状态数的HMM去建模唤醒词(该数量少于唤醒词音素组成数量)
- keyword、non-keyword、sil 都各用一个HMM建模
- 针对唤醒任务,提出alignment free LFMMI,分子不用对齐文本得到分子lattice,由于文本就是keyword/non-keyword,文本只有一个HMM,直接遍历HMM所有可能路径,求路径和概率。(直接用文本图上添加自环,让解码更自由,前后向可选的路径更多)
- 负样本文本一般比较长,一个HMM可能建模不了,因此把负样本切成和正常本长度差不多,每个负样本的训练文本为freetext(一个HMM),就可以去生成egs了
- 负样本如果不segment,会严重过拟合
- 该方法能有效改善FAR高
- 分母图上路径权重:按正负样本比例来分配
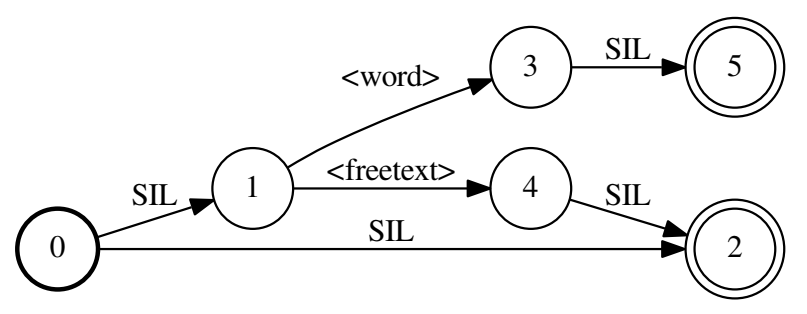
分子图fst:用一个文本构成(一个文本就是一个单词,一个单词用一个HMM建模)

分母图fst:可以理解成word 并联序列,只不过添加了sil(不是loop,不能重复走)
实验
- 负样本进行了分块chunk,==chunk长度和正样本差不多==,
- 负样本后继chunk重叠0.3s,使得前一个chunk被截掉的单词有机会在后继chunk全词出现
- 声学模型:TDNN-F,分解到两个低秩矩阵,前一个矩阵是半正定的,确保高维到低维信息不会丢失
- 前一层的输入乘上缩放比例0.66与本层输入加和(是add,而不是concatenate)
- 拼帧结构:把本来要拼在一层的结构 分解到两层会更好,比如第一层拼(-3,0,3),第二层拼(0),更好的做法是第一层拼(-3,0),第二层拼(0,3)
- 训练了一个alignment-free LF-MMI后,对齐lattice,重新训练一个普通的LF-MMI,效果会更好
- alignment-free体现在:
- (雷博)不需要GMM-HMM训练过程,不需要对齐ali文件
- 不需要对齐训练样本然后统计得到phone-lm
- 一个没有一点对齐能力的模型(0.mdl)也可以拿来使用的
- nnet3-chain-e2e-get-egs分子cegs生成,直接用text构建的fst,找到所有可能的fst中的状态序列求和就是分子,普通的还要由fst构建lattice?(感觉二者差不多)
- 博士论文中比较了不同topo结构:
- 把sil和freetext表示在一个HMM中,该HMM有多种可走的路径,这样就能够表示当训练样本前后是非命令词,中间是静音的情况。结果是增加了训练难度,误拒率很高,只有对齐准确的初始模型可能会得到好一点的误拒率,但是还是不好,因此最好不要把sil和freetext放在一起建模
- 用5状态建模HMM,效果比3状态好
注意
- 雷博说:
- 负样本切chunk后,要注意正负样本比例,不要让负样本远远多于正样本。
- 切割负样本(长文本切到短文本)时,文本不知道对应的是sil还是freetext,不好得知文本,把静音段也视作freeetext会有问题
- 实验效果好,可能由于数据集较小
在线解码
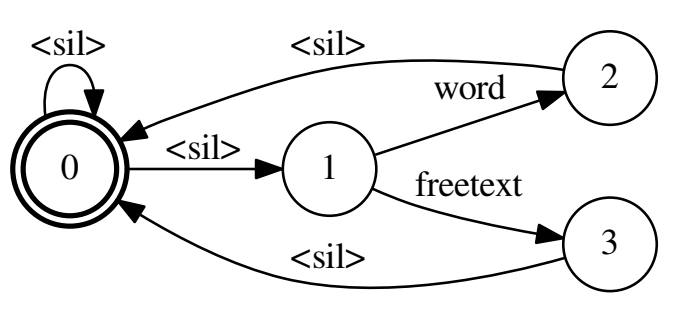
- 解码FST:其实长得有点像分母图,不同之处在于是起始状态和终止状态在同一个结点,使得可以生成词串,比如生成word后还可以生成freetext,再生成word等等,文本串;而分母图要不然就走freetext,要不然就走word,不能都串行出现。
在线解码:一个chunk一个chunk解码,每次解码了一个chunk后,就去更新immortal token和prev_immortal token(在所有active tok里找公共祖先(emitting[0],或者说tokenOne),作为immortal tok,把前一次的immortal tok作为prevImmortal tok),每次在两个immortal tokens之间的路径寻找(backtrace)是否有唤醒词,实现了逐chunk搜索。
每处理过一段固定长度的录音后,我们用更新不朽token算法来回溯最近两个“不朽token”中间的这些帧,检查这部分回溯是否包含唤醒词。如果发现唤醒词则停止解码,如果没有唤醒词继续解码。(不朽token是现存激活token的共同祖先)
这个是基于这样一个假设:如果现有的存活的部分假设都是来自于前一个时刻的相同的token(不朽token),同时在这之前的所有的假设都已经压缩到了这一个token上,我们就可以从这个“不朽token”检查是否具有唤醒词 [csdn]
伪代码 online decoding:

- 更新immortal token,用于回溯

代码实现
The code and recipes are available in Kaldi [24]: https://github.com/kaldi-asr/kaldi/tree/master/egs/{snips,mobvoi,mobvoihotwords}.
本文中引入了一种不需要对齐(Alignment-free)、不需要词图的(Lattice-Free MMI)鉴别性准则训练的模型
相比Lattice-free MMI准则需要额外修改一下发音字典、HMM拓扑结构
1.HMM拓扑结构(KW和freetext)用的是5个状态;silence用的是2个状态,但是保持(Lattice-free MMI)的结构self-loop-pdf和forward-pdf对应两个不同的PDF-id,因此神经网络共82+21=18个pdf
2.分子图与分母图
分子图和chain的不同点在于:不需要依赖对齐结果生成label对应的图,生成一个非扩展的fst,在训练过程中通过前后向算法更加灵活的学习对齐结果
分母图和chain的不同点在于:phone级别的语言模型不再需要通过训练数据训练得到,直接手动生成一个语言模型fst,一共3条路径,关键词路径、freetext、silence,其中关键词和freetext前后都可加silence。每一条路径上的权重受训练数据中正负样本的占比因素影响
3.声学模型
使用TDNN-F模型(因式分解的TDNN),将一层的参数矩阵分解成两个低秩矩阵、第一个矩阵强制限制为半正定矩阵
模型(20层每层80节点)存在跨层连接,前一层的输入乘上缩放比例0.66与本层输入加和。
4.数据预处理和增强
对于负样本(存在很多样本时长较长)会按照正样本的时长分布,对负样本进行切段,每一段分配一个负样本标签。
增强:尽管训练数据很多是在实际场景中录制的,增强后效果仍然后提升
5.解码
手动构造词级别的解码网络FST,每条路径上的权重生成和分母图的LM-fst图方式是一样的。在开始token和结束token上增加从结束token到开始token的空边,原因是音频中可能存在唤醒词和其他可能的音频交叉现象。
在线解码的过程中:每处理过一段固定长度的录音后,我们用更新不朽token算法来回溯最近两个“不朽token”中间的这些帧,检查这部分回溯是否包含唤醒词。如果发现唤醒词则停止解码,如果没有唤醒词继续解码。(不朽token是现存激活token的共同祖先)
这个是基于这样一个假设:如果现有的存活的部分假设都是来自于前一个时刻的相同的token(不朽token),同时在这之前的所有的假设都已经压缩到了这一个token上,我们就可以从这个“不朽token”检查是否具有唤醒词
实验
由于freetext只用一个HMM,因此不支持于自定义唤醒词,可应用于小模型的需求。
路径:24.3:/home/data/yelong/kaldi/egs/mobvoihotwords/v1
命令词:
sil freetext 上一曲 下一曲 减小音量 增大音量 小源小源 播放 暂停 静音
数据准备
- 不用run_e2e.sh脚本里的随机切割得到负样本,而是用对齐信息,得到边界,可以避免把静音对成freetext
- ==把带有关键词的负样本删掉==
切割长负样本到短负样本
1 | work_dir=/home/storage/speech/kaldi/egs/keyword/s5 |
去掉存在长静音段的负样本,然后按与正样本长度差不多的随机切割,这是因为正样本有前后静音,如果负样本只有发音段,不太好,因此把存在小的前后静音段考虑进负样本中
把静音区域大于1s的负样本丢弃:
1 | python local/phone2word.py data_hua/ali_12000/ctm > data_hua/ali_12000/output_ctm |
筛选出neg_segments:
1 | utils/filter_scp.pl data_hua/ali_12000/output_ctm data_hua/data_all_sub2_Xiaoyuan_12000_whole/segments > data_hua/data_all_sub2_Xiaoyuan_12000_whole/neg_segments |
筛选出正样本(开头SY、Xiaoyuan、sp的)
按照正样本长度范围切割负样本:
1 | srcdir=data_hua/data_all_sub2_Xiaoyuan_12000 |
把长度太短的(小于0.5s)、太长的删掉(大于5.05s)
data_hua/data_all_sub2_Xiaoyuan_12000_segmented_e2e_cut:正样本正负样本比例:正样本433万条,负样本1635万条,正负样本比例1:3.7(接近1:4)(不好,应该减少正样本的比例)
2021.11.23新:正样本233w,负样本1635万条,正负样本1:7
2021.11.27新:发现split5测试集的唤醒率不高,原来是没有把9w条Xiaoyuan数据都用了,只用了4.5万条,把9w条需要都加入进去才行,正样本237万,负样本1635万,正负样本1:7【训练出来效果很差,不知道为什么】
模型
tdnnf结构,13层,dim=80,bottleneck dim=20,左拼27帧,右拼27帧,参数量 111388(113k)
74个分类状态(2* (9* 4+1) =74),sil:1状态,freetext、keyword:4状态
训练很快
实验测试结果
-
实验结果分析
- 正负样本1:4时:
- 声学模型输出在同一帧中有很多分类的概率都挺高,说明声学模型效果不好,但是还能得到测试集唤醒率高、误唤醒率低的唤醒词,说明后面接的G还是挺关键的
- 其他唤醒词误唤醒率很高,不是喊该命令词时,也会唤醒,比如喊小源没唤醒,但是会误唤醒其他唤醒词,因此不能把很多命令词都当作唤醒词,就是即使把命令词放在唤醒词后面唤醒,也很容易出现喊命令词却识别成另一个命令词的情况,我们希望的是即使不唤醒,也别唤醒成别的。对多唤醒词任务不友好。
- 正负样本1:7时:
- 其他唤醒词误唤醒率相较于正负样本1:4的模型下降许多
- 唤醒率低,容易识别成freetext,考虑通过增加每个HMM的topo状态数来缓解[TODO]
- 过拟合比较严重,对未见过的样本识别率很低,可能是因为建模单元颗粒度大(词),建模topo结构状态数少
- freetext后接keyword的输出很少见,应该是和训练相关。
- Alignment-Free当模型为tdnnf,13layer,80_20,参数量100K,状态数30时,很容易过拟合,说明模型太小时,不具备大建模单元(一个词用4状态表示)的建模能力;
TODO
- 增加topo建模状态数
- alignment free LF-MMI对齐lattice训练regular LF-MMI