端到端命令词识别
==Yiming Wang et al. “Wake Word Detection with Streaming Transformers” International Conference on Acoustics, Speech, and Signal Processing (2021).==
github代码:https://github.com/freewym/espresso
思想
- 之前的transformer是非流式,需要输入一整个序列,知道transformer-XL提出流式后,才能流式,但是transformer适用于长序列,没有文章表明对于短序列(比如唤醒任务)效果也好,本文做了实验;
- 唤醒任务不关心唤醒词出现在序列的哪个位置,只关心有没有出现,因此不用transformer提出的基于整个句子的position embedding,而是采用相对位置编码relative positional encoding,将位置编码为层的隐藏值;
- $Q=W_QX$,$=K=W_KX$,$V=W_VX$ $\in{\mathbb{R}^{d_h\times{T}}}$
- $h_i=(V+E)a_i\in{\mathbb{R}^{d_h}}$, $\large{a_i=softmax(\frac{[Q^T(K+E)]_i}{\sqrt{d_h}})}\in{\mathbb{R}^{T}}$
(之前是:$h_i=Va_i\in{\mathbb{R}^{d_h}}$, $\large{a_i=softmax(\frac{[Q^TK]_i}{\sqrt{d_h}})}\in{\mathbb{R}^{T}}$)
- state-caching是选择哪些参数来更新,之前的参数要不要更新(gradient stopping)
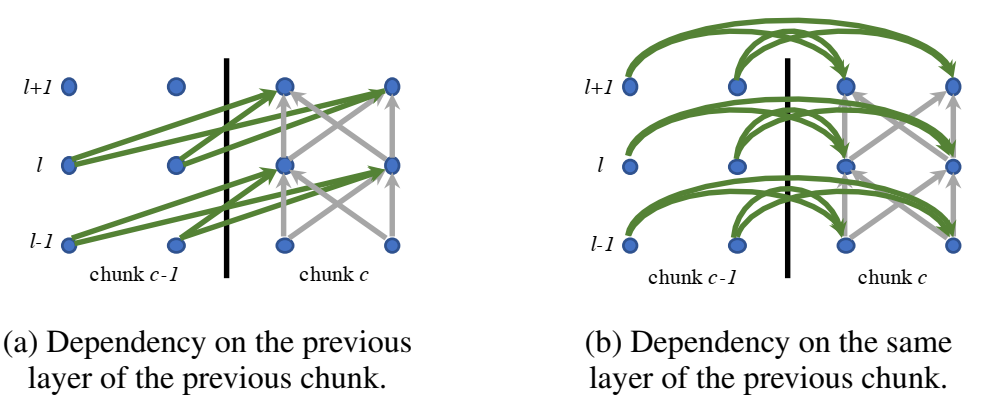
- 本文探索了look-ahead of the future chunk, and different gradient stopping,layer dependency, and positional embedding strategies 对性能的影响
网络
baseline:5层1维空洞卷积 dilated convolution,48个filter,kernel size=5, leading to 30 frames for both left and right context ,58k参数量
streaming transfomer:前两层1维卷积,然后3层attention层,32维embedding,4head,48k参数量
chunk size 27,27是实验得到的最优值,太短了效果下降,太长了效果没有明显改善但是带来了延迟
实验
mobvoi数据集
初始学习率1e-3,Adam,学习率减半,epoch不超过15,或者学习率小于1e-5停止训练
学习率warm-up在该实验中无效,可能由于任务简单
建模单元是?
结果
- 效果劣于Alignment-free LF-MMI;
- without state-caching效果优于with state-caching;
- stream transformer一定要加 look-ahead chunk,看见未来信息,不然效果不好
- 用相对位置编码relative positional embedding 更适合唤醒任务,这个embedding放在value上效果更好

- 最好的一组:without state-caching,transformer + look-ahead + relative embedding to value,每小时虚警0.5次的条件下,“hi xiaowen”误拒率0.6%,“nihao wenwen” 误拒率0.6%
==Sun, Ming et al. “Max-pooling loss training of long short-term memory networks for small-footprint keyword spotting.” 2016 IEEE Spoken Language Technology Workshop (SLT) (2016): 474-480.== citations:93
思路
输入t帧语音特征,输出t帧*类别,二分类,word level labels,关键词alexa和非关键词background
提出max-pooling loss,是在keyword区域内模型输出的最大后验概率,加入loss function(目标之一是最大化keyword输出的某帧后验概率)
后处理:每30帧计算一次是否触发,30帧的滑动窗口,平滑窗口内的后验概率,若大于阈值,视为触发,触发后的40帧不再计算(lock out period),以免重复触发;有触发的音频发送完后,会多送入20帧(latency windows),以防没送完。
loss function:$\large{L_T^{maxpool}=-\sum\limits_{t\in{\hat{L}}}lny_t^{k_t^+}-\sum\limits_{p=1}^Plny_{l_p^+}^{k_p^+}}$
其中:$\hat{L}$是非keyword区域的其他区域,$l_p$:keyword帧区域;$k_p^+$:target keyword label;$l_p^+$:keyword帧区域内的最大后验概率对应的帧,$k_t^+$:target nonkeyword label
也就是说,只有keyword区域时,用第二项计算,非keyword区域时(positive sample里的非keyword区域也算),用第一项计算;
因此非keyword计算/更新的帧远多于keyword参与计算/更新的帧数,会有正负样本不平衡的问题;
为了减少匹配keyword初始段的类似帧的误触发,将当前帧与左右相邻帧进行堆叠,再送入DNN,作为baseline。
网络
- LSTM
- 参数量:$n = n_c×n_r×4+n_i×n_c×4+n_r×n_o+n_c×n_r+n_c×3$
实验
- LSTM参数量118k,随机初始化时,ce loss的初始学习率0.00001,max-pooling的初始学习率0.00005;ce模型作为初始预训练模型时,max-pooling的初始学习率0.00005 ;
- 数据集非开源,用了大量房间内的远场数据
结果
- 比CE训练得好;其中,ce预训练模型再用max-pooling loss训练的模型效果最好
启发
- 逐帧出分类结果的适用模型是看得范围比较远的模型,比如lstm,甚至我感觉lstm后面区域的帧分类结果才比较准确,因为只看前面几帧,比如读一个“小源小源”的“小”,就要求lstm二分类,分类正确,这着实有点为难了(对于单向lstm来说),因此小区域的cnn(tdnn)还不是很适用,大感受野的cnn、lstm会比较使用于逐帧都有分类结果的任务。
==Hou, Jingyong, et al. “Mining effective negative training samples for keyword spotting.” ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2020.==西北工业大学
==github开源代码==:https://github.com/jingyonghou/KWS_Max-pooling_RHE KWS_Max-pooling_RHE
引言
- 把最近的KWS架构分为两种:
- keyword/filler posterior modeling followed by a search algorithm;最近都是alexa那种hmm
- end-to-end (E2E) based architectures ;把keyword作为建模单元,逐帧判断是否是keyword,二分类任务(如果只有一个keyword)
思想
- 针对论文“Max-pooling loss training of long short-term memory networks for small-footprint keyword spotting”使用的max-pooling loss存在的正负样本不平衡的问题,做出了改进:
- 为了缓解对齐标签不准确的影响,训练初期epoch做的max-pooling来自对齐keyword区域内的最大后验概率帧,训练后期的max-pooling来自正样本全句的keyword类别的最大后验概率帧,这是由于后期模型训练得比较好了;[一点点用]
- 在keyword区域的结尾再做max-pooling,而不是中间???
- 训练的正样本里的其他非keyword区域的帧,不用来计算loss了,丢弃之;
- 二分类,只用一个输出结点(sigmoid),而不是原论文的两个结点(softmax)
- 对负样本进行下采样,没有用到负样本的所有帧
- 借鉴目标检测论文“Training region-based object detectors with online hard example mining”提出Mining regional hard examples (RHE) 来缓解类不平衡问题,具体做法:

简单说来,就是负样本的输出概率中,keyword分类的概率高的(二分类keyword分类高于非keyword的)取出来,这些是难训练的负样本;
至于怎么取出来,是把分类高的进行从高到低排序,取出高的,周围一小区域帧就不考虑了(不列入难训负样本),然后遍历所有帧,取出来难训负样本,然后只保留rP帧,P是正样本帧数,r是正负样本比例;
实验
- 数据集mobvoi:
- keyword时长0.3s-2s;
- 谱增广SpecAugment:对每个minibatch里1/3样本time masking,1/3样本frequency masking,1/3样本time masking和frequency masking;
- time masking:随机选50帧特征设为0(mel-filter bank=0);
- frequency masking:在所有帧中,随机选30维(40维特征)特征设为0;
模型
- GRU:2层单向,128结点,一层projection层 ReLU激活函数,128结点;学习率0.0005;
- dilated TCN;第一层1×1的1维causal 卷积,8层dilated causal 卷积,卷积核8,8 dilated rates are {1,2,4,8,1,2,4,8},感受野210帧,relu激活函数,filter数量64;学习率0.01;
- minibatch size=400;Adam optimization;不少于15epoch
- 学习率warm-up(前200minibatch小学习率,逐渐增加至0.0005/0.01);
结果
- GRU优于TCN
- 用“Efficient keyword spotting using dilated convolutions and gating“效果不差
- 负样本下采样的max-pooling相比于负样本全用的max-pooling,有改进一点
- RHE很有用
- 对该数据集 specaugment很有用
- 最佳超参数:正负帧数比例1:10;RHE处理时前后的$\triangle$=200帧(不用再处理的时长)
疑问
- 不是很懂这个到底是比如平滑后验概率和阈值判断,还是逐帧分类?
==Hou, Jingyong, et al. “Region proposal network based small-footprint keyword spotting.” IEEE Signal Processing Letters 26.10 (2019): 1471-1475.==ciations:14 西北工业大学 侯
思路
- 借鉴目标检测领域的anchor-based region proposal network(RPN)jointly optimize keyword detection and location loss function:分类准确度+区域估计准确度
模型
- GRU作为特征抽取器M0,输入声学特征x,输出高级特征h,$\mathbf{h}=M_0(\mathbf{x};\theta)$
- Region classifiction:子网络M1选出一些anchors(keyword起止时间)(分类),输入高级特征h,输出K个anchor分类概率,$\vec{y_t}=M_1(h_t;\theta_1)$,只有一个关键词(唤醒词)的任务,则y是标量,输出一个概率;?一个linear层
- Region Transformation :子网络M2 predicts the transformation needed to extract the full keyword associated with that region (回归)有点像二级,在一级唤醒后才触发,anchor是positive anchor才会计算,输入高级特征h,输出anchor的转换向量,$\vec{p_t}=M_2(h_t;\theta_2)$,每个anchor都有一个$p_t^i$向量,向量元素为平移shifting因子和scaling因子;MSE loss 进行更新,一个linear层
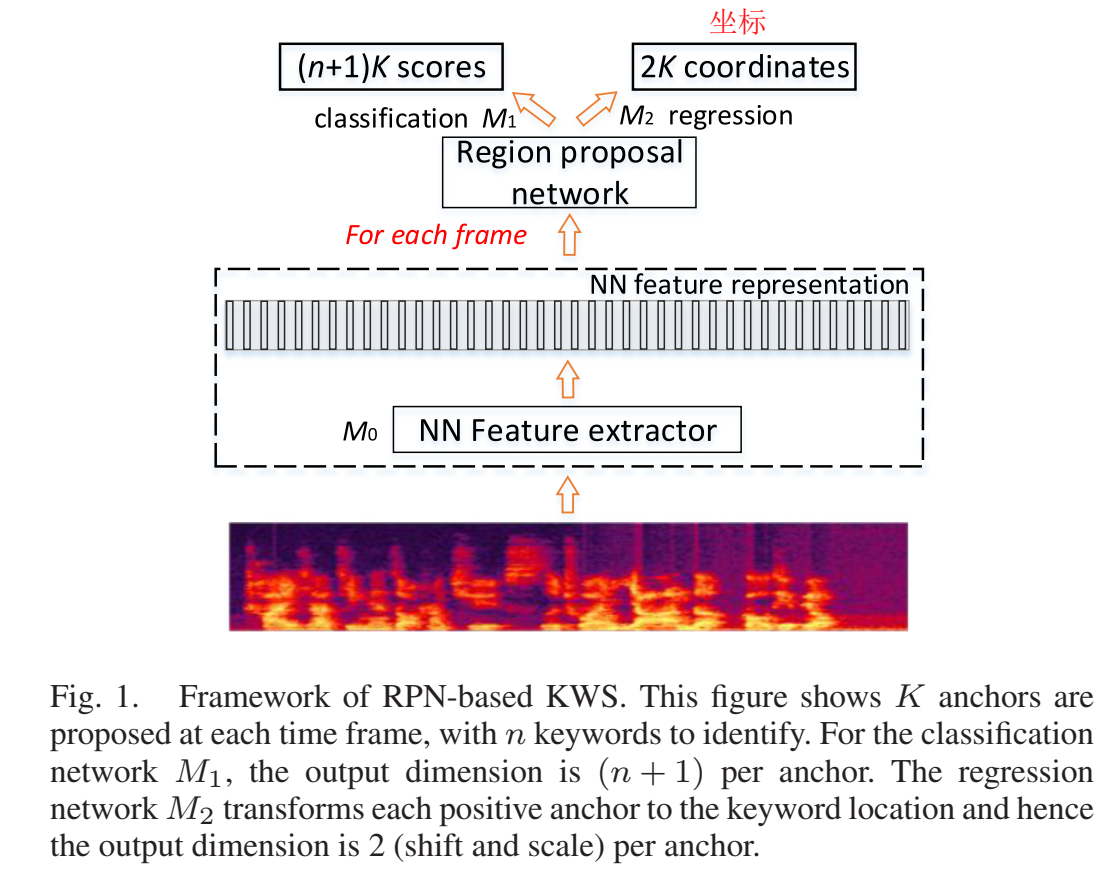
Anchors 锚(框框区域):对每帧t,t作为终止时间,往前一些步作为起始时间,有K个不同的起始时间,K个anchors ,K是超参,用cv集调参;
举例:anchor $P(t_1,t_2)$(一个很小的区域),标签$Q(t_3,t_4)$,(t1、t3表示区域开始帧,t2、t4表示区域结束帧),希望P变换到Q,因此对P做平移u,使得P中点与Q中点重合,在scale v,使得区域长度和Q一样长:
$u=(t3+t4)/2-(t1+t2)/2$
$v=(t4-t3)/(t2-t1)$
用的时候,M2预测的是$\hat{u}=u/l$,scale因子$\hat{v}=log(v)$,其中,$l=t_2-t_1$
确定哪些是positive anchor:用IoU区域判断,大于阈值0.7就认为是positive anchor
$IoU(P,Q)=\frac{P \cap Q}{P \cup Q}$
$P \cap Q = max(min(t_2,t_4)-max(t_1,t_3),0)$
$P \cup Q = (t_4-t_3) + (t_2-t_1) - (P\cap Q)$
ps.论文“Shrivastava A , Kundu A , Dhir C , et al. Optimize What Matters: Training DNN-Hmm Keyword Spotting Model Using End Metric[C]// ICASSP 2021 - 2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2021”也是用了iou,不过是作为loss funciton进行训练的,keyword spotting最近经常使用目标检测提出的方法,可以关注一波目标检测最新的方法;
- 目标函数MTL objective function $\large{Loss=\frac{1}{N}\sum\limits_{i=1}^NL_c(y(i),y^*(i))+\frac{\lambda}{N_+}\sum\limits_{i:a(i)\in{A^+}}L_r(p(i),p^*(i))}$
其中,$A^+$是positive anchor,$p(i)=(\hat{u}(i),\hat{v}(i))$, $L_c$是预测概率 $y(i)$ 和标签 $y_i^*$ 之间的交叉熵,$L_r$是预测转换向量 $p(i)$ 和训练目标 $p^*(i)$ 之间的 MSE loss,所有样本训练M1,只对正样本训练M2
- 推理:找到每帧最大后验概率y对应的,大于阈值,则唤醒?
==Zhang Y, Suda N, Lai L, et al. Hello edge: Keyword spotting on microcontrollers[J]. arXiv preprint arXiv:1711.07128, 2017.== citations:225
思路
- 模型采用 depthwise separable convolutional neural network (DS-CNN)
==Sørensen, Peter Mølgaard, Bastian Epp, and Tobias May. “A depthwise separable convolutional neural network for keyword spotting on an embedded system.” EURASIP Journal on Audio, Speech, and Music Processing 2020.1 (2020): 1-14.==
github开源代码:https://github.com/PeterMS123/KWS-DS-CNN-for-embedded
思路
这篇和”Hello edge: Keyword spotting on microcontrollers”其实很像;
探索降低(scale?)网络复杂度时哪个参数对性能改变最大;
10个词的任务,在ARM Cortex M4
每次处理1s(49帧),20维,每次送入网络的输入是20*49
后处理:1s一个分类,然后帧移动0.25s又计算一次(也就是说1s计算4次),一共延长检测时间为$T_{integrate}$,然后看关键词的平均后验概率有没有超过阈值,然后如果触发了关键词,则后面一段时间$T_{refractory}$不再计算,以免多次触发;
本文$T_{integrate}=0.75s$,$T_{refractory}=1s$;
数据增广的噪声源之一是开源噪声源:TUT database、DEMAND database;通过filtering and noise adding tool (FaNT) 工具添加背景噪声到干净音频中;
噪声添加进音频中分类两类,分为match和mismatch噪声;给训练集添加A噪声,测试带有A噪声的测试集,叫做match噪声集;给训练集添加A噪声,测试带有B噪声的测试集,叫做mismatch噪声集;match噪声集和mismatch噪声集都测试,就知道网络的泛化性如何了。
资源估计:
- Operations 计算量,网络的乘法数和加法数;
- Memory 内存,网络需要储存的参数量
- Execution time 执行时间,用处理器上的timer测量
网络
- DS-CNN网络
实验
- 为了查看(量化)系统复杂度与性能的关系:对比了2层10个滤波器,一直到9层300个滤波器的很多个模型;
- 可以使用更大的学习率,因为每一层的梯度的大小更相似,这导致更快的模型收敛。
- 数据集google speech commands,正负比例8:2
==Bai, Shaojie, J. Zico Kolter, and Vladlen Koltun. “An empirical evaluation of generic convolutional and recurrent networks for sequence modeling.” arXiv preprint arXiv:1803.01271 (2018).==citations:1782
github开源代码: http://github.com/locuslab/TCN
思路
sequence modeling一般使用RNN,本文探讨了CNN能有比RNN更好的序列建模能力,更适合序列任务
提出TCN网络,TCN=1D FCN + dilated casual convolutions
其中,FCN是fully-convolutional network,隐层神经元数量和输入层数量相同,并且0padding,pad长度为(kernel size−1),以保持后一层与前一层的长度相同;
casual convolutions因果卷积:当前t之和之前t有关
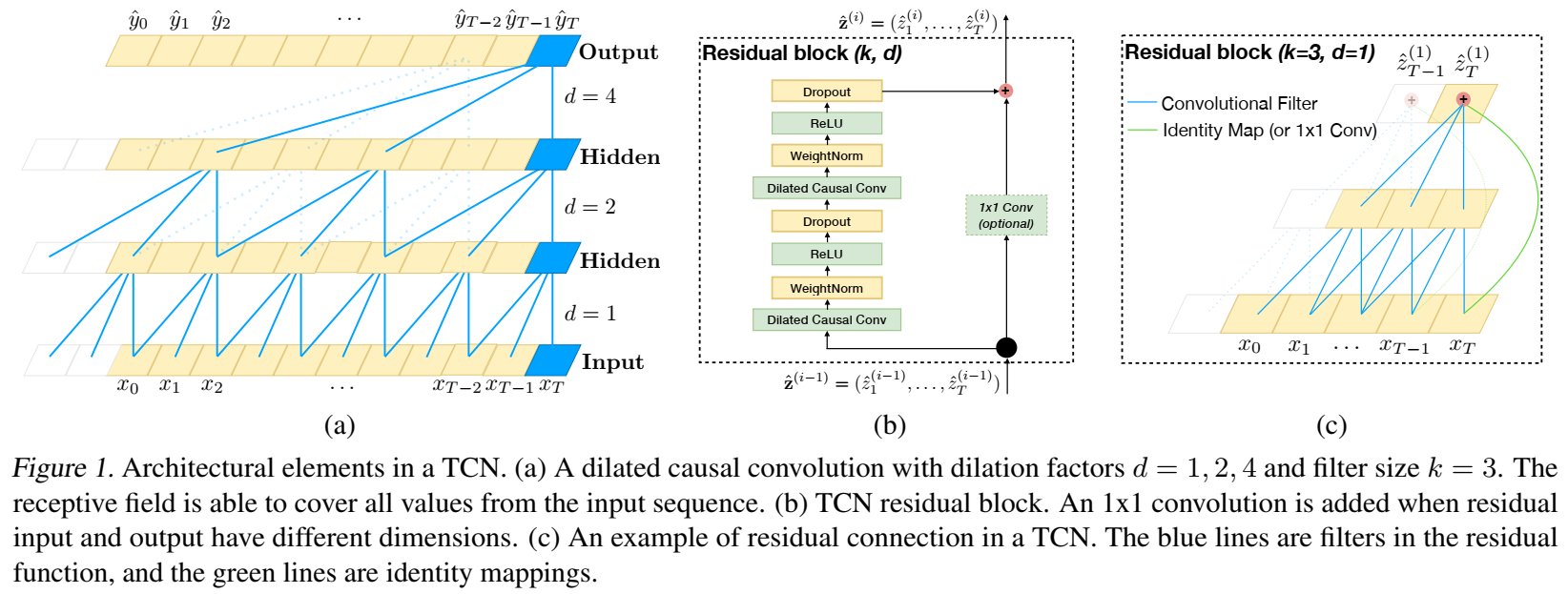
- $\large{F(s)=(x*df)(s)=\sum\limits{i=0}^{k-1}f(i)\cdot{x_{s-d\cdot{i}}}}$
其中,d=1,和普通卷积一样;d>1,对每帧意味着更大的输入范围;
增加TCN感受野的方法:更大的filter size、更大的dilation factor;每层的历史信息=(filter_size - 1)*dilation_factor
残差结构
==Leem, Seong-Gyun, In-Chul Yoo, and Dongsuk Yook. “Multitask learning of deep neural network-based keyword spotting for IoT devices.” IEEE Transactions on Consumer Electronics 65.2 (2019): 188-194.==citations:19 高丽大学
思路
GMM-HMM-Based Keyword Spotting:
输入特征同时进入triphone训练的keyword model和monophone训练的filler model,log keyword路径分数 - log filler路径分数是否大于阈值(log-likelihood ratio),判断是否唤醒;
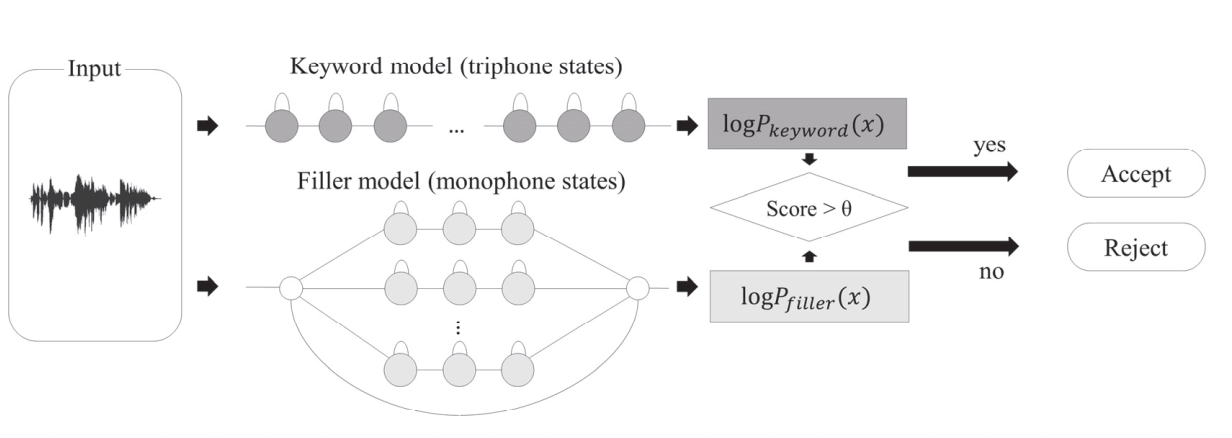
DNN-HMM-Based Keyword Spotting
$P_{filler}(x)=\alpha\max\limits_{k,i}P_{k,i}(x)+(1-\alpha)\min\limits_{k,i}P_{k,i}(x)$
其中,$k$是可能的keyword系数,$i$是状态系数;
[?]filler概率为keyword最大路径分数和最小路径分数加权求和??
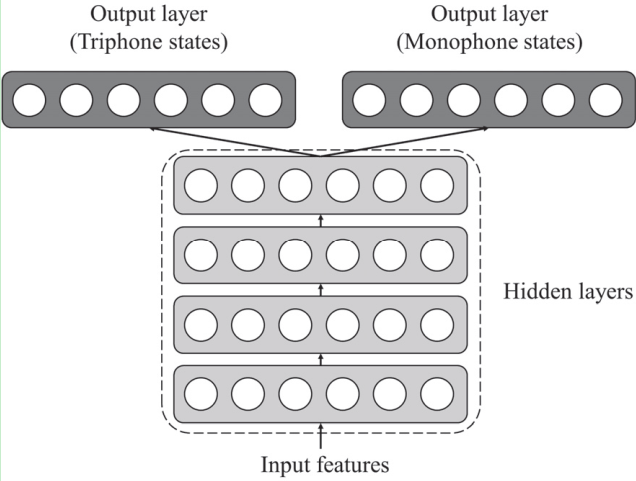
Multitask DNN architecture that predicts both triphone state probabilities for keyword models and monophone state probabilities for filler models
前面层参数都相同,最后一层参数区分,输出keyword或者filler;
这个思路好奇怪,本来是可以简单认为是分类任务,现在把一个分类任务变成两个分类任务
$Loss=\beta{Loss_{triphone}}+(1-\beta)Loss_{monophone}$
Temporal Feedback Convolutional Recurrent Neural Networks for Keyword Spotting
An End-to-End Architecture for Keyword Spotting and Voice Activity Detection