基于Transformer、conformer的识别
==Gulati, Anmol, et al. “Conformer: Convolution-augmented transformer for speech recognition.” arXiv preprint arXiv:2005.08100 (2020).==
github:https://github.com/lucidrains/conformer
思路
- transformer模型善于捕捉基于content的global interaction全部的影响,而CNN善于捕捉local features,结合二者,提出convolution-augmented transformer,称为conformer
模型
- conformer encoder:
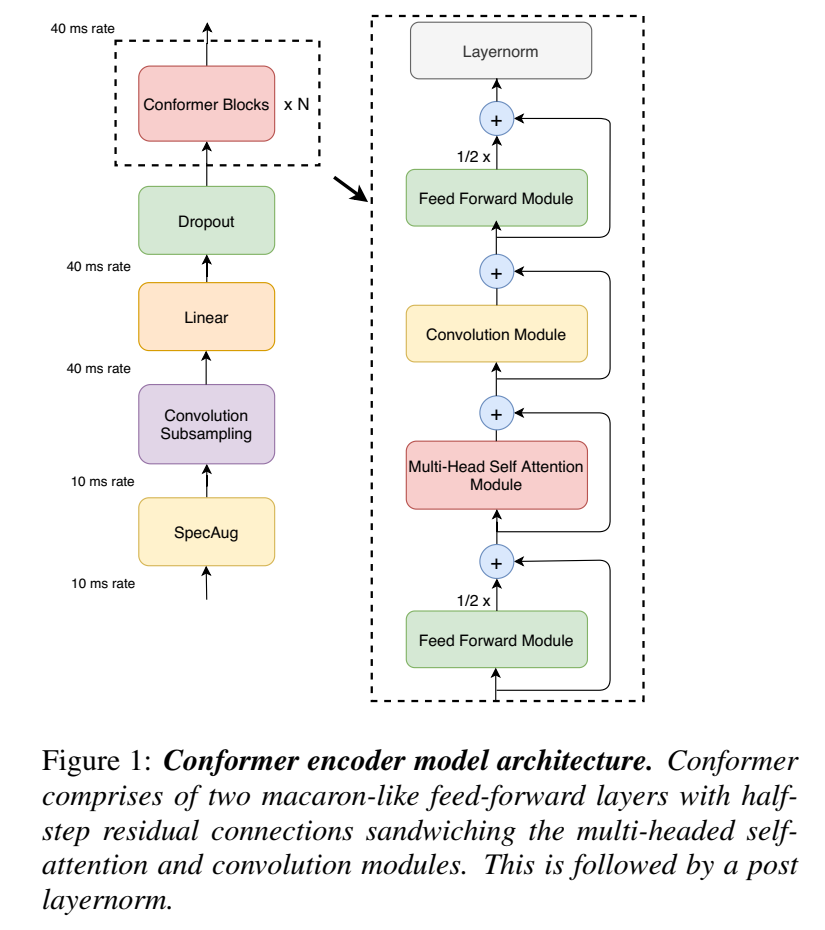
conformer block的输入输出:
$\large \widetilde x_i=x_i+\frac{1}{2}FFN(x_i) $ (Feed Forward Module)
$\large x_i’=\widetilde x_i + MHSA(\widetilde x_i)$ (Multi-Head Self Attention Module)
$\large x_i’’=x_i’+Conv(x_i’)$ (Convolution Module)
$\large y_i=Layernorm(x_i’’+\frac{1}{2}FFN(x_i’’))$ (Feed Forward Module)
- Convolution Module:
- pointwise 卷积(每个channel只被一个卷积核卷),接门激活函数,接linear(gated linear unit(GLU)),接1维 depthwise 卷积

- Multi-Head Self Attention Module:
- multi-headed self-attention (MHSA) ,输入是relative positional embedding,位置编码适用于边长序列,后接prenorm residual units
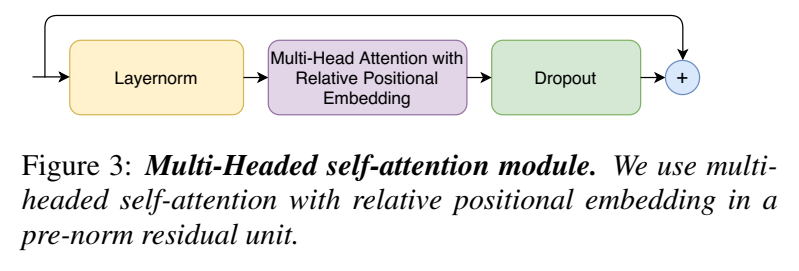
- Feed Forward Module

实验
- 数据:数据用SpecAugment进行增广,mask参数 F=27;进行了10次mask,最大time-mask比ps=0.05[???]
- 训练了参数量为10M,30M,118M的三个模型,decoder用的单层LSTM
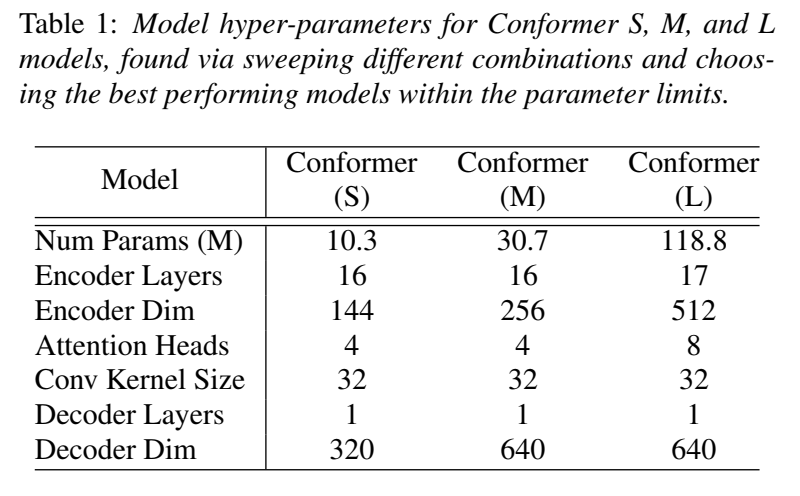
每个residual unit都加dropout,P_dropout=0.1,L2 正则(weight decay)= 1e-6 ,
Adam optimizer ,$\beta_1=0.9$,$\beta_2=0.98$,$\epsilon=10e^{-9}$, transformer learning rate schedule
10k步 warmup,peak learning rate $0.05/\sqrt d$ where d is the model dimension in conformer encoder
语言模型,用3层LSTM,width 4096,10千WPM,和声学模型用权重$\lambda$进行shallow fusion
实现框架用的 Lingvo toolkik
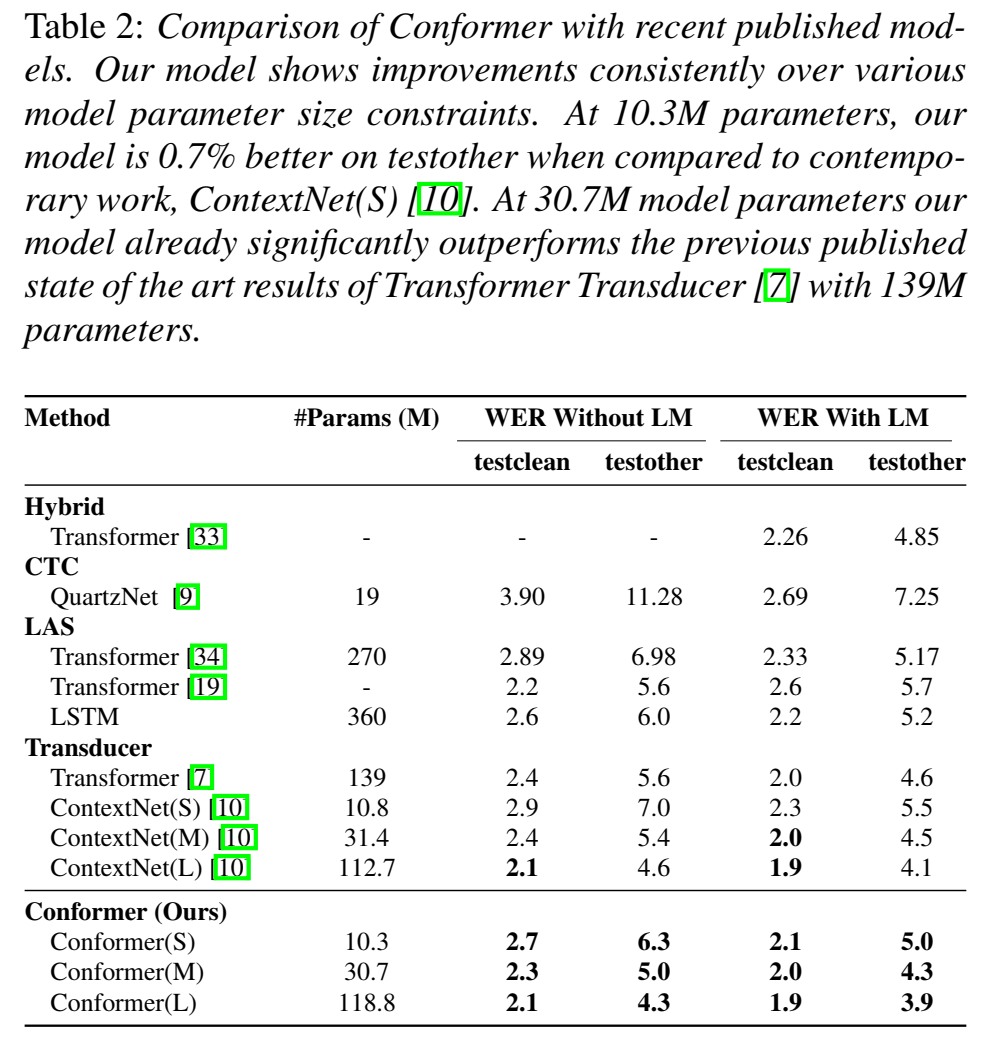
总体的模型对比,和ContextNet 、Transformer transducer 、QuartzNet 进行比较:
- 做了消融实验Ablation ,对比Conformer Block vs. Transformer Block:
- 不同之处:conformer结果用了a convolution block and having a pair of FFNs surrounding the block in the Macaron-style.
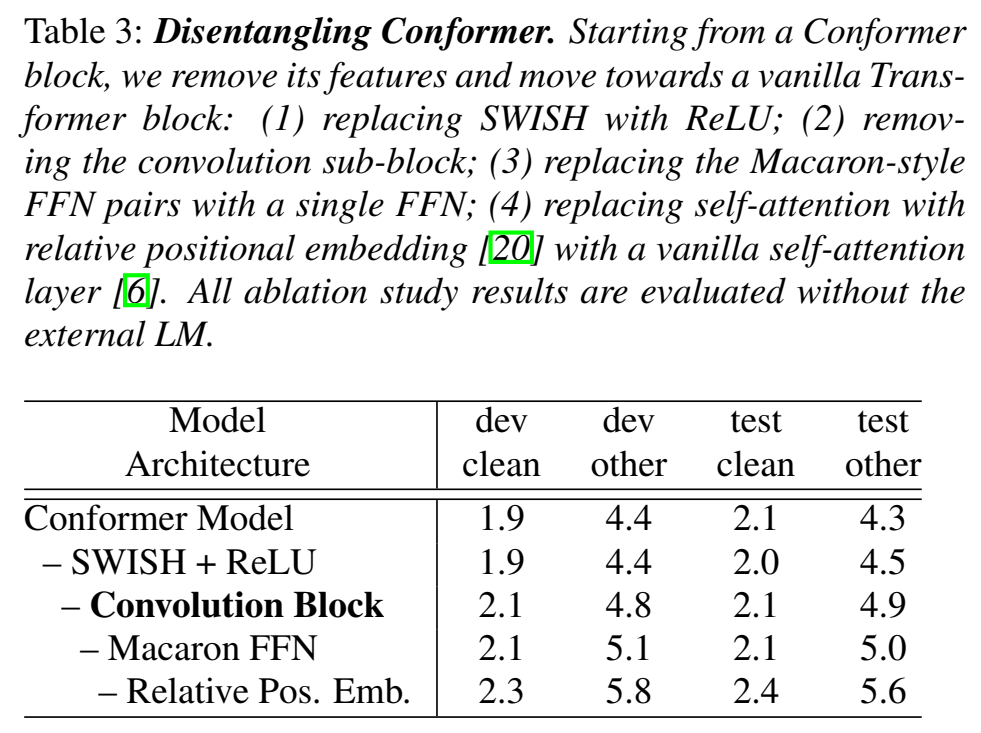
- 消融实验发现,convolution sub-block是最重要的特征
- 同等参数量下,马卡龙结构的FFN pair比单个FFN有改善(两个FFN中间夹着attention和conv)
- 用swish activations 能更快收敛(可能没改善?但是能加速收敛)
- Disentangling conformer,把几个有用的分别用其他代替,看看哪个最影响识别率
- Combinations of Convolution and Transformer Modules :
- 把depthwise 卷积换成 lightweight 卷积,效果马上变差,不ok
- 把convolution module放在MHSA module之前,效果变差一丢丢,不ok,卷积层放在注意力层之后会更好
- convolution module和MHSA module并联,在concatenate,效果变差较多,不ok

- Macaron Feed Forward Modules
- transformer用的single FFN,conformer用的前后两个FNN(称之为FFN pair),包裹中间的 MHSA module和convolution module(像sandwiching 三明治/Macaron 马卡龙结构)
- Conformer feed forward modules are used with half-step residuals
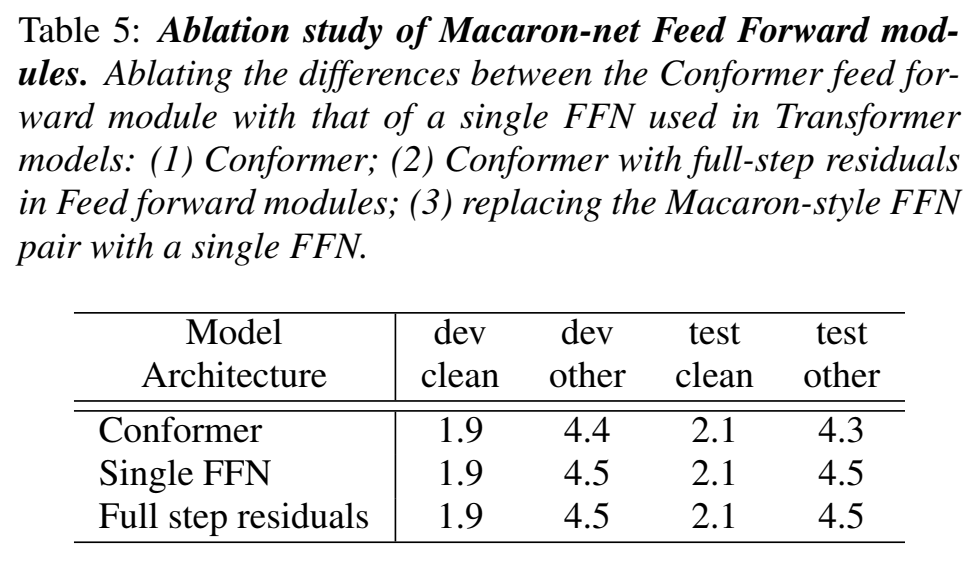
- Number of Attention Heads :不同head数量 、dim的影响,觉得head=16好一点
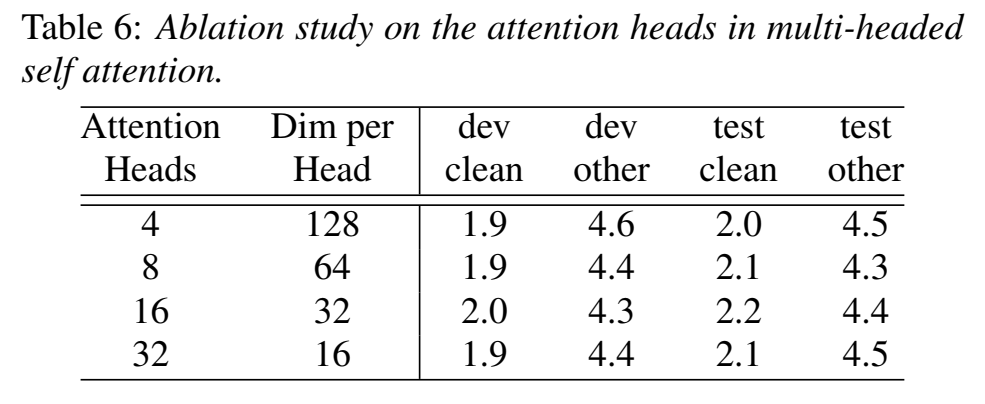
- Convolution Kernel Sizes :在{3, 7, 17, 32, 65} ,kerenl size对性能的改善是先增后降,32最好
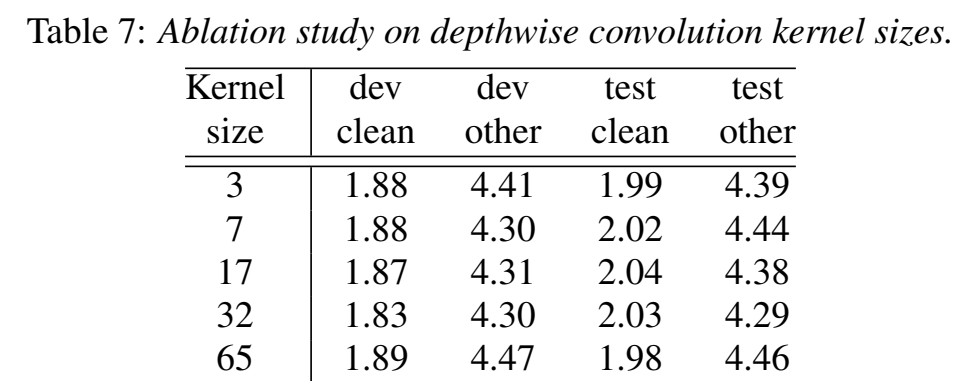
最后两个实验感觉是凑数的
TODO
- swish activations?
- lightweight?
收获
设计模块的方式:马卡龙方式
卷积和自注意力模块的组合方式:卷积在后