蒸馏学习用在命令词的论文
==Geoffrey E. Hinton, Oriol Vinyals, & Jeffrey Dean (2015). Distilling the Knowledge in a Neural Network arXiv: Machine Learning.==
知识蒸馏里面的公式推导 知乎
- 知识蒸馏 Knowledge Distill 的开创论文
- 知识蒸馏:一个小模型(student)如何训练得更好?通过学习大模型(teacher)给的知识,大模型用交叉熵训练,要让正确标签的概率越高,对于不正确标签的概率,交叉熵并不考虑其概率,但是一个训练得好的大模型,其他标签概率也包含着一些信息,比如和正确标签更相近的其他标签概率,会比和正确标签很不相近的其他标签概率更大,这就涵盖了信息。如果只有label这样的一个目标的话,那么这个模型的目标就是把训练样本中每一类的样本强制映射到同一个点上,这样其实对于训练很有帮助的类内variance和类间distance就损失掉了
- 要如何突出这些信息,就是通过“soft target”,小模型的训练目标标签不是groundtruth了,而是大模型输出的soft target作为小模型的训练目标标签了。可以看成是利用训练好的大模型对原始的标定空间进行了一次data augmentation
- 因此,知识蒸馏是一种弥补分类问题监督信号不足的办法
- soft logit里的temperature,分为高温和低温,高温的时候,蒸馏操作相当于最小化大模型的logits和蒸馏模型的logits的MSE,低温的时候那些数值小的logits不太被关注,这些数值很小的logits可能是噪声,所以一定程度上对蒸馏模型的效果是有好处的。 但同时这些很小的也有可能代表了一些非常重要的信息,因为很小的温度效果不一定最好,选取适中的T得到最好的结果
公式推导
(这里参考的知乎的变量,和论文的q、p相反)
小模型的输出为:
$$
p_i=softmax(z_i)=\frac{exp(z_i)}{\sum_{j=1}^Nexp(z_j)}
$$
交叉熵损失的公式,其中$q_i$是真实概率,$p_i$是预测概率:
$$
Loss=-\sum_{j=1}^Nq_ilog(p_i)
$$
softmax的求导
$softmax(p_i)$是和所有的logit相关的,所有分为两种情况:
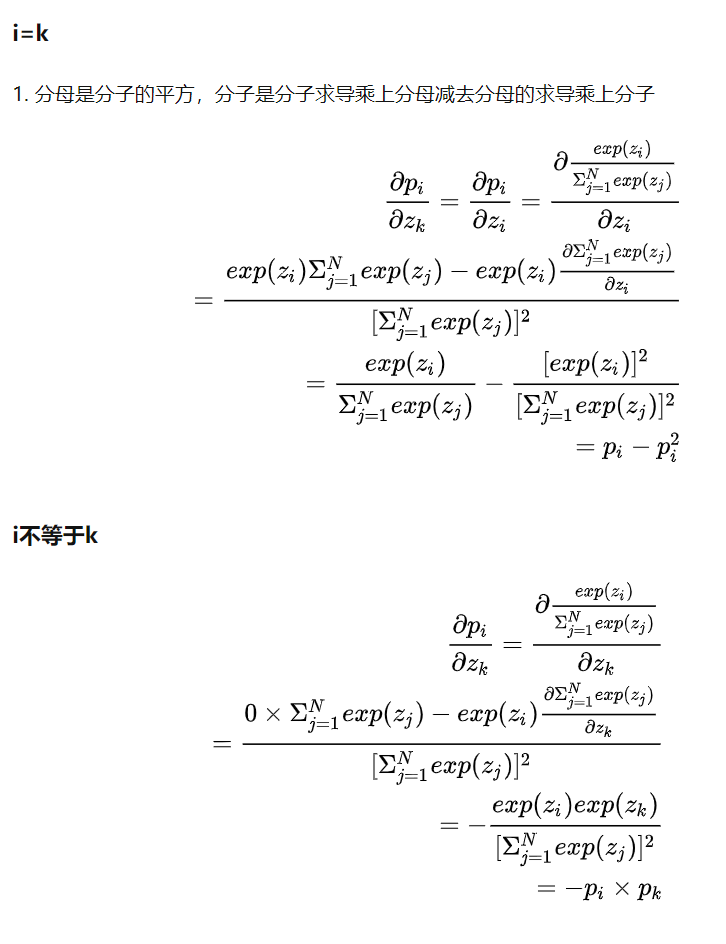
交叉熵的求导:

知识蒸馏:


==Gao, Yan, Titouan Parcollet, and Nicholas Lane. “Distilling Knowledge from Ensembles of Acoustic Models for Joint CTC-Attention End-to-End Speech Recognition.” arXiv preprint arXiv:2005.09310 (2020).==
思路
- 提出知识蒸馏(Knowledge Distillation, KD)
MINIMUM WORD ERROR RATE TRAINING FOR ATTENTION-BASED SEQUENCE-TO-SEQUENCE MODELS
Dictionary-guided Scene Text Recognition