END-TO-END STREAMING KEYWORD SPOTTING
EFFICIENT KEYWORD SPOTTING USING DILATED CONVOLUTIONS AND GATING
SEQUENCE-TO-SEQUENCE MODELS FOR SMALL-FOOTPRINT KEYWORD SPOTTING
==Lin, James, et al. “Training keyword spotters with limited and synthesized speech data.” ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2020.==
==Wu, Haiwei, et al. “Domain aware training for far-field small-footprint keyword spotting.” arXiv preprint arXiv:2005.03633 (2020).==
==Chen, Wuyang, et al. “Collaborative global-local networks for memory-efficient segmentation of ultra-high resolution images.” Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2019.== citations:85
github:https://github.com/chenwydj/ultra_high_resolution_segmentation 、https://github.com/VITA-Group/GLNet
思路
- 提出Global-Local Networks (GLNet)
==He, Tong, et al. “Bag of tricks for image classification with convolutional neural networks.” Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2019.==ciations:702
思路
Efficient Training
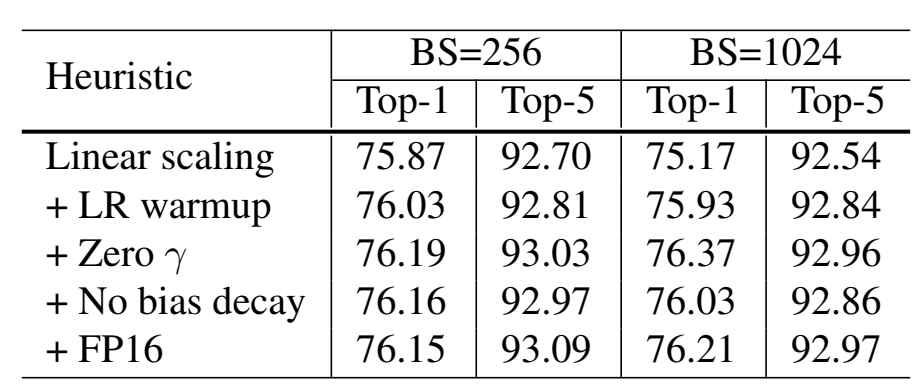
- Large-batch training 认为大的batch会造成精度下降,而且训练更慢,对于凸问题,batch越大,收敛速度更慢。解决方法:
- **Linear scaling learning rate **:因为每个batch里的样本随机,因此梯度下降是随机的,更大的batch虽然也是随机的,但是它的方差更小,因此梯度下降的学习率可以设置更大;
- 举例,batch size 256,学习率0.1,换成batch size = b,学习率则改为 0.1 * b/256;
- Learning rate warmup: 在训练的开始,所有的参数通常是随机值,因此远离最终的解决方案。使用过大的学习率可能会导致数值不稳定。
- **Zero $\gamma$ **:给BN层结尾的residual block(x+block(x))的BN层的超参 $\gamma$ 初始化为0($\gamma\hat{x}+\beta$);这样返回的就是input x,一开始模型结构变得简单更易于训练;
- **No bias decay **:设置bias不需要进行weight decay(L2正则),BN层不进行weight decay;
- **Linear scaling learning rate **:因为每个batch里的样本随机,因此梯度下降是随机的,更大的batch虽然也是随机的,但是它的方差更小,因此梯度下降的学习率可以设置更大;
- Low-precision training 以往的训练都是32-bit floating point(FP32),FLOPS没有低精度FP16高,速度慢,因此部分参数用FP16比较好:
- store all parameters and activations in FP16 and use FP16 to compute gradients
- all parameters have an copy in FP32 for parameter updating
- multiplying a scalar to the loss to better align the range of the gradient into FP16
结果有小幅度的提升:
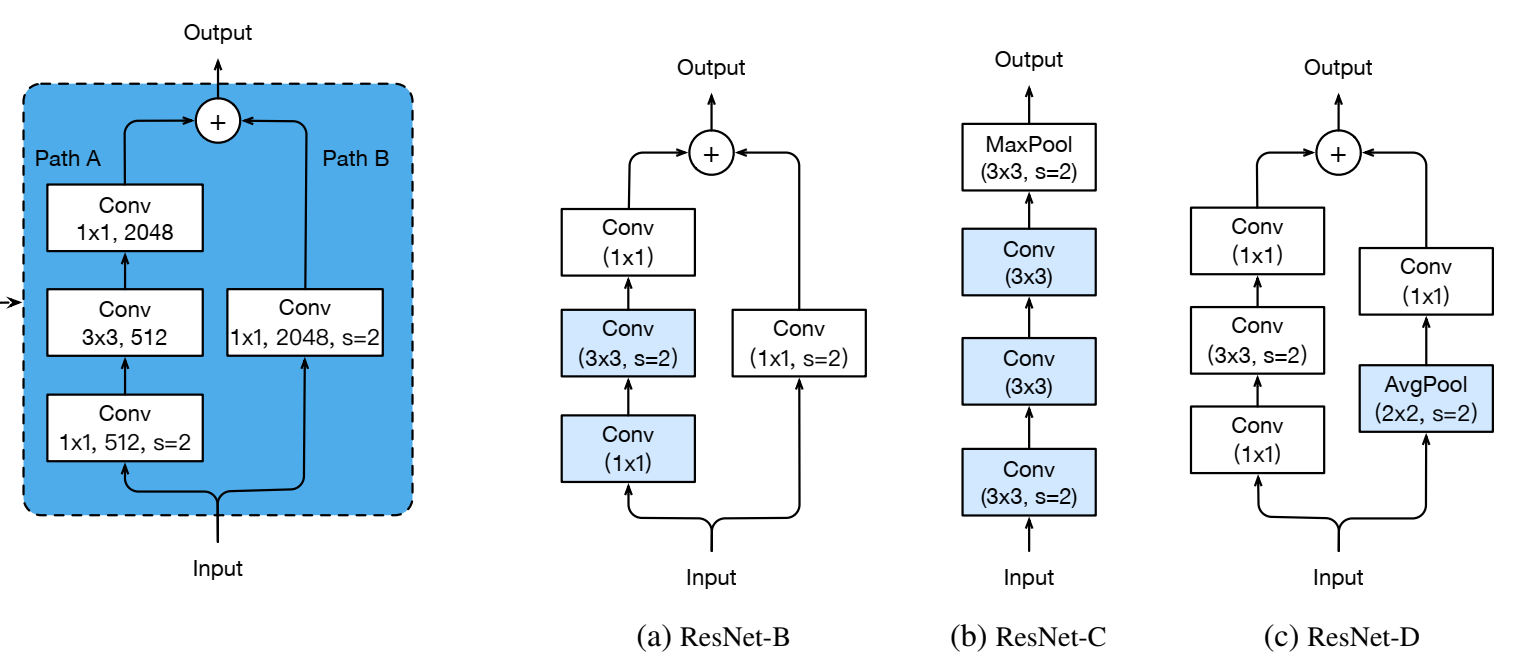
Model Tweaks改变模型结构
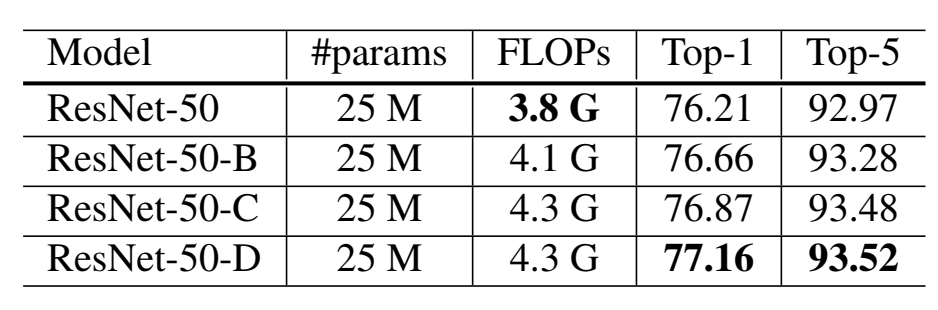
结果都有一定提升:
Training Refinements
- **Cosine Learning Rate Decay **:学习率衰减策略用cos函数
- ==**Label Smoothing **==:
$q_i=
\begin{cases}
1-\epsilon& \text{if i=y}\
\epsilon/(K-1)& \text{otherwise}
\end{cases}$, $z_i^*=
\begin{cases}
log((K-1)(1-\epsilon)/\epsilon)+\alpha& \text{if i=y}\
\alpha& \text{otherwise}
\end{cases}$
K是类别,如果K=2,则分别是1-e,e
- Knowledge Distillation
学生模型倒一层输出$z$,教师模型倒一层输出$r$,真实概率分布$p$,目标函数为 $l(p,softmax(z))+T^2l(softmax(r/T),softmax(z/T))$
T:温度超参,让softmax输出更smooth,从而从教师的预测中提炼出标签分布的知识;
- Mixup Training
- 每个时刻,随机采样两个样本,加权线性插值构造新样本,然后用新样本进行训练;each time we randomly sample two examples (xi; yi) and (xj; yj). Then we form a new example by a weighted linear interpolation of these two examples:
- $\hat{x}=\lambda{x}_i+(1-\lambda)x_j$,$\hat{y}=\lambda{y}_i+(1-\lambda)y_j$
- where λ 2 [0; 1] is a random number drawn from the Beta(α; α) distribution.
- In mixup training, we only use the new example $(\hat{x},\hat{y})$.
Transfer Learning
==Berg, Axel, Mark O’Connor, and Miguel Tairum Cruz. “Keyword transformer: A self-attention model for keyword spotting.” arXiv preprint arXiv:2104.00769 (2021).==
==He, Kaiming, et al. “Masked autoencoders are scalable vision learners.” arXiv preprint arXiv:2111.06377 (2021).==
思路
- 提出一种masked autoencoder(MAE),scalable self-supervised learner 可扩展的自监督学习器,应用于计算机视觉中
- MAE的结构是一个不对称的encoder-decoder结构:
- encoder只在可见的输入子集(subset of patches)上训练(输入mask,但token没有mask)
- decoder是一个lightweight的decoder,输入隐藏层特征(latent representation)和mask token,输出重建的image
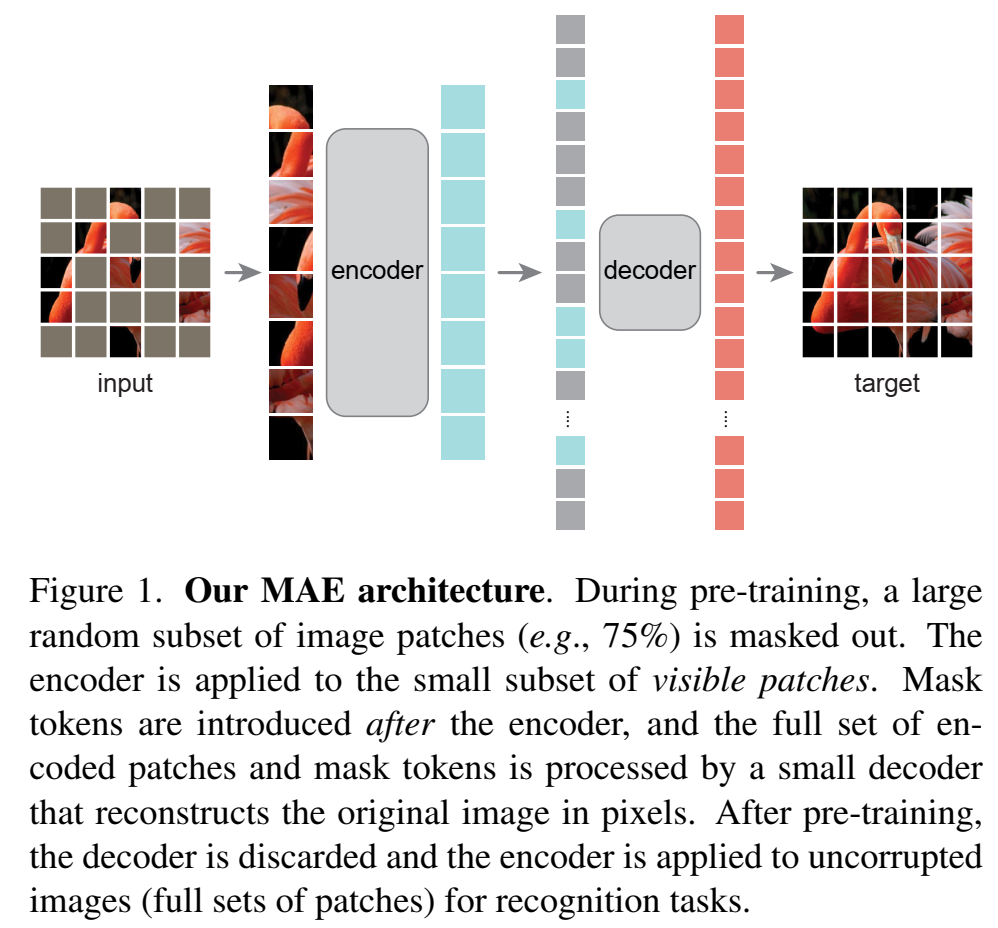
- mask随机块pathches,并且mask比例很大,大部分都要遮住(比如75%),大大改善自监督任务性能
- 为什么自编码器方法在计算机视觉里一开始用得少,在nlp用得多:
- 因为卷积都是规规矩矩沿着常规grids计算的,mask token和positional embedding不好弄?Convolutions typically operate on regular grids and it is not straightforward to integrate ‘indicators’ such as mask tokens or positional embeddings 【不知道mask token是什么,看bert论文【TODO】】,这个不同之处,通过Vision Transformers (ViT) 解决了;
- nlp的文本信息是稠密的,每个字都是有用的,而图片信息分布稀疏,图片中缺失一些信息不影响图片识别;为了解决这个不同之处,提出了masking a very high portion of random patches,mask随机块pathches,并且mask比例很大,大部分都要遮住;这种策略在很大程度上减少了冗余,并创建了一个挑战性的自监督任务;
- 自编码器的decoder(decoder作用是将隐层特征映射回input),文本和图像的decoder也有所不同,视觉decoder输出的是像素pixels,像素的语义级别很低,低级特征,(那我们恢复的是音频特征,也是比较低级的),要输出信息量比较少、不具有代表性的输出,对decoder的要求就很高(nlp的自编码器decoder可以很简单,比如MLP),因此cv的自编码器的decoder建模能力要强;


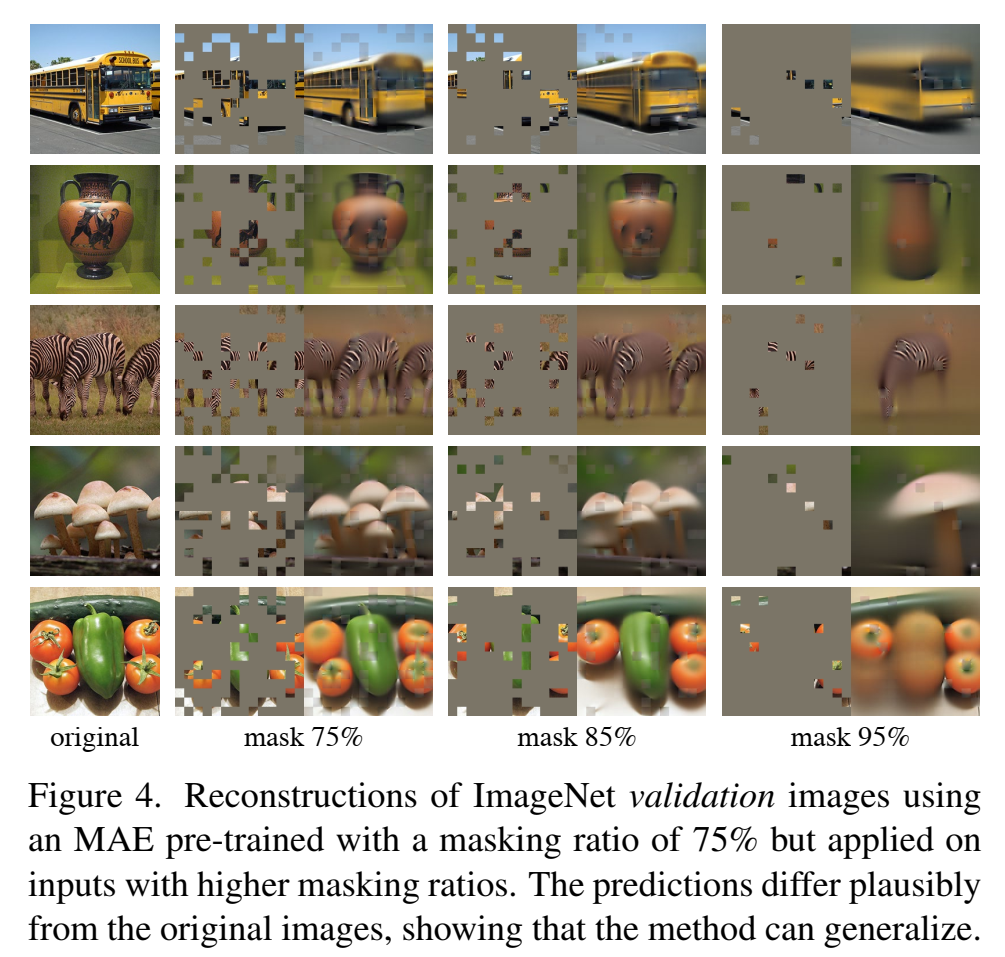
- Related Word
- Masked language modeling:比如BERT和GPT,是输入特征序列只输入全序列中的部分序列,训练模型以预测缺失部分;
- Autoencoding :学习representation的经典方法,encoder映射 input 到 latent representation,decoder映射 latent representation到input,比如 PCA、k-means;Denoising autoencoders (DAE) 是破坏输入,输出未破坏的干净信号,来学会抗干扰能力;破坏的方法比如masking pixels 、removing color channels ;
- Masked image encoding :应该是把encoding的输出也做mask,再给decoder??
- Self-supervised learning : pre-training 、contrastive learning
==Park, Daniel S., et al. “Specaugment: A simple data augmentation method for automatic speech recognition.” arXiv preprint arXiv:1904.08779 (2019).==citations:1603
[论文翻译]SpecAugment:一种用于自动语音识别的简单数据扩增方法 https://blog.ailemon.net/2020/03/09/paper-translation-specaugment-a-simple-data-augmentation-method-for-automatic-speech-recognition/
思路
- 之前论文里的数据扩展方法:VTLN、叠加噪声、速度扰动、模拟房间音频
- 提出一种数据增广方法,叫做 SpecAugment,对语音特征的log mel spectrogram 进行处理来进行数据增广(而不是直接对原始信号),这是因为特征做这些变形,有助于模型的robust,三种处理方法:
- time warping :在时间轴进行变形,对应tensorflow的函数sparse_image_warp ,给定时间步t的特征,看作图像(时间轴是水平的,频率轴是垂直的)[?????]
- time masking :在连续时间步进行一些mask,$[t_0,t_0+t]$被masked,t是0-T之间的均匀分布中选的一个数(T是超参,叫time mask parameter),$t_0 \in [0,\tau-t]$
- frequency masking:在mel 频率channel进行一些mask,$f$个频谱被masked,masked区间$[f_0,f_0+f]$,
- $f$是从0到$F$之间的均匀分布中选出的一个数,$F$是超参(叫frequency mask parameter),
- $f_0 \in [0,v-f]$中选出的一个值,$v$是mel frequency channel的总数
