Hey Siri: An On-device DNN-powered Voice Trigger for Apple’s Personal Assistant 2017.10
DNN分数:路径分数(贪心)
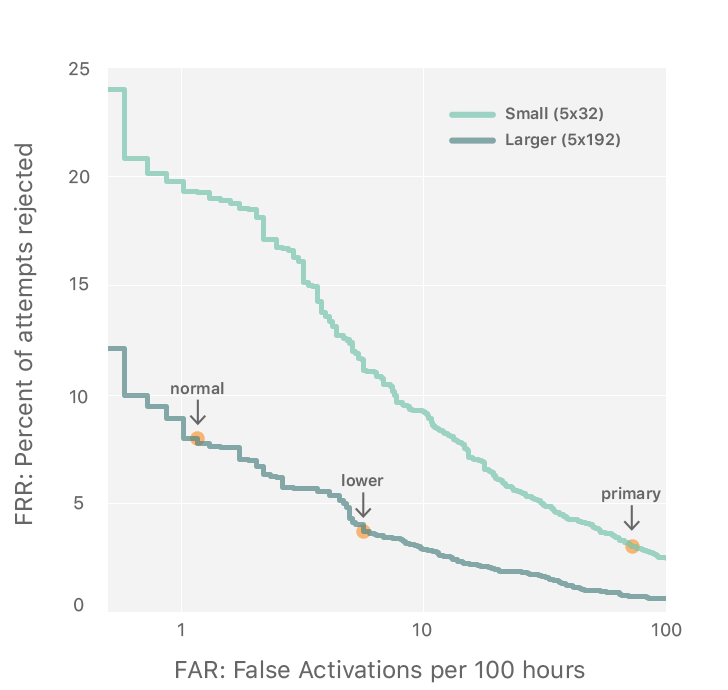
三个阈值,一个阈值在small DNN中,两个阈值在large DNN中;
large DNN,一个正常阈值(normal),一个较低阈值(lower);当超过较低阈值时,但没有超过较高阈值,系统会进入一个更敏感的状态几秒钟,如果此时用户重复了命令词,就可以轻易唤醒。
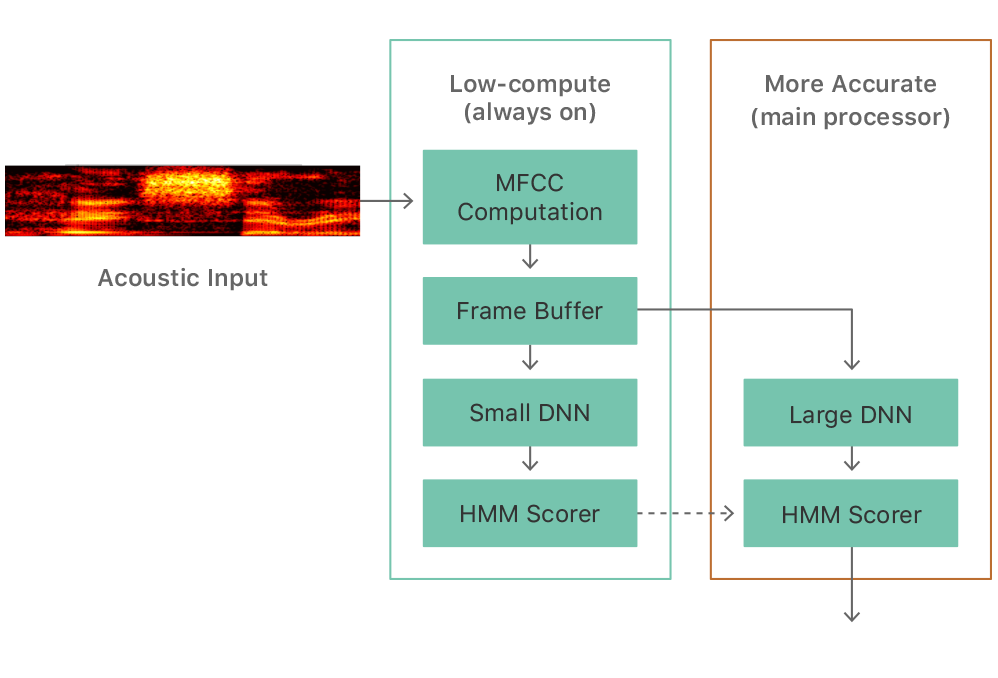
- Always On Processor (AOP) (a small, low-power auxiliary processor, that is, the embedded Motion Coprocessor)
- 经过小的DNN的分数超过阈值(primary),则原信号再进入大DNN进行处理(没超过阈值,不会进入大DNN)When the score exceeds a threshold the motion coprocessor wakes up the main processor, which analyzes the signal using a larger DNN.
- 小DNN:5层,32节点;大DNN:5层,192节点;In the first versions with AOP support, the first detector used a DNN with 5 layers of 32 hidden units and the second detector had 5 layers of 192 hidden units.
- DNN分数:对关键词phrase做强制对齐,得到关键词边界,计算边界内的路径分数;
声学模型训练
- 每个phone三个状态建模 phonetic symbol results in three speech sound classes (beginning, middle and end)
- 训练的时候用了先验,这个先验会很不平均,要补偿(设置成一样?)
- 调整阈值,把lower阈值设置为允许far大一点的位置,normal阈值设置为far小一点的位置
语音识别基本法(清华) 语音识别实际问题:(九)关键词识别与嵌入式应用 2020.8
滑动窗口
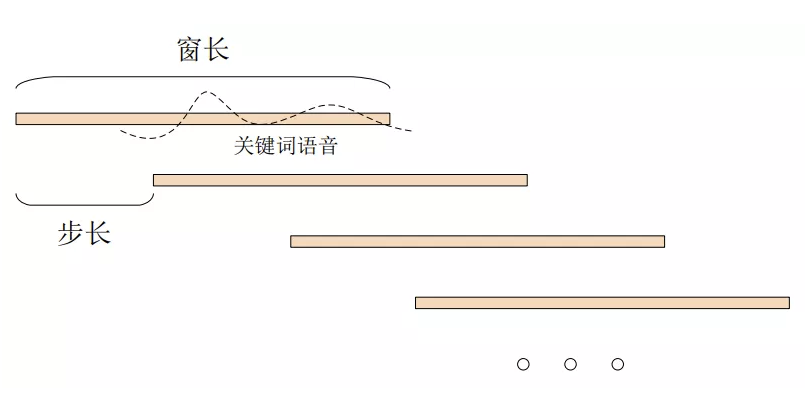
- 滑窗机制包含了一个无法覆盖的关键词语音(?),相邻的数个窗口之间可以并行计算,且窗口之间重叠部分的中间输出结果可以重复利用。
- 假设窗长为window,窗口滑动步长为step,某个命令词语音时长为cmd,为了保证该命令词不会漏检,则需要保证step+cmd < window;而为了该词不被重检,则需要在检出一个关键词时,直接丢弃该窗口内的语音,不再参与下一次识别。
Small-footprint
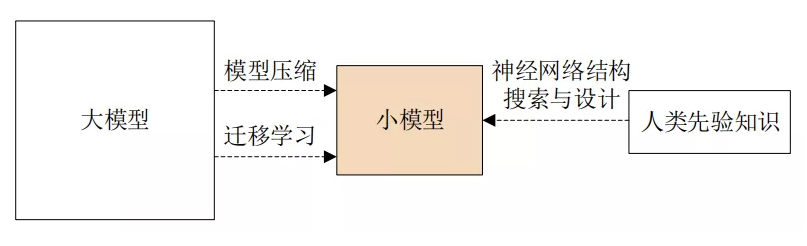
模型压缩(Model Compression)
训练大模型、网络修剪、网络微调(Fine-tuning)
- 点、边
- 损失函数对参数的海森矩阵(Hessian Matrix)[105,106]。我们常用的一阶范数(L1-norm)、二阶范数(L2-norm,Weight Decay)正则化方法本质上都是限制权重的值,使其尽可能趋近于0,从而自动学习到稀疏结构,然后可以将权重为0或极小的边直接剪掉,或者用于下一步的网络修剪。
- 彩票假设(The Lottery Ticket Hypothesis)[107]
- 权重
- 权重的等价存储或高效存储是模型压缩的重要手段。对权重的量化(Quantization)、二值化(Binarization)可以将原始网络中一个浮点数参数由更少的位数来表示,而不明显影响模型性能,也可以直接从头训练一个事先固定好参数位数的网络。
- 编码是数字存储中必须要考虑的问题,神经网络的所有权重就是一堆位置相关的数字,也直接决定着模型大小,对这些数字可以采用更加高效的组织形式或编码算法,如哈希桶(Hash Bucket)[108]、哈夫曼编码(Huffman Coding)[109] 等
- 子结构
- 卷积神经网络的卷积操作就使用了共享过滤器(及其参数)的机制;奇异值分解(Singular Value Decomposition,SVD)和低秩矩阵分解(Low-rank Matrix Factorization)等手段都是使得一个较大的权重矩阵可以由更小计算规模的矩阵表示;模型训练前便限制权重矩阵的格式,比如限制其为一个对称矩阵,缩减一半参数量;特定子结构的修剪,比如卷积神经网络以滤波器为单位进行修剪[110]。
迁移学习(Transfer Learning)
- 师傅带着徒弟学习(将一个网络的结构和参数用于另一个网络的初始化也属于迁移学习,但这样的迁移学习是同等规模的网络迁移)。
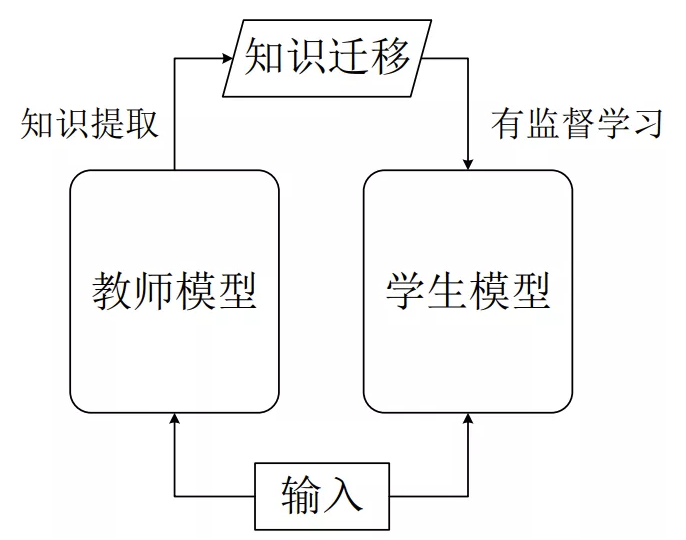
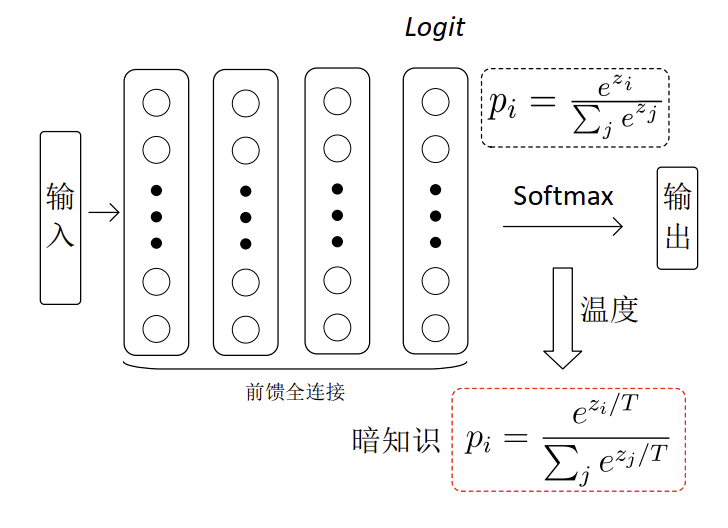
- 迁移学习中一个重要的问题是如何显性表征教师模型的知识,或者是学生模型要学习的目标,其中一个常用的手段则是知识萃取(Knowledge Distillation)[111]。考虑一个典型的深度神经网络分类器,网络经过Softmax后的最终输出本身已是一种知识表征,但为了增加Softmax输出的“柔韧”度,可以引入一个可调系数,记为温度(沿用了能量模型中的相关概念),并将知识拓展为暗知识(Dark Knowledge),该表征可以作为学生模型的学习目标。
网络结构搜索与设计
- 修剪一个模型,结构的重要性大于权重 。让机器自行进行神经网络结构搜索(Neural Architecture Search,NAS)[112]。
- 常见的精小人工设计网络结构都基于卷积神经网络,包括 MobileNet[113, 114]、ShuffleNet[115, 116]、 EfficientNet[117]等。
==Arik S O, Kliegl M, Child R, et al. Convolutional recurrent neural networks for small-footprint keyword spotting[J]. arXiv preprint arXiv:1703.05390, 2017.==
思想
- 用CRNN做分类,命令词
- 适用于低信噪比环境
- 输入特征perchannel energy normalized (PCEN) mel spectrograms,经过二维卷积提高维特征,送入双向GRU,因为用了双向,因此推理时需要等输入输完后(1.5s输入)才能进行计算,有1.5s延迟;
训练
- PCEN -> CNN -> BRNN -> DNN -> SoftMax


- 伪代码看不是很懂??
- 使用CE loss,平滑分数
实验
- 输入40*151(1.5s)PCEN特征
- 网络结构:一层CNN层,两层RNN层(64个节点)
- 在Deep Speech2上训练
- 没有和其他文献中模型对比,模型对比,采用的是不同神经元节点/gru/lstm对比
- 对比的是不同信噪比下、不同远场距离下的frr/far曲线
- gru优于lstm
==Lengerich, Chris, and Awni Hannun. “An end-to-end architecture for keyword spotting and voice activity detection.” arXiv preprint arXiv:1611.09405 (2016).==
思想
- 用一个模型,解决KWS和VAD任务,但是这样,就等于一个网络要一直检测VAD,能耗就高了
- PS. 我们现在的做法:VAD没有用网络,降噪后的信号进入VAD检测,若触发,则把降噪前的信号送进KWS网络。
训练
- CRNN结构、ctc loss、输出字母、blank、空格
- VAD推理置信度分数:$\large{logp(speech|x_{t:t+\omega})=1-\sum\limits_{i=t}^{t+\omega}p_i(\epsilon|x_{t:t+\omega})}$
- KWS推理置信度分数:每100ms走命令词(包含建模单元间blank)文本路径,得到路径分数,累计800ms,得到一个置信度分数
实验
- kws baseline:https://github.com/Kitt-AI/snowboy
- vad baseline:https://github.com/wiseman/py-webrtcvad
- 结构:1 层 CNN(filter尺寸11*32,stride=3,filter数量32)、3 层 RNN(256 hidden),1.5M参数量
- 不带噪声数据集:正样本1544条,负样本526k;带噪声数据集:正样本1544*10条,负样本526k +57k.
- 训练集组成 KW + KW-noise > KW + KW-noise + noise > KW,即“只对正样本里加噪声,负样本不加噪声”优于“额外加负样本噪声”
==Sigtia, Siddharth, et al. “Efficient Voice Trigger Detection for Low Resource Hardware.” INTERSPEECH. 2018. citation:20== Apple
思路
- two stage 一个简易的网络,普通的阈值,超过阈值,才把原信号输入kws网络,类似vad、kws思路
- minimum duration constraint :每个phone用一个状态建模,每个状态至少持续n帧,n为3、4时,效果好(我现在是每个状态至少持续1帧,可以尝试该方法),是改帧长 or 解码时添加约束?
- frame rate:帧移,因为hmm假设,所以帧与帧之间不要重叠?帧移为n,帧移60ms不错(我现在是帧移10ms,可以尝试该方法)
- 实现每个phone至少持续n帧的方法:比如 小源小源对应的words是 x x x iao iao iao vv vv vv van van van这样??【这种效果没有送进解码器进行下采样效果好,差一点点】
实测效果
- ==下采样确实会让far降低很多==
吴本谷:今天带来一篇模拟远场数据的论文用在唤醒上。论文题目:A study on more realistic room simulation for far-field keyword spotting,地址:https://arxiv.org/pdf/2006.02774.pdf 。这篇文章的主要思想就是生成RIR来提高远场唤醒的性能,使用image source method (ISM) 来生成,也提供了对应的工具箱。https://github.com/LCAV/pyroomacoustics;https://github.com/ebezzam/room-simulation。用这种生成的RIR在未知的场景下可以有效的提高唤醒率。基本这种方法也是通用办法。如果生成多种多样的RIR,以及如何高效的跑起来。kaldi里的wav-reverberate类似,但kaldi里的rir是实际场景搞出来的,模拟的话可以生成很多种类。有兴趣的可以使用试试。
之前还有一个版本的用GPU生成RIR的,地址:https://github.com/DavidDiazGuerra/gpuRIR .
因为interspeech很多人收到接受的邮件,所以最近感觉arxiv上论文有点多。今天继续带来唤醒的论文,这些apple跟amazon的团队的两篇唤醒论文。
1.Stacked 1D convolutional networks for end-to-end small footprint voice trigger detection
2.Accurate Detection of Wake Word Start and End Using a CNN
第一篇论文来自apple团队,跟20200807那个每日分享的论文基本两个思路,这个是在网络结构上动的功夫,把SVDF引入到唤醒,可以保证性能不怎么变的情况下,模型大小变小。SVDF又可以用CNN来弄,所以变成2个CNN层来弄就可以了。这个想法是借鉴谷歌论文的思想,地址:http://150.162.46.34:8080/icassp2019/ICASSP2019/pdfs/0006336.pdf 。
同时,论文在DNN-HMM的框架下跟E2E下来验证性能:
做唤醒的标配做法吧,如果计算资源不够,可以尝试下。
第二篇论文是亚马逊的唤醒做法
我们之前在介绍亚马逊一直是基于二级模型做的,然后也是keyword-filler的方案。但这篇论文一改之前的方案,直接基于DNN-KWS的方法来。而且更直接,直接提取特征,训练了一个2分类的模型。
直接拿一段时间的频谱特征,输出就是是否是唤醒词。但这个方案没法有起点跟尾点的检测,那么就来个方案是:
直接把之前唤醒词建模的网络freeze掉,然后来搞起点跟尾点的检测。此外,也尝试放在一起搞的方案,最终论文发出来了,效果当然也不错。这个思想其实挺好的,会抛弃原来建模的一些思想,但我理解就是比较难训练。
做唤醒的同学可以认真看看这些论文,值得好好研究。基本唤醒就这么多做法。相信后面也不会突破这些基本的框架体系。
好的,祝大家学习愉快。
==Sigtia, Siddharth, et al. “Multi-task learning for speaker verification and voice trigger detection.” ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2020.==